我们希望通过AI,能够自动识别像“一”、“(一)”、“1”、“(1)” 这类常见标题序号。做一个规则,如果存在“一”时,则“一”、“(一)”、“1”分别识别为H1、H2、H3;如果不存在“一”时,“(一)”、“1”、“(1)”分别识别为H1、H2、H3;如果不存在“(一)”时,“1”、“(1)”、“1)”分别识别为H1、H2、H3;依次类推。并生成目录,为文档编排减轻负担。
一、需求分析
1.自定义+AI模式
当然,AI也并不是总能够识别精准,所以为了更好的实现,我们做两套规则,即:
(1)自定义规则识别标题:在代码里添加自定义规则,按照常见标题序号格式识别标题,然后设置对应的标题级别。
(2)deepseek API识别的规则。
再把API返回的结果和自定义规则结合起来,提高标题识别的准确性。
2.具体事项实现思路
(1)判断特定标题序号的存在情况:通过一次遍历文档段落,使用正则表达式判断是否存在 “一、”、“(一)”、“1、” 等标题序号,并将结果存储在相应的布尔变量中。
(2)根据存在情况设置标题级别:再次遍历文档段落,根据之前判断的结果,按照不同的规则将标题序号对应的段落添加到 headings 对象的不同级别中。
(3)API结果处理:调用DeepSeek API来识别标题,把结果存储在apiHeadings里。
(4)结果合并:将 API 返回的标题信息apiHeadings 和自定义规则识别的标题信息headings 合并,然后根据合并后的结果allHeadings 设置文档段落的标题样式。
(5)设置标题级别:依据 allHeadings 里的标题信息,设置文档中对应段落的标题级别。
(6)创建目录:设置好标题级别后,创建并更新目录。
3.标题序号处理
关于标题序号,除了“一、”、“(一)”、“1、”这些类型外,还有序列要实现:'一', '二', '三', '四', '五', '六', '七', '八', '九', '十',所以也要分别做处理:
(1)统计标题序号类型数量:
在判断是否存在不同标题序号(hasOne、hasBracketOne、hasNumberOne)之后,统计存在的标题序号类型的数量,存储在 titleTypeCount 变量中。
(2)处理只有一种标题序号类型的情况:
如果 titleTypeCount 大于 1,说明存在多种标题序号类型,按照之前的规则进行标题级别设置。
如果 titleTypeCount 等于 1,说明只有一种标题序号类型,将所有匹配该标题序号的段落都设置为 标题1。
4.文档信息读取
获取文档段落:使用 doc.Content.Paragraphs 获取文档中的所有段落。
获取WPS内置标题样式:使用doc.Styles获取WPS中标题样式。
5.文档处于受保护状态
若文档处于受保护状态,就无法创建新样式。你需要检查文档是否被保护,若被保护则解除保护。可以按照以下步骤在 WPS 中解除文档保护:
(1)打开文档:在 WPS 中打开你要处理的文档。
(2)找到 “审阅” 选项卡:在 WPS 文字的顶部菜单栏中,找到并点击 “审阅” 选项卡。
(3)点击 “限制编辑”:在 “审阅” 选项卡中,找到 “限制编辑” 按钮,点击它。这通常会在右侧弹出一个 “限制编辑” 的侧边栏。
(4)停止保护文档:在 “限制编辑” 侧边栏中,找到 “停止保护” 按钮并点击。
(5)输入密码(如果有):如果文档设置了保护密码,系统会提示你输入密码。输入正确的密码后,点击 “确定” 按钮。
(6)确认解除保护:完成上述步骤后,文档的保护状态应该就被解除了。你可以再次运行宏代码来检查是否能够成功执行。
解除保护后,再运行之前的宏代码,应该就可以正常创建样式并执行后续的标题识别和目录创建操作了。
二、自定义规则实现
1打开WPS的JS宏编辑器
具体操作可以看我的CSDN文章:在WPS中通过JavaScript宏(JSA)调用DeepSeek官网API优化文档教程-CSDN博客。
【工具】选项卡 --> 【开发工具】 --> 【切换到JS环境】 --> 【WPS宏编辑器】。

2.在Project(Normal.dotm)中新建模块
Project(Normal.dotm)可以控制全局,即所有文档都可以用。
在模块中添加以下代码(加入当前的模块名是Module2):
