概述
背景介绍
当今世界充斥着大量图像和视频数据,理解和分析这些视觉信息对于计算机系统变得至关重要。在这个背景下,目标检测作为计算机视觉中重要的任务,致力于在图像或视频中准确识别和定位特定目标物体。
这一领域的发展经历了从传统方法到基于深度学习的新兴技术的转变,深度学习技术的兴起带来了卷积神经网络等强大工具,这些工具能够自动地从数据中学习特征,并在目标检测任务中取得了令人瞩目的成果。通过卷积神经网络提取图像特征并结合分类器与定位器的设计,现代目标检测算法能够准确地找到图像中感兴趣的目标物体,并标注其位置和类别。基于深度学习的目标检测算法利用卷积神经网络(CNN)等模型提取图像特征,并通过候选区域提取和分类定位阶段,识别出目标物体的位置和类别。
近年来,诸如Faster R-CNN(Region-based Convolutional Neural Networks)、YOLO(You Only Look Once)、SSD(Single Shot MultiBox Detector)等基于深度学习的模型极大地提高了目标检测的准确性和实时性能,这些算法在各种领域得到了广泛应用,包括自动驾驶、安防监控、医学影像分析等。这些目标检测方法总体上可以细分为分类和回归两个子任务。
分类的目标是将数据分为不同的类别或标签,在分类问题中,模型接收输入数据并尝试将其归类到预定义的类别之一。回归与分类不同,它的目标是预测连续值的输出,回归模型根据输入变量预测一个或多个连续的目标值。目标检测的两个子任务分别为分类和回归,分类负责确定检测到的物体属于哪个类别,算法会对图像中的区域进行分类,判断物体是猫、狗、车等等。回归部分用于定位物体的边界框。算法会对边界框的位置进行回归,以准确地确定图像中物体的位置。
研究现状
目标检测是计算机视觉中的重要问题,近年来在深度学习技术的推动下取得了巨大进展。现今,该领域的发展不断推陈出新,为智能交通、安防监控、医学影像分析等应用领域带来前所未有的机遇与潜力。WOS数据库中以“Object Detection”为关键词可检索到多达11万篇相关文献,且数量逐年上升,这充分展现了目标检测的热门程度。
近年来,深度学习技术的推动使得目标检测领域取得了显著进展。最初的研究聚焦于解决传统目标检测中的性能瓶颈。例如,由Ren,SQ等人提出的SPPnet和Fast R-CNN方法,通过优化区域提议算法,将重点放在减少网络运行时间上,解决了传统目标检测中区域提议算法的性能瓶颈。SPPnet引入了空间金字塔池化层(SPP),实现了任意尺寸输入图像到固定大小特征映射的映射,从而使得网络能够处理变尺寸的输入图像;而Fast R-CNN则通过共享卷积计算来减少计算复杂性,能够极大提高检测速度和准确性。这些工作为目标检测领域的发展奠定了基础。Liu, W等人提出的SSD方法采用边界框作为输出空间,同时预测目标的位置和类别。其能够在单次前向传播中同时进行对象检测和定位,通过引入不同尺度和长宽比的默认边界框,有效地适应不同尺寸和形状的目标。在网络结构方面,He, KM等人引入了残差学习框架(Residual Learning),通过引入残差模块,网络能够学习残差函数,使得网络更容易优化,并且可以从更深层次的网络中获得更高的准确性和表示能力,允许训练更深层次的神经网络,从而提高了准确性和表征能力。Mask R-CNN是由He, KM等人在Faster R-CNN基础上进一步发展,引入了对象掩码的预测分支,使网络不仅能实现对象检测,还能进行对象分割。通过同时预测目标的边界框和掩码,这种方式在对象检测和分割任务中取得了显著的进展。Redmon, J 等人提出了YOLO(You Only Look Once)方法,它将目标检测视为回归问题,在单次前向传播中直接从整张图像中预测目标位置和类别,虽然定位精度上可能存在一定的限制,但在实时性方面具有很大的的优势。
