一、说明
作为广泛使用这些工具和模型的人,我的目标是解开 RNN、Transformer 和 Diffusion 模型的复杂性和细微差别,为您提供详细的比较,为您的特定需求提供正确的选择。
无论您是在构建语言翻译系统、生成高保真图像,还是处理时间序列预测,了解每个模型的功能和局限性都至关重要。我们将剖析每个架构的内部工作原理,比较它们在各种任务中的性能,并讨论它们的计算要求。
二、了解基础知识
好了,让我们深入了解机器学习模型的迷人世界,在这里,算法变成了艺术家,数据变成了决策。我说的是递归神经网络、变形金刚和扩散模型——人工智能界的摇滚明星。每个人都有自己的怪癖、优势和看待世界的独特方式。了解它们是释放人工智能潜力的关键,相信我,它并不像看起来那么令人生畏。
2.1 顺序数据:信息的无名英雄
首先,让我们谈谈顺序数据。它无处不在,隐藏在众目睽睽之下。想想看:语言,有序的词语流动;金融市场,其趋势瞬息万变;甚至是你的日常生活,你执行的一系列动作。所有这些例子都有一个共同点——信息的顺序很重要。与排列通常无关紧要的图像或单个数据点不同,顺序数据在很大程度上依赖于其元素的上下文和顺序。
现在,传统的神经网络,许多机器学习任务的主力,都在与这种秩序概念作斗争。它们擅长处理固定大小的输入,如图像,但向它们抛出一个序列,它们会有点迷失。他们缺乏“记忆”来理解过去的信息如何影响现在和未来。
2.2 RNN 救援:记住过去
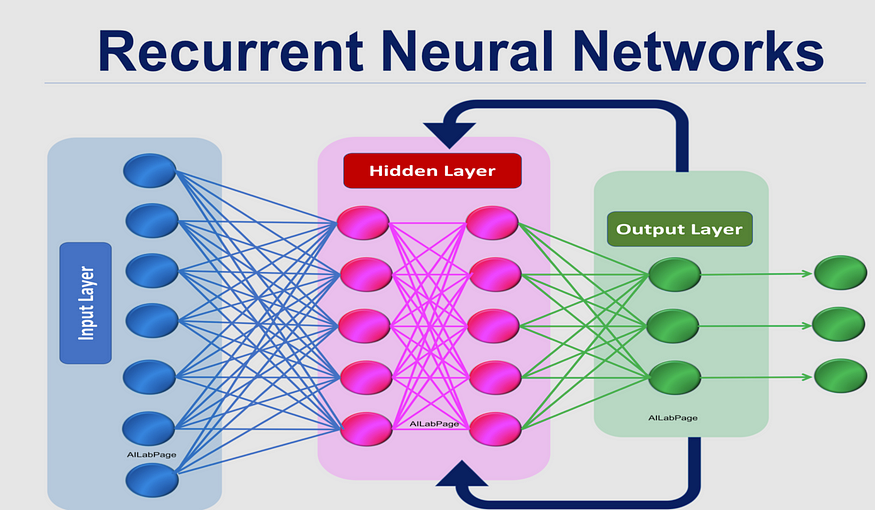
这就是 RNN 介入的地方,就像穿着代码制成的斗篷的超级英雄一样。它们拥有一种独特的能力——一种充当记忆的隐藏状态,存储来自先前输入的信息。把它想象成一个小笔记本,RNN在处理序列时记下重要的细节。这使得网络能够理解元素之间的上下文和关系,使其非常适合解决顺序数据挑战。
2.2 RNN 架构:序列母版系列
RNN 有多种口味,每种都有自己的优势和怪癖。让我们来认识一下这个家庭:
简单的 RNN:开国元勋
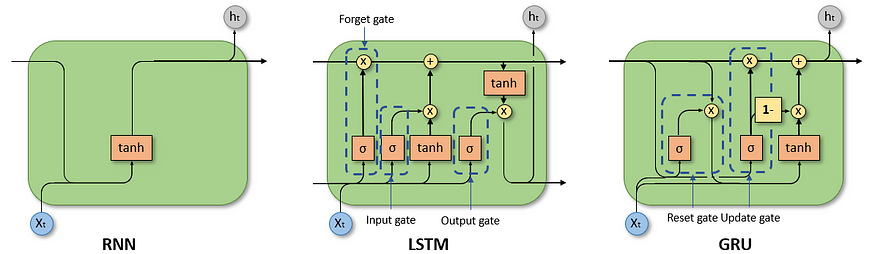
- 简单 RNN 是 RNN 家族的 OG 成员。它们有一个简单的结构:一个输入层、一个隐藏层(我们讨论的内存)和一个输出层。信息在网络中流动,隐藏状态根据当前输入及其先前的值不断更新。这就像一场电话游戏,信息随着传递而演变。
- 然而,简单的RNN有一点短期记忆问题。随着序列变长,它们很难保留来自遥远过去的信息,这种现象被称为梯度消失问题。这限制了它们对需要长期依赖的任务的有效性。
LSTM:记忆冠军
- 长短期记忆网络(LSTM)是RNN家族的大脑。它们通过复杂的细胞结构正面解决了梯度消失的问题。每个 LSTM 单元都有三个门(输入、忘记和输出),用于控制信息流。这些门就像小小的保镖,决定让哪些信息进入,记住什么,忘记什么。这种选择性内存使 LSTM 能够轻松处理长期依赖关系,使其成为语言翻译和语音识别等任务的理想选择。
