Nat. Rev. Drug Discov. | 计算驱动的药物再定位研究:策略、工具评测与典型案例分析
已有药物的新适应症开发因其可加速药物研发、降低成本而备受关注。针对药物再定位,研究人员已开发数百种可用于预测与筛选的计算资源(如数据库与平台),但如何为具体项目选择合适工具仍具挑战。为解决这一问题,研究人员构建了一个用于药物再定位的本体体系,对现有计算资源进行分类梳理,并综述了各类计算方法。同时,研究人员还对部分代表性资源进行了专家评估,并结合Horizon Europe REMEDi4ALL项目中的三个实际案例,展示其在真实场景中的应用。本文通过系统综述、专家评价与案例分析,为药物再定位中计算资源的高效利用提供了指南,并为构建可持续、可拓展的药物再定位网络目录奠定基础。

引言
将已获批药物用于新的适应症,即药物再定位,是一种广泛应用的策略,可降低药物开发成本并满足尚未满足的临床需求,尤其是在缺乏治疗方案的罕见病领域。若实施得当,药物再定位可加速甚至跳过部分研发阶段,显著提高研发效率并节约成本。典型成功案例包括用于脱发治疗的米诺地尔和从白血病转用于胃肠间质瘤治疗的伊马替尼。
与之密切相关的是药物再开发,即最初因疗效不足、副作用或非药理因素被搁置的候选药物,后续被重新用于新的疾病治疗。例如,西地那非最初用于心绞痛未果,后被用于勃起功能障碍;沙利度胺也从镇静剂转为多发性骨髓瘤治疗药物。此类例子显示出药物再定位在不同适应症和药物类型中的广泛适用性和巨大潜力。
尽管“再定位”“再开发”“药物救援”等术语存在交叉,研究人员在此统称为“药物再定位”,即将已在人类中测试过的药物用于新的或额外的适应症。例如,PD1/PDL1 抑制剂在多种癌症中的适应症拓展,TNF 抑制剂在多种自身免疫病中的应用等。需要注意的是,再定位不同于同一疾病不同阶段的适应症扩展,如达沙替尼由复发性慢性髓性白血病扩展用于初诊患者。
药物再定位可分为两类:一是原始作用机制适用于新适应症;二是发现新的作用机制后用于新的疾病。例如,索拉非尼由 RAF 抑制剂转为抗血管生成治疗,阿扎胞苷和地西他滨从细胞毒性核苷类似物转为 DNA 甲基转移酶抑制剂。
近年来,药物再定位研究数量持续增长,尤其在 COVID-19 疫情期间,诸如地塞米松、瑞德西韦、巴瑞替尼等药物被快速用于新适应症。此外,一些最初研发失败的药物,如用于精神分裂的 fezolinetant,也成功转用于治疗更年期潮热。
尽管约三成的 FDA 批准药物后续获得了新的适应症,但每次再定位仍需充分考虑新旧适应症的差异、药物的安全性、药代动力学等因素。例如,不同适应症的耐受性、给药方式和剂量可能均不同。此外,还需深入理解药物的作用机制、靶点及可能的药物相互作用,以优化治疗窗口。
当前,研究人员已开发出多种计算资源,支持药物再定位的验证工作,包括基因表达、功能通路、药物结构、靶点结合、细胞表型与临床结果等多维数据。同时,多种计算方法和工具被提出用于候选药物筛选与机制挖掘。已有学者对方法体系进行过分类,如按药物或疾病为起点的策略,也有研究将计算方法与生物学知识相结合,构建面向特定适应症的再定位流程。
