设计数据库
- 1. 数据建模
- 1.1 概念模型
- 1.2 逻辑模型
- 1.3 实体模型
- 主键
- 外键
- 外键约束
- 2. 标准化
- 2.1 第一范式
- 2.2 链接表
- 2.3 第二范式
- 2.4 第三范式
- 3. 数据库模型修改
- 3.1 模型的正向工程
- 3.2 同步数据库模型
- 3.3 模型的逆向工程
- 3.4 实际应用建议
- 4. 数据库实体模型
- 4.1 创建和删除数据库
- 4.2 创建表
- 4.3 更改表
- 4.4 创建关系
- 4.5 更改主键和外键约束
- 4.6 字符集和排序规则
- 4.7 存储引擎
1. 数据建模
数据建模的4个步骤:
- 理解需求
理解和分析商业/业务需求,遗憾是很多程序员跳过了这一步就急着去设计数据库里的表和列了,实际上,这一步是最关键的一步,你对问题理解的越透彻,你才越容易找到最合适的解决方案,设计数据库也一样。所以,在动手创建表和列之前,要先完整了解你的业务需求,包括和产品经理、行业专家、从业人员甚至终端用户深入交流以及收集查阅已有的领域相关的表、文件、应用程序、数据库,以及其他与问题领域相关的任何信息或资料。 - 概念建模
当收集并理解了所有相关信息后,下一步就是为业务创建一个概念性的模型。这一步包括找出/识别/确认(identify)业务中的实体/事务/概念(entities/things/concepts)以及它们之间的关系。概念模型只是这些概念的一个图形化表达,用来与利益相关方交流和达成共识。 - 逻辑建模
创建好概念模型后,转而创建数据模型(data model)或数据结构(data structure for storing data),即逻辑建模。这一步创建的是不依赖于具体数据库技术的抽象的数据模型,主要是确认所需要的表和列以及大体的数据类型。 - 实体建模
实体建模指的是将逻辑模型在具体某种DBMS上加以实现的过程,相比于逻辑模型,实体模型会确定更多细节,包括各表主键的设定,各列在某一DBMS下特定的具体的数据类型,默认值,是否可为空,还包括储存过程和触发器等对象的创建。总之,实体模型是在某一特定DBMS下对数据模型非常具体的实现。
1.1 概念模型

案例:建立学生实体并确定相关属性;建立课程实体并确定相关属性;建立两个实体之间的关系。如上图所示。
将实体及其关系可视化的方法,一种是实体关系图(Entity Relationship, ER),一种是统一建模语言(Unified Modeling Language,UML),这里我们用实体关系图(ER),这里采用工具为VISIO。
NOTE: 建模是个迭代过程,不可能第一次就建立完美模型,需要在理解需求和模型设计之间不断反复,多次调整。比如这里的学生属性,可以先确定个大概,之后可以根据需要再进行增删修改。
概念模型主要是从很高的视角来总览业务需求,识别业务中的实体/事务/概念以及他们彼此间的关系,通常这些实体包括人、事件、地点等。只是从概念上总揽全局,目的是和业务人员交流,保持理解一致。
1.2 逻辑模型
逻辑模型是在概念模型的基础上,在不依赖特定数据库系统的前提下确定数据结构,包括细化实体间的关系(常常要为关系创造新的实体),调整字段设置,确定大体的数据类型。总之,逻辑模型会基本确立数据库中的表、列以及表间关系。
对概念模型逻辑化的过程如下:
- 细化实体间关系
考虑学生和课程的关系,首先这是一种多对多关系(通常意味着需要进一步细化);这些属性相对于学生和课程而言都是一对多关系,不管放在学生还是课程身上都不合适,所以应该为学生和课程之间的关系,即注册课程的事件另外设立一个实体 enrollmemt,上面的注册日期和注册价格都应该是这个enrollment 注册事件的属性。 - 调整字段并大体确定字段的数据类型
姓名(name)最好拆分为姓和名 (first_name 和 last_name),同理,地址应该拆分为省、市、街道等等小的部分,这样方便查询。注意课程里的 tags 标签字段不是一个好的设计,之后讲归一化时再来处理。
这里的数据类型只需确定个大概即可,如:是 string,float 而非 VARCHAR, DECIMAL。等到下一步实体模型里再来确定某个DBMS下的具体数据类型。

1.3 实体模型
实体模型(实际模型)就是逻辑模型在具体DBMS的实现,这里我们用MySQL实现的逻辑模型。实体模型是逻辑模型在特定DBMS上的实现,主要是一些技术上的细化,包括确定字段具体数据类型和性质(能否为空等),设置主键等。
