在人工智能的浩瀚宇宙中,有一种神奇的生物,它拥有着强大的语言魔法,能够生成各种各样的文本,仿佛拥有无尽的创造力。它就是——Transformer 模型!Transformer 模型的出现,为人工智能领域带来了一场“语言魔法”的革命。它不仅让机器学会了“说话”,还为人类的生活带来了许多惊喜和便利。今天,就让我们踏上一场关于 Transformer 模型的奇幻之旅,去探索它背后的奥秘吧!
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
文章目录
- 🧠 向所有学习者致敬!
- 🌐 欢迎[点击加入AI人工智能社区](https://bbs.csdn.net/forums/b8786ecbbd20451bbd20268ed52c0aad?joinKey=bngoppzm57nz-0m89lk4op0-1-315248b33aafff0ea7b)!
- 引言:从标记到 Transformer 的文本生成之旅
- 第 0 步:设置 —— 库、语料库、标记化、超参数
- 第 0.1 步:导入库
- 第 0.2 步:定义训练语料库
- 第 0.3 步:字符级标记化
- 第 0.4 步:编码语料库
- 第 0.5 步:定义超参数
- 第 1 步:训练数据准备
- 第 1.1 步:创建输入(`x`)和目标(`y`)对
- 第 1.2 步:批处理策略(简化:随机采样)
- 第 2 步:模型组件初始化
- 第 2.1 步:标记嵌入层
- 第 2.2 步:位置编码矩阵
- 第 2.3 步:Transformer 块组件初始化
- 第 2.4 步:最终层初始化
- 第 3 步:定义正向传播(内联 —— 概念块)
- 第 3.1 步:输入嵌入 + 位置编码
- 第 3.2 步:Transformer 块循环(概念)
- 第 3.2.1 步:带掩码的多头自注意力(概念)
- 第 3.2.2 步:添加与归一化 1(第一次注意力后)(概念)
- 第 3.2.3 步:位置级前馈网络(FFN)(概念)
- 第 3.2.4 步:添加与归一化 2(第一次 FFN 后)(概念)
- 第 3.3 步:最终层(概念)
- 第 4 步:训练模型(内联循环)
- 第 4.1 步:定义损失函数
- 第 4.2 步:定义优化器
- 第 4.3 步:训练循环
- 第 5 步:文本生成(内联)
- 第 5.1 步:设置生成种子和参数
- 第 5.2 步:生成循环
- 第 5.3 步:解码生成序列
- 第 6 步:保存模型状态(可选)
- 第 7 步:总结
引言:从标记到 Transformer 的文本生成之旅
回顾:标记化的作用
之前我们研究了像字节对编码(BPE)这样的技术,文本处理的第一步就是标记化。这会把原始文本分解成便于管理的单元(标记)。在这个 notebook 里,为了简单起见,我们采用基本的字符级标记化,即文本中的每个独特字符都成为一个独立的标记。这些标记随后会被映射到独特的数字 ID 上。我们主要关注的是从这些 ID 序列中学习的模型:语言模型。
目标:构建生成型 Transformer
我们的目标是构建一个基于Transformer 架构的基本语言模型。具体来说,我们将构建一个类似 GPT 风格的仅解码器 Transformer。这个模型能够根据前面的标记来预测序列中的下一个标记(在我们这里就是字符)。通过反复预测下一个标记并将它重新输入到输入序列中,模型可以逐字符地生成新的文本序列。
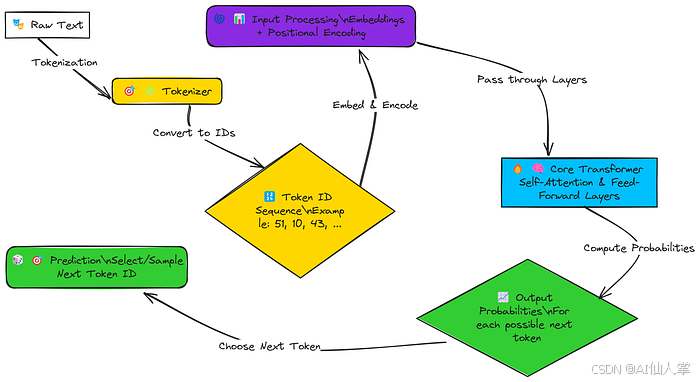
Transformer 架构:关键概念
Transformer 是在“Attention Is All You Need”(Vaswani 等人,2017 年)中提出的,它使用注意力机制来衡量在处理某个标记时不同输入标记的重要性,消除了 RNN/LSTM 中使用的递归需求。我们将要实现的关键组成部分如下:
- 输入嵌入:将数字标记(字符)ID 转换为密集的向量表示。
- 位置编码:向序列中添加关于标记位置的信息。
- 多头自注意力(带掩码):让模型能够关注序列中的前面标记以预测下一个标记。掩码防止关注未来的标记。
- 添加与归一化层:残差连接后跟层归一化,用于稳定训练。
- 逐位置前馈网络:独立地对每个标记表示应用非线性变换。
- 解码器块:多次堆叠这些组件。
- 最终线性层与 Softmax:将最终表示映射回词汇表得分(logits),然后再映射为概率。
本文的方法:
我们将逐步实现这个架构,直接在代码中操作,而不是定义函数或类。每个概念部分会被分解成最小的代码块,并附上极其详细的解释和数学公式(使用 LaTeX)。我们会使用一个小型文本数据集和模型配置,以确保透明度。
第 0 步:设置 —— 库、语料库、标记化、超参数
目标:通过导入 PyTorch,定义文本语料库,执行字符级标记化,设置模型配置(超参数)来准备环境。
第 0.1 步:导入库
解释:我们需要 torch 来进行张量操作、神经网络组件(nn)、激活函数(F)、优化器(optim),以及 math 来进行像注意力缩放中的平方根这样的计算。
# 导入必要的库
import torch
import torch.nn as nn
from torch.nn import functional as F
import torch.optim as optim
import math
import os# 为了可重复性(可选,但这是个好习惯)
torch.manual_seed(1337)print(f"PyTorch 版本:{torch.__version__}")
print("库已导入。")
第 0.2 步:定义训练语料库
解释:我们将使用《爱丽丝梦游仙境》的同一段摘录作为训练数据。这提供了一个小型但还算现实的文本来源。
# 定义用于训练的原始文本语料库
corpus_raw = """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain would be worth the trouble of getting up and
picking the daisies, when suddenly a White Rabbit with pink eyes ran
close by her.
