一、概念
在 Shell 脚本中,正则表达式是一种强大且常用的文本处理工具,它可以用来匹配、搜索、替换和截取字符串。
正则表达式是由一些字符去描述规则,在正则表达式中有两类字符
(1)元字符(Meta Character):Shell 环境中具有特殊含义的字符,在命令行解释、文件名扩展、变量替换等方面起着关键作用。
(2)普通字符:仅代表自身的字符。\元字符 ==> 普通字符
正则表达式也有不同的流派(如Egrep,java,C#)很多语言都用到了正则表达式,但是这些语言中用来描述字符串规则的"元字符"不是都一样的,因此称正则表达式有不同的流派。
正则表达式中匹配的三种量词:贪婪(Greedy)、勉强(Reluctant)、独占(Possessive)
二、元字符
| 元字符 | 含义 | 示例 | 说明 |
| . | 匹配一个除换行符以外的任意字符 | a.b | 匹配以a开头b结尾,中间有一个任意字符的单词 |
| ^ | 匹配行首 | ^ab | 匹配以ab为行首的单词 |
| $ | 匹配行尾 | ab$ | 匹配以ab为行尾的单词 |
| \ | 转义符 | \ | 转换 < 原本的含义 |
| < > | 匹配一个指定的单词 | \ | 精准匹配ab这个单词 |
| \| | 逻辑或 | ab\|AB | 匹配ab或者AB |
| \d | 匹配任何数字,等同于[0-9] | grep -P '\d' | 需要和grep等工具一起使用 |
| \D | 匹配一个非数字字符,等价于 | grep -P '\D' | 需要和grep等工具一起使用 |
| \w | 匹配任何字母,等同于[a-zA-Z0-9] | grep -P '\w' | 需要和grep等工具一起使用 |
| \W | 匹配任何非单词字符,等同于[^a-zA-Z0-9] | grep -P '\W' | 需要和grep等工具一起使用 |
| \s | 匹配任何空白字符(空格、制表符、换行符等) | grep -P '\s' | 需要和grep等工具一起使用 |
| \S | 匹配任何非空白字符 | grep -P '\S' | 需要和grep等工具一起使用 |
| \b | 匹配单词边界 | grep -P '\bhello\b' | 单词的开头边界:\bword 匹配 "word" 单词的结尾边界:word\b 匹配 "word" |
| \B | 匹配非单词边界 | grep -P 'hello\B' | 匹配单词内部的连接点:\Bcat\B 会匹配 "category" 中的 "cat" 确保匹配不发生在单词边界:\B-\B 会匹配 "a-b" 中的 - |
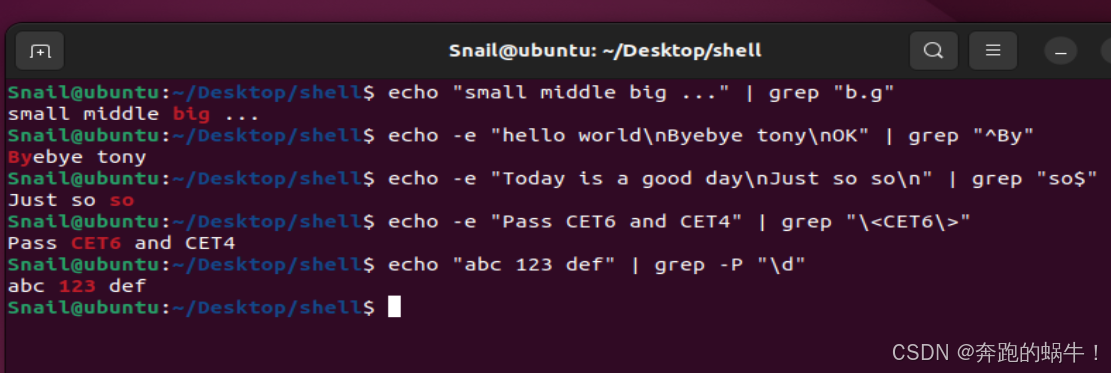
Shell程序实例
#/bin/bash#使用 . 匹配任意字符
echo "small middle big ..." | grep "b.g"#使用 ^ 匹配行首
echo -e "hello world\nByebye tony\nOK" | grep "^By"#使用 $ 匹配行尾
echo -e "Today is a good day\nJust so so\n" | grep "so$"#使用 <> 匹配一个指定单词
echo -e "Pass CET6 and CET4" | grep "\<CET6\>"#使用 \d 匹配任何数字
echo "abc 123 def" | grep -P "\d"Shell程序效果截图