function identifyAndSetHeadingsAndCreateTOC() {// 获取文档内容var doc = this.Application.ActiveDocument;// 尝试获取文档的保护类型,若抛出异常则认为文档可能存在问题try {var protectionType = doc.ProtectionType;if (protectionType!== -1) {alert("文档处于受保护状态,请先解除保护。");return;}} catch (error) {alert("获取文档保护状态时出现异常,请检查文档是否正常。");return;}var paragraphs = doc.Content.Paragraphs;// var title1Style = doc.Styles("标题 1");// if (title1Style) {// alert("成功读取标题 1 样式");// }// 定义标题级别映射var headings = {"标题1": [],"标题2": [],"标题3": []};// 先判断文档中是否存在不同类型的标题序号var hasOne = false;var hasBracketOne = false;var hasNumberOne = false;var hasChineseNumbers = [];var hasBracketNumbers = [];var hasPlainNumbers = [];for (var i = 1; i <= 10; i++) {hasChineseNumbers[i] = false;hasBracketNumbers[i] = false;hasPlainNumbers[i] = false;}for (var i = 1; i <= paragraphs.Count; i++) {var para = paragraphs.Item(i);var text = para.Range.Text.trim();if (text) {for (var j = 1; j <= 10; j++) {var chineseRegex = new RegExp(`^${getChineseNumber(j)}、|^${getChineseNumber(j)}\\.|^${getChineseNumber(j)}\\s`);var bracketRegex = new RegExp(`^(${j})`);var plainRegex = new RegExp(`^${j}、|^${j}\\.|^${j}\\s`);if (chineseRegex.test(text)) {if (j === 1) hasOne = true;hasChineseNumbers[j] = true;} else if (bracketRegex.test(text)) {if (j === 1) hasBracketOne = true;hasBracketNumbers[j] = true;} else if (plainRegex.test(text)) {if (j === 1) hasNumberOne = true;hasPlainNumbers[j] = true;}}}}// 统计存在的标题序号类型数量var titleTypeCount = 0;for (var i = 1; i <= 10; i++) {if (hasChineseNumbers[i]) titleTypeCount++;if (hasBracketNumbers[i]) titleTypeCount++;if (hasPlainNumbers[i]) titleTypeCount++;}// 根据存在情况设置标题级别for (var i = 1; i <= paragraphs.Count; i++) {var para = paragraphs.Item(i);var text = para.Range.Text.trim();if (text) {if (titleTypeCount > 1) {if (hasOne) {for (var j = 1; j <= 10; j++) {var chineseRegex = new RegExp(`^${getChineseNumber(j)}、|^${getChineseNumber(j)}\\.