"""print(f"训练语料库已定义(长度:{len(corpus_raw)} 个字符)。")
第 0.3 步:字符级标记化
解释:我们创建一个包含语料库中所有独特字符的词汇表。然后我们创建映射:一个是从每个字符到独特整数 ID(char_to_int)的映射,另一个是它的逆映射(int_to_char)。这个独特字符集的大小决定了我们的 vocab_size。
# 找出原始语料库中所有独特的字符
chars = sorted(list(set(corpus_raw)))
vocab_size = len(chars)# 创建字符到整数的映射(编码)
char_to_int = { ch:i for i,ch in enumerate(chars) }# 创建整数到字符的映射(解码)
int_to_char = { i:ch for i,ch in enumerate(chars) }print(f"创建了大小为:{vocab_size} 的字符词汇表")
print(f"词汇表:{''.join(chars)}")
# print(f"Char-to-Int 映射:{char_to_int}") # 可选
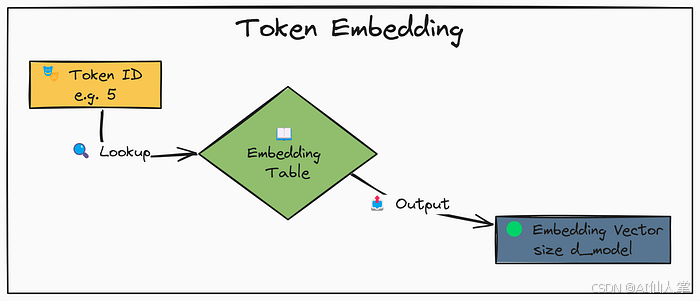
第 0.4 步:编码语料库
解释:使用 char_to_int 映射,将整个原始文本语料库转换为整数标记 ID 序列。这个数字序列就是模型将要处理的实际输入。
# 将整个语料库编码为整数 ID 列表
encoded_corpus = [char_to_int[ch] for ch in corpus_raw]# 将列表转换为 PyTorch 张量
full_data_sequence = torch.tensor(encoded_corpus, dtype=torch.long)print(f"将语料库编码为张量,形状为:{full_data_sequence.shape}")
# print(f"前 100 个编码的标记 ID:{full_data_sequence[:100].tolist()}") # 可选
第 0.5 步:定义超参数
解释:设置模型和训练的配置。我们使用从数据中确定的 vocab_size。其他值为了演示保持较小。
d_model:嵌入和内部表示的维度。n_heads:并行注意力计算的数量。n_layers:Transformer 块的数量。d_ff:前馈网络中的隐藏维度。block_size:一次处理的最大序列长度。learning_rate、batch_size、epochs:训练控制参数。device:如果可用,使用 GPU(‘cuda’),否则使用 CPU。
# 定义模型超参数(使用从数据中计算出的 vocab_size)
# vocab_size = vocab_size # 已经从数据中定义
d_model = 64 # 嵌入维度(对于字符稍微增加一点)
n_heads = 4 # 注意力头的数量
n_layers = 3 # Transformer 块的数量
d_ff = d_model * 4 # 前馈网络的内部维度
block_size = 32 # 最大上下文长度(序列长度)
# dropout_rate = 0.1 # 为了简单起见,省略了 dropout 层# 定义训练超参数
learning_rate = 3e-4 # 对于 AdamW,稍小的学习率通常更好
batch_size = 16 # 每步处理 16 个序列
epochs = 5000 # 对于字符级模型增加训练周期以观察学习效果
eval_interval = 500 # 多久打印一次损失# 设备配置
device = 'cuda' if torch.cuda.is_available() else 'cpu'# 确保 d_model 能被 n_heads 整除
assert d_model % n_heads == 0, "d_model 必须能被 n_heads 整除"
d_k = d_model // n_heads # 每个头的键/查询/值的维度print(f"超参数已定义:")
print(f" vocab_size: {vocab_size}")
print(f" d_model: {d_model}")
print(f" n_heads: {n_heads}")
print(f" d_k (每个头的维度): {d_k}")
print(f" n_layers: {n_layers}")
print(f" d_ff: {d_ff}")
print(f" block_size: {block_size}")
print(f" learning_rate: {learning_rate}")
print(f" batch_size: {batch_size}")
print(f" epochs: {epochs}")
print(f" 使用设备:{device}")
第 1 步:训练数据准备
目标:将编码后的数据(full_data_sequence)结构化为适合训练下一个标记预测任务的输入(x)和目标(y)对。
第 1.1 步:创建输入(x)和目标(y)对
解释:模型需要学习 P(token_i | token_0, ..., token_{i-1})。我们通过创建长度为 block_size 的序列来实现这一点。对于从 data[i : i+block_size] 取出的每个输入序列 x,相应的目标序列 y 是 x 中每个位置的下一个标记,即 data[i+1 : i+block_size+1]。我们从编码后的语料库中提取所有可能的重叠序列。
# 创建列表以保存所有可能的输入(x)和目标(y)序列,长度为 block_size
all_x = []
all_y = []# 遍历编码后的语料库张量以提取重叠序列
# 我们需要提前停止,以便我们总能获得相同长度的目标序列
num_total_tokens = len(full_data_sequence)