GRUs:高效的表兄弟
- 门控循环单元 (GRU) 就像 LSTM 更年轻、更冷的表亲。它们有着相似的目标——解决消失的梯度问题——但结构更简单。GRU 有两个门而不是三个门,这使得它们在计算上比 LSTM 更有效。虽然它们可能并不总是与 LSTM 的性能相匹配,但它们的速度和易于训练使它们成为许多应用的热门选择。
2.3 优势:擅长序列数据、自然语言处理
RNN 已在广泛的应用中证明了其实力,彻底改变了我们与技术交互的方式。让我们来探讨一下他们最有影响力的贡献:
自然语言处理 (NLP):语言耳语者
- RNN 已成为许多 NLP 任务的支柱。他们擅长机器翻译,可以捕捉不同语言的细微差别并生成准确的翻译。情感分析,理解文本背后的情感,是RNN大放异彩的另一个领域。他们可以分析评论、社交媒体帖子和其他文本数据,以衡量公众舆论和品牌情绪。
时间序列分析:预测未来
- RNN 非常适合时间序列分析,其中数据点按时间排序。它们可用于预测,根据历史趋势预测未来值。这在金融、天气预报甚至预测工业环境中的设备故障方面都很有价值。此外,RNN 可以检测时间序列数据中的异常,识别可能表明问题或机会的异常模式。
语音识别和生成:赋予机器声音
- RNN 在语音识别中起着至关重要的作用,将口语转换为文本。他们可以分析语音信号的声学特征,并将它们映射到相应的单词或音素。另一方面,RNN也可以用于语音生成,创建听起来非常像人类的合成语音。该技术为有语言障碍的人提供虚拟助手、文本转语音应用程序和辅助工具。
2.4 弱点:梯度消失,长期记忆有限
- RNN 在语音识别中起着至关重要的作用,将口语转换为文本。他们可以分析语音信号的声学特征,并将它们映射到相应的单词或音素。另一方面,RNN也可以用于语音生成,创建听起来非常像人类的合成语音。该技术为有语言障碍的人提供虚拟助手、文本转语音应用程序和辅助工具。弱点:梯度消失,长期记忆有限
但即使它们的能力令人印象深刻,RNN 也有局限性。如前所述,原版RNN在消失的梯度中挣扎,这意味着它们无法记住过去太久的事情。LSTM 和 GRU 在一定程度上缓解了这种情况,但长期依赖关系仍然是一个挑战。
另一个问题是 RNN 按顺序处理信息,一次一个步骤。这可能很慢,尤其是对于长序列。在当今大数据和即时满足的世界中,速度至关重要。
2.5 使它具体化
想象一下:RNN 就像一条传送带,输入层、隐藏层和输出层都是工人。权重矩阵是连接它们的秘密武器。这是矩阵乘法和非线性变换的美丽舞蹈。
现在,训练这些坏男孩不是在公园里散步。我们使用一种叫做时间反向传播(BPTT)的小魔法来让它们学习。但要注意,消失和爆炸的梯度问题可能是真正的派对屎!这就像玩一个数字电话游戏——信息可能会丢失或在你的脸上爆炸。
为了让你体验一下这个动作,这里有一个小代码片段,告诉你如何在 PyTorch 中创建一个简单的 RNN:
<span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">导入</span>火炬 <span style="color:#aa0d91">导入</span>火炬
。nn <span style="color:#aa0d91">作为</span> nn</span></span><span style="background-color:#f2f2f2"><span style="color:#242424">class SimpleRNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(SimpleRNN, self).__init__()self.hidden_size = hidden_sizeself.rnn = nn.RNN(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size) def forward(self, x):_, hidden = self.rnn(x)output = self.fc(hidden.squeeze(0))return output</span></span>三、变形金刚:注意力革命
好了,伙计们,系好安全带,因为我们即将潜入变形金刚的世界,变形金刚是机器学习领域的摇滚明星,他们以其令人难以置信的能力吸引了人们的目光和下巴。还记得我们之前谈到的那些 RNN 吗?是的,好吧,变形金刚来了,说,“拿着我的啤酒”,然后开始彻底改变我们处理顺序数据的方式。
3.1 变形金刚的崛起:注意力就是你所需要的一切
那么,是什么导致了这次 Transformer 收购?好吧,尽管 RNN 令人惊叹,但它们也有其局限性。还记得他们是如何一步一步地处理信息的,比如逐字阅读一本书吗?这种顺序方法使他们很难处理长程依赖关系,其中单词或数据点之间的关系在序列中相距甚远。这就像当你读到结尾时,试图记住一本长篇小说开头发生的事情——事情变得有点模糊。
另一个问题是RNN可能很慢,计算成本高,尤其是在处理海量数据集时。训练他们感觉就像看着油漆干了一样,没有人有时间这样做。
进入注意力机制,这是使变形金刚如此强大的秘诀。注意力不是按顺序处理信息,而是允许模型专注于输入序列中最相关的部分,而不管它们的位置如何。这就像拥有一种超能力,可以让您放大重要的细节并忽略干扰。
因此,变形金刚诞生了——一种完全建立在这种注意力机制上的新颖架构。它就像一股新鲜空气,提供了一种更高效、更有效的方法来处理顺序数据。不再需要为远程依赖关系而苦苦挣扎,也不必永远等待模型进行训练。变形金刚将继续存在,他们已经准备好改变现状。
3.2 Transformer 架构:注意力的交响乐
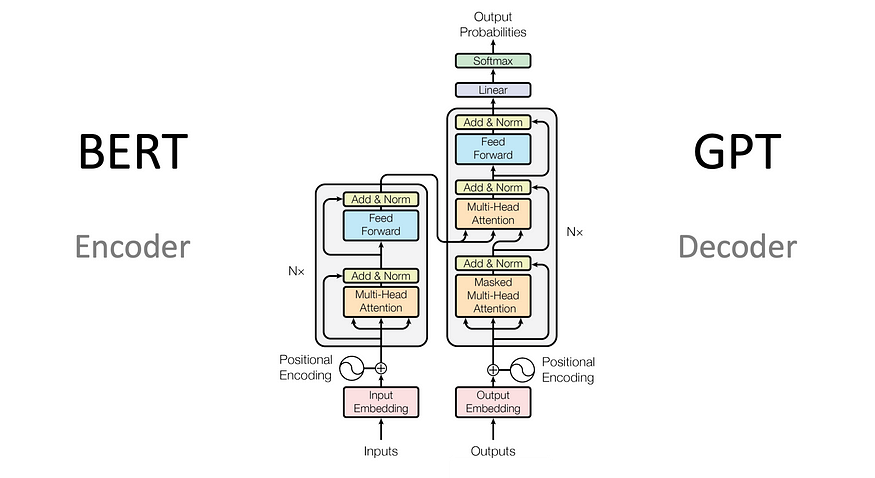