三、字符范围匹配
| 字符 | 含义 | 示例 | 说明 |
| [ ] | 匹配一个指定范围的字符 | a[xyz]b | 匹配以a开头b结尾,中间有一个x或y或z的单词 |
| [^ ] | 匹配一个不在指定范围的字符 | a[^xyz]b | 匹配以a开头b结尾,中间有一个不是x或y或z的单词 |
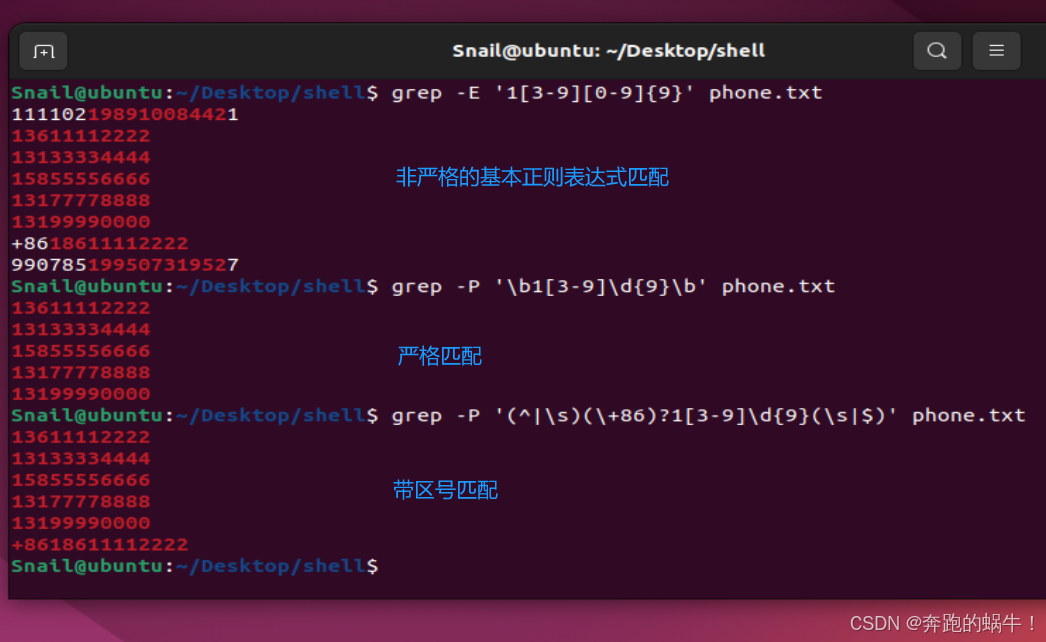
Shell程序实例 (国内手机号码匹配)
phone.txt
111102198910084421
13611112222
13133334444
15855556666
13177778888
13199990000
+8618611112222
990785199507319527
66666666666phone.sh
#!/bin/bash#Shell程序实例 (国内手机号码匹配)
#基本正则表达式
grep -E '1[3-9][0-9]{9}' phone.txt
#严格匹配(推荐)
grep -P '\b1[3-9]\d{9}\b' phone.txt
#带区号匹配
grep -P '(^|\s)(\+86)?1[3-9]\d{9}(\s|$)' phone.txtShell程序效果截图
四、字符重复匹配
1、贪婪匹配
| 非贪婪量词 | 含义(尽量重复的多) | 示例 | 说明 |
| ? | 使前面的字符重复0次或1次 | a? | 匹配a重复了0次或1次的单词 |
| * | 使前面的字符重复0次或多次 | a* | 匹配a重复了0次或多次的单词 |
| + | 使前面的字符重复1次或多次 | a+ | 匹配a重复了1次或多次的单词 |
| {n} | 使前面的字符重复n次 | a{6} | 匹配a重复了6次的单词 |
| {n,} | 使前面的字符n次或以上 | a{6,} | 匹配a重复了6次或以上的单词 |
| {n,m} | 使前面的字符重复n次到m次 | a{6,9} | 匹配a重复了6次到9次的单词 |
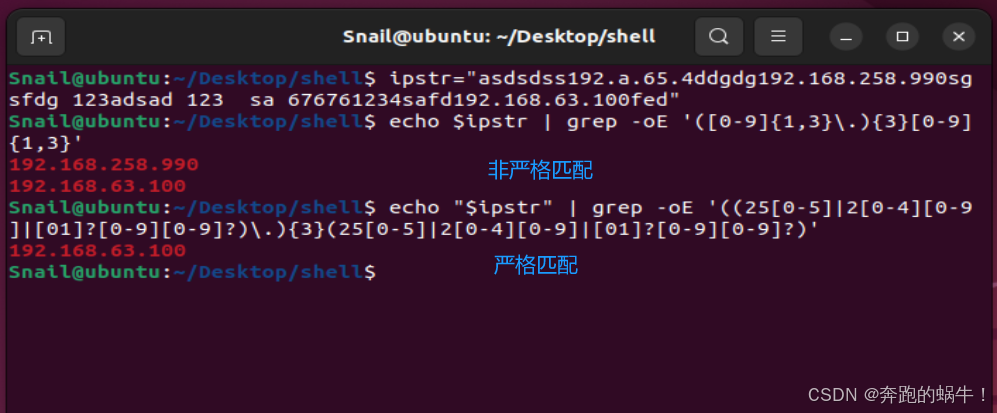
Shell程序实例(IPv4地址匹配)
#/bin/bashipstr="asdsdss192.a.65.4ddgdg192.168.258.990sgsfdg 123adsad 123 sa 676761234safd192.168.63.100fed"#匹配 IPv4地址
#非严格匹配:快速提取 X.X.X.X 格式的字符串,可能数字超IPV4的范围
echo $ipstr | grep -oE '([0-9]{1,3}\.){3}[0-9]{1,3}'
#严格匹配:不仅匹配X.X.X.X 格式的字符串,还限制数字的范围
echo "$ipstr" | grep -oE '((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)'
Shell程序效果截图
2、非贪婪匹配
非贪婪匹配就是在贪婪量词后面加个问号?
| 非贪婪量词 | 含义(尽量重复的少) | 示例 | 说明 |
| ?? | 匹配 0 次或 1 次,但尽可能少 | a?? | 尽量少地匹配a重复了0次或1次的单词 |
| *? | 匹配 0 次或多次,但尽可能少 | a*? | 尽量少地匹配a重复0次或多次的单词 |
| +? | 匹配 1 次或多次,但尽可能少 | a+? | 尽量少地匹配a重复了1次或多次的单词 |