for i in range(num_total_tokens - block_size):# 提取长度为 block_size 的输入序列片段x_chunk = full_data_sequence[i : i + block_size]# 提取目标序列片段(向右移动一个位置)y_chunk = full_data_sequence[i + 1 : i + block_size + 1]# 将片段添加到我们的列表中all_x.append(x_chunk)all_y.append(y_chunk)# 将列表中的张量堆叠成单个大张量
# train_x 的形状为 (num_sequences, block_size)
# train_y 的形状为 (num_sequences, block_size)
train_x = torch.stack(all_x)
train_y = torch.stack(all_y)num_sequences_available = train_x.shape[0]
print(f"创建了 {num_sequences_available} 个重叠的输入/目标序列对。")
print(f"train_x 的形状:{train_x.shape}")
print(f"train_y 的形状:{train_y.shape}")# 可选:显示一个输入/目标对并解码它
# sample_idx = 0
# sample_x_ids = train_x[sample_idx].tolist()
# sample_y_ids = train_y[sample_idx].tolist()
# sample_x_chars = ''.join([int_to_char[id] for id in sample_x_ids])
# sample_y_chars = ''.join([int_to_char[id] for id in sample_y_ids])
# print(f"\n样本输入 x[{sample_idx}] ID:{sample_x_ids}")
# print(f"样本目标 y[{sample_idx}] ID:{sample_y_ids}")
# print(f"样本输入 x[{sample_idx}] 字符:'{sample_x_chars}'")
# print(f"样本目标 y[{sample_idx}] 字符:'{sample_y_chars}'")
第 1.2 步:批处理策略(简化:随机采样)
解释:为了避免实现复杂的数据加载器,对于每个训练步骤,我们只需简单地从可用序列(0 到 num_sequences_available - 1)中随机选择 batch_size 个索引。然后我们使用这些索引来获取对应的输入(xb)和目标(yb)序列,从 train_x 和 train_y 中。这模拟了从数据集中随机抽取批次。
# 检查我们是否有足够的序列来满足所需的批次大小
if num_sequences_available < batch_size:print(f"警告:序列数量({num_sequences_available})小于批次大小({batch_size})。调整批次大小。")batch_size = num_sequences_availableprint(f"数据已准备好用于训练。将随机抽取大小为 {batch_size} 的批次。")
第 2 步:模型组件初始化
目标:初始化 Transformer 模型所有层的可学习参数。每个层都被创建为 torch.nn 模块的一个实例,并移动到目标 device 上。
第 2.1 步:标记嵌入层
解释:将整数标记 ID(在我们这里是字符 ID)映射到密集向量。输入 (B, T) -> 输出 (B, T, C),其中 B=批次,T=时间/序列长度,C=d_model。
# 初始化标记嵌入表(查找表)
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)print(f"初始化了标记嵌入层(词汇表:{vocab_size},维度:{d_model})。设备:{device}")
第 2.2 步:位置编码矩阵
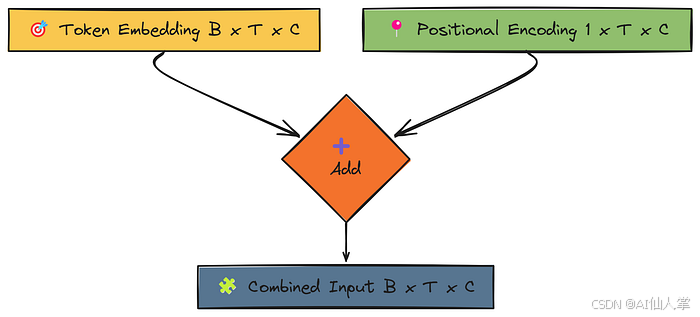
解释:使用正弦和余弦函数创建固定(非学习)向量来编码位置信息,频率各不相同。这个矩阵 (1, block_size, d_model) 将被添加到标记嵌入中。
公式如下:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d model ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i / d_{\text{model}}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d model ) PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i / d_{\text{model}}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
# 预计算正弦波位置编码矩阵
print("第 2.2 步:创建位置编码矩阵...")# 矩阵用于存储编码:形状为 (block_size, d_model)
positional_encoding = torch.zeros(block_size, d_model, device=device)# 位置索引(0 到 block_size-1):形状为 (block_size, 1)
position = torch.arange(0, block_size, dtype=torch.float, device=device).unsqueeze(1)# 维度索引(0, 2, 4, ...):形状为 (d_model/2)
div_term_indices = torch.arange(0, d_model, 2, dtype=torch.float, device=device)