- 操作方法:Workbench-file-【new model】新建数据库,上方用 add diagram 作 EER 图,这里EER表示Enhanced Entity Relationship增强型实体关系图。为三个实体创建三张表,设定表名、字段、具体的数据类型、是否可为空(即是否为必须字段),也可以选择设定默认值(主键设定之后再讲)。
NOTE:
- 表名:之前逻辑模型里表名用单数,但这里表名用复数。这只是一种惯例,单复数都行,关键是要保持一致。
- 字段名:以enrollments表为例,注册事件的属性应该是dat日期和pric价格而非enrollment_date注册日期和enrollement_price注册价格,不要将表名前缀加上字段上造成不必要的麻烦,保持精简(keep thingssimple)。
- 数据类型:数据类型要根据业务需要来,例如,和业务人员确认后发现课程价格最高是999美元,所以price价格就可以设定为DECIMAL(5,2),之后如果需求变了了也可以随时更改,不要一上来就设定DECIMAL(9,2),浪费磁盘,注意保持精简(keep things small)
主键
主键就是能唯一标识表中每条记录的字段。(一般用数字ID来确定)
主键要短,可唯一标识记录,且永不改变。我们增加一个 student_id 作为主键,类型设为 INT(最大可表示2亿,一般足够了,但记得总是根据具体的需求决定),设为主键后自动变为不可为空,另外还要设定 AI(AutoIncremental)自动递增,这样会方便许多,不用担心主键唯一性的问题,最后我们把主键拖到表的第一列让表的结构看起来更清晰。

外键
实体模型需要更多得实现细节。

Note: 连线时记不得先连主表还是子表可以看状态栏的提示; MySQL自动添加的外键会带父表前缀,没必要,建议去掉.
注意 enrollments 表的特殊性,它可以说是 students 和 courses 的衍生表,先要有学生和课程,才能有学生注册课程这一事件,后者表述的是前两者的关系,学生和课程是因,注册课程这一事件是果。
MySQL里可以通过一对一或一对多两种连线表达这种先后关系/因果关系并自动建立外键,其中学生和课程被称作父表或主键表,注册事件被称作子表或外键表,外键是子表里对父表主键的引用。
根据表间关系给enrollments表添加了student_id和course_id两个外键,enrollments 的主键设置有两个选择:
- 将这两个外键作为联合主键;
- 另外设置一个单独的主键 enrollment_id。
- 联合主键可以防止同一个学生重复注册同一门课程,因为主键(这里是联合主键)是唯一不可重复的,这可以防止一些不合理的数据输入。坏处是如果 enrollments 未来有新的子表,就需要复制两个字段(而不是 enrollment_id 这样的一个字段)作为外键,这也不一定是很大的麻烦,要根据数据量以及子表是否还有子表等情况来考虑,在一定情况下可能会造成不必要冗余和麻烦(相对于将 enrollment_id 一个字段作为主键来说)。
创建表之间关系和设置ID时,先考虑当下的情况。
外键约束
有外键时,需要设置约束以防止数据损坏/污染(不一致)。
右边 Foreign KeyOptions 可分别选择当父表里的主键被修改或删除(Update / Delete)时,子表里的外键如何反应,有三种选项:
- CASCADE: 瀑布/串联/级联,表示随着主键改变而改变,如主键某学生的student_id从1变成2,则改学生的所有注册课程记录的 student_id也会全部变为2(注意主键一般也最好是永远不要变的,这里讨论的是特殊情况)
- RESTRICT/NO ACTION: 等效,作用都是禁止更改或删除主键。如:对于有过注册记录的课程,除非先删除该课程的注册购买记录,不然不能在 courses表里删除该课程的信息。(另外注意:MySQL 里外键默认的 On Update 和 On Delete 的反应都是 NO ACTION)
- SET NULL: 就是当主键更改或删除时,使得相应的外键变为空,这样的子表记录就没有对应的主键和对应的父表记录了(no parent),被称为孤儿记录(orphan record),这是垃圾数据,让我们不知道是谁注册的课程或不知道注册的是什么课程,一般不用,只在极其特殊的情况可能有用.
- 通常对于 UPDATE, 设置为 CASCADE 级联,随之改变.
