目录
一、了解什么是字体加密
二. 定位字体位置
三. python处理字体
1. 工具库
2. 字体读取
3. 处理字体
案例1:起点
案例2:字符偏移:
5请求数据 - 发现偏移量
5.4 多套字体替换
套用模板
版本1
版本2
四.项目实战
1. 采集目标
2. 逆向结果
一、了解什么是字体加密
字体加密是页面和前端字体文件想配合完成的一个反爬策略。通过css对其中一些重要数据进行加密,使我们在代码获取的和在页面上看到的数据是不同的。
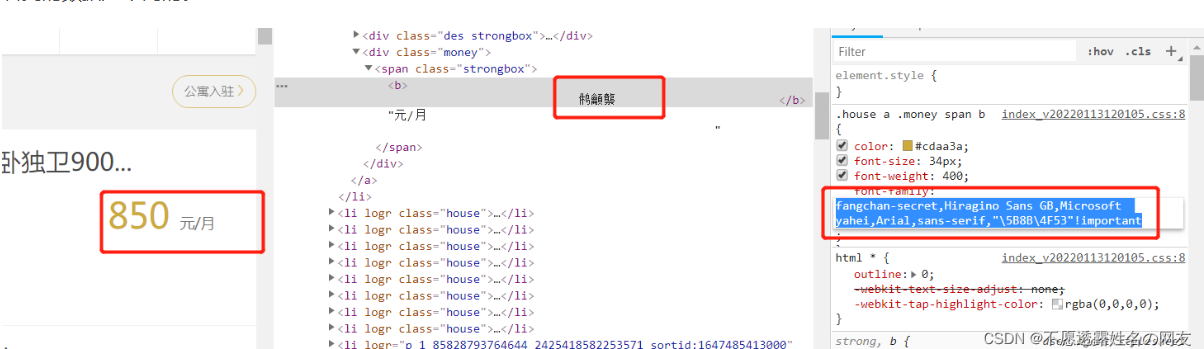
前端人员通过使用font-face来达到这个目的,font-face是CSS3中的一个模块,他主要是把自己定义的Web字体嵌入到你的网页中。而font-face的格式为:
@font-face {font-family: <FontName>; # 定义字体的名称。 src: <source> [<format>][,<source> [<format>]]*; # 定义该字体下载的网址,包括ttf,eof,woff格式等
}
二. 定位字体位置
- 字体加密会有个映射的字体文件
- 可以在元素面板搜索@font-face会通过这个标签指定字体文件,可以直接在页面上搜索,找到他字体的网址
-
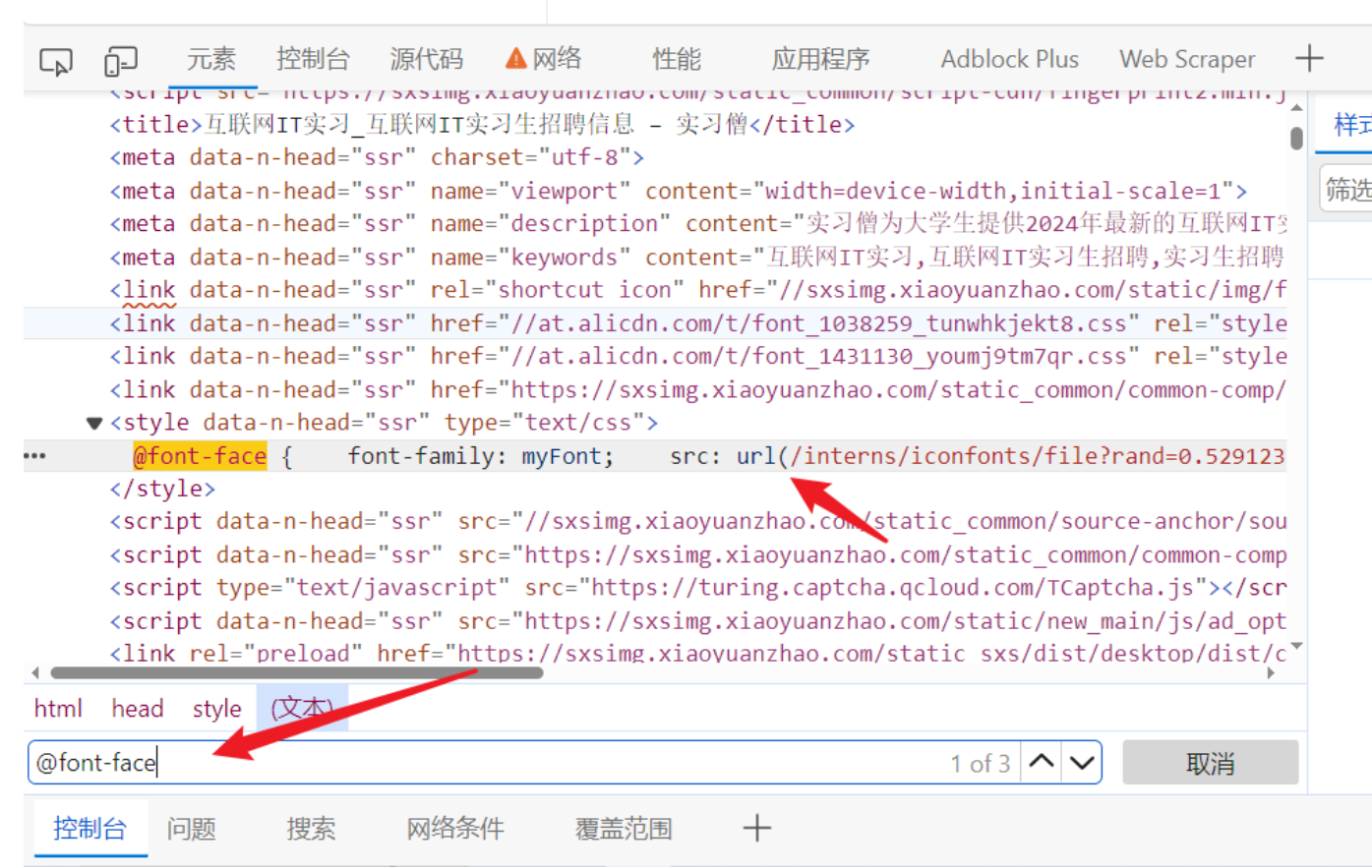
- 可以直接把字体文件下载下来, 文件可以一般需要自己修改后缀(网页的字体后缀一般选用woff)
- TTF:这是Windows操作系统使用的唯一字体标准,macintosh计算机也用truetype字体作为系统字体。
- OTF:这是一种开放的字体格式,支持Unicode字符集,可以在多种操作系统和设备上使用。