# 分母项:1 / (10000^(2i / d_model))
div_term = torch.exp(div_term_indices * (-math.log(10000.0) / d_model))# 计算偶数维度的正弦值
positional_encoding[:, 0::2] = torch.sin(position * div_term)# 计算奇数维度的余弦值
positional_encoding[:, 1::2] = torch.cos(position * div_term)# 添加批次维度:形状为 (1, block_size, d_model)
positional_encoding = positional_encoding.unsqueeze(0)print(f" 位置编码矩阵已创建,形状为:{positional_encoding.shape}。设备:{device}")
第 2.3 步:Transformer 块组件初始化
解释:初始化 n_layers 解码器块所需的所有组件。我们将它们存储在 Python 列表中,索引对应于层号(0 到 n_layers-1)。
print(f"第 2.3 步:初始化 {n_layers} 个 Transformer 层的组件...")# 列表用于存储每层 Transformer 块的层
layer_norms_1 = [] # 第一次 MHA 后的层归一化
layer_norms_2 = [] # 第一次 FFN 后的层归一化
mha_qkv_linears = [] # QKV 投影的组合线性层
mha_output_linears = [] # MHA 的输出线性层
ffn_linear_1 = [] # FFN 中的第一个线性层
ffn_linear_2 = [] # FFN 中的第二个线性层# 遍历层数
for i in range(n_layers):# 第一次 MHA 后的层归一化ln1 = nn.LayerNorm(d_model).to(device)layer_norms_1.append(ln1)# 多头注意力:QKV 投影层qkv_linear = nn.Linear(d_model, 3 * d_model, bias=False).to(device) # 通常这里 bias=Falsemha_qkv_linears.append(qkv_linear)# 多头注意力:输出投影层output_linear = nn.Linear(d_model, d_model).to(device)mha_output_linears.append(output_linear)# 第一次 FFN 后的层归一化ln2 = nn.LayerNorm(d_model).to(device)layer_norms_2.append(ln2)# 位置级前馈网络:第一个线性层lin1 = nn.Linear(d_model, d_ff).to(device)ffn_linear_1.append(lin1)# 位置级前馈网络:第二个线性层lin2 = nn.Linear(d_ff, d_model).to(device)ffn_linear_2.append(lin2)print(f" 初始化了第 {i+1}/{n_layers} 层的组件。")print(f"已初始化 {n_layers} 层的组件。")
第 2.4 步:最终层初始化
解释:初始化最后一个块之后应用的最终层归一化和将 Transformer 输出映射回词汇表得分的最终线性层。
print("第 2.4 步:初始化最终层归一化和输出层...")# 最终层归一化
final_layer_norm = nn.LayerNorm(d_model).to(device)
print(f" 初始化了最终层归一化。设备:{device}")# 最终线性层(语言建模头)
output_linear_layer = nn.Linear(d_model, vocab_size).to(device)
print(f" 初始化了最终线性层(到词汇表大小 {vocab_size})。设备:{device}")
第 3 步:定义正向传播(内联 —— 概念块)
目标:详细说明构成 Transformer 正向传播的序列操作。这些概念块将在训练和生成循环中直接执行。
第 3.1 步:输入嵌入 + 位置编码
解释:将输入标记 ID (B, T) 转换为嵌入 (B, T, C) 并添加位置信息。输出 x 的形状为 (B, T, C)。
print("概念第 3.1 步已定义(嵌入 + 位置编码)。在循环中执行。")
第 3.2 步:Transformer 块循环(概念)
解释:概述在循环中迭代 n_layers 次的操作。
第 3.2.1 步:带掩码的多头自注意力(概念)
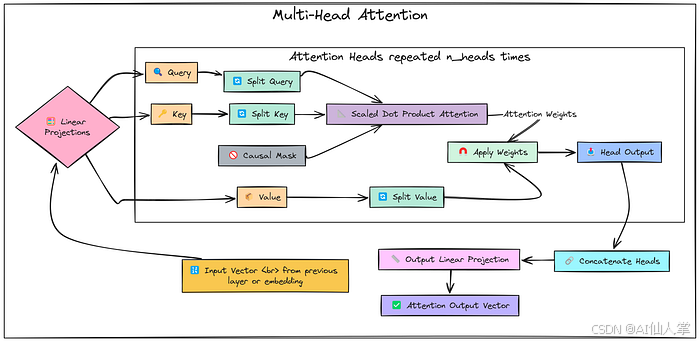
解释:允许每个标记关注前面的标记(包括自身)。
- 将输入
x(B, T, C)投影到 Q、K、V(B, n_heads, T, d_k)。 - 计算缩放点积注意力分数:
Attention ( Q , K , V ) = softmax ( Q K T d k + M ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V Attention(Q,K,V)=softmax(dkQKT+M)V
其中 (M) 是因果掩码(将上三角部分设置为 (-\infty))。 - 将头连接起来并投影回
(B, T, C)。
print("概念第 3.2.1 步已定义(多头注意力)。在层循环中执行。")
第 3.2.2 步:添加与归一化 1(第一次注意力后)(概念)
解释:残差连接(x + AttentionOutput)后跟层归一化。
LayerNorm ( x ) = γ x − μ σ 2 + ϵ + β \text{LayerNorm}(x) = \gamma \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta LayerNorm(x)=γσ2+ϵx−μ+β