除了这些,还有一些方法针对特定问题提出了解决方案。比如,Dai, JF等人提出的可变形卷积网络(Deformable ConvNets),通过学习新的可变形层解决了光学遥感图像中目标旋转变化的问题,这种方法能够有效地处理目标在图像中的旋转变化,提高了目标检测的鲁棒性。Cheng, G 等人提出了特征金字塔网络(FPN),利用了卷积网络的多尺度结构,通过构建特征金字塔提高了多尺度目标检测的性能。这种架构在不同尺度下提取特征,并通过横向连接实现信息的传递和整合,从而提高了目标检测的准确性和鲁棒性。
此外,一些算法如Shrivastava等人提出的在线困难样本挖掘(OHEM)和Shrivastava等人提出的Inside-Outside Net(ION)等方法,前者通过自动选择困难样本进行训练,有效地提升了目标检测的性能。这种算法能够自动挖掘那些对网络学习具有挑战性的样本,从而提高了网络的泛化能力。后者利用感兴趣区域内外的信息,提高了目标检测的性能。通过内部和外部信息的融合,这种方法显著改进了PASCAL VOC 2012和MS COCO数据集上的目标检测。Bell, S提出的ION方法,结合内外部信息实现目标检测,显著提高了PASCAL VOC 2012和MS COCO数据集上的检测性能。ION模型在2015年的MS COCO Detection Challenge中获得了“Best Student Entry”并取得了第三名。
在这个充满活力和挑战的领域中,目标检测的不断演进为诸多应用领域(如智能交通、安防监控、医学影像分析等)带来了前所未有的机遇与潜力。通过深入研究和创新,目标检测领域将继续推动着计算机视觉技术的发展,并为人工智能的应用带来更多可能性。
算法原理
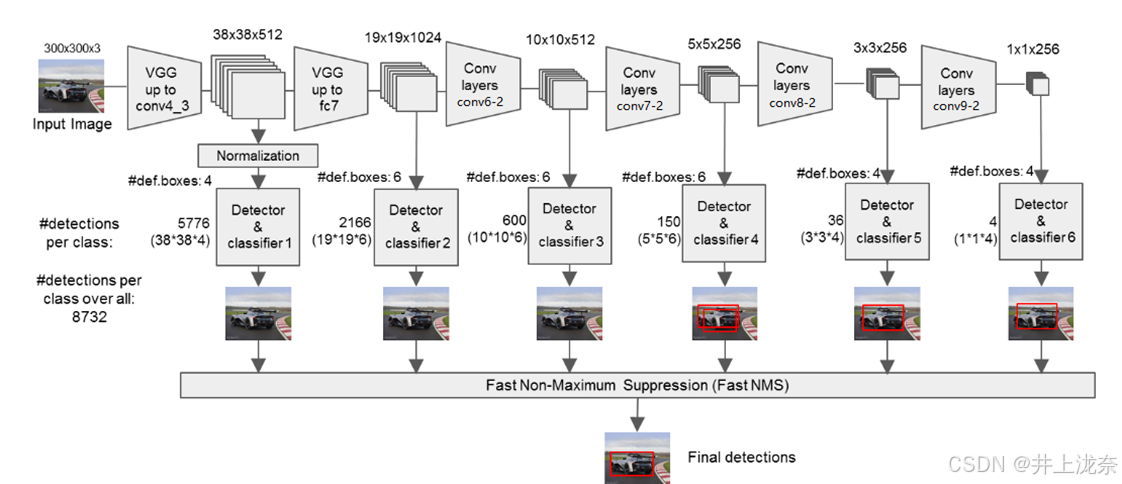
SSD(Single Shot MultiBox Detector)通过单次前向传播能够实现高效的目标检测,它结合了Faster R-CNN中的区域建议网络(RPN)和YOLO的回归思想,综合两者的优点,在速度和准确性上取得了很好的平衡,SSD的网络结构如下图所示,它包含了一个VGG-16网络以及额外四个卷积层,通过卷积池化操作能够将输入的图片不断分解,并在利用特定的步骤生成的结果进行分类和回归。其中VGG网络部分相较于原网络有修改,将VGG16的FC6和FC7层转化为卷积层,去掉了所有的Dropout层和FC8层。
SSD网络结构
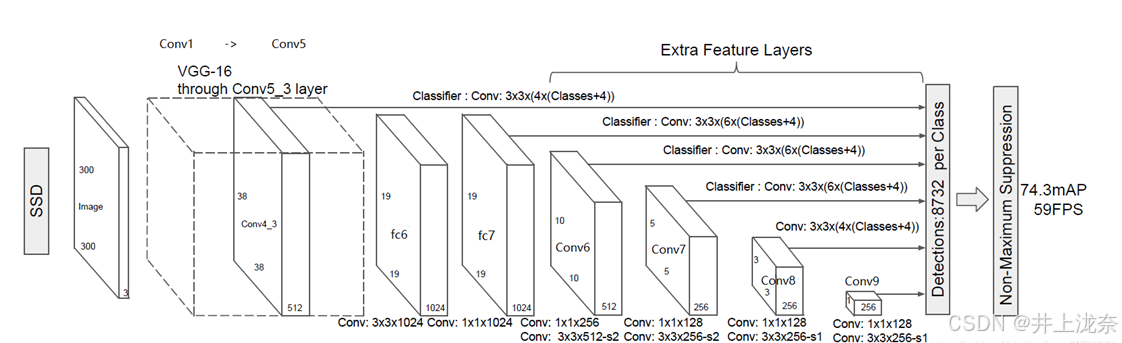
SSD的结构如下图所示。
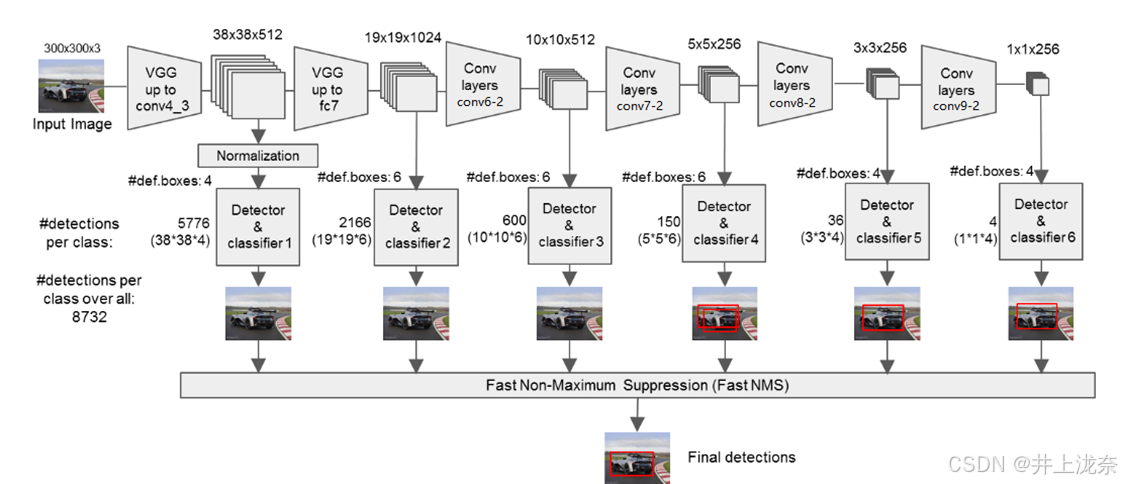
算法首先会输入一张3003003的图像,通过:
- 2次步长为1,窗口大小为33,输出层为64的卷积操作得到300300*64的图像
- 步长为2的22池化操作得到150150*64的图像
- 2次步长为1,窗口大小为33,输出层为128的卷积操作得到150150*128的图像
- 步长为2的22池化操作得到7575*128的图像
- 3次步长为1,窗口大小为33,输出层为256的卷积操作得到7575*256的图像
- 步长为2,窗口大小为为22的保留额外特征点池化操作得到3838*256的图像
- 3次步长为1,窗口大小为33,输出层为512的卷积操作得到3838*512的图像
- 步长为2的22池化操作得到1919*512的图像
- 3次步长为1,窗口大小为33,输出层为512的卷积操作得到1919*512的图像
- 边缘填充1像素,步长为1窗口大小为33的池化得到1919*512的图像