对于 DELETE,看情况而定,可能设置为 CASCADE 随之删除 也可能设置为 RESTRICT / NO ACTION 禁止删除。不要死板,永远按照业务/商业需求来选择,这也正是为什么之前强调“理解业务需求”是最重要的一步。比如我们课程注册记录里包含购买价格信息,则应该禁止删除,否则之后想查询某课或某时间段的收入情况就不能实现,相反如果只是个用户登录并设定一系列提醒的软件,可能用户允许用户注销并删除所有提醒就没什么大不了的,但万一,我们需要这些提醒记录来进行统计,则又该设置为禁止删除,总之一定要根据具体业务需求来(always check with the business)。
2. 标准化
正式建立数据库前我们先要检查并确定现在的设计是最优化的(optimal),关键是没有任何冗余或重复,简洁且便于修改和保持一致性。重复数据会占用更多空间并且使得增删查改的操作复杂化,比如,如果用户名在多处出现的话,一旦更改用户名就要到多处更改否则就会使得数据不一致,出现无效数据。
为了防止重复冗余,需要遵循数据库设计的7大规则或者说7大范式,每一条都是建立在你已经遵循了前一条的基础上。实际上,99%的数据库之需要遵循前3大范式就够了。
2.1 第一范式
第一范式要求一行中的每一个单元格都应该有单一值,且不能出现重复列。Each cell should have a single value and we cannot have repeated columns。
案例:courses 里的 tags 标签列就不符合第一范式。tags 列用逗号隔开多个标签,不是单一值。若将 tags 分割成多列,每个标签一列,问题是我们不知道到底有多少标签,每次出现新标签就要改动表结构,这样的设计很糟糕。这也正是范式1要求没有重复列的原因。因此将tags列单独拉出生成表。

2.2 链接表

建立courses和tags之间的联系,发现两者是多对多关系(MySQL里只有一对一和一对多,没有多对多),这说明两者的关系需要进一步细化,我们添加一个course_tags表来专门描述两者间的关系,记录每一对课程和标签的组合,这个中间表或者说链表(link table)同时是 courses 和 tags 的子表,与这两个父表均为一对多的关系,建立两条一对多连线后MySql自动给 course_tags表增加了两个外键course_id和tage_id(注意去掉自动添加的表前缀),两者构成 course_tags表的联合主键。
建立链表细化多对多关系,这是很常用的一种方法,有时链表只包含引用的两个外键,如course_tags 表,有时链表还包含其它信息,如 enrollments 表。
链表也可以直接用多对多来生成。当表中存在不确定数值的属性列时需要在实体模型中进一步细分。
2.3 第二范式
每个表都应该是单一功能的/应该表示一个实体类型,这个表的所有字段都是用来描述这个实体的。Every table should describe one entity, and every column in that table should describe that entity。
以 courses 表为例,course_id、title、price 都完全是属于课程的属性,放在courses 表里没问题,但注册时间enrollment_date放在courses表里就不合适,因为一个课程可以被多个学生注册所以有多个注册时间,同样的注册时间也不应该是students表的属性,因为一个学生可以注册多门课所以可以有多个注册时间,注册时间应该是属于“注册事件”的属性,所以应该另外建个enrollments表,放在该表里。
总之,第一范式是要求单一值和无重复列,这里第二范式是要求表中所有列都只能是完全描述该表所代表的实体的属性,不属于该实体(如订单表)的、在记录中可重复的属性,应该另外放在描述相应实体的表里(如顾客表)。
案例:courses里的instructors虽然是单一值符合第一范式却不符合第二范式,因为老师不是完全属于课程的属性,老师在不同课程中可能重复。所以,另外建立instructrors表作为父表,包含instructor_id和name字段,其中instructor_id为主键,一对多连接courses表后自动引进courses表作为外键,删除原先的instructor列。还有注意设置外键约束,UPDATE 设置为CASCADE,DELETE设置为NO ACTION,也就是instructor_id会随着instructors表更改,但不允许在某教师有课程的情况下删除该教师的信息。

2.4 第三范式
一个表中的字段不应该是由表中其他字段推导而来。A column in a table should not be derived from other columns.
案例:
- invoices 发票表里假设有三个字段:发票额、支付额 和 余额,第三个可以由前两个相减得到所以不符合3NF,每次前两者更新第三个就要随之更新,假设没有这样做,让三者出现了 100,40,80 这样不一致的数据,就不知道到底该相信哪个了,余额到底是 80 还是 100-40=60?
