欢迎点击关注下方公众号并加入官方读者交流群,一个有趣有AI的AIGC公众号:关注AI、深度学习、计算机视觉、AIGC、Stable Diffusion、Sora等相关技术,欢迎一起交流学习💗~

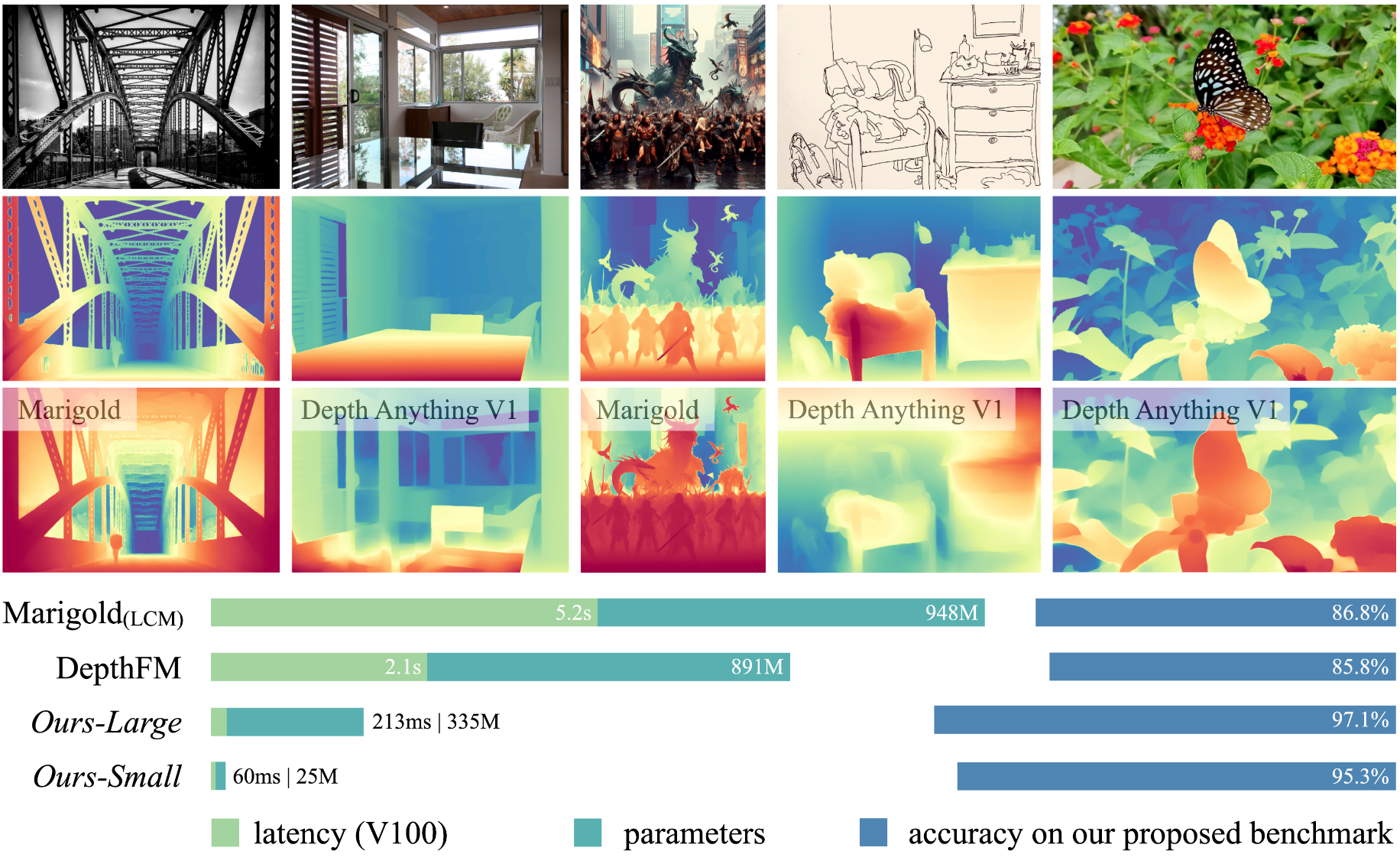
字节发布Depth Anything V2深度模型。比 Depth Anything V1 更精细的细节。与基于 SD 构建的模型相比效率显著更高(快了10倍以上)且更准确。提供了不同规模的模型(参数从25M到1.3B不等),以支持各种应用场景。分别针对室内和室外场景发布了三个尺度的 六种度量深度模型。
通过三个关键实践产生了更精细和更鲁棒的深度预测:
-
用合成图像取代所有标注的真实图像,
-
扩大教师模型的容量,