其中 (\mu, \sigma^2) 是特征维度 (C) 上的均值/方差,而 (\gamma, \beta) 是可学习的缩放/偏移量。
print("概念第 3.2.2 步已定义(添加与归一化 1)。在层循环中执行。")
第 3.2.3 步:位置级前馈网络(FFN)(概念)
解释:在每个位置 (t) 独立应用两次线性变换,中间有一个非线性激活(ReLU)。
FFN ( x ) = Linear 2 ( ReLU ( Linear 1 ( x ) ) ) \text{FFN}(x) = \text{Linear}_2(\text{ReLU}(\text{Linear}_1(x))) FFN(x)=Linear2(ReLU(Linear1(x)))
print("概念第 3.2.3 步已定义(前馈网络)。在层循环中执行。")
第 3.2.4 步:添加与归一化 2(第一次 FFN 后)(概念)
解释:第二次残差连接(Norm1Output + FFNOutput)后跟层归一化。这个输出成为下一层的输入 x。
print("概念第 3.2.4 步已定义(添加与归一化 2)。在层循环中执行。")
第 3.3 步:最终层(概念)
解释:对最后一个块的输出应用最终层归一化,然后将其投影到词汇表得分 (B, T, V)。
print("概念第 3.3 步已定义(最终层)。在层循环之后执行。")
第 4 步:训练模型(内联循环)
目标:迭代调整模型参数以最小化预测误差(损失)。
第 4.1 步:定义损失函数
解释:使用交叉熵损失函数,适用于多类分类(预测下一个字符 ID)。它需要 logits (N, V) 和目标 (N)。我们将 (B, T, V) 重塑为 (B*T, V),(B, T) 重塑为 (B*T)。
# 定义损失函数
criterion = nn.CrossEntropyLoss()print(f"第 4.1 步:已定义损失函数:{type(criterion).__name__}")
第 4.2 步:定义优化器
解释:使用 AdamW 优化器。将所有初始化层的可学习参数收集到一个列表中,供优化器管理。
# 收集所有需要梯度的模型参数
all_model_parameters = list(token_embedding_table.parameters())
for i in range(n_layers):all_model_parameters.extend(list(layer_norms_1[i].parameters()))all_model_parameters.extend(list(mha_qkv_linears[i].parameters()))all_model_parameters.extend(list(mha_output_linears[i].parameters()))all_model_parameters.extend(list(layer_norms_2[i].parameters()))all_model_parameters.extend(list(ffn_linear_1[i].parameters()))all_model_parameters.extend(list(ffn_linear_2[i].parameters()))
all_model_parameters.extend(list(final_layer_norm.parameters()))
all_model_parameters.extend(list(output_linear_layer.parameters()))# 定义 AdamW 优化器
optimizer = optim.AdamW(all_model_parameters, lr=learning_rate)print(f"第 4.2 步:已定义优化器:{type(optimizer).__name__}")
print(f" 管理 {len(all_model_parameters)} 个参数组/张量。")# 在循环外部创建自注意力的下三角掩码
# 形状:(1, 1, block_size, block_size)
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)
第 4.3 步:训练循环
解释:迭代 epochs 次。在每一步中:选择批次,执行正向传播(执行概念步骤 3.1-3.3),计算损失,清零梯度,反向传播,更新权重。
print(f"\n第 4.3 步:开始 {epochs} 个周期的训练循环...")# 列表用于记录损失
losses = []# 将层设置为训练模式(例如,对于可能的 dropout,尽管这里省略了)
# 这在没有 dropout/batchnorm 的情况下实际上什么也不做,但这是个好习惯
for i in range(n_layers):layer_norms_1[i].train()mha_qkv_linears[i].train()mha_output_linears[i].train()layer_norms_2[i].train()ffn_linear_1[i].train()ffn_linear_2[i].train()
final_layer_norm.train()
output_linear_layer.train()
token_embedding_table.train()# 训练循环