然而,面对大量不断涌现的工具和数据库,研究人员很难全面了解其适用场景与优势。因此,建立系统的分类、评估标准及使用指南至关重要。作为 REMEDi4ALL 项目的一部分,研究人员系统梳理了181种计算资源,构建了用于分层分类的药物再定位本体,并据此总结了基于靶点与表型的再定位策略,评估了部分资源的实用性,并通过三个真实案例展示其应用,相关资源已整理为可持续、可扩展的在线目录。最后,研究人员讨论了药物再定位中的关键经验与未来挑战。
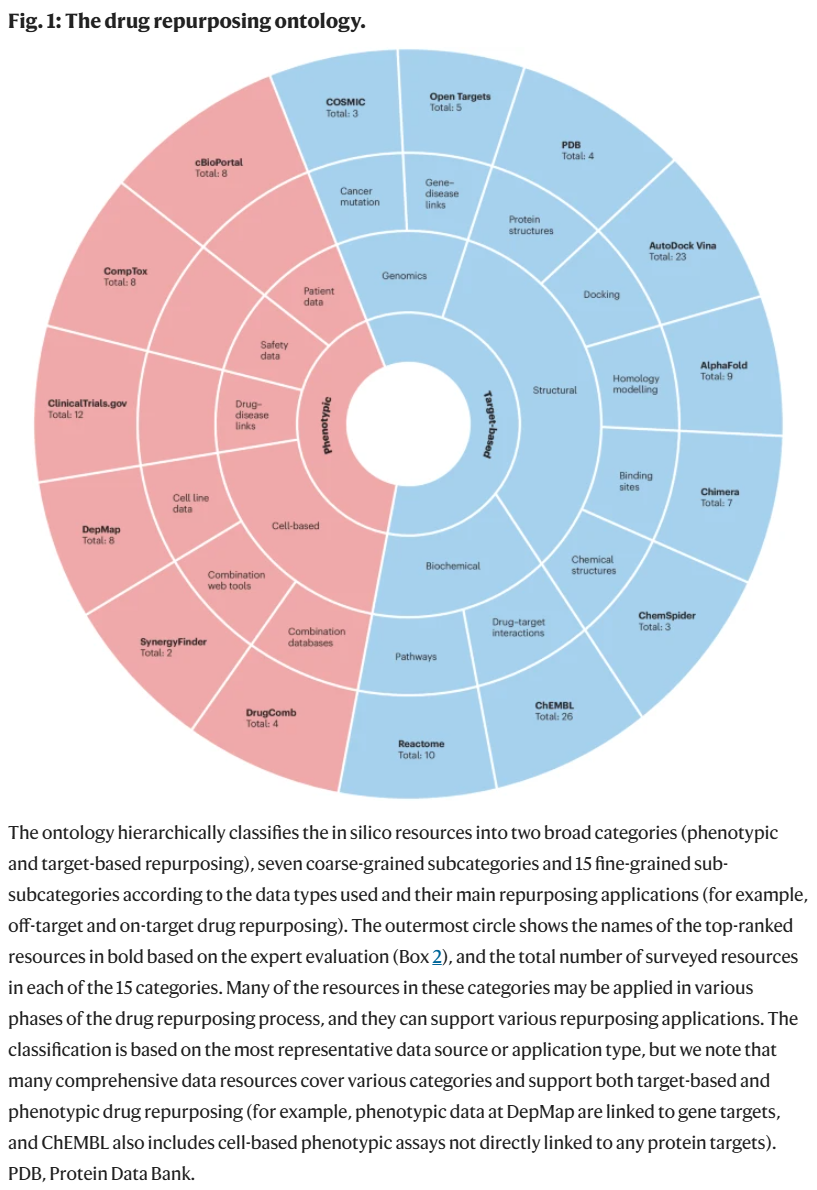
计算药物再定位方法概述
基于靶点的药物再定位方法
基因组学方法
人类基因组测序的初衷之一是识别与疾病相关的基因,并寻找针对性治疗方法。目前已有大量基因组变异数据可用于疾病机制解析,尤其是基因组关联研究(GWAS)数据。研究人员整合这些信息,通过链接疾病相关基因变异与药物靶点,加速药物再定位的发现。
例如,PharmGWAS 平台利用约2,000个GWAS和75万个药物诱导表达谱,挖掘可再定位药物及组合。此外,多个临床基因数据库(如ClinVar、ClinGen)汇集了大量与疾病相关的基因变异信息。gnomAD、DisGeNET等平台进一步提供全基因组/外显子组变异数据和基因-疾病关联,用于靶点筛选。
癌症领域尤为活跃,COSMIC 是目前最完整的癌症体细胞突变数据库,有助于识别具有治疗潜力的突变靶点。Open Targets 则融合了多组学信息,用于系统评估靶点与疾病的关联,覆盖肿瘤、罕见病、神经退行性疾病等多个领域。
结构生物学方法
分子对接技术可模拟药物与靶标的结合过程,是结构基础上的药物再定位核心方法之一。虚拟筛选通过评分函数筛选最可能结合的化合物;反向对接则用于寻找已有药物可能作用的新靶点。AlphaFold 等结构预测工具提升了无结构靶标的建模准确性。
常见对接软件包括 AutoDock、AutoDock Vina 和 Glide,配合可视化工具如 Chimera 和 PyMol,可实现高效筛选与结果解读。进一步的分子动力学模拟或结合机器学习、量子力学打分方法,有助于优化结合构象和亲和力预测。
生物化学方法
高通量筛选(HTS)技术可用于评估大规模药物与靶点的结合活性。相关数据已被系统收录于如 PubChem、ChEMBL 等数据库。ChEMBL 以手工整理提升数据质量,广泛用于小分子药物筛选。
此外,通路数据库如 Reactome、KEGG 也支持将基因变异与功能通路相连,用于药物机制研究。蛋白互作数据库(如STRING、IntAct)和基因表达签名数据库(如MSigDB)可进一步支持机制验证与靶点推断。
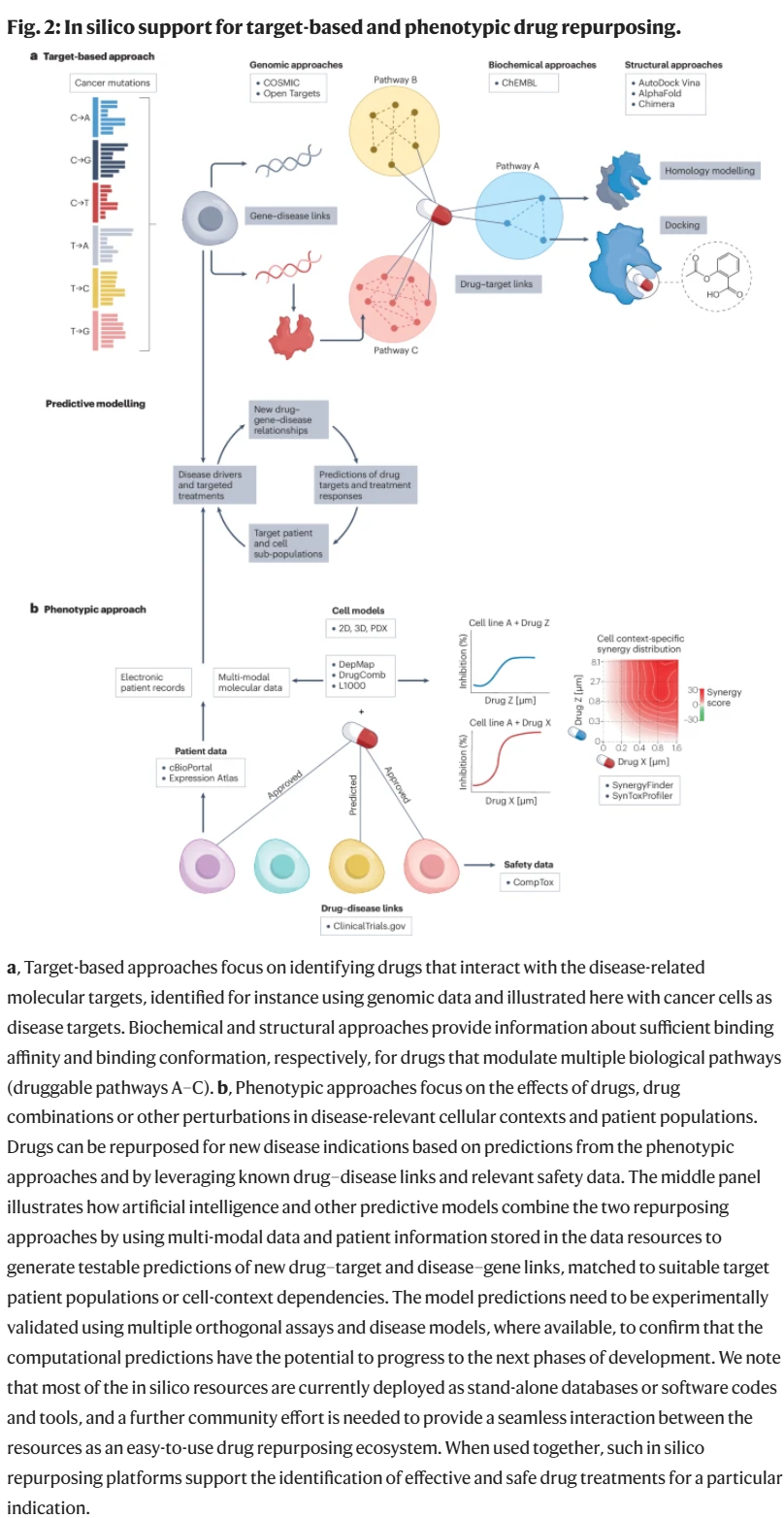
基于表型的药物再定位方法
