前言
欢迎来到我的博客
个人主页:北岭敲键盘的荒漠猫-CSDN博客

本文主要整理前端js代码的打点思路
本文只为学习安全使用,切勿用于非法用途。
一切未授权的渗透行为都是违法的。

前端js打点概念与目的
javascript文件属于前端语言,也就是说他的代码都是在前端可见的。通过观察js文件,我们可以从中获取一些网址,接口地址,源码,加密逻辑等信息。
js打点主要面向于核心代码是js写的站点。这类站点的用户信息处理大部分用的js。从js中可以获取到更多的信息。
判断目标网站是否为js网站
插件wappalyzer
源程序代码简短
引入多个js文件
一般有/static/js/app.js等顺序的js文件
一般cookie中有connect.sid
手工js打点
注释信息泄露
我们查看我们响应的数据包即可。
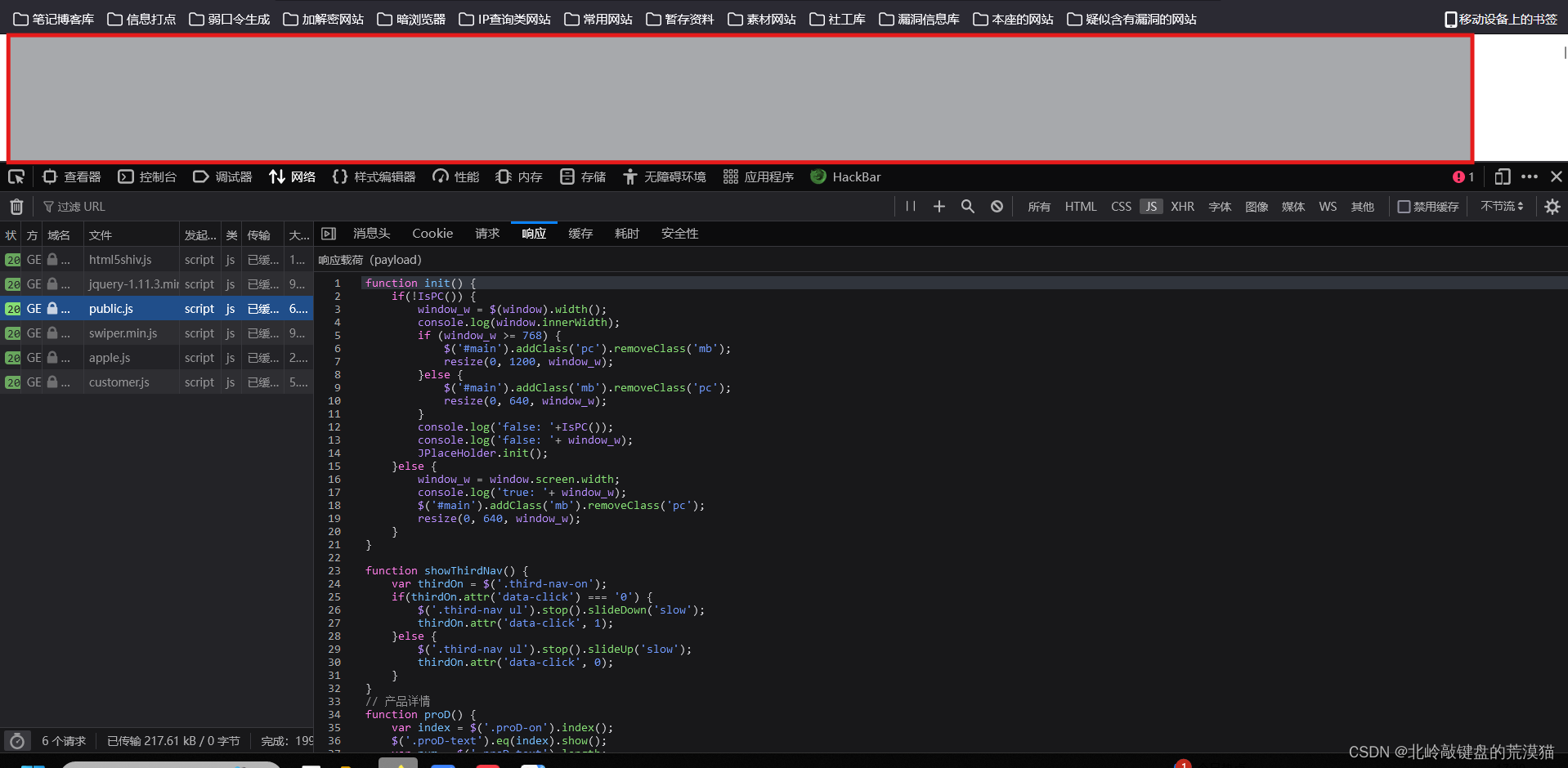
用开发者工具进行搜索信息。
这里注意我们可以看到他的注释也是一模一样的反馈给我们的。
这也就是说,如果用一些源码,源码会有版权,而很有可能就会写在这些文件里。
不禁是源码,QQ,甚至一些接口,都会直接的写!
而我们可以根据QQ来找作者进而找源码,或者直接拿源码,判断cms,搜cms的漏洞。
从黑盒转化为白盒。
这个就是我找的一个,看他的代码末端。