for epoch in range(epochs):# --- 1. 批次选择 ---indices = torch.randint(0, num_sequences_available, (batch_size,))xb = train_x[indices].to(device) # 输入批次形状:(B, T)yb = train_y[indices].to(device) # 目标批次形状:(B, T)# --- 2. 正向传播(内联执行)---B, T = xb.shape # B = batch_size, T = block_sizeC = d_model # 嵌入维度# 第 3.1 步:嵌入 + 位置编码token_embed = token_embedding_table(xb) # (B, T, C)pos_enc_slice = positional_encoding[:, :T, :] # (1, T, C)x = token_embed + pos_enc_slice # (B, T, C)# 第 3.2 步:Transformer 块for i in range(n_layers):# 这个块的输入x_input_block = x # --- MHA ---# 在 MHA 之前应用层归一化(预归一化变体 —— 常见)x_ln1 = layer_norms_1[i](x_input_block)# QKV 投影qkv = mha_qkv_linears[i](x_ln1) # (B, T, 3*C)# 分割头qkv = qkv.view(B, T, n_heads, 3 * d_k).permute(0, 2, 1, 3) # (B, n_heads, T, 3*d_k)q, k, v = qkv.chunk(3, dim=-1) # (B, n_heads, T, d_k)# 缩放点积注意力attn_scores = (q @ k.transpose(-2, -1)) * (d_k ** -0.5) # (B, n_heads, T, T)# 应用因果掩码(使用预先计算的掩码,切片到 T)attn_scores_masked = attn_scores.masked_fill(causal_mask[:,:,:T,:T] == 0, float('-inf'))attention_weights = F.softmax(attn_scores_masked, dim=-1) # (B, n_heads, T, T)# 注意力输出attn_output = attention_weights @ v # (B, n_heads, T, d_k)# 连接头attn_output = attn_output.permute(0, 2, 1, 3).contiguous().view(B, T, C) # (B, T, C)# 输出投影mha_result = mha_output_linears[i](attn_output) # (B, T, C)# 添加与归一化 1(残差连接将输出添加到原始输入)x = x_input_block + mha_result # 残差连接 1# 注意:我们将 LN1 移到 MHA *之前*(预归一化)# --- FFN ---# FFN 的输入x_input_ffn = x # 在 FFN 之前应用层归一化(预归一化变体)x_ln2 = layer_norms_2[i](x_input_ffn)# FFN 层ffn_hidden = ffn_linear_1[i](x_ln2) # (B, T, d_ff)ffn_activated = F.relu(ffn_hidden)ffn_output = ffn_linear_2[i](ffn_activated) # (B, T, C)# 添加与归一化 2(残差连接将输出添加到 FFN 输入)x = x_input_ffn + ffn_output # 残差连接 2# 注意:我们将 LN2 移到 *FFN 之前*(预归一化)# 这个块的输出 'x' 成为下一个块的输入 'x_input_block'# 第 3.3 步:最终层(循环之后)# 应用最终层归一化(预归一化风格,应用于最终投影之前)final_norm_output = final_layer_norm(x) # (B, T, C)logits = output_linear_layer(final_norm_output) # (B, T, vocab_size)# --- 3. 计算损失 ---B_loss, T_loss, V_loss = logits.shapelogits_for_loss = logits.view(B_loss * T_loss, V_loss) targets_for_loss = yb.view(B_loss * T_loss)loss = criterion(logits_for_loss, targets_for_loss)# --- 4. 清零梯度 ---optimizer.zero_grad()# --- 5. 反向传播 ---loss.backward()# --- 6. 更新参数 ---optimizer.step()# --- 日志记录 ---current_loss = loss.item()losses.append(current_loss)if epoch % eval_interval == 0 or epoch == epochs - 1:print(f" 第 {epoch+1}/{epochs} 个周期,损失:{current_loss:.4f}")print("--- 训练循环已完成 ---")
第 5 步:文本生成(内联)
目标:使用训练好的模型参数逐字符生成新文本,从种子上下文开始。
第 5.1 步:设置生成种子和参数
解释:定义生成的起始字符,并指定要生成多少个字符。我们将种子字符(在这里是 ‘t’)转换为其标记 ID。
print("\n--- 第 5 步:文本生成 ---")# 种子字符
seed_chars = "t"
# 将种子字符转换为标记 ID
seed_ids = [char_to_int[ch] for ch in seed_chars]# 创建初始上下文张量
# 形状:(1, len(seed_ids)) -> 批次维度 = 1
generated_sequence = torch.tensor([seed_ids], dtype=torch.long, device=device)
print(f"初始种子序列:'{seed_chars}' -> {generated_sequence.tolist()}")# 定义要生成的新标记(字符)数量
num_tokens_to_generate = 200
print(f"将生成 {num_tokens_to_generate} 个新标记...")