|^${getChineseNumber(j)}\\s`);var bracketRegex = new RegExp(`^(${j})`);var plainRegex = new RegExp(`^${j}、|^${j}\\.|^${j}\\s`);if (chineseRegex.test(text)) {headings["标题1"].push(text);} else if (bracketRegex.test(text)) {headings["标题2"].push(text);} else if (plainRegex.test(text)) {headings["标题3"].push(text);}}} else if (hasBracketOne) {for (var j = 1; j <= 10; j++) {var bracketRegex = new RegExp(`^(${j})`);var plainRegex = new RegExp(`^${j}、|^${j}\\.|^${j}\\s`);var subBracketRegex = new RegExp(`^(${j})`);if (bracketRegex.test(text)) {headings["标题1"].push(text);} else if (plainRegex.test(text)) {headings["标题2"].push(text);} else if (subBracketRegex.test(text)) {headings["标题3"].push(text);}}} else if (hasNumberOne) {for (var j = 1; j <= 10; j++) {var plainRegex = new RegExp(`^${j}、|^${j}\\.|^${j}\\s`);var subBracketRegex = new RegExp(`^(${j})`);var subPlainRegex = new RegExp(`^${j})`);if (plainRegex.test(text)) {headings["标题1"].push(text);} else if (subBracketRegex.test(text)) {headings["标题2"].push(text);} else if (subPlainRegex.test(text)) {headings["标题3"].push(text);}}}} else {// 只有一种标题序号类型,全部设为标题1for (var j = 1; j <= 10; j++) {var chineseRegex = new RegExp(`^${getChineseNumber(j)}、|^${getChineseNumber(j)}\\.|^${getChineseNumber(j)}\\s`);var bracketRegex = new RegExp(`^(${j})`);var plainRegex = new RegExp(`^${j}、|^${j}\\.|^${j}\\s`);var subBracketRegex = new RegExp(`^(${j})`);var subPlainRegex = new RegExp(`^${j})`);if (chineseRegex.test(text) || bracketRegex.test(text) || plainRegex.test(text) || subBracketRegex.test(text) || subPlainRegex.test(text)) {headings["标题1"].push(text);}}}}}// 检查样式是否存在if (!doc.Styles("标题 1") || !doc.Styles("标题 2") || !doc.Styles("标题 3")) {alert("样式 标题 1、标题 2或标题 