-
通过大规模伪标注的真实图像作为桥梁来教授学生模型。
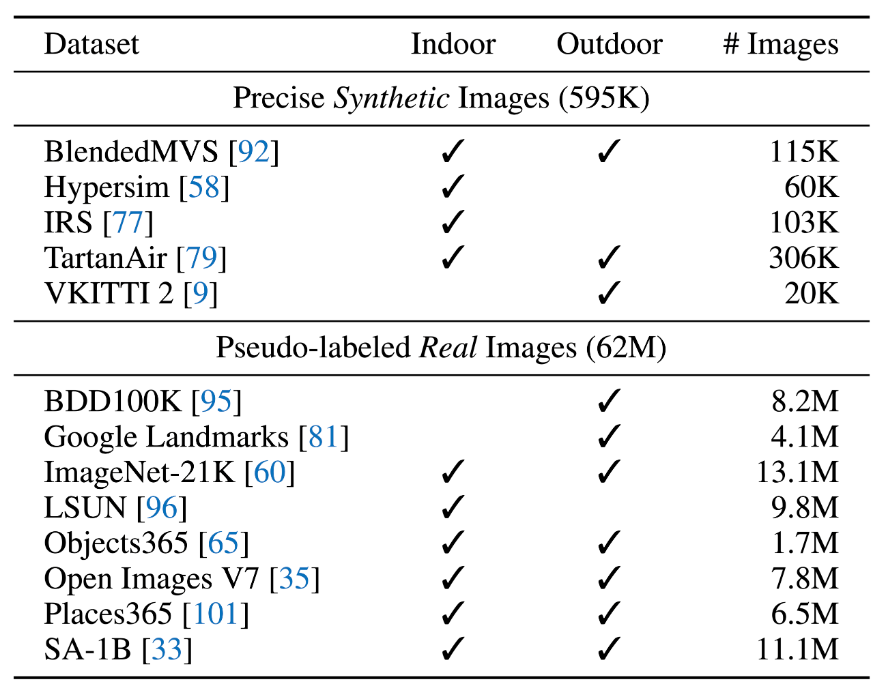
Depth Anything V2基于595K张合成标记图像和62M+张真实未标记图像进行训练,提供最强大的单目深度估计(MDE)模型。
相关链接
论文地址:https://arxiv.org/abs/2406.09414
代码地址:https://github.com/DepthAnything/Depth-Anything-V2
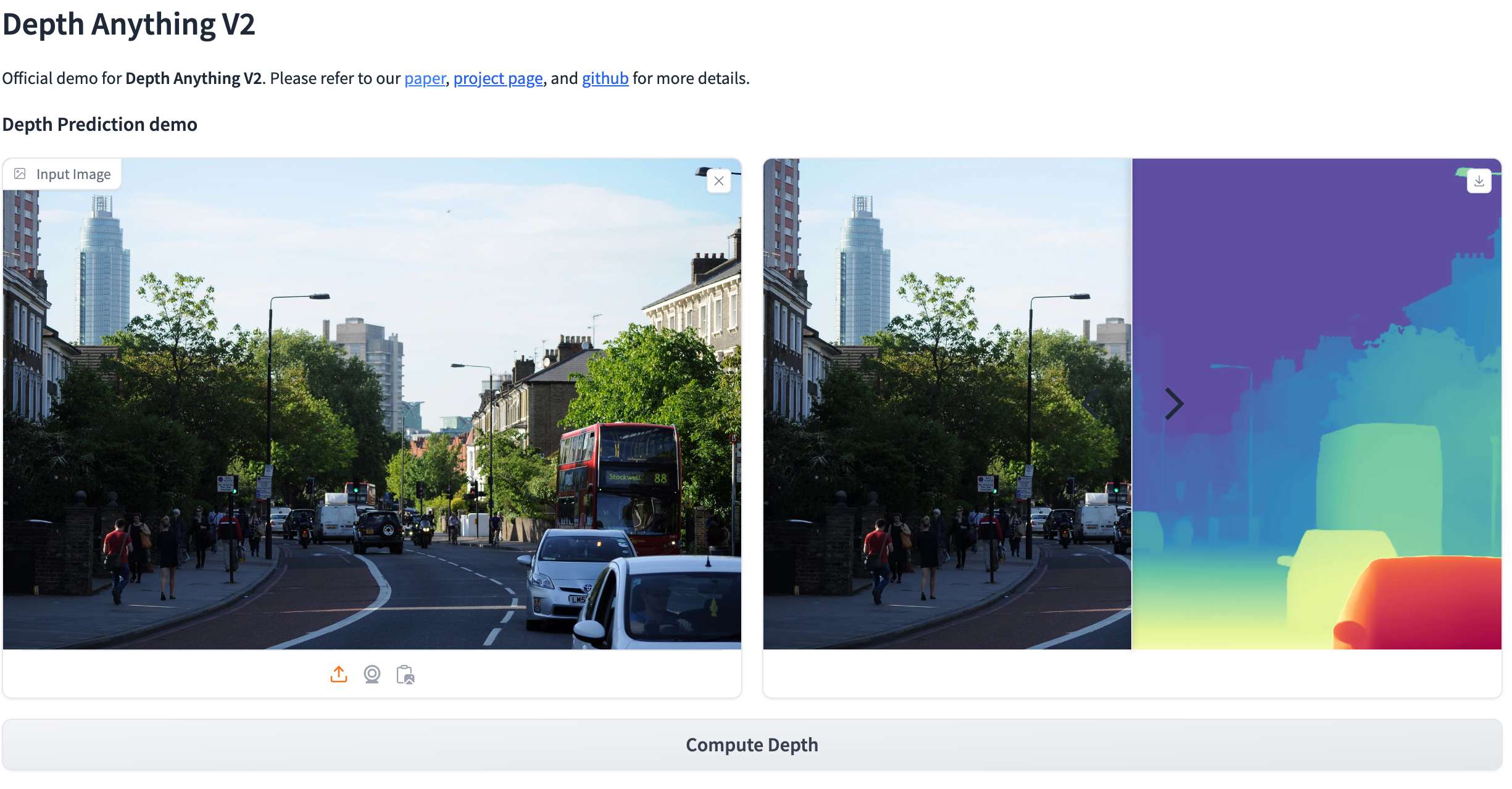
试用链接:https://huggingface.co/spaces/Depth-Anything/Depth-Anything-V2
论文阅读