- 输入层为512,输出层为1024的33空间卷积操作的到1919*1024的图像
- 输入层为1024,输出层为1024的11卷积操作的到1919*1024的图像
- 步长为1,窗口大小为11,输出层为256的卷积操作得到 1919*256的图像
- 步长为2,窗口大小为33,输出层为512的卷积操作得到1010*512的图像
- 步长为1,窗口大小为11,输出层为128的卷积操作得到1010*128的图像
- 步长为2,窗口大小为33,输出层为256的卷积操作得到55*256的图像
- 步长为1,窗口大小为11,输出层为128的卷积操作得到55*128的图像
- 步长为1,窗口大小为33,输出层为256的卷积操作得到33*256的图像
- 步长为1,窗口大小为11,输出层为128的卷积操作得到33*128的图像
- 步长为1,窗口大小为33,输出层为256的卷积操作得到11*256的图像
上述步骤中,1 ~ 7为conv4-3的执行步骤,8 ~ 12为FC7的执行步骤,剩下的步骤为额外卷积层的执行步骤。SSD算法会从上述步骤中提取6个有效特征层,也就是步骤7、步骤12、步骤14、步骤16、步骤18和步骤20的输出作为特征层进行分类和回归。这些特征层从小到大将图片分为了3838、1919、1010、55、33和11的网格,这些格的划分可以使SSD算法对大小无图均有比较好的检测效果,对于大物体使用大网格进行预测,对于小物体使用小网格进行预测。SSD算法会在这些网格上生成先验框,每个有效特征层上每个网格生成的先验框数量分别是4、6、6、6、4、4。也就是说,对于3838的网格,每个网格会生成4个先验框,那么第一个有效特征层将会产生3838*4=5776个先验框,SSD算法总共会产生8732个先验框作为预测框的候选。
Detector&classifier的图示如下,以55256的特征层作为示例。
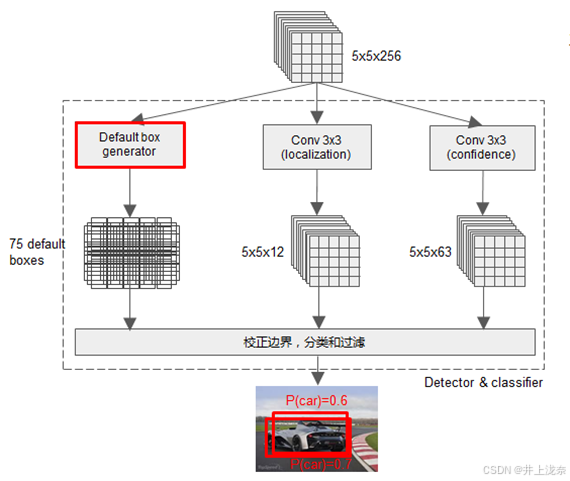
Detector & classifier有三个部分,默认候选框default boxes、4个位置偏移localization和每个类别的置信度confidence。由于是将图像分为55的网格,因此会产生75个default boxe,另外会对该特征层分别进行输出层为34和321的33卷积,对于示例特征层,原始分类数量为21,因此得到一个5512的localization和5563的confidence,共得到150个输出,localization和confidence将记录default boxes的信息。
Localization可以看作是3个554的位置,每个像素点代表了4个位置的值,因此对于每个网格,有3个候选框,在localization中都有4个位置对应,即localization有75个先验框的4个位置值。同理,对于Confidence,每个候选框都会对应21个概率值。最终,通过这一步就会得到每个候选框的位置以及概率,进行NMS非极大抑制选择得分最高的先验框作为预测框即可得到最终结果。
开始实践
环境配置
环境说明
目标检测算法通常需要大量的计算资源进行训练,GPU相对于传统的CPU具有更强大的并行计算能力,这种并行性能使得GPU在处理深度学习模型、大规模数据集和复杂的计算任务时具有明显的优势。在目标检测的训练过程中,具有大量的矩阵计算和神经网络运算,GPU加速执行这些过程,显著缩短了训练时间,因此。并且对于不同的项目,其需要的环境可能不同,在Python中,许多第三方的包可能会因为版本的问题导致各种问题的出现,因此对环境的管理就至关重要。环境配置可以分为环境管理与GPU环境搭建两个任务。
配置步骤
(1)安装Anaconda环境管理器