3不存在,请检查!");return;}// 设置标题级别for (var i = 1; i <= paragraphs.Count; i++) {var para = paragraphs.Item(i);var text = para.Range.Text.trim();if (headings["标题1"].includes(text)) {try {para.Style = doc.Styles("标题 1");} catch (e) {alert(`设置“标题 1”样式时出现意外错误,段落内容:${text},错误信息:${e.message}`);}} else if (headings["标题2"].includes(text)) {try {para.Style = doc.Styles("标题 2");} catch (e) {alert(`设置“标题 2”样式时出现意外错误,段落内容:${text},错误信息:${e.message}`);}} else if (headings["标题3"].includes(text)) {try {para.Style = doc.Styles("标题 3");} catch (e) {alert(`设置“标题 3”样式时出现意外错误,段落内容:${text},错误信息:${e.message}`);}}}// 创建目录var tocPara = doc.Content.Paragraphs.Add();var tocRange = tocPara.Range;tocRange.InsertAfter("目录\n");try {var toc = doc.TablesOfContents.Add(tocRange, {"UseHeadingStyles": true,"UpperHeadingLevel": 1,"LowerHeadingLevel": 3});toc.Update();alert('设置标题并识别目录,完成!');} catch (e) {alert("创建目录失败,请检查标题设置!");}}function getChineseNumber(num) {var chineseNumbers = ['一', '二', '三', '四', '五', '六', '七', '八', '九', '十'];return chineseNumbers[num - 1];}界面效果如下:
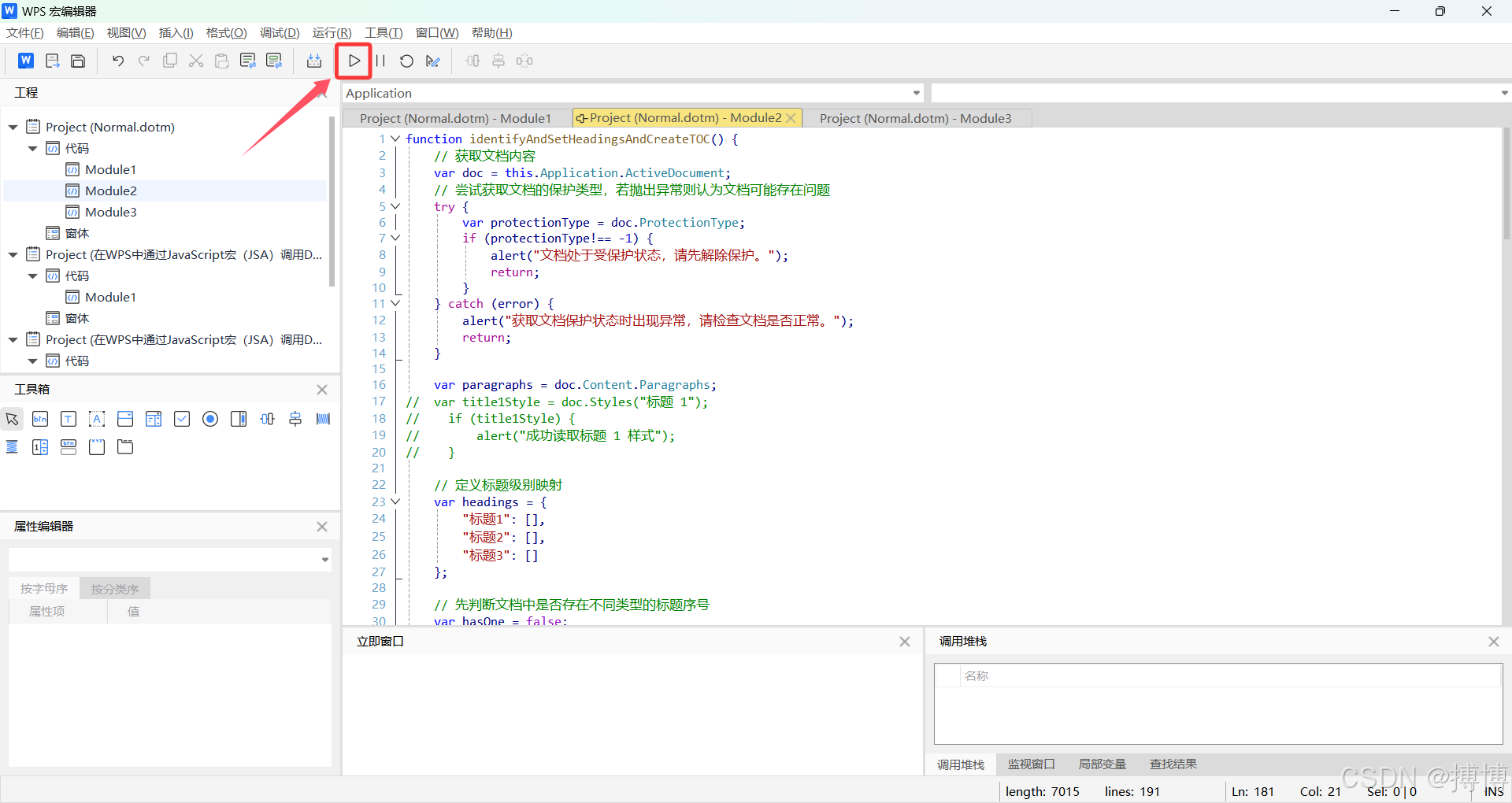
接下来即可点击界面上的“运行”按钮,直至提示完成,即可看文档被设置后的效果!

三、结合DeepSeek的API能力
要在WPS中通过JavaScript宏(JSA)调用DeepSeek官方API自动识别文档的标题级别并设置,同时实现识别并创建目录,可以按照以下步骤进行:
1. 获取 DeepSeek API 密钥
首先,你需要前往DeepSeek官网注册账号,在开发者中心创建应用,从而获取API Key。注意选择合适的模型,如deepseek - v3。
具体的内容同样可以看我的CSDN文章:在WPS中通过JavaScript宏(JSA)调用DeepSeek官网API优化文档教程-CSDN博客。
2. 编写 WPS JavaScript 宏代码
在Module2中继续添加代码,添加在identifyAndSetHeadingsAndCreateTOC()函数中,添加的位置如下,插入在“检查样式是否存在”之前:
// 根据存在情况设置标题级别
for (var i = 1; i <= paragraphs.Count; i++) {}
------ 添加在此位置 ------
// 检查样式是否存在
if (!doc.Styles("标题 1") || !doc.Styles("标题 2") || !doc.Styles("标题 3")) {
alert("样式 标题 1、标题 2或标题 3不存在,请检查!");
return;
}
以下是添加的详细代码:
// 显示正在执行的提示alert("正在调用 DeepSeek API 进行标题识别,请稍候...\n点击确定,将进入后台运行!");// 尝试调用 DeepSeek API 辅助识别标题var apiHeadings = {"标题1": [],"标题2": [],"标题3": []};try {var content = "";for (var i = 1; i <= paragraphs.Count; i++) {var para = paragraphs.Item(i);content += para.Range.Text;}// DeepSeek API 配置var apiUrl = 'https://api.deepseek.com/v1/chat/completions';var apiKey = 'sk-e4df3c51537048af980934467b594163';var model = 'deepseek-chat';// 构建请求体,明确告知 API 识别标题序号并分类var requestBody = {"model": model,"messages": [{"role": "user","content": `请识别以下文档内容中以 "一、"或"一."或"一 "、"(一)"、"1、"或"1."或"1 "、"(1)"、"1)" 等开头的标题,并按照3个级别进行分类,格式为:标题1: [标题1内容1, 标题1内容2, ...]标题2: [标题2内容1, 标题2内容2, ...]标题3: [标题3内容1, 标题3内容2, ...]${content}`}],"stream": false};requestBody = JSON.stringify(requestBody);// 创建 XMLHttpRequest 对象var xhr = new XMLHttpRequest();xhr.open('POST', apiUrl, false);// 设置请求头xhr.setRequestHeader('Content-Type', 'application/json');xhr.setRequestHeader('Authorization', 'Bearer ' + apiKey);// 设置超时时间(单位:毫秒)xhr.timeout = 30000;// 超时处理函数xhr.ontimeout = function () {alert('请求超时,请稍后重试!');return;};// 发送请求xhr.send(requestBody);if (xhr.status === 200) {var response = JSON.parse(xhr.responseText);var result = response.choices[0].message.content;// 解析 API 结果var lines = result.split('\n');for (var i = 0; i < lines.length; i++) {var line = lines[i];if (line.startsWith('标题1:')) {var titles = line.substring(4).trim().replace('[', '').replace(']', '').split(',');for (var j = 0; j < titles.length; j++) {apiHeadings["标题1"].push(titles[j].trim());}} else if (line.startsWith('标题2:')) {var titles = line.substring(4).trim().replace('[', '').replace(']', '').split(',');for (var j = 0; j < titles.length; j++) {apiHeadings["标题2"].push(titles[j].trim());}} else if (line.startsWith('标题3:')) {var titles = line.substring(4).trim().replace('[', '').replace(']', '').split(',');for (var j = 0; j < titles.length; j++) {apiHeadings["标题3"].push(titles[j].trim());}}}} else {alert('请求失败,状态码:' + xhr.status);return;}} catch (e) {alert('调用 DeepSeek API 出错:' + e.message);return;}if(headings["标题1"].length!