| {n}? | 使前面的字符重复n次 | a{6}? | 尽量少地匹配a重复了6次的单词 |
| {n,}? | 使前面的字符n次或以上,但尽可能少 | a{6,}? | 尽量少地匹配a重复了6次或以上的单词 |
| {n,m}? | 使前面的字符重复n次到m次,但尽可能少 | a{6,9}? | 尽量少地匹配a重复6次到9次的单词 |
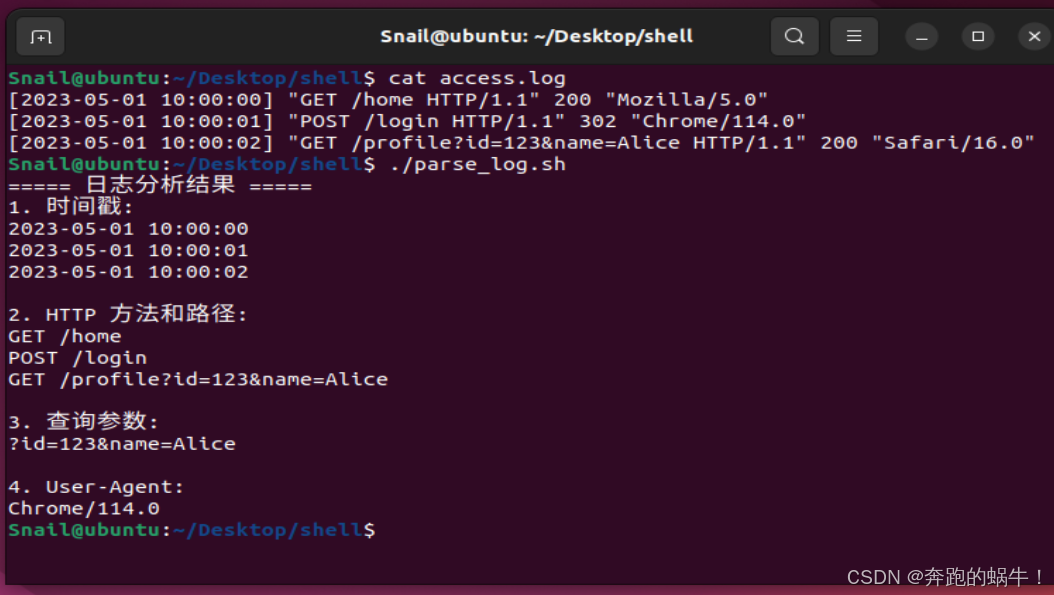
Shell程序实例 (匹配 HTML 标签内容)
Web 服务器日志 (access.log)
[2023-05-01 10:00:00] "GET /home HTTP/1.1" 200 "Mozilla/5.0"
[2023-05-01 10:00:01] "POST /login HTTP/1.1" 302 "Chrome/114.0"
[2023-05-01 10:00:02] "GET /profile?id=123&name=Alice HTTP/1.1" 200 "Safari/16.0"parse_log.sh
#!/bin/bashecho "===== 日志分析结果 ====="
echo "1. 时间戳:"
grep -Po '\[\K.*?(?=\])' access.logecho -e "\n2. HTTP 方法和路径:"
grep -Po '"\K[A-Z]+ .*?(?= HTTP)' access.logecho -e "\n3. 查询参数:"
grep -Po 'GET /.*?\K\?.*?(?= HTTP)' access.logecho -e "\n4. User-Agent:"
grep -Po '"\K[^"]*?(?="$)' access.log | tail -n +2 | sed -n 'p;n'Shell程序效果截图
五、常用文本处理命令
1、grep
grep是Global search Regular Expression and Print out the line的简称,即全面搜索正则表达式并把行打印出来。
grep(egrep):用来在文本文件里查一个特定的字符串。
egrep用的是扩展的正则表达式。
grep [选项] [模式] [文件…]
grep options "正则表达式" filenames
options:-n 显示行号-E egrep用的是扩展的正则表达式-i ignore 在字符串比较时忽略大小写-c count 打印每个文件里匹配行的个数--color=always 高亮显示 --color=never 不高亮显示--color=auto 自动-H 显示文件名-h 不显示文件名注意:默认情况下,grep命令打印出包含模式的所有行,一旦加上-c选项,就只显示包含模式行的数量
grep -n -E --color=always -H "([0-9]{1,3}.){3}[0-9]{1,3}" 1.txt2、awk
AWK 是一种强大的文本处理语言,特别适合处理结构化文本数据(如日志文件、CSV 文件等)。它以行为单位处理文本,并支持字段分割、模式匹配、计算和格式化输出等功能。
awk:逐行读取文件,默认以 连续的空白字符(空格/制表符) 为分隔符将每行数据拆分为多个字段($1, $2...),然后可以对字段、整行($0)、行号(NR)等数据进行处理,支持计算、匹配、统计等操作。
awk options 'pattern {action}' filepattern:正则表达式或条件,用于匹配行