细胞模型方法
基于细胞的表型筛选,如癌细胞系、类器官等,广泛用于药物作用的初步筛选。DepMap 是目前最权威的癌症依赖性图谱平台,系统整合了细胞系的遗传、转录、蛋白和药物反应数据。
PRISM 药物敏感性数据库提供了数千种药物的表型反应数据,便于识别具有特异性反应的细胞系。SynergyFinder 可用于分析药物组合的协同效应。
Connectivity Map(CMap)是另一个重要资源,收录了大量化合物处理后的基因表达签名。通过计算表达谱相似性,可识别具有类似机制或可逆转病理表型的候选药物。
药物-疾病关联数据
系统挖掘药物与疾病之间的关联信息,有助于发现再定位的候选分子。DrugCentral、CTD、DrugRepo 等数据库涵盖了药物的化学结构、生物活性、适应症、剂量、不良反应等信息。clinicaltrials.gov 提供全球临床试验的详细信息,是识别再定位应用和疗效评估的重要平台。
安全性评估方法
为了降低再定位过程中潜在的临床风险,研究人员需评估药物在新适应症下的安全性。SIDER、OnSIDES、DrugBank 等数据库汇集了不良反应、药物相互作用和毒性信息。CompTox、ClarityVista 等平台结合体内外毒理数据,为药物筛选提供决策支持。
患者数据的整合利用
癌症领域的 TCGA、cBioPortal 和 GENIE 项目整合了多组学数据与临床信息,为药物再定位提供了患者层级的实证支持。GTEx 提供了健康人群的组织特异性表达谱,是评估疾病选择性的重要参考。
此外,EHRs、国家级健康数据库(如 UK Biobank、FinnGen)和平台如 CURE ID、Danish Disease Trajectory Browser 也为基于真实世界数据的再定位提供了可能。
预测模型与人工智能方法
随着生物医学数据的大量积累,网络分析与机器学习(ML)模型已成为药物再定位的重要手段。ML 可从结构、安全性、PK/PD 等多模态数据中学习高阶特征,预测药物活性、毒性或疾病适应症。
资源如 Therapeutics Data Commons 和 MoleculeNet 提供标准化数据集与评价指标,用于算法训练与对比。新兴方法如 Drug2Cell、scTherapy 融合单细胞表达谱与药物信息,实现个体化、多靶点的药物筛选。
资源分类与专家评估
为构建药物再定位资源目录并开展专家评估,研究人员设计了一套分层的药物再定位本体体系,将计算资源划分为两个主类、七个子类和十五个应用层级子子类。基于调研,目录还补充了三个高层类别:预测方法、基于网页的预测工具、以及带图形界面的数据挖掘工具。其中后两类尤其适合缺乏编程能力或生物信息支持的科研人员;而预测方法类多为命令行工具,集成了高级机器学习或人工智能模型。每一类资源还附带了相关注释信息,包括应用场景、适应症支持范围、开放性指标等,已集成于在线目录中,便于持续更新和对比评估。