让我们仔细看看是什么让这些变形金刚滴答作响。将变压器想象成一台复杂的机器,有两个主要组件:编码器和解码器。编码器的工作是处理输入序列,而解码器则使用该信息生成输出序列。把它想象成一个翻译,他听一种语言的句子(编码器),然后用另一种语言(解码器)说出等效的句子。
现在,神奇的事情发生在这些编码器和解码器块中,其中自我注意力占据了中心位置。自注意力使模型能够理解同一序列中不同元素之间的关系。这就像一个句子中的每个单词都在查看其他单词并弄清楚它们是如何连接的。这有助于模型掌握序列的上下文和含义,这对于翻译或文本摘要等任务至关重要。
但是等等,还有更多!变形金刚不仅有一个磁头,而且有多个磁头——准确地说,是多磁头。每个头都专注于元素之间关系的不同方面,从而提供对序列的更全面理解。这就像有一个专家团队,每个人都有自己的观点,共同分析数据。
3.3 优势:并行处理,处理远程依赖关系
变压器具有一些重要的优点:
- 并行处理:它们可以一次处理整个序列,使其比RNN快得多,特别是对于长序列。时间就是金钱,在人工智能世界中,这转化为效率和可扩展性。
- 长期依赖关系:自我注意力机制允许 Transformer 捕获序列中相距很远的单词之间的关系,从而解决了困扰 RNN 的长期记忆问题。
3.4 弱点:计算成本、位置编码挑战
当然,没有一个模型是完美的,变形金刚也有自己的怪癖:
- 计算成本:所有这些并行处理和关注都是有代价的。训练 Transformer 可能需要大量的计算资源,这对于那些硬件有限的人来说可能是一个障碍。
- 位置编码:由于 transformer 同时处理序列,因此它们会丢失固有的顺序信息。为了补偿,他们使用“位置编码”技术来注入有关单词顺序的信息。但是,这可能很棘手,并且可能并不总是完美的。
3.5 变形金刚的应用:一次征服一个序列的世界
凭借其令人印象深刻的功能,Transformers 已迅速成为各种任务的首选模型,尤其是在自然语言处理 (NLP) 领域。让我们来看看变形金刚家族中涌现出的一些超级巨星:
- BERT(来自 Transformer 的双向编码器表示):这种蒙面语言模型就像一个伪装大师,学习预测句子中缺失的单词。它已成为许多 NLP 任务的基本构建块,包括情感分析、问答和文本分类。
- GPT-3(生成式预训练转换器 3):这个语言一代的庞然大物就像一本行走的百科全书,能够以各种风格和格式生成人类品质的文本。它可以写故事、诗歌、文章,甚至代码,突破人工智能的界限。
- 视觉转换器 (ViT):变形金刚不仅限于文本,它们还在计算机视觉领域留下了自己的印记。ViT 将 Transformer 架构应用于图像处理,在图像分类任务上取得了最先进的结果。
而这只是冰山一角!Transformer 也在其他领域掀起波澜,例如音频处理和时间序列分析。它们就像瑞士陆军的机器学习刀,在各种情况下都具有适应性和有效性。
四、使它具体化
变形金刚:注意,注意,注意!