Anaconda是一个开源的Python发行版和包管理器,用于数据科学、机器学习和科学计算。它集成了许多常用的Python库、工具和环境管理功能,它能够非常好地管理各种环境,这样就解决了不同项目需要不同的运行环境的问题,尤其是当项目中有细微差距,如第三方包的版本不同时,可以无需重新配置复杂的运行环境,在anaconda powershell prompt环境管理控制台中,可以直接使用conda create -n A --clone B命令来复制A环境,并在B环境中做微调,这对不同项目的部署运行有很大的帮助。
Anaconda可以直接从官网进行一键式安装,十分便捷。常用的命令包括conda activate A:创建虚拟环境A;conda activate A:激活A环境;conda env list:列出所有的环境;conda list:列出当前环境下安装的所有包的信息。通过conda list可以对环境的所有包进行查看,十分方便,尤其是在项目中遇到因为版本问题的报错,可以非常方便地修改出问题的包。
(2)安装CUDA和Cudnn库
CUDA是一种由NVIDIA提供支持的并行计算平台和编程模型,基于CUDA编写的程序能够充分利用GPU的计算能力,加速各种计算任务,这对于科学计算、数据处理和深度学习等领域尤为重要。许多深度学习框架(如TensorFlow、PyTorch等)都提供了与CUDA的集成,允许利用CUDA加速神经网络的训练和推理过程。Cudnn是NVIDIA专门为深度学习任务而设计的加速库,是基于CUDA架构的深度神经网络库,能够优化深度神经网络的训练和推理过程。
通过命令nvidia-smi可以查看自己显卡能够支持的CUDA版本,我的电脑最高能够支持CUDA 12.3版本。但是考虑到CUDA、Pytorch、Cudnn版本需要对应,因此不宜安装太高的CUDA版本,避免其他环境的版本不契合,最终我选择安装的版本为为Pytorch 2.1.1,CUDA11.8,Cudnn 8.0。
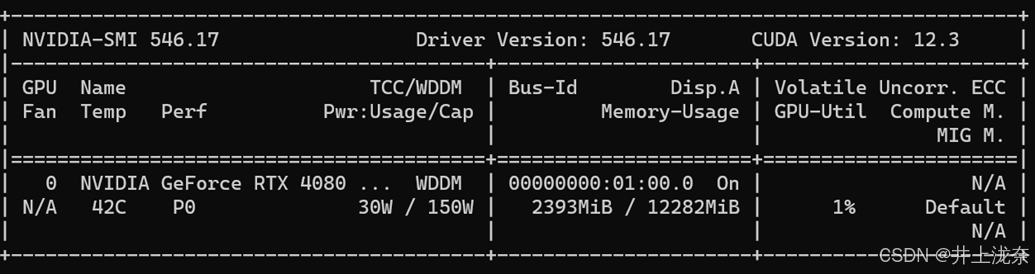
CUDA的安装可以通过NVIDIA官网下载安装包进行安装,随后可以在前面安装的Anaconda管理器中使用pip命令或者conda命令安装cudnn。
(3)安装PyTorch库
PyTorch是一个基于Python的开源机器学习库,专注于深度学习任务。它由Facebook的人工智能研究小组开发并维护,提供了丰富的工具和接口,使得构建深度神经网络模型变得简单而灵活。它提供了强大的GPU支持,PyTorch能够充分利用GPU的加速能力,它提供了针对GPU计算的优化接口,能够使模型训练和推理速度大幅提升。在大多数的深度学习项目中,几乎都会用到PyTorch,因此需要在环境中安装PyTorch才能真正实现使用GPU进行运算。
由于之前安装了Anaconda,PyTorch的安装可以直接在官网中复制安装的conda命令或pip命令进行一键式安装:conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia。
(4)其他库的安装
通过Anaconda能够非常方便地安装各种库并进行管理,有时候安装某些库后,可能会安装或者更新某些库,可以使用Anaconda进行管理安装,例如TensorFlow库,TensorFlow是一个由Google开发的开源机器学习框架,用于构建和训练各种机器学习模型。一般来说通过上述步骤配置后应该是不含有TensorFlow库的,因此需要安装,但是需要注意的是,对于GPU环境,需要安装TensorFlow的GPU版本,否则在计算时还是使用CPU资源进行计算。另外如果在安装其他库的时候会级联安装TensorFlow,一般都是CPU版本,需要卸载后重新安装TensorFlow-GPU。