研究人员邀请来自 REMEDi4ALL 项目及外部的 27 位领域专家,对初筛的181项计算资源进行双轮评估,涵盖全部15个子类。专家在评估过程中补充了丰富的元数据,如是否开源、是否提供API、支持的疾病类型和再定位场景等。基于这些注释,研究人员对各类资源进行了评分和排序,并最终汇总为目录。
值得注意的是,此次评估并非覆盖所有已发表的计算资源,而是聚焦于当前公认的、具有代表性的、支持不同药物再定位应用的关键工具,作为构建目录与评估流程的起点。
在评估中得分最高的15个资源(11个数据库和4个网页工具)均为开源项目,其专家评分中位数达到8.5以上。这些资源中,10个数据库支持API,便于集成至本地再定位流程;其中11个资源(占73%)为疾病无关型,适用于多种适应症,其余4个主要聚焦于癌症或新冠肺炎。
当前这些顶级资源大多具备广泛适应性,除再定位外,也支持一般性药物研发流程。然而,在精准靶点筛选、表型机制挖掘等再定位流程的关键阶段,仍缺乏便捷、高效的工具,尤其在药物组合疗法的预测(如抗癌或抗病毒协同作用)方面,尚缺少对体内协同效应和安全性进行评估的易用计算平台。
此外,181个资源中,有161个(89%)为完全开放获取或代码开源;102个数据库中,有40个(39%)提供API。根据专家注释,50个资源主要服务于肿瘤研究(27%),12个用于特定非肿瘤适应症(如新冠),其余119个为广谱型工具(66%)。整体来看,面向靶点导向型再定位的资源数量比表型导向型高出约21%。
这些初步调研结果已作为在线目录的一部分发布,并将通过可持续的网页平台不断扩展和更新。该目录还支持用户提交反馈建议,修正资源统计和注释信息。为促进资源的使用,研究人员还提供了各类别中排名前列资源的GUI和API操作指南。
结论与未来方向
当前,药物再定位所需的机制信息和表型数据分散在大量数据库和预测平台中,信息覆盖范围、质量与可靠性参差不齐,给实际应用带来挑战。为应对这一问题,研究人员与 REMEDi4ALL 项目合作,对181项广泛使用的计算资源进行了系统评估。与以往侧重方法学不同,本次评估更强调资源的可访问性、可信度与互操作性,并为15个子类的高评分资源提供了详细的GUI与API使用指南,构建了首个可持续、可拓展的药物再定位资源在线目录。
该目录采用可扩展的本体结构,支持后续不断纳入新资源,并鼓励社区参与修正与补充注释内容。鉴于药物再定位资源不断增长,尤其是AI相关工具快速涌现,构建一个由社区驱动的共享型评估平台尤为重要,以维持目录的实时性与适用性。
评估还展示了多个成功案例,例如结合知识图谱、酶活性数据和转录响应数据识别了 vandetanib 与 everolimus 在儿童脑干胶质瘤中的协同作用,且已通过动物实验验证。也有如 celastrol 再定位为肥胖治疗药物的早期预测,历经多年才进入临床试验阶段。这表明再定位从计算预测到临床落地周期较长,但随着资源和流程的完善,未来将涌现更多成功案例。