再如下面的这个:


不只是这些,还有一个我搜过的网站是把自己的接口整理到里面了。包括了一些支付接口,但是找不到那个站点了。
搜索正文价值信息
运用搜索的功能进行搜索关键字
关键字:
src=
path=
method:"get"
http.get("
method:"post"
http.post("
$.ajax
http://service.httppost
http://service.httpget利用这些连接关键词可以找一些价值信息。

说不定就找到了一个本来不应该能直接访问的未授权访问漏洞。
半自动工具打点
burp半自动
burp里面有官方插件js link finder这些搜集js的插件。
插件也比较简单,我就不多赘述了。
因为我习惯使用yakit,所以这里我介绍yakit帮助信息收集的插件。
yakit半自动
使用js-api插件。

直接输入目标地址跑就行了。
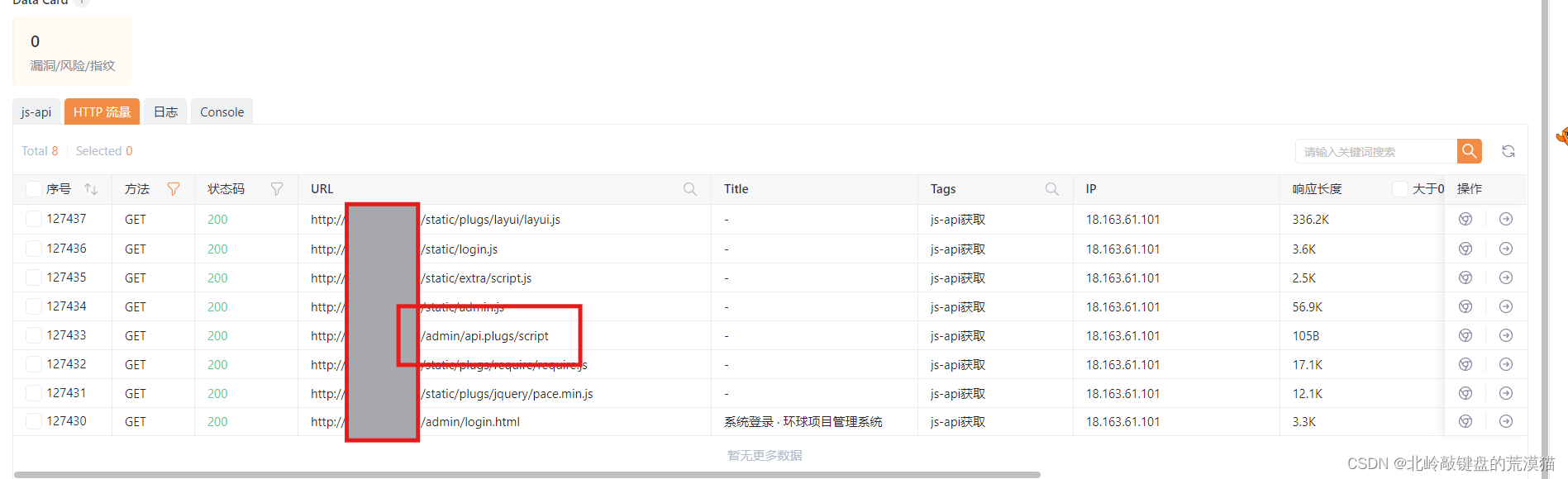
根据js返回链接。
我们也可以直接输入网址自己看js源码。
确实抓取了重要信息。