第 5.2 步:生成循环
解释:迭代 num_tokens_to_generate 次。在每次迭代中:
- 准备当前上下文(最后
block_size个标记)。 - 使用 已训练 的模型参数执行正向传播(在评估模式下 —— 使用
torch.no_grad()禁用梯度计算以提高效率)。 - 获取 最后一个 时间步的 logits。
- 应用 softmax 获得概率。
- 根据概率采样下一个标记 ID。
- 将新的标记 ID 添加到
generated_sequence中。
# 将层设置为评估模式(如果使用了 dropout/batchnorm,这很重要)
# 这会禁用 dropout。我们手动进行,因为没有使用 nn.Module 类。
for i in range(n_layers):layer_norms_1[i].eval()mha_qkv_linears[i].eval()mha_output_linears[i].eval()layer_norms_2[i].eval()ffn_linear_1[i].eval()ffn_linear_2[i].eval()
final_layer_norm.eval()
output_linear_layer.eval()
token_embedding_table.eval()# 禁用生成时的梯度计算
with torch.no_grad():# 循环生成标记for _ in range(num_tokens_to_generate):# --- 1. 准备输入上下文 ---# 取最后 block_size 个标记作为上下文current_context = generated_sequence[:, -block_size:] # 形状:(1, min(current_len, block_size))B_gen, T_gen = current_context.shape C_gen = d_model# --- 2. 正向传播 ---# 嵌入 + 位置编码token_embed_gen = token_embedding_table(current_context) # (B_gen, T_gen, C_gen)pos_enc_slice_gen = positional_encoding[:, :T_gen, :] x_gen = token_embed_gen + pos_enc_slice_gen # (B_gen, T_gen, C_gen)# Transformer 块for i in range(n_layers):x_input_block_gen = x_gen# 预归一化 MHAx_ln1_gen = layer_norms_1[i](x_input_block_gen)qkv_gen = mha_qkv_linears[i](x_ln1_gen)qkv_gen = qkv_gen.view(B_gen, T_gen, n_heads, 3 * d_k).permute(0, 2, 1, 3)q_gen, k_gen, v_gen = qkv_gen.chunk(3, dim=-1)attn_scores_gen = (q_gen @ k_gen.transpose(-2, -1)) * (d_k ** -0.5)# 使用预先计算的掩码,切片到当前上下文长度 T_genattn_scores_masked_gen = attn_scores_gen.masked_fill(causal_mask[:,:,:T_gen,:T_gen] == 0, float('-inf'))attention_weights_gen = F.softmax(attn_scores_masked_gen, dim=-1)attn_output_gen = attention_weights_gen @ v_genattn_output_gen = attn_output_gen.permute(0, 2, 1, 3).contiguous().view(B_gen, T_gen, C_gen)mha_result_gen = mha_output_linears[i](attn_output_gen)x_gen = x_input_block_gen + mha_result_gen # 残差 1# 预归一化 FFNx_input_ffn_gen = x_genx_ln2_gen = layer_norms_2[i](x_input_ffn_gen)ffn_hidden_gen = ffn_linear_1[i](x_ln2_gen)ffn_activated_gen = F.relu(ffn_hidden_gen)ffn_output_gen = ffn_linear_2[i](ffn_activated_gen)x_gen = x_input_ffn_gen + ffn_output_gen # 残差 2# 最终层final_norm_output_gen = final_layer_norm(x_gen)logits_gen = output_linear_layer(final_norm_output_gen) # (B_gen, T_gen, vocab_size)# --- 3. 获取最后一个时间步的 logits ---logits_last_token = logits_gen[:, -1, :] # 形状:(B_gen, vocab_size)# --- 4. 应用 softmax ---probs = F.softmax(logits_last_token, dim=-1) # 形状:(B_gen, vocab_size)# --- 5. 采样下一个标记 ---next_token = torch.multinomial(probs, num_samples=1) # 形状:(B_gen, 1)# --- 6. 添加采样标记 ---generated_sequence = torch.cat((generated_sequence, next_token), dim=1)print("\n--- 生成完成 ---")
第 5.3 步:解码生成序列
解释:使用 int_to_char 映射将生成的标记 ID 序列转换回人类可读的字符。
# 获取第一个(也是唯一一个)批次项的生成序列
final_generated_ids = generated_sequence[0].tolist()# 将 ID 列表解码回字符串
decoded_text = ''.join([int_to_char[id] for id in final_generated_ids])print(f"\n最终生成的文本(包括种子):")
print(decoded_text)
第 6 步:保存模型状态(可选)
由于我们的 Transformer 模型是以内联方式实现的,使用的是单独的组件变量,而不是 PyTorch nn.Module,因此我们需要手动将所有参数收集到一个状态字典中,然后才能保存。
# 创建一个目录来保存模型(如果它不存在)
os.makedirs('saved_models', exist_ok=True)# 创建一个状态字典来保存所有模型参数