管理方式
通过上述步骤,GPU运算环境配置完毕,该环境可以当做GPU的基本环境,当有项目需要在GPU环境运行时,可以复制该环境随后根据项目对该环境的库进行微调,这样可以确保每个项目都有对应的运行环境,不会因为第三方库的版本问题在不同项目之间起冲突,同时也不需要对每个项目都进行繁琐的GPU环境配置。例如在我的虚拟环境中,pytorchGpuEnv环境作为SSD项目的运行环境,里面配置了机器学习会用到了大多数通用库。YoloEnv环境就是复制的pytorchGpuEnv环境,作为YOLO V8项目的运行环境,并在YoloEnv下安装了yolo等该YOLO项目特有的库,并根据YOLO项目的requirements文档更新了numpy等库的版本。
数据集介绍
本次实践所使用的数据集是要是对船舶进行分类,其中包括有5775张船舶图片,其中5486张图片被划分为训练集,289张被划分为测试集。这些船舶中包含有engineer ship、cargo、Passenger ship、warship、fishing ship、unknown这些类别。
船舶图片数据集
除了船舶图片,每张图片还有对应的标签文件,使用XML格式存放数据,在这个XML文件中,有标签,对应着图片的标签,还有标签,表示这张图像中的物体,该标签下包含有许多子标签,需要关注的有标签和标签,前者表示该物体的类别,后者有,,,四个子标签,代表该物体在图像中的位置。我所拿到的数据集已经有这些文件了,如果需要制作新的数据集,可以使用labelimg标注工具进行标注文件生成。最后可以根据图片文件和标签文件制作训练、测试文件,文件的每一行有图片信息和物品信息,格式如D:/Projects/DataSet/imageData/JPEGImages/0.jpg 266,226,440,312,0 186,326,203,342,5 367,317,400,332,5,表示图片地址为D:/Projects/DataSet/imageData/JPEGImages/0.jpg,图片中共有3个物体,类别分别是0,5,5,并给出这三个物体在图像中的位置。
SSD项目使用的是开源项目ssd-pytorch,项目地址为:https://github.com/bubbliiiing/ssd-pytorch。该项目利用SSD方法对VOC(Visual Object Classes)数据集进行训练并预测。该数据集是一个广泛用于计算机视觉领域的标准数据集之一,它主要用于目标检测、物体识别和语义分割等任务的训练和评估。包含了20个不同类别的物体,涵盖了常见的物体和场景,比如人、动物、交通工具、家具等。
部署与训练
核心代码阅读
VGG特征提取网络
首先从git上将代码拉取到本地,并切换为之前配置好的GPU虚拟运行环境,随后检查是否有缺失的库或者是版本不对应。该项目的特征提取网络使用的是VGG模型。根据之前对SSD的介绍,其特征提取网络会将输入的3003003的图片进行卷积池化操作得到11256的特征图。特征提取网络部分代码如下。
base = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',512, 512, 512]def vgg(pretrained=False):layers = []in_channels = 3for v in base:if v == 'M':layers += [nn.MaxPool2d(kernel_size=2, stride=2)]elif v == 