- 如果表里已经有 first_name 和 last_name 就不该有 full_name,因为第三者总是可以由前两者合并得到不管是上面的 余额balance 还是 全名fullname,都是一种冗余,应该删除。
这些范式目的:减少数据重复和冗余,增强数据的一致性和完整性。
3. 数据库模型修改
3.1 模型的正向工程
通过模型正向搭建数据库:workbench 菜单的 Database 选项 → Forward Engineer 正向搭建数据库。依据向导保持默认不断点下一步就好了,不要更改,除非你知道你在做什么。
最后一步会展示对应的SQL代码,里面有创建 school 数据库(schema 架构;模式;纲目;结构方案)以及各表的SQL代码,之后会详细讲。可以选择保存代码为文件(以保存到仓库中)或者复制到剪贴板然后到workbench查询窗口里以脚本方式运行,这里我们直接运行,返回local instance连接刷新界面就可以看到新的school数据库和里面的6张表了。
3.2 同步数据库模型
之后可能会修改数据库结构,比如更改某些表中字段的数据类型或增加字段之类,如果只是自己一个人用的一个本地数据库,可以直接打开对应表的设计模式并点击更改即可,但如果是在团队中工作通常不是这样。在中大型团队中,我们通常有多个服务器来模拟各种环境,其中有:
- 生产环境production environment:用户真正访问应用和数据库的地方;
- 模拟环境staging environment:与生产环境十分接近;
- 测试环境testing environment:存粹用来做测试的
- 开发环境development environment
每次需要对数据库做修改时我们需要复制相同的修改到不同的环境以保持数据的一致性。
***操作:***所以不能是在设计模式中直接点击修改,相反,是在之前模型标签(注意模型可以保存为一个 MySQL 模型文件,下次可以直接打开使用)里的实体模型图(EER Diagram)中修改表或字段,并使用菜单中的 Database →Synchronize Model ( 用 模 型 创 建 数 据 库 时 用 Forward Engineer , 对 已 有 数 据 库 进 行 同 步 修 改 时 用Synchronize Model ) 。 注 意 点 开 Synchronize Model 后 可 以 选 择 连 接 。
3.3 模型的逆向工程
为数据库创建模型,之后可以在模型上更改,便于同步各个环境下的数据库数据。
模型图中实线和虚线表示强联系和弱联系,实线表示must be,虚线表示may be。
Note:
- 关闭当前 Model,不然之后的逆向工程结果会添加到当前模型上,最好是每个数据库都有一个单独的模型,除非数据库间相互关联否者不要在一个模型中处理多个数据库.
- Database → Reverse Engineer,可以选择目标数据库,如上说所,除非数据库相互关联,否者最好一次只逆向工程一个数据库,让每个数据库都有一个单独的模型.
- 可以对逆向的表格进行筛选。
在反向搭建出的模型中,可以更好的看到和理解数据库的结构设计,可以修改表结构(并将相关修改脚本保存并用于其它环境的数据库),还可以发现问题。尽量消除没有关联的表格。
3.4 实际应用建议
- 不要死记范式规则,重点在于消除冗余,减轻数据库复杂度
比如发现一个name字段下出现的是一些重复的名字而不是重复的外键(如某种id),那就说明设计还不够归一化,具体违反哪条范式并不重要,关键是专注于避免重复性。 - 不要对什么都建模
简单才是最高境界。Simplicity is the Ultimate Sophistication. - 第六范式:不要在关系型数据库中再建关系型数据结构。
设计数据库时总是考虑当前的业务需求,不要试图包罗万象,总有开发人员会考虑各种未来可能出现的需求,实际上大部分那些需求都从未发生,反而使得数据库增加了很多没必要的复杂性,复杂化了查询并拖慢了执行效率.
建立复杂模型不是本事,让模型尽可能优美简单易懂又能满足目前的需求这才是本事,如果还能有不错的拓展性以满足未来可能的新特性就更好了.