action:匹配后执行的操作(如 print、计算等)
file:输入文件(可省略,默认从 stdin 读取)
options:-F 指定分隔符-v 定义变量-f 从脚本读取命令-E 启用扩展正则--posix 启用 POSIX 正则基本匹配
awk '/正则表达式/' file
#示例
awk '/error/' log.txt # 打印包含 "error" 的行匹配特定字段
awk '$2 ~ /正则表达式/' file
#示例
awk '$3 ~ /^[0-9]+$/' data.txt # 第 3 列是数字的行反向匹配(不匹配)
awk '!/正则表达式/' file
#示例
awk '!/warning/' log.txt # 打印不包含 "warning" 的行3、sed
sed全称为Stream Editor,是一个强大的流式文本编辑器,用于对文本进行过滤和转换。它特别适合用于批量编辑文件或处理文本流。
sed [选项] '命令' 文件选项:控制 sed 的行为(如 -i 直接修改文件)
命令:指定对文本的操作(如替换 s/old/new/)
文件:输入文件(可省略,默认从 stdin 读取)选项:-n 静默模式(仅打印处理的行)-i 直接修改文件(慎用!)-E/-r 启用扩展正则-e 执行多条命令--debug 调试模式(GNU sed 支持)基本匹配
sed -n '/正则表达式/p' file
#示例
sed -n '/error/p' log.txt # 打印包含 "error" 的行替换(s///)
sed 's/正则表达式/替换内容/修饰符' file
#示例
sed 's/foo/bar/g' file # 全局替换 "foo" 为 "bar"
sed 's/[0-9]\+/NUM/g' file # 替换所有数字为 "NUM"(\+ 需转义)
sed -E 's/[0-9]+/NUM/g' file # 同上,但用扩展正则(\+ 无需转义)删除(d)
sed '/正则表达式/d' file
#示例
sed '/^#/d' file # 删除所有注释行(以 `#` 开头)
sed '/^$/d' file # 删除所有空行反向引用(\1, \2…)
sed 's/\(正则表达式\)/替换\1/' file
#示例
sed 's/\(foo\) bar/\1 baz/' file # "foo bar" → "foo baz"
sed -E 's/(foo) bar/\1 baz/' file # 扩展正则写法(括号无需转义)4、cut
cut 是一个简单但实用的文本处理工具,用于从文件或标准输入中提取文本的特定部分(如列或字符位置)。它特别适合处理结构化数据(如 CSV、TSV 或固定宽度的文本)。它 不支持正则表达式,但可以快速截取固定格式的字段。
把cut放进到本文中一起讲解,主要是给使用shell编程设计的大伙们,提供一个参考比对借鉴的工具。
cut [选项] [文件]选项 :指定如何截取文本(如按字符、字段等)。
文件 :输入文件(可省略,默认从 stdin 读取)选项 :-d 指定 分隔符(默认 TAB)-f 选择 字段(列)-c 选择字符位置-s 仅显示包含分隔符的行--complement 反选(排除指定列)按字段(列)提取
cut -d':' -f1,3 /etc/passwd
#示例输出
root:0
daemon:1
bin:2
...按字符位置提取
echo "abcdefgh" | cut -c2-5
#示例输出 (提取第 2~5 个字符)
bcde排除某些列
#(提取 data.csv 中 除了第 2 列 的所有列)
cut -d',' -f2 --complement data.csv处理 CSV 文件
#(先过滤含 "ERROR" 的行,再提取第 3 列)
cut -d',' -f1,3 employees.csv提取固定宽度的数据
#(提取第 1~10 和第 20~30 个字符)
cut -c1-10,20-30 data.txt结合 grep 过滤后提取
#(先过滤含 "ERROR" 的行,再提取第 3 列)
grep "ERROR" log.txt | cut -d' ' -f35、wc
wc(Word Count)是一个用于 统计文件或文本的行数、单词数、字符数 的简单工具,常用于日志分析、代码统计等场景。
wc [选项] [文件...]选项:控制统计的内容(如仅显示行数)。
文件:输入文件(可省略,默认从 stdin 读取)。
选项:-l 仅统计 行数(Line)-w 仅统计 单词数(Word)-c 仅统计 字节数(Byte)-m 仅统计 字符数(适用于 Unicode)-L 显示 最长行的长度无选项 显示 行数、单词数、字节数基础使用案例
#基本统计
wc file.txt
#输出结果
12 45 230 file.txt #12:行数;45:单词数(以空格分隔);230:字节数#仅统计行数
wc -l file.txt
#输出结果
12 file.txt#统计多个文件
wc *.txt
#输出结果
12 45 230 file1.txt
20 80 400 file2.txt
32 125 630 total#结合 grep 统计匹配行数
grep "ERROR" log.txt | wc -l #(统计 log.txt 中包含 "ERROR" 的行数)#统计代码行数
find . -name "*.py" -exec wc -l {} \; #(统计当前目录下所有 .py 文件的行数)6、sort
sort 是 Linux 中用于 对文本行进行排序 的强大工具,支持按字母、数字、月份等多种规则排序,并能去重、合并文件等。
sort [选项] [文件]选项:控制排序规则(如降序、按数字排序等)
文件:输入文件(可省略,默认从 stdin 读取)选项:-r 降序排序(默认升序)-n 按数字排序(默认按字符串)-k 指定排序的列-u 去重(仅保留唯一行)-f 忽略大小写-t 指定列分隔符-o 结果输出到文件-m 合并已排序的文件-c 检查文件是否已排序...基础使用案例
#1、基本排序(按字母升序)
sort fruit.txt
#输出结果
banana
apple
orange#2、按数字排序
sort -n numbers.txt
#numbers.txt文件输入:
10
2
45
#输出
2
10
45#3、按指定列排序
sort -t',' -k2 data.csv
#输入(data.csv):
Alice,25
Bob,30
Eve,20
#输出:
Eve,20
Alice,25
Bob,30#4、降序排序 + 去重
sort -r -u names.txt
#输入:
Alice
Bob
Alice
#输出:
Bob
Alice#5、检查文件是否已排序
#若已排序,无输出;未排序则报错。
sort -c file.txt#6、合并多个已排序文件
sort -m sorted1.txt sorted2.txt