数值稳定性
神经网络的梯度

NT:里面所有的h都是向量,向量关于向量的导数是一个矩阵
所以这里要进行d-t次的矩阵乘法
多次的矩阵乘法又会带来两个问题:梯度爆炸、梯度消失

例子中的数字能表示,但是也说明了存在浮点问题(有范围限制)
例子:MLP
- MLP:多层感知机
- 对角矩阵(diagonal matrix)是一个主对角线之外的元素皆为0的矩阵,常写为diag(a1,a2,…an)
- diag*W:把diag和W分开看。这就是个链式求导,diag是n维度的relu向量对n维度的relu的输入的求导,向量对自身求导就是对角矩阵

梯度爆炸
当W元素值>1 & 层数很深时,连乘会导致梯度爆炸

梯度爆炸的问题

梯度消失
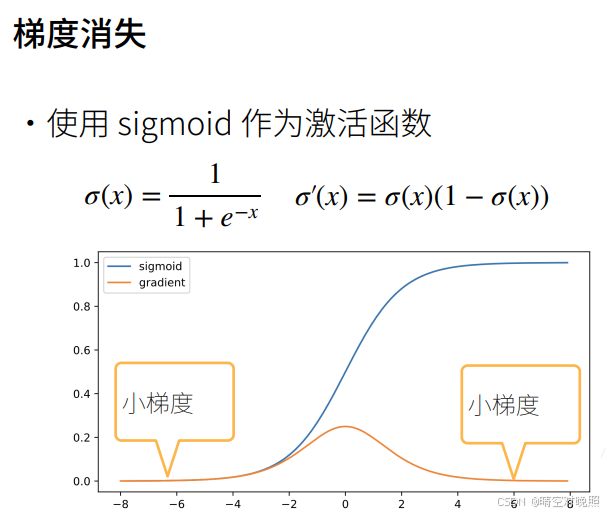
如上图例子,当激活函数的输入稍微大一点时,他的导数就趋近于0,连续n个接近0的数相乘,最后的梯度就接近0,梯度就消失了

存在的问题
- 梯度值变为0
对16位浮点数尤为严重 - 训练没有进展
不管如何选择学习率 - 对于底部层尤为严重
- 仅仅顶部曾训练的较好
- 无法让神经网络更深
让训练更稳定
- 目标:让梯度值在合理的范围内
- 常见方法:让乘法变加法(如ResNet,LSTM)
- 归一化:梯度归一化,梯度裁剪
- 合理的权重初始化 和 激活函数(本节重点)
- 裁剪:clipping
权重初始化
让每层的方差是一个函数


要使输出和权重的方差都为常数的话,该如何处理?
- 例:MLP
- 假设
- 权重使独立同分布,均值为0
- 假设输入与权重是相互独立的

求解:

第二行,因为独立同分布均值=0,所以第二项的累加=0
第三行,期望可以累加,所以可以写进去
第四行1,因为第三行两项均值=0,所以计算等价于方差
第四行2,第一项代换,第二项就是输入的方差
如果要推出输入的方差和输出的方差一样,那么要推出nr项=1(n是输入的维度,r是输入的方差)
- 假设


rt:第t层权重的方差
Xavier是常用的权重初始化的方法
权重初始化时的方差是根据输入和输出维度来定的
激活函数


- 检查查用激活函数
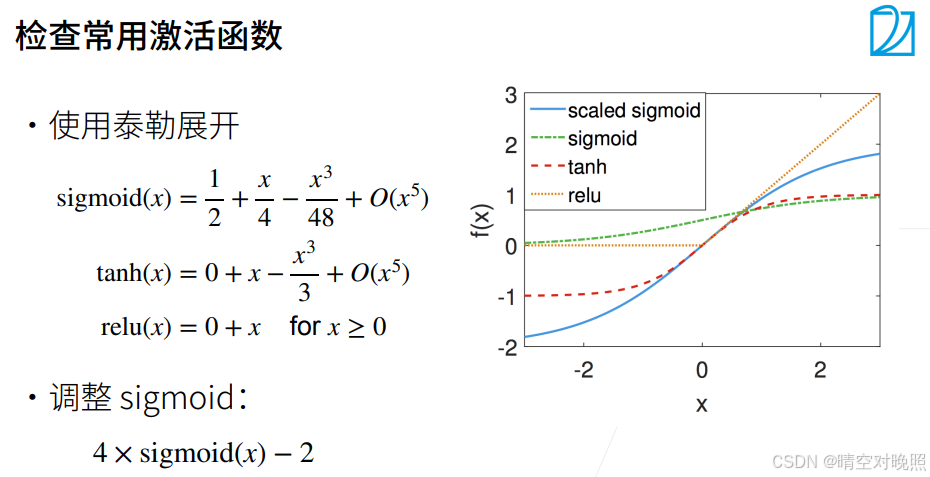
在x附近,tanh和relu近似到f(x)=x,满足之前的要求
但是sigmoid不满足,可以进行调整,如上