在 REMEDi4ALL 的多个案例中,研究人员展示了如何结合药物作用数据、基因表达谱和患者级别信息来挖掘新机制、优化药物组合并降低临床风险。然而,当前公开数据库在化合物ID、靶点注释等方面仍存在不一致问题,亦缺乏对罕见不良反应的系统记录。若能打通这些信息孤岛,将显著提升计算预测的效能和可转化性。
当前AI驱动的预测方法日益丰富,但仍缺乏易用的网页平台和可视化界面,限制了它们在广泛研究群体中的推广。多数数据库未提供API,也不便于数据互通与集成使用。研究人员建议数据库维护者在官网明确标注关键统计信息,并通过目录的反馈通道持续更新。
新冠疫情加速了再定位研究的进展,但也暴露了预测模型数据质量不足、结果报告不规范等问题。SIDER 等常用不良反应数据库多年未更新,ClinicalTrials.gov 等平台也缺乏统一标识符,限制了跨平台数据整合。研究人员建议引入统一的化合物和疾病ID(如 PubChem ID、MeSH ID)以提升互通性。
在前沿技术方面,单细胞组学与空间转录组学正在成为新一代再定位工具,如使用患者细胞进行表型成像识别再定位候选药物的研究正在增加,已成功应用于急性白血病和胶质母细胞瘤的多药协同筛选中。
然而,患者级别的临床结局数据仍受隐私法规和数据共享激励机制不足等限制。如 OpenTargets 这类学术-产业合作平台的开放策略值得推广,可为再定位提供高质量的内部数据。与此同时,一些商业平台如 ClarityVista 虽集成了临床前及上市后药物安全性数据,但多以专有形式存在,限制了科研界的广泛使用。
药物再定位在药代动力学(PK)、药效动力学(PD)及靶点结合等方面也面临挑战。不同疾病状态下药物在体内的分布、作用机制和毒性反应可能完全不同,因此亟需针对PK/PD与靶点结合的专门计算资源和实验策略。
目前,药物再定位缺乏足够的商业驱动因素。专利药厂更倾向于保护其现有资产,不愿冒险探索新适应症;而仿制药厂利润空间有限,难以承担再定位带来的开发成本。研究人员认为,计算方法可显著降低再定位成本,通过预先筛选潜力药物、优化剂量、组合策略和适应症人群,为新适应症建立专利与数据基础,也能提高药品通过审批的可能性。
尽管仍存在诸多限制,研究人员希望本研究能为未来构建更完善的药物再定位目录与工具体系奠定基础,推动个性化、疾病特异性和机制导向的再定位策略落地。随着更多资源的整合与开放,计算药物再定位将不断扩展其在临床转化中的应用潜力,最终实现对患者治疗效果的积极影响。
参考资料
Tanoli, Z., Fernández-Torras, A., Özcan, U.O. et al. Computational drug repurposing: approaches, evaluation of in silico resources and case studies. Nat Rev Drug Discov (2025).
https://doi.org/10.1038/s41573-025-01164-x