- FON:这是Windows 95及之前版本使用的字体格式。
- TTC:这是一种字体集合格式,包含多个字体文件,可以一次性安装多个字体。
- SHX:这是CAD系统自带的一种字体文件,符合了CAD的文字标准,但不支持中文等亚洲语言文字。
- EOT:这是早期网页浏览器使用的字体格式,但现在已经很少使用。
- WOFF:这是一种网页字体格式,可以在网页中使用,也可以转换为.TTF格式用于桌面应用。
- 查看字体文件
- 在线字体解析网站:在线字体编辑器-JSON在线编辑器
- 可以直接把文件拖动到在线网址
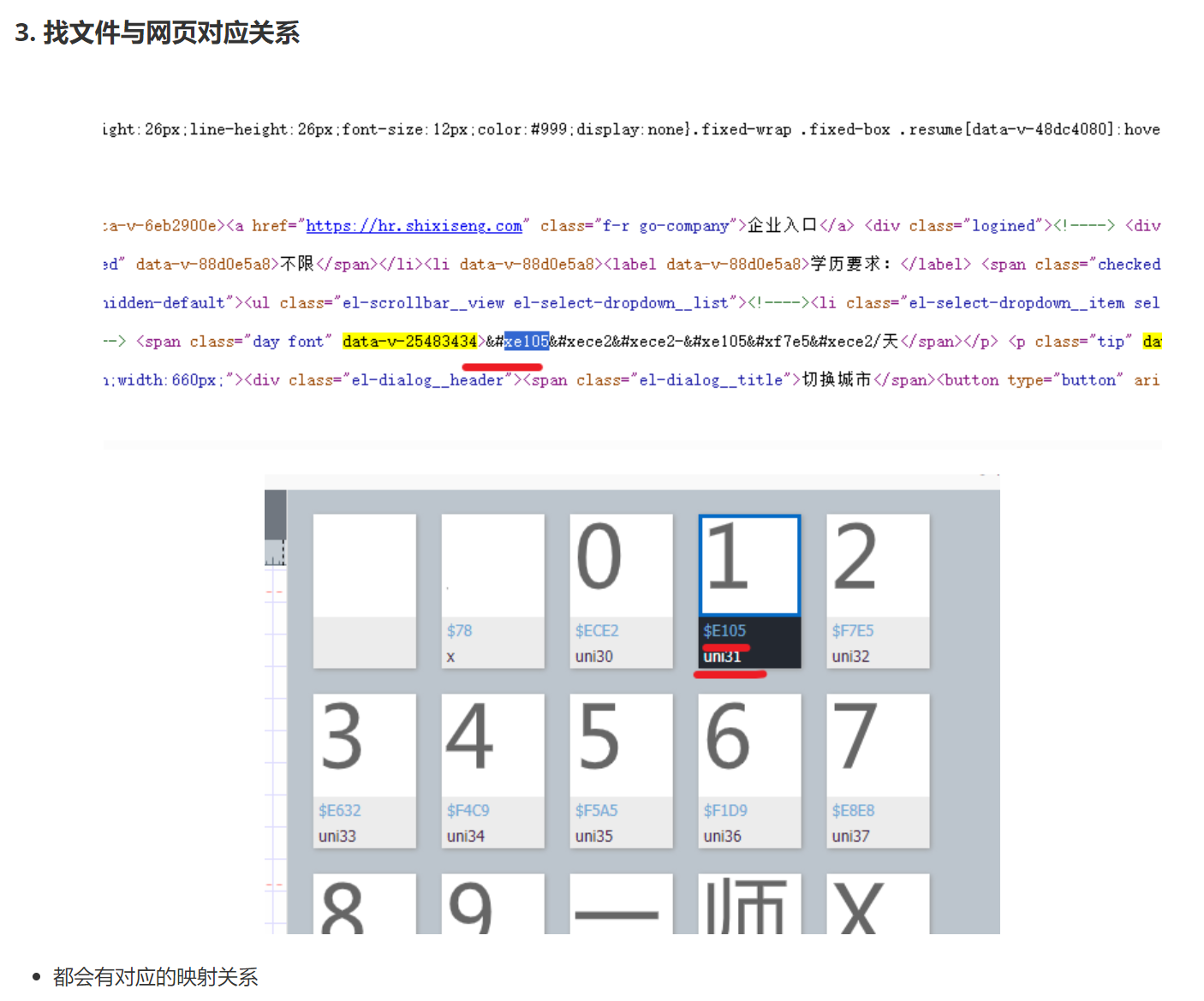
我们抓包一个字体文件,在Font那一列,复制这个url到浏览器就可以下载下来
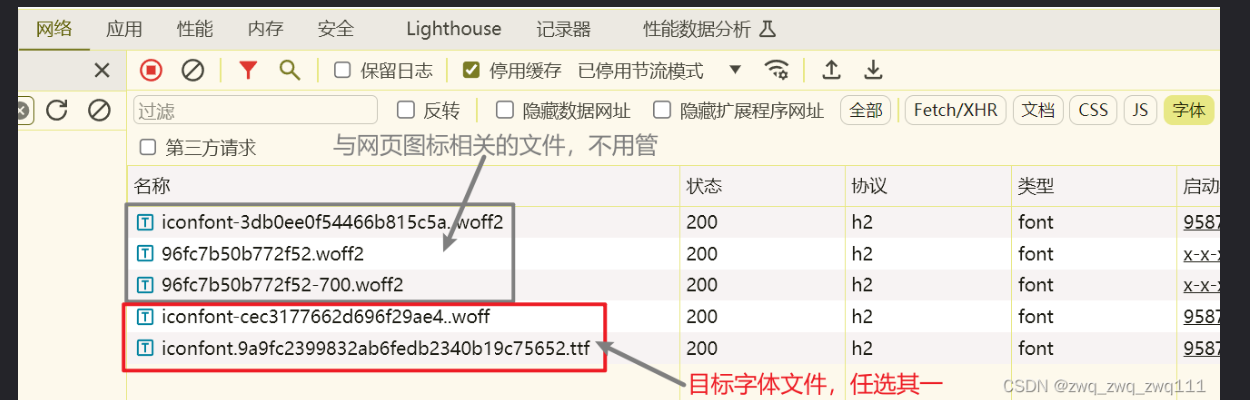