=0){if(apiHeadings["标题1"].length==0){alert("请继续等待30秒...");}}// 合并自定义规则和 API 结果var allHeadings = {"标题1": headings["标题1"].concat(apiHeadings["标题1"]),"标题2": headings["标题2"].concat(apiHeadings["标题2"]),"标题3": headings["标题3"].concat(apiHeadings["标题3"])};// 隐藏正在执行的提示(这里只是逻辑上的隐藏,alert 无法真正隐藏)// 可以考虑使用更复杂的 UI 组件来实现显示和隐藏添加完之后,修改以下代码段为(其实就是将代码中的headings改为allHeadings):// 设置标题级别for (var i = 1; i <= paragraphs.Count; i++) {var para = paragraphs.Item(i);var text = para.Range.Text.trim();if (allHeadings["标题1"].includes(text)) {try {para.Style = doc.Styles("标题 1");} catch (e) {alert(`设置“标题 1”样式时出现意外错误,段落内容:${text},错误信息:${e.message}`);}} else if (allHeadings["标题2"].includes(text)) {try {para.Style = doc.Styles("标题 2");} catch (e) {alert(`设置“标题 2”样式时出现意外错误,段落内容:${text},错误信息:${e.message}`);}} else if (allHeadings["标题3"].includes(text)) {try {para.Style = doc.Styles("标题 3");} catch (e) {alert(`设置“标题 3”样式时出现意外错误,段落内容:${text},错误信息:${e.message}`);}}}至此代码就完成了!
3. 新建WPS组件
这个方式在我的另外一篇文章中已经讲解过了,具体的可以参照CSDN文章:在WPS中通过JavaScript宏(JSA)调用本地DeepSeek API优化文档教程:在WPS中通过JavaScript宏(JSA)调用本地DeepSeek API优化文档教程_wps调用api-CSDN博客。
(1)创建新选项卡和组。
前文已经创建过了DeepSeek选项卡。我们继续在这个选项卡下新增。
(2)新建组
前文我们也已经添加了“AI优化”组件。接下来我们再添加一个“创建标题与目录”的组。如下图:
(3)为“创建标题与目录”组添加组件
选中“创建标题与目录”组,在左侧下来选择“宏”,选择identifyAndSetHeadingsAndCreateTOC,之后点击“添加”,将组件添加到“创建标题与目录”下。
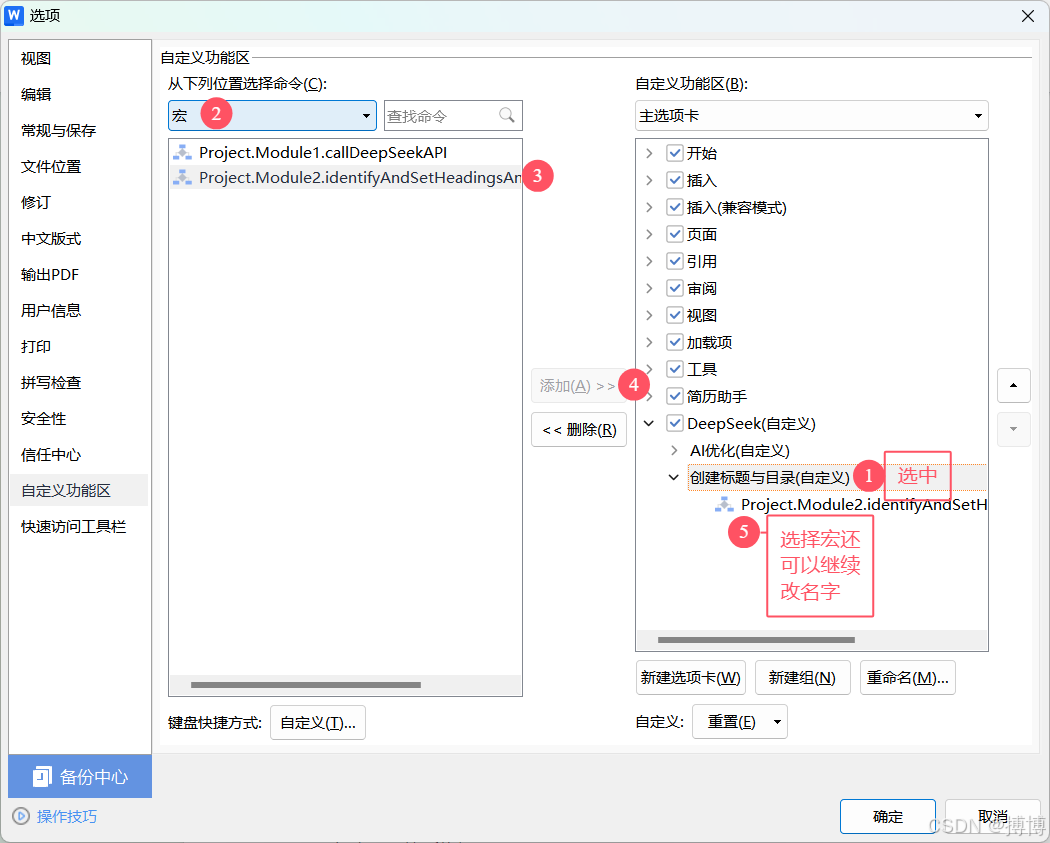
(4)组件改名
对Project.Module2.identifyAndSetHeadingsAndCreateTOC改名:创建标题与目录。可得如下效果:
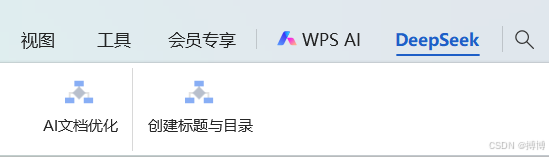
4. 注意事项
(1)请将代码中的 sk-替换为你的API密钥 替换为你实际的 DeepSeek API 密钥。
(2)确保你的网络连接正常,因为需要调用 DeepSeek API。
(3)该代码依赖于 WPS 的内置标题样式 “标题 1”、“标题 2” 和 “标题 3”,请确保文档中这些样式存在。
当然代码还有很多不完善的,逻辑结构考虑的不够完整,大家可以继续修改!