- 好吧,要记住的关键是自我注意力机制,这是变形金刚的秘诀。
4.1 围绕自我关注建立直觉
这就像一场“谁是最重要的词”的游戏。查询、键和值向量是参与者,它们计算注意力权重以找出哪些单词是 MVP。
变形金刚有多个头,就像注意力的九头蛇。每个头都专注于输入的不同方面,使模型具有多维理解。这就像有一个专家团队一起工作来破解密码。
别忘了位置编码!它们就像单词的 GPS 坐标,确保模型不会迷失在序列中。
下面是一个简短的代码片段,向您展示了如何使用预训练的 BERT 模型进行情绪分析:
from transformers import BertTokenizer, BertForSequenceClassification
import torchtokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
inputs = tokenizer("I love this movie!", return_tensors="pt")
labels = torch.tensor([1]).unsqueeze(0) # Positive sentiment
outputs = model(**inputs, labels=labels)
loss = outputs.loss
logits = outputs.logits
print(f"Sentiment: {torch.argmax(logits, dim=1).item()}")所以,你有它 - 一瞥变形金刚的世界及其引人注目的能力。它们彻底改变了我们处理顺序数据的方式,它们对人工智能领域的影响是不可否认的。随着研究和开发的继续,我们可以期待这些注意力驱动的模型带来更多突破性的应用和进步。人工智能的未来一片光明,变形金刚正在引领潮流。
4.2 扩散模型 — 用噪声绘画:生成式 AI 的新时代
现在,让我们从文字转向图像,进入创造力和艺术性的领域。
扩散模型,这个新生代,正在改变图像生成的游戏规则。他们的方法很独特,就像一个艺术家从一张空白的画布开始,逐渐添加细节,直到杰作出现。
忘掉你认为你知道的关于创建图像的一切,因为扩散模型正在翻转脚本,向我们展示了一种全新的噪音绘画方式。
五、新范式:扩散模型
在我们深入了解这些模型如何工作的细节之前,让我们退后一步,了解为什么它们如此重要。
5.1 生成模型:从现有模式创建新数据
生成模型是扩散模型所属的总称,它就是要创建与训练数据相似的新数据。可以这样想:你给一个生成模型看一堆猫的图片,它学习了“猫性”的本质。然后,它可以召唤出全新的、从未见过的猫图片,看起来像是真正的猫科动物。很酷,对吧?
5.2 扩散过程:逐渐添加噪声和反转
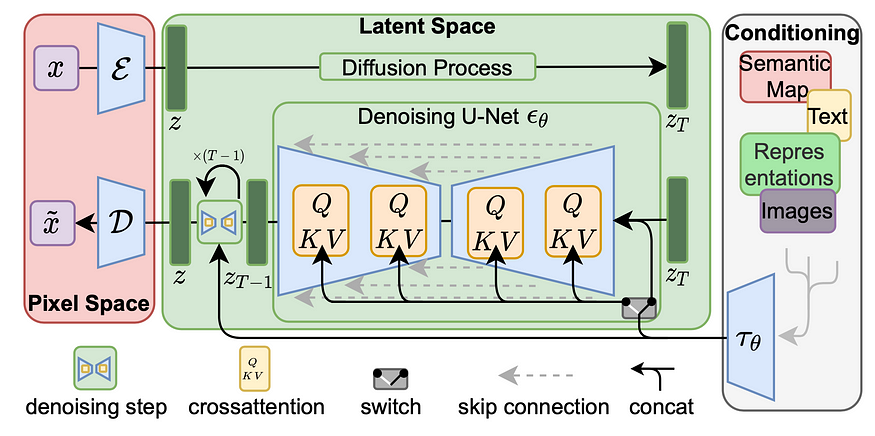
现在,这就是扩散模型变得有趣的地方。他们对这个生成过程采取了独特的方法。想象一下,拍摄一张非常清晰的图像,然后慢慢地向它添加噪点,就像电视屏幕上的静电一样,直到它变成纯粹的、无法识别的噪点。这就是前向扩散过程。
当我们逆转这个过程时,奇迹就会发生。扩散模型学习拍摄噪声图像并逐步逐渐消除噪声,直到恢复原始图像。这就像看着一位技艺精湛的艺术家一丝不苟地去除油漆层,露出下面的杰作。
5.3 学习降噪:训练扩散模型
那么,模型是如何学习这种去噪魔术的呢?我们在海量图像数据集上对其进行训练。该模型看到嘈杂的图像,并尝试预测嘈杂较小的版本。随着时间的流逝,它在这个去噪任务中变得越来越好,本质上是学习逆转扩散过程。