使用jsfind插件

用法一样用。
全自动打点
不演示了,跟着命令行输入就行。
ulrfind插件打点
下载地址:GitHub - pingc0y/URLFinder: 一款快速、全面、易用的页面信息提取工具,可快速发现和提取页面中的JS、URL和敏感信息。
使用方法:
显示全部状态码
URLFinder.exe -u http://www.baidu.com -s all -m 3显示200和403状态码
URLFinder.exe -u http://www.baidu.com -s 200,403 -m 3结果分开保存
导出全部
URLFinder.exe -s all -m 3 -f url.txt -o .
只导出html
URLFinder.exe -s all -m 3 -f url.txt -o res.html结果统一保存
URLFinder.exe -s all -m 3 -ff url.txt -o .-a 自定义user-agent请求头
-b 自定义baseurl路径
-c 请求添加cookie
-d 指定获取的域名,支持正则表达式
-f 批量url抓取,需指定url文本路径
-ff 与-f区别:全部抓取的数据,视为同一个url的结果来处理(只打印一份结果 | 只会输出一份结果)
-h 帮助信息
-i 加载yaml配置文件,可自定义请求头、抓取规则等(不存在时,会在当前目录创建一个默认yaml配置文件)
-m 抓取模式:1 正常抓取(默认)2 深入抓取 (URL深入一层 JS深入三层 防止抓偏)3 安全深入抓取(过滤delete,remove等敏感路由)
-max 最大抓取数
-o 结果导出到csv、json、html文件,需指定导出文件目录(.代表当前目录)
-s 显示指定状态码,all为显示全部
-t 设置线程数(默认50)
-time 设置超时时间(默认5,单位秒)
-u 目标URL
-x 设置代理,格式: http://username:password@127.0.0.1:8877
-z 提取所有目录对404链接进行fuzz(只对主域名下的链接生效,需要与 -s 一起使用) 1 目录递减fuzz 2 2级目录组合fuzz3 3级目录组合fuzz(适合少量链接使用)插件打点
挖掘更多js文件
我们访问js文件的时候,不会一次性访问所有的js文件。
就比如说,我们登录后跟登录前就会多访问一些js。
但是js是可以直接访问的,那么我们就可以fuzz直接爆破js文件。
ffuf-FUZZ爆破
GitHub - ffuf/ffuf: Fast web fuzzer written in Go
ffuf.exe -w 字典 -u 网址/FUZZ -t 线程数
fuzz是告诉程序在fuzz处进行爆破。
webpack打包器信息打点
webpack打包器简介
他是javascript代码打包器,用于打包javascript代码,所以,网站如果是使用了webpack打包,那么我们就能通过这种方法进行打点。
但是网站没有使用webpack,那么就不能使用这种方法。
使用工具
Packer-Fuzzer工具:
GitHub - rtcatc/Packer-Fuzzer: Packer Fuzzer is a fast and efficient scanner for security detection of websites constructed by javascript module bundler such as Webpack.
安装的时候记得安装一下依赖环境。
pip3 install -r requirements.txt
使用指令:
PackerFuzzer.py -u 网址
结果会返回在repo的一个网页中。
总结
挖掘目标
1.从返回的已知js中提取信息。
2.用fuzz爆破出未知的js信息
3.从框架中提取js信息。