5. 附上identifyAndSetHeadingsAndCreateTOC完整代码
function identifyAndSetHeadingsAndCreateTOC() {// 获取文档内容var doc = this.Application.ActiveDocument;// 尝试获取文档的保护类型,若抛出异常则认为文档可能存在问题try {var protectionType = doc.ProtectionType;if (protectionType!== -1) {alert("文档处于受保护状态,请先解除保护。");return;}} catch (error) {alert("获取文档保护状态时出现异常,请检查文档是否正常。");return;}var paragraphs = doc.Content.Paragraphs;
// var title1Style = doc.Styles("标题 1");
// if (title1Style) {
// alert("成功读取标题 1 样式");
// }// 定义标题级别映射var headings = {"标题1": [],"标题2": [],"标题3": []};// 先判断文档中是否存在不同类型的标题序号var hasOne = false;var hasBracketOne = false;var hasNumberOne = false;var hasChineseNumbers = [];var hasBracketNumbers = [];var hasPlainNumbers = [];for (var i = 1; i <= 10; i++) {hasChineseNumbers[i] = false;hasBracketNumbers[i] = false;hasPlainNumbers[i] = false;}for (var i = 1; i <= paragraphs.Count; i++) {var para = paragraphs.Item(i);var text = para.Range.Text.trim();if (text) {for (var j = 1; j <= 10; j++) {var chineseRegex = new RegExp(`^${getChineseNumber(j)}、|^${getChineseNumber(j)}\\.|^${getChineseNumber(j)}\\s`);var bracketRegex = new RegExp(`^(${j})`);var plainRegex = new RegExp(`^${j}、|^${j}\\.|^${j}\\s`);if (chineseRegex.test(text)) {if (j === 1) hasOne = true;hasChineseNumbers[j] = true;} else if (bracketRegex.test(text)) {if (j === 1) hasBracketOne = true;hasBracketNumbers[j] = true;} else if (plainRegex.test(text)) {if (j === 1) hasNumberOne = true;hasPlainNumbers[j] = true;}}}}// 统计存在的标题序号类型数量var titleTypeCount = 0;for (var i = 1; i <= 10; i++) {if (hasChineseNumbers[i]) titleTypeCount++;if (hasBracketNumbers[i]) titleTypeCount++;if (hasPlainNumbers[i]) titleTypeCount++;}// 根据存在情况设置标题级别for (var i = 1; i <= paragraphs.Count; i++) {var para = paragraphs.Item(i);var text = para.Range.Text.trim();if (text) {if (titleTypeCount > 1) {if (hasOne) {for (var j = 1; j <= 10; j++) {var chineseRegex = new RegExp(`^${getChineseNumber(j)}、|^${getChineseNumber(j)}\\.|^${getChineseNumber(j)}\\s`);var bracketRegex = new RegExp(`^(${j})`);var plainRegex = new RegExp(`^${j}、|^${j}\\.|^${j}\\s`);if (chineseRegex.test(text)) {headings["标题1"].push(text);} else if (bracketRegex.test(text)) {headings["标题2"].push(text);} else if (plainRegex.test(text)) {headings["标题3"].push(text);}}} else if (hasBracketOne) {for (var j = 1; j <= 10; j++) {var bracketRegex = new RegExp(`^(${j})`);var plainRegex = new RegExp(`^${j}、|^${j}\\.|^${j}\\s`);var subBracketRegex = new RegExp(`^(${j})`);if (bracketRegex.test(text)) {headings["标题1"].push(text);} else if (plainRegex.test(text)) {headings["标题2"].push(text);} else if (subBracketRegex.test(text)) {headings["标题3"].push(text);}}} else if (hasNumberOne) {for (var j = 1; j <= 10; j++) {var plainRegex = new RegExp(`^${j}、|^${j}\\.|^${j}\\s`);var subBracketRegex = new RegExp(`^(${j})`);var subPlainRegex = new RegExp(`^${j})`);if (plainRegex.test(text)) {headings["标题1"].push(text);} else if (subBracketRegex.test(text)) {headings["标题2"].push(text);} else if (subPlainRegex.test(text)) {headings["标题3"].push(text);}}}} else {// 只有一种标题序号类型,全部设为标题1for (var j = 1; j <= 10; j++) {var chineseRegex = new RegExp(`^${getChineseNumber(j)}、|^${getChineseNumber(j)}\\.|^${getChineseNumber(j)}\\s`);var bracketRegex = new RegExp(`^(${j})`);var plainRegex = new RegExp(`^${j}、|^${j}\\.|^${j}\\s`);var subBracketRegex = new RegExp(`^(${j})`);var subPlainRegex = new RegExp(`^${j})`);if (chineseRegex.test(text) || bracketRegex.test(text) || plainRegex.test(text) || subBracketRegex.test(text) || subPlainRegex.test(text)) {headings["标题1"].push(text);}}}}}// 显示正在执行的提示alert("正在调用 DeepSeek API 进行标题识别,请稍候...\n点击确定,将进入后台运行!");// 尝试调用 DeepSeek API 辅助识别标题var apiHeadings = {"标题1": [],"标题2": [],"标题3": []};try {var content = "";for (var i = 1; i <= paragraphs.Count; i++) {var para = paragraphs.Item(i);content += para.Range.Text;}// DeepSeek API 配置var apiUrl = 'https://api.deepseek.com/v1/chat/completions';var apiKey = 'sk-e4df3c51537048af980934467b594163';var model = 'deepseek-chat';// 构建请求体,明确告知 API 识别标题序号并分类var requestBody = {"model": model,"messages": [{"role": "user","content": `请识别以下文档内容中以 "一、"或"一."或"一 "、"(一)"、"1、"或"1."或"1 "、"(1)"、"1)" 等开头的标题,并按照3个级别进行分类,格式为:
标题1: [标题1内容1, 标题1内容2, ...]
