def __init__(self):super(CNNModel, self).__init__()self.feature = nn.Sequential()self.feature.add_module('f_conv1', nn.Conv2d(3, 64, kernel_size=5))self.feature.add_module('f_bn1', nn.BatchNorm2d(64))self.feature.add_module('f_pool1', nn.MaxPool2d(2))self.feature.add_module('f_relu1', nn.ReLU(True))self.feature.add_module('f_conv2', nn.Conv2d(64, 50, kernel_size=5))self.feature.add_module('f_bn2', nn.BatchNorm2d(50))self.feature.add_module('f_drop1', nn.Dropout2d())self.feature.add_module('f_pool2', nn.MaxPool2d(2))self.feature.add_module('f_relu2', nn.ReLU(True))self.class_classifier = nn.Sequential()self.class_classifier.add_module('c_fc1', nn.Linear(50 * 4 * 4, 100))self.class_classifier.add_module('c_bn1', nn.BatchNorm1d(100))self.class_classifier.add_module('c_relu1', nn.ReLU(True))self.class_classifier.add_module('c_drop1', nn.Dropout2d())self.class_classifier.add_module('c_fc2', nn.Linear(100, 100))self.class_classifier.add_module('c_bn2', nn.BatchNorm1d(100))self.class_classifier.add_module('c_relu2', nn.ReLU(True))self.class_classifier.add_module('c_fc3', nn.Linear(100, 10))self.class_classifier.add_module('c_softmax', nn.LogSoftmax())self.domain_classifier = nn.Sequential()self.domain_classifier.add_module('d_fc1', nn.Linear(50 * 4 * 4, 100))self.domain_classifier.add_module('d_bn1', nn.BatchNorm1d(100))self.domain_classifier.add_module('d_relu1', nn.ReLU(True))self.domain_classifier.add_module('d_fc2', nn.Linear(100, 2))self.domain_classifier.add_module('d_softmax', nn.LogSoftmax(dim=1))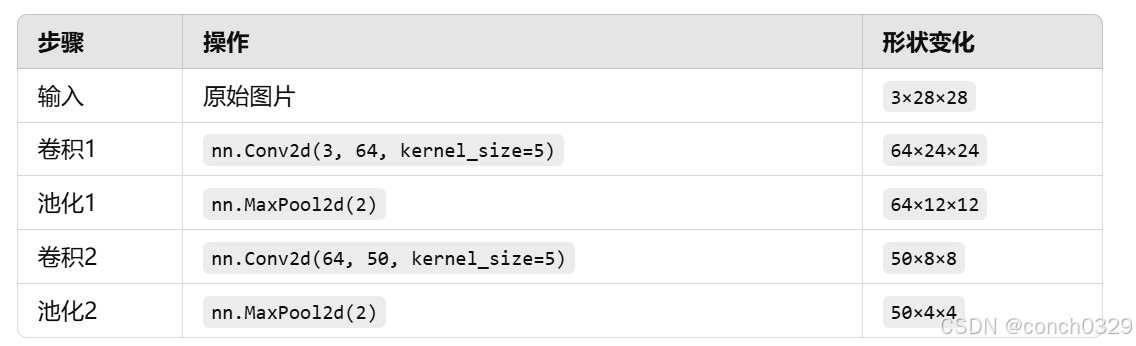
你可以把 CNN 过程想象成一个图片精炼机:
- 第一层卷积:提取基础特征(边缘、直线)。
- 第一层池化:减少数据量,但保留重要信息。
- 第二层卷积:提取更复杂的特征(形状、轮廓)。
- 第二层池化:再一次压缩,保留最核心的信息。
最终,我们把 3×28×28 的图片变成了 50 个 4×4 的特征块,然后这些特征会被送到全连接层进行分类。
1️⃣ 输入图像:3×28×28
假设我们的输入是一张 RGB 彩色图片(3通道),大小为 28×28:
- 3:RGB 三个通道
- 28×28:图片的高和宽
💡 想象一下,你拿着一张 28×28 的小图片,里面可能是一只猫的局部,或者是手写的 "5"。
2️⃣ 第一层卷积 Conv1: nn.Conv2d(3, 64, kernel_size=5)
这一步,我们用 64 个 5×5 的卷积核 去扫描图片,提取特征:
- 输入:
3×28×28 - 卷积核:64 个
5×5×3(5×5 空间大小,3 代表 RGB 通道) - 步长=1,padding=0
- 输出:
64×24×24
为什么输出是 64×24×24?