尽可能保持简洁,简洁才是终极哲学,无论你对未来的预测有多好,总会有意料之外的需求出现,总有一天你会写脚本改数据库甚至进行数据迁移,这是避免不了的,当前只需考虑如何最好地满足目前的需求就好了,不要企图对全宇宙建模。
4. 数据库实体模型
4.1 创建和删除数据库
用workbench的向导来创建和修改数据库能够提高效率,但作为 DBA (Database Administrator 数据库管理员),你必须要能理解并审核相关代码,确保其不会对数据库有不利影响,而且也有能力手动写代码完成创建和修改数据库的操作,可以不依赖(图形化和向导)工具。
创建和删除数据库代码:
CREATE DATABASE IF NOT EXISTS sql_store2;
DROP DATABASE IF EXISTS sql_store2;
4.2 创建表
DROP DATABASE IF EXISTS sql_store2;
CREATE DATABASE IF NOT EXISTS sql_store2;
-- 没有就创建,有就删除
USE sql_store2; -- 创建数据库后一定要选择相关数据库
DROP TABLE IF EXISTS customers;
CREATE TABLE IF NOT EXISTS customers(customer_id INT PRIMARY KEY AUTO_INCREMENT,first_name VARCHAR(50) NOT NULL,points INT NOT NULL DEFAULT 0,email VARCHAR(255) NOT NULL UNIQUE
);
NOTE:
- 创建对象(不管是数据库还是表)有两种方式,DROP …… IF EXIXTS ……; CREAT …… 和 CREAT …… IF NOT EXISTS ……,注意两种方式的区别在于,当原对象存在时,前者是推倒重建,后者是保持原状放弃创建(所以按通常的需求来看还是前者更符合)。
- 括号中设置列的方式为 列名 数据类型 各种列性质,列间逗号分隔,常用的列性质有PRIMARY KEY 、AUTO_INCREMENT、 NOT NULL 、DEFAULT 0、 UNIQUE。
4.3 更改表
ALTER TABLE customersADD COLUMN last_name VARCHAR(50) NOT NULL AFTER first_name,ADD city VARCHAR(50) NOT NULL,MODIFY COLUMN first_name VARCHAR(60) DEFAULT '',
DROP COLUMN points;
NOTE:
- COLUMN 是可选的,有的人喜欢加上以增加可读性;
- AFTER first_name 是可选的,不加的话默认将新列添加到最后一列;
- MODIFY 修改已有列,经实验发现其实应该是重置该列(= DROP + ADD),所以注意要列出全部类型和属性信息,如上例中将 first_name 修改为 VARCHAR(60) 类型并将默认值修改为空字符串’',但忘了加 NOT NULL,刷新后发现 first_name 不再有 NOT NULL 属性;
- 列名最好不要有空格,但如果有的话可用反引号包裹,如
last name. - 修改表永远不要直接在生产环境中进行,要首先在测试环境进行,确保没有错误和不良影响后再到生产环境进行修改。
4.4 创建关系
CREATE DATABASE IF NOT EXISTS sql_store2;
USE sql_store2;
DROP TABLE IF EXISTS orders;
DROP TABLE IF EXISTS customers;
CREATE TABLE customers(customer_id INT PRIMARY KEY AUTO_INCREMENT,first_name VARCHAR(50) NOT NULL,points INT NOT NULL DEFAULT 0,email VARCHAR(255) NOT NULL UNIQUE
);
CREATE TABLE orders(order_id INT PRIMARY KEY,customer_id INT NOT NULL,order_date DATE NOT NULL, -- 在添加完所有的列之后设置外键FOREIGN KEY fk_orders_customers(customer_id)REFERENCES customers(customer_id)ON UPDATE CASCADEON DELETE NO ACTION
);
Note:
- 外键名的命名习惯:fk_子表_父表
- 语法结构:
FOREIGN KEY 外键名 (外键字段)
REFERENCES 父表 (主键字段)
-- 【设置外键约束】
ON UPDATE CASCADE
ON DELETE NO ACTION