摘要
这项工作提出了 Depth Anything V2。我们不追求花哨的技术,而是旨在揭示关键发现,为构建强大的单目深度估计模型铺平道路。值得注意的是,与 V1 相比,此版本通过三个关键实践产生了更精细、更稳健的深度预测:
-
用合成图像替换所有标记的真实图像;
-
扩大我们的教师模型的容量
-
通过大规模伪标记真实图像的桥梁教授学生模型。
与基于稳定扩散构建的最新模型相比,我们的模型效率更高(速度快 10 倍以上)且更准确。我们提供不同规模的模型(从 25M 到 1.3B 参数不等)以支持广泛的场景。得益于它们强大的泛化能力,我们使用度量深度标签对它们进行微调以获得我们的度量深度模型。除了我们的模型之外,考虑到当前测试集中的多样性有限和频繁的噪声,我们构建了一个具有稀疏深度注释的通用评估基准,以方便未来的研究。
方法
我们首先在纯合成图像上 训练一个初始的最大教师模型(基于 DINOv2-Giant)。然后,它为大规模未标记的真实图像生成高质量的伪标签。最后,仅在伪标记的真实图像上训练学生模型。

效果展示
与Depth Anything V1在细粒度细节上的比较



与 Depth Anything V1 的稳健性比较



与 Marigold 和 Geowizard 的比较




视频深度可视化
注意: Depth Anything V2是一种基于图像的深度估计方法,我们使用视频只是为了更好地展示我们的优势。





数据覆盖范围
我们使用595K张合成图像来训练初始最大的教师模型,并使用62M+张真实伪标记图像来训练最终的学生模型。
结论
在这项工作中,我们提出了 Depth Anything V2,这是一种更强大的单目深度估计基础模型。它能够
-
提供稳健且细粒度的深度预测;
-
支持具有各种模型大小(从 25M 到 1.3B 参数)的广泛应用
-
作为一种有前途的模型初始化,可以轻松微调到下游任务。
我们揭示了关键的发现,为构建强大的 MDE 模型铺平了道路。此外,考虑到现有测试集中的多样性较差和噪声丰富,我们构建了一个多功能评估基准 DA-2K,涵盖了具有精确且具有挑战性的稀疏深度标签的各种高分辨率图像。