'C':layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]else:conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)layers += [conv2d, nn.ReLU(inplace=True)]in_channels = vpool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)conv7 = nn.Conv2d(1024, 1024, kernel_size=1)layers += [pool5, conv6,nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
这段代码首先定义了一组列表数字代表卷积层的输出通道数,'M’代表最大池化层,'C’代表使用了ceil_mode的最大池化层。随即利用循环对图像进行操作。对于3003003的图片,首先进行2次输出特征层为64的卷积操作得到30030064的特征图,随后通过步长为2的22最大池化得到15015064的特征图。需要注意的是,对7575256的特征图进行池化时,由于窗口大小为22,步长为2,如果直接进行池化会导致最边缘的一列数据无法被池化,最终得到的特征图尺寸会和期望不符,因此需要定义ceil_mode=True,这样才不会丢失数据,达到期望结果。pool5由于设置的步长stride=1,因此特征图不会被压缩,conv6进行了空间卷积操作,padding=6表示使用6像素进行填充来保证输出特征图的尺寸,dilation=6则是指定进行空间卷积操作。一般来说,为了降低计算量,可以采用降采样的方式,但还是这种方式会降低空间分辨率,空洞卷积可以不丢失分辨率,不改变图像输出特征图的尺寸的前提下,仍然扩大感受野(神经网络中,输出特征图上的一个像素点对应输入图像的区域大小)。这种方式在这在检测、分割任务中十分有用,一方面感受野大了可以检测分割大目标,另一方面分辨率高了可以精确定位目标。
上述代码对输入图像的操作如下。
- 3003003 -> 30030064 -> 30030064 2次 64卷积
- 30030064 -> 15015064 步长为2的2*2最大池化
- 15015064 -> 150150128 -> 150150128 2次 128卷积
- 150150128 -> 7575128 步长为2的2*2最大池化
- 7575128 -> 7575256 -> 7575256 -> 7575256 3次 256卷积
- 7575256 -> 3838256 步长为2的2*2最大池化
- 3838256 -> 3838512 -> 3838512 -> 3838512 3次 512卷积
- 3838512 -> 1919512 步长为2的2*2最大池化
- 1919512 -> 1919512 -> 1919512 -> 1919512 3次 512卷积
- 1919512 -> 1919512 边缘填充1像素,步长为1池化,窗口大小3*3
- 1919512 -> 19191024 1024空间卷积
- 19191024 -> 19191024 1024空间卷积
上述步骤执行结束后能得到红框中的内容,根据SSD的流程图可见,SSD会在特征提取网络中提取3838512和19191024,分别在步骤7)和12)得到,其在代码中的计算序号分别为22和34。额外卷积层的构建代码如下。
layers += [nn.Conv2d(in_channels, 256, kernel_size=1, stride=1)]