- 应该把orders表(子表)的DROP语句放到最前面,不然第二次运行会出问题。
4.5 更改主键和外键约束
USE sql_store2;
ALTER TABLE ordersDROP PRIMARY KEY,ADD PRIMARY KEY (order_id),DROP FOREIGN KEY fk_orders_customers,ADD FOREIGN KEY fk_orders_customers (customer_id)references customers (customer_id)ON UPDATE CASCADEON DELETE NO ACTION;
Note:
- 这里不管是之前创建orders表时设置外键还是这里通过修改ADD增加外键,外键名明明写的是 fk_orders_customers,实际上都会变成 orders_ibfk_1,要去设计模式手动修改才行,可能是bug
- 通过类似的 ALTER TABLE 语句增删主键:可增加多个主键,在括号内用逗号隔开,注意说的是 ADD 其实是重置,所以一次要把该表所有需要的主键声明完整。
4.6 字符集和排序规则
字符是以数字序列的形式储存于电脑中的,字符集是数字序列与字符相互转换的字典,不同的字符集支持不同的字符范围,有些支持拉美语言字符,有些也支持亚洲语言字符,有些支持全世界所有字符,查看MySQL支持的所有字符集:
SHOW CHARSET;
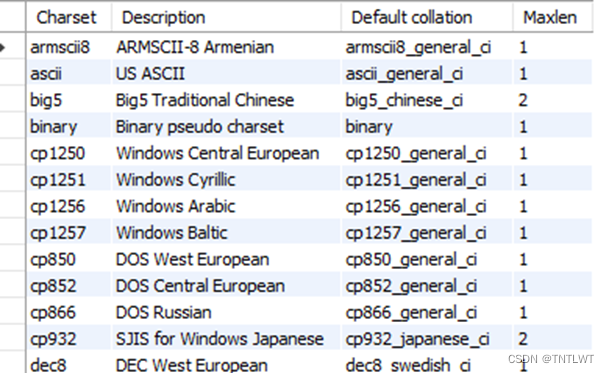
其中armscii8支持亚美尼亚语,big5支持繁体中文,gb2312和gbk支持简体中文(gk是国标的拼音简称,k是扩展的拼音简称),而utf-8支持全世界的语言,utf-8也是MySQL自版本5之后的默认字符集。还可以看到字符集描述,默认排序规则,最大长度。
排序规则(collation)指的是某语言内字符的排序方式,utf-8的默认排序规则是utf8_general_ci,其中ci表示case insensitive大小写不敏感,即MySQL在排序时不会区分大小写,这在大部分时候都是适用的,比如用户输入名字的时候大小写不固定,我们希望只按照字符顺序而不管大小写来对名字进行排序。总之,99.9%的情况下都不需要更改默认排序规则。
对于字符集来说,大部分时候用默认的utf-8就行了。但有时,我们可以通过更改字符集来减少空间占用,例如,我们某个特定的应用(对应的数据库)/特定表/特定列是只能输入英文字符的,那如果将该列的字符集从utf-8改为latin1,占用空间就会缩小到原来的1/3,以字段类型为CHAR(10)(固定预留10个字符)且有1百万条记录为例,占用空间就会从约30MB减到10MB。接下来将如何用菜单和代码方式更改库/表/列的字符集。
-
Workbench更改办法
- 菜单方式更改字符集:右键sql_store2 数据库,点击 Schema Inspector可查看;
- 要修改库或者表和列的字符集,直接点开库或者表的设计模式(扳手按钮)在里面选择更改即可。
-
代码更改
1)在创建数据库时设置字符集或更改已有数据库字符集
CREATE/ALTER DATABASE db_name
CHARACTER SET latin1
2)在创建表时设置字符集或更改已有表的字符集
CREATE/ALTER TABLE table1
(……)
CHARACTER SET latin1
3)在创建表时设置列的字符集
CREATE TABLE IF NOT EXISTS customers(
customer_id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) CHARACTER SET latin1 NOT NULL,
points INT NOT NULL DEFAULT 0,
email VARCHAR(255) NOT NULL UNIQUE)
4.7 存储引擎
在MySQL中我们有若干种储存引擎,储存引擎决定了我们数据的储存方式以及可用的功能.
SHOW ENGINES;
储存引擎有很多,我们真正需要知道只有两个:MyISAM(读作 My-I-SAM) 和 InnoDBMyISAM是曾经很流行的引擎,但自MySQL5.5之后,默认引擎就改为InnoDB了,InnoDB支持更多的功能特性,包括事务、外键等等,所以最好使用InnoDB引擎是表层级的设置,每个表都可以设置不同的引擎(虽然这没必要)。
外键是十分重要的,它可以增加引用一致性/完整性(referential integrity),如果我们有一个老数据库的引擎是 MyISAM,我们想要给它设置外键,就必须要将其引擎升级为 InnoDB,可以在表的设计模式里选择更改,也可以用修改表的代码:
ALTER TABLE customers
ENGINE = InnoDB;
改变引擎是一个代价极高(expensive)的操作,它会重建整个表,在此期间无法方法访问数据。所以,不要轻易在生产环境中改变储存引擎,除非有特殊的理由。