标题2: [标题2内容1, 标题2内容2, ...]
标题3: [标题3内容1, 标题3内容2, ...]${content}`}],"stream": false};requestBody = JSON.stringify(requestBody);// 创建 XMLHttpRequest 对象var xhr = new XMLHttpRequest();xhr.open('POST', apiUrl, false);// 设置请求头xhr.setRequestHeader('Content-Type', 'application/json');xhr.setRequestHeader('Authorization', 'Bearer ' + apiKey);// 设置超时时间(单位:毫秒)xhr.timeout = 30000;// 超时处理函数xhr.ontimeout = function () {alert('请求超时,请稍后重试!');return;};// 发送请求xhr.send(requestBody);if (xhr.status === 200) {var response = JSON.parse(xhr.responseText);var result = response.choices[0].message.content;// 解析 API 结果var lines = result.split('\n');for (var i = 0; i < lines.length; i++) {var line = lines[i];if (line.startsWith('标题1:')) {var titles = line.substring(4).trim().replace('[', '').replace(']', '').split(',');for (var j = 0; j < titles.length; j++) {apiHeadings["标题1"].push(titles[j].trim());}} else if (line.startsWith('标题2:')) {var titles = line.substring(4).trim().replace('[', '').replace(']', '').split(',');for (var j = 0; j < titles.length; j++) {apiHeadings["标题2"].push(titles[j].trim());}} else if (line.startsWith('标题3:')) {var titles = line.substring(4).trim().replace('[', '').replace(']', '').split(',');for (var j = 0; j < titles.length; j++) {apiHeadings["标题3"].push(titles[j].trim());}}}} else {alert('请求失败,状态码:' + xhr.status);return;}} catch (e) {alert('调用 DeepSeek API 出错:' + e.message);return;}if(headings["标题1"].length!=0){if(apiHeadings["标题1"].length==0){alert("请继续等待30秒...");}}// 合并自定义规则和 API 结果var allHeadings = {"标题1": headings["标题1"].concat(apiHeadings["标题1"]),"标题2": headings["标题2"].concat(apiHeadings["标题2"]),"标题3": headings["标题3"].concat(apiHeadings["标题3"])};// 隐藏正在执行的提示(这里只是逻辑上的隐藏,alert 无法真正隐藏)// 可以考虑使用更复杂的 UI 组件来实现显示和隐藏// 检查样式是否存在if (!doc.Styles("标题 1") || !doc.Styles("标题 2") || !doc.Styles("标题 3")) {alert("样式 标题 1、标题 2或标题 3不存在,请检查!");return;}// 设置标题级别for (var i = 1; i <= paragraphs.Count; i++) {var para = paragraphs.Item(i);var text = para.Range.Text.trim();if (allHeadings["标题1"].includes(text)) {try {para.Style = doc.Styles("标题 1");} catch (e) {alert(`设置“标题 1”样式时出现意外错误,段落内容:${text},错误信息:${e.message}`);}} else if (allHeadings["标题2"].includes(text)) {try {para.Style = doc.Styles("标题 2");} catch (e) {alert(`设置“标题 2”样式时出现意外错误,段落内容:${text},错误信息:${e.message}`);}} else if (allHeadings["标题3"].includes(text)) {try {para.Style = doc.Styles("标题 3");} catch (e) {alert(`设置“标题 3”样式时出现意外错误,段落内容:${text},错误信息:${e.message}`);}}}// 创建目录var tocPara = doc.Content.Paragraphs.Add();var tocRange = tocPara.Range;tocRange.InsertAfter("目录\n");try {var toc = doc.TablesOfContents.Add(tocRange, {"UseHeadingStyles": true,"UpperHeadingLevel": 1,"LowerHeadingLevel": 3});toc.Update();alert('设置标题并识别目录,完成!');} catch (e) {alert("创建目录失败,请检查标题设置!");}
}function getChineseNumber(num) {var chineseNumbers = ['一', '二', '三', '四', '五', '六', '七', '八', '九', '十'];return chineseNumbers[num - 1];
}