layers += [nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1)]layers += [nn.Conv2d(512, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)]layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)]
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)]
这段代码对上述步骤得到的19191024特征图继续处理,首先进行11,步长为1,通道为256的卷积操作来使缩减图像通道数以降低运算量。随后利用步长为2,大小为33,通道为512的卷积操作得到1010512的特征图,后面依次进行卷积操作,具体步操作如下。
13) 19191024 -> 1919256 步长为1的11 256卷积
14) 1919256 -> 1010512 步长为2的33 512卷积
15) 1010512 -> 1010128 步长为1的11 128卷积
16) 1010128 -> 55256 步长为2的33 256卷积
17) 55256 -> 55128 步长为1的11 128卷积
18) 55128 -> 33256 步长为1的33 256卷积,未填充
19) 33256 -> 33128 步长为1的11 128卷积
20) 33128 -> 11256 步长为1的33 256卷积
SSD会在特征提取网络中继续提取1010512、55256、33256和11256的特征图,分别在步骤14)、16)、18)和20)得到,其在代码中的计算序号分别为第1层、第3层、第5层和第7层。
特征处理
通过上述VGG特征提取网络,能够得到6个特征层,SSD目标检测算法后面会对于提取出来的特征进行处理,部分特征处理的代码如下。
mbox = [4, 6, 6, 6, 4, 4]loc_layers = []
conf_layers = []
backbone_source = [21, -2]for k, v in enumerate(backbone_source):# 回归预测结果loc_layers += [nn.Conv2d(self.vgg[v].out_channels, mbox[k] * 4, kernel_size=3, padding=1)]# 分类预测结果conf_layers += [nn.Conv2d(self.vgg[v].out_channels, mbox[k] * num_classes, kernel_size=3, padding=1)]for k, v in enumerate(self.extras[1::2], 2):loc_layers += [nn.Conv2d(v.out_channels, mbox[k] * 4, kernel_size=3, padding=1)]conf_layers += [nn.Conv2d(v.out_channels, mbox[k] * num_classes, kernel_size=3, padding=1)]
代码定义了mbox,这是每个提取特征层的先验框个数,从SSD的算法流程图中可以看出,每个特征层的先验框个数分别为4, 6, 6, 6, 4, 4。loc_layers和conf_layers分别存放回归预测结果和分类预测结果,也就是物体的类别和位置。backbone_source中存放的是VGG网络列表从左往右数第21层,和从右往左数的第二层,从右往左数第一层是-2的索引,分别代表之前提取出来的3838512和19191024。由于后续经过了ReLU激活函数的,没有out_channels,因此需要使用序号-1未经过激活函数处理的输出。两个循环分别对提取的特征层做先验框数量4和先验框数量类别数的卷积操作并得到回归预测结果和分类预测结果,并存放在对应的list中。