训练完成后,模型可以从纯噪声开始,然后逐步对其进行降噪,直到生成与训练数据相似的全新图像。这就像看着雕塑家在一块大理石上劈开,慢慢地露出里面的美丽形状。
六、扩散模型架构:噪声和有序
扩散模型有几种不同风格,每种模型都有自己独特的去噪和图像生成方法。让我们来探讨一些关键参与者:
6.1 去噪扩散概率模型 (DDPM):开拓者
DDPM是最早获得广泛关注的扩散模型之一。他们使用马尔可夫链来模拟扩散过程,这意味着噪声添加或去除的每个步骤都仅取决于前一步。这使得它们的实施和训练相对简单。
6.2 级联扩散模型:分而治之
级联扩散模型将去噪过程分解为多个阶段,每个阶段由单独的模型处理。这允许对生成过程进行更精细的控制,并可以产生更高质量的图像。这就像让一个专家团队共同努力创造杰作一样。
6.3 基于分数的生成模型:驾驭概率波
基于分数的模型采用的方法略有不同。他们不是直接预测去噪图像,而是估计扩散过程每个步骤的数据分布梯度。该梯度(也称为分数)告诉模型向哪个方向移动以消除噪声并更接近实际数据分布。这就像用指南针导航一样,总是指向想要的目的地。
6.4 优势:生成高质量图像,灵活和创造性的应用程序
扩散模型在创意界掀起波澜是有充分理由的:
- 高质量图像:它们可以生成令人难以置信的逼真和高质量的图像,通常与真实照片无法区分。这就像有一个触手可及的人工智能艺术家,能够创造任何你能想象到的东西。
- 灵活和创造性的应用:扩散模型不仅限于从头开始生成图像。它们还可用于图像绘画(填充图像的缺失部分)、图像到图像的转换(更改图像的样式或内容),甚至生成 3D 模型等任务。
6.5 弱点:训练复杂性、潜在的偏差和伪影
然而,扩散模型也有其挑战:
- 训练复杂度:训练这些模型需要对扩散过程有深入的了解,并仔细优化各种参数。它不适合胆小的人。
- 潜在的偏差和伪影:与任何在数据上训练的模型一样,扩散模型可以反映和放大训练数据中存在的偏差。重要的是要意识到这些偏见并采取措施减轻它们。此外,它们有时会在生成的图像中生成伪影或不切实际的细节。
6.6 使它具体化
扩散模型:噪音,噪音,宝贝!
- 这就像看一个画家创作一幅杰作,一次一笔。前向扩散过程就像在原始图像中添加噪点,直到无法识别为止。反向扩散过程就像艺术家小心翼翼地去除噪音,揭示隐藏在下面的美。
在引擎盖下,这一切都与目标函数有关。对模型进行训练以最小化变分下限或噪声条件得分。这就像在玩一个有噪音的“猜猜是谁”的游戏。
下面是一个代码片段,演示如何使用预训练的扩散模型生成图像:
from diffusers import DDPMPipeline, DDIMSchedulermodel_id = "google/ddpm-cifar10-32"
scheduler = DDIMScheduler(beta_start=0.0001, beta_end=0.02, beta_schedule="linear", num_train_timesteps=1000)
pipeline = DDPMPipeline.from_pretrained(model_id)
image = pipeline(num_inference_steps=1000, output_type="numpy").images[0]七、总结:找到合适的 - 不过度拟合 😜
好了,伙计们,让我们切入正题。我们在RNN、变形金刚和扩散模型的理论宴会厅里跳华尔兹,欣赏它们独特的动作和能力。现在,是时候进入正题并回答这个紧迫的问题了:您为下一个项目选择哪一个?