卷积的计算公式是:
输出尺寸=输入尺寸−卷积核尺寸步长+1\text{输出尺寸} = \frac{\text{输入尺寸} - \text{卷积核尺寸}}{\text{步长}} + 1输出尺寸=步长输入尺寸−卷积核尺寸+1
这里:

所以输出是 64×24×24,即 64 张 24×24 的特征图。
💡 想象一下: 你用 64 种不同类型的滤镜(卷积核)在图像上滑动,比如:
- 一个滤镜专门检测 水平边缘
- 另一个滤镜专门检测 垂直边缘
- 还有一些滤镜检测 纹理、颜色变化等
3️⃣ 第一层最大池化 MaxPool1: nn.MaxPool2d(2)
最大池化(Max Pooling) 作用是 降低特征图的大小,减少计算量,同时保留重要信息。
- 池化窗口:
2×2 - 步长=2(即每次跳过 2 个像素)
- 输入:
64×24×24 - 输出:
64×12×12
为什么变成 12×12?
池化的计算公式是:

所以,每张 24×24 的特征图被压缩到 12×12,总共有 64 张。
💡 想象一下:
你拿一个小窗口(2×2)在特征图上滑动,每次取 4 个像素里最大的值,比如:
复制编辑
原始数据: 1 3 4 2
最大池化后:
复制编辑
4 (因为4最大)
这样可以保留最强的特征,同时减少数据量。
4️⃣ 第二层卷积 Conv2: nn.Conv2d(64, 50, kernel_size=5)
这次,我们用 50 个新的 5×5 卷积核 继续提取更高级的特征,比如曲线、复杂边缘等。
- 输入:
64×12×12 - 卷积核:50 个
5×5×64 - 输出:
50×8×8
为什么输出是 8×8?
12−51+1=8\frac{12 - 5}{1} + 1 = 8112−5+1=8
所以输出是 50×8×8。
💡 想象一下: 经过第一层卷积,我们已经找到了 基础特征(直线、边缘),现在这 50 个新卷积核要把这些基础特征组合起来,比如:
- 识别 更复杂的形状(如 "5" 的整个轮廓)
- 识别 特定模式(比如 "O" 形状)
5️⃣ 第二层最大池化 MaxPool2: nn.MaxPool2d(2)
再一次进行 最大池化,降低尺寸,减少计算量:
- 输入:
50×8×8 - 池化窗口:
2×2 - 步长=2
- 输出:
50×4×4
为什么输出是 4×4?
82=4\frac{8}{2} = 428=4
所以最终得到 50 张 4×4 的特征图。
💡 想象一下: 现在特征已经非常精炼,图片的大量细节已经被简化,变成了更重要的核心特征。
📌 最终输出 50×4×4 是什么意思?
- 50 代表 50 个不同的特征通道,每个通道关注不同的信息(比如某些通道专门识别曲线,某些通道专门识别直线)。
4×4代表 最终的特征图尺寸,相当于把整张图片压缩成了4×4大小的一个特征表示,后面会接全连接层进行分类。
随后接的是一个线性层的分类器
接着是
📌 总体流程
- 输入:
50×4×4=800维的特征向量 - 第一层全连接层:
800 → 100 - 批归一化 + ReLU
- 第二层全连接层:
100 → 2 - Softmax 归一化,输出两个类别的概率