其他代码简述
后续的代码主要是根据结果去计算先验框的位置调整并绘制,代码较长,这里进行简述。SSD算法后续会把原图像划分网格,每个特征层将会对每个网格点绘制对应数量的先验框,例如3838512的特征层会将整个图像分成38x38个网格,然后从每个网格中心建立4个先验框,因此对于3838512的特征层会产生38x38x4个先验框,也就是SSD流程图中的5776个先验框。
从特征处理到先验框的生成对应了下面SSD流程图的红框部分。
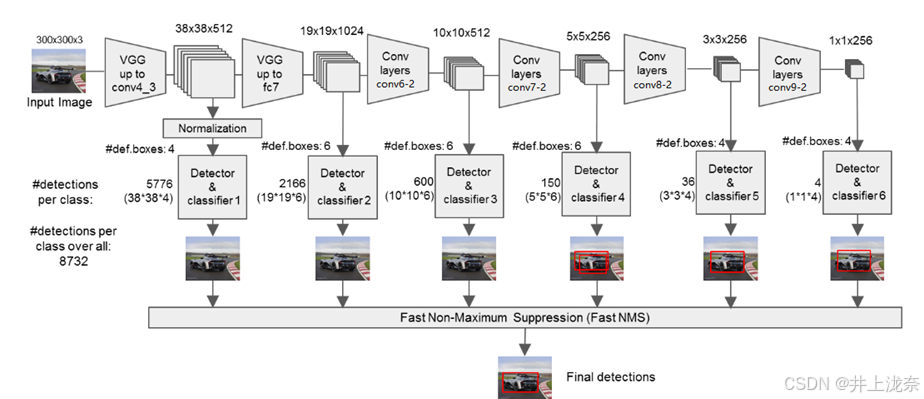
代码最后会利用卷积结果来对先验框进行调整,将每个网格的中心点加上它对应的偏移得到预测框的中心,并调整先验框获得预测框的宽和高,对于所有提取的特征层绘制出来的框,会根据预测框的位置和得分进行非极大抑制得到最终结果,对应流程图的剩余部分。
模型训练
训练模型需要修改项目下的test.txt、trian.txt以及classes.txt文件,分别代表训练、测试文件以及类别数,类别数文件中修改为个人数据集的5个类别即可。随即在train.py文件中修改各个参数,例如是否使用GPU、模型位置、图像大小、最大训练轮次等参数,修改完毕后运行该python文件即可开始模型训练。因为个人电脑性能的原因,本次实验只训练了50轮,主要的原因是显存容易超,因为目标检测会生成很多先验框这些先验框需要映射到GPU上才能计算,所以刚开始显存没有超,但是训练轮数一高,先验框太多了就报错了。
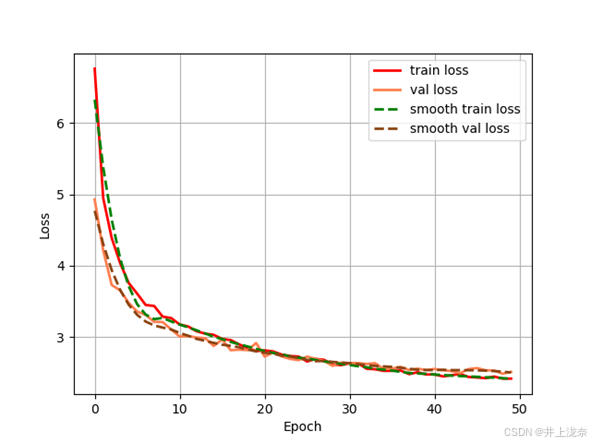
训练的loss(损失值,损失值越低表示模型对训练数据和验证数据的拟合程度越好)率变化如下图所示,可以看到在10轮之前,loss率下降很快,40轮训练后,loss率的下降趋于平滑,并且在50轮训练后,训练集损失和验证集损失都下降到了一个比较低的水平。
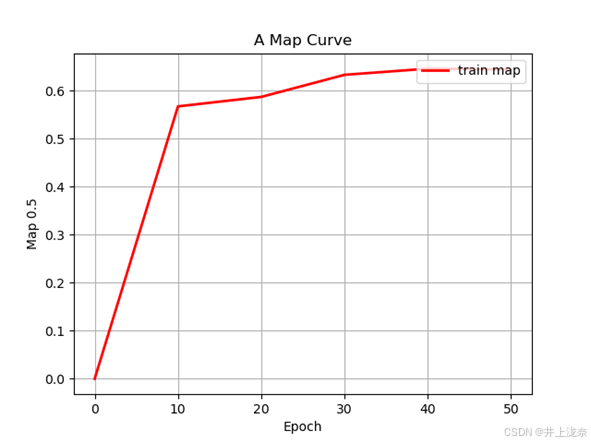
训练过程汇总的 MAP(Mean Average Precision,平均精确率均值) 曲线如下图所示,该曲线表示在训练中的平均精确率均值的变化情况。由于SSD目标检测算法不仅仅会进行分类,还有回归任务,因此不能仅仅只用分类准确率来表示,平均精确率均值能够表示分类准确率和回归准确率的平均情况。通过曲线可以看出,在 epoch=10 之前, MAP上升速度较快,表示模型开始有效地学习特征和调整权重。
10 到 50 之间, MAP 的增长速度放缓,表示模型已经在前期的训练中学到了一些有效特征,后续的训练对性能的提升不像刚开始那么显著。训练结束后,整体的MAP值提升到了60多,这种精确度已经能达到简单的检测效果了,由于只进行了50轮训练,后续在性能更高的机器上训练更多轮次应该能进一步提升MAP值。
预测效果
模型训练完毕后,即可通过训练的模型执行对象检测任务,我挑选了几个不同类型的船舶图片进行检测,下面是模型的预测效果。
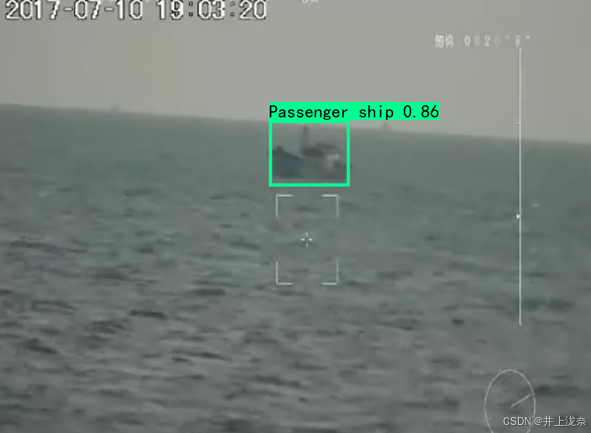




从结果可以看出,模型对于很模糊的船舶依旧能够进行识别,对于差别较大的艘船,即一张图中有大物体和小物体也能够准确识别出来,对于场景较为复杂的情况,模型识别效果会减弱,例如上面图片中左下角的船舶的预测框绘制略大,不过其给出的可能也较低,只有0.7,说明复杂的场景会降低模型识别精确度,但SSD目标检测算法依旧有良好的检测效率,对于一张图片中有很多的船舶,依旧能够检测出来。并且上述检测结果只是训练50轮的检测结果,更多轮次的训练应该能够进一步提升模型检测的准确性。