如果你期待一个简单的答案,一个神奇的公式,每次都能吐出完美的模型,那么,准备好失望吧。这不是自动售货机,您可以在其中打入您的欲望并弹出一个完美包装的解决方案。选择合适的模型是一门艺术,而不是一门科学,它需要敏锐的眼光、一点经验和亲自动手的意愿。

模型军械库里没有银弹
首先要做的是:摒弃一刀切模式的概念。这些架构中的每一个都有自己的包袱、自己的怪癖和偏好。RNN 具有循环机制,擅长处理序列,但它们可能会被长期依赖关系和消失的梯度所绊倒。变形金刚是这个街区的酷孩子,它拥有并行处理和注意力机制,可以征服长序列,但它们的计算要求很高,需要仔细的位置编码。然后是扩散模型,这群艺术家从噪声中召唤出高质量的图像,但它们伴随着训练的复杂性以及潜在的偏差和伪影。
这就像为工作选择合适的工具一样。你不会用大锤来挂相框,也不会试图用螺丝刀盖房子。每种工具都有其用途、优势和局限性。我们的模型动物园也是如此。
八、比较:摊牌
- 好吧,让我们把这些模型放在擂台上,看看它们是如何相互叠加的。这里有一个小比较表,可以清楚地说明问题:

如您所见,每个模型都有自己的优点和缺点。RNN 是 OG,非常适合短期记忆。变形金刚是这个街区的新孩子,拥有花哨的自我注意力机制。和扩散模型?它们是外卡,撼动了图像生成游戏。
但事情是这样的:能力越大,计算责任就越大。转换器和扩散模型可能是真正的资源消耗者,尤其是在训练期间。这就像试图把一头大象塞进迷你冰箱一样——它不会很漂亮。
问题与资源:指路明灯
那么,我们如何驾驭这个模型迷宫呢?首先要清楚地了解两个关键因素:你要解决的问题和你可以使用的资源。
手头的任务:
是序列建模吗?预测句子中的下一个单词、预测股票价格或分析时间序列数据?RNN,尤其是 LSTM 和 GRU,可能是您的首选。
处理自然语言处理?机器翻译、文本摘要还是情感分析?变形金刚凭借其自我关注的超能力,很可能会夺冠。
构思令人惊叹的图像或生成创意内容?扩散模型是人工智能世界的毕加索,随时准备将噪音变成杰作。
资源现实检查: 数据是这些模型的命脉。如果你使用的数据有限,RNN 可能难以有效学习,变形金刚可能会屈服于过度拟合的恶魔。然而,在大数据领域,Transformers和扩散模型都可以真正发挥作用,学习复杂的模式和关系。
但数据并不是唯一的难题。计算资源同样重要。训练这些模型,尤其是较大的 Transformer 和 diffusion 模型,可能需要大量的计算能力和时间。对您可以使用的硬件以及您可以负担得起的培训投资时间要现实。请记住,一个需要很长时间来训练的模型可能不切实际,无论其结果多么令人印象深刻。
技能和生态系统:配角
除了问题和资源的核心因素外,还有其他因素需要考虑。
框架熟悉度:您是 PyTorch 爱好者还是 TensorFlow 爱好者?值得庆幸的是,这三种模型类型在主要的深度学习框架中都有强大的支持,但你对特定框架的熟悉程度可能会影响你的选择。
学习曲线:让我们面对现实吧,这些模型都不是在公园里散步。每个都有自己的一套复杂性和理论基础。了解潜在机制对于有效应用和故障排除至关重要。考虑您自己的舒适度和投入时间学习每种架构的复杂性的意愿。
社区和支持:没有人是一座孤岛,在不断发展的人工智能世界中尤其如此。当您遇到障碍或需要灵感时,强大的社区和现成的资源可能是无价的。寻找具有活跃社区、全面文档以及大量在线教程和示例的模型。
人工智能
的不断变化的沙子 请记住,这种景观远非一成不变。新的架构正在出现,现有模型正在完善,人工智能的功能正在以惊人的速度扩展。今天最前沿的东西明天可能就是旧新闻。及时了解最新进展对于做出明智的决策和充分利用人工智能的潜力至关重要。
杰森·罗尔