state_dict = {'token_embedding_table': token_embedding_table.state_dict(),'positional_encoding': positional_encoding, # 这不是一个参数,只是一个张量'layer_norms_1': [ln.state_dict() for ln in layer_norms_1],'mha_qkv_linears': [linear.state_dict() for linear in mha_qkv_linears],'mha_output_linears': [linear.state_dict() for linear in mha_output_linears],'layer_norms_2': [ln.state_dict() for ln in layer_norms_2],'ffn_linear_1': [linear.state_dict() for linear in ffn_linear_1],'ffn_linear_2': [linear.state_dict() for linear in ffn_linear_2],'final_layer_norm': final_layer_norm.state_dict(),'output_linear_layer': output_linear_layer.state_dict(),# 保存超参数以重建模型'config': {'vocab_size': vocab_size,'d_model': d_model,'n_heads': n_heads,'n_layers': n_layers,'d_ff': d_ff,'block_size': block_size},# 保存分词器信息以便文本生成'tokenizer': {'char_to_int': char_to_int,'int_to_char': int_to_char}
}# 保存状态字典
torch.save(state_dict, 'saved_models/transformer_model.pt')
print("模型已成功保存到 'saved_models/transformer_model.pt'")
要稍后加载模型,可以这样做:
# 加载保存的状态字典
loaded_state_dict = torch.load('saved_models/transformer_model.pt', map_location=device)# 提取配置和分词器信息
config = loaded_state_dict['config']
vocab_size = config['vocab_size']
d_model = config['d_model']
n_heads = config['n_heads']
n_layers = config['n_layers']
d_ff = config['d_ff']
block_size = config['block_size']
d_k = d_model // n_headschar_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']# 重新创建模型组件
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
token_embedding_table.load_state_dict(loaded_state_dict['token_embedding_table'])positional_encoding = loaded_state_dict['positional_encoding'].to(device)# 初始化层列表
layer_norms_1 = []
mha_qkv_linears = []
mha_output_linears = []
layer_norms_2 = []
ffn_linear_1 = []
ffn_linear_2 = []# 加载每层的组件
for i in range(n_layers):# 层归一化 1ln1 = nn.LayerNorm(d_model).to(device)ln1.load_state_dict(loaded_state_dict['layer_norms_1'][i])layer_norms_1.append(ln1)# MHA QKV 线性qkv_linear = nn.Linear(d_model, 3 * d_model, bias=False).to(device)qkv_linear.load_state_dict(loaded_state_dict['mha_qkv_linears'][i])mha_qkv_linears.append(qkv_linear)# MHA 输出线性output_linear = nn.Linear(d_model, d_model).to(device)output_linear.load_state_dict(loaded_state_dict['mha_output_linears'][i])mha_output_linears.append(output_linear)# 层归一化 2ln2 = nn.LayerNorm(d_model).to(device)ln2.load_state_dict(loaded_state_dict['layer_norms_2'][i])layer_norms_2.append(ln2)# FFN 线性 1lin1 = nn.Linear(d_model, d_ff).to(device)lin1.load_state_dict(loaded_state_dict['ffn_linear_1'][i])ffn_linear_1.append(lin1)# FFN 线性 2lin2 = nn.Linear(d_ff, d_model).to(device)lin2.load_state_dict(loaded_state_dict['ffn_linear_2'][i])ffn_linear_2.append(lin2)# 最终层归一化
final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_state_dict['final_layer_norm'])# 输出线性层
output_linear_layer = nn.Linear(d_model, vocab_size).to(device)
output_linear_layer.load_state_dict(loaded_state_dict['output_linear_layer'])print("模型已成功加载!")
第 7 步:总结
这个 notebook 提供了一个字符级仅解码器 Transformer 语言模型的极其详细的逐步内联实现。通过避免使用函数和类,我们展示了训练和文本生成中涉及的粒度操作。
我们涵盖了以下内容:
- 设置与分词:准备环境,定义文本语料库,执行字符级分词(创建字符映射并编码语料库),设置超参数。
- 数据准备:将编码后的语料库结构化为输入/目标对,用于下一个标记预测。
- 模型初始化:创建所有必要的
torch.nn层(嵌入、线性层、层归一化)的实例,并预先计算位置编码。 - 正向传播(内联):详细说明并执行从嵌入、位置编码、多个 Transformer 块(带掩码的多头自注意力和前馈网络,包括残差连接和层归一化 —— 使用预归一化结构)到最终输出层的流程。
- 训练:实现训练循环,包括批次采样、正向传播执行、交叉熵损失计算、反向传播以及通过 AdamW 优化器更新参数。
- 文本生成:通过从种子开始,迭代执行正向传播(在
torch.no_grad()内),根据输出概率采样下一个标记,并将其添加到序列中,最终将生成的 ID 解码回文本,展示了自回归生成过程。
虽然非常冗长,但这种方法清晰地展示了 Transformer LM 中的基本机制和数据流。实际应用中,人们会大量使用函数和类来提高模块化、可重用性和可读性,但这种内联方法作为一个详细的教育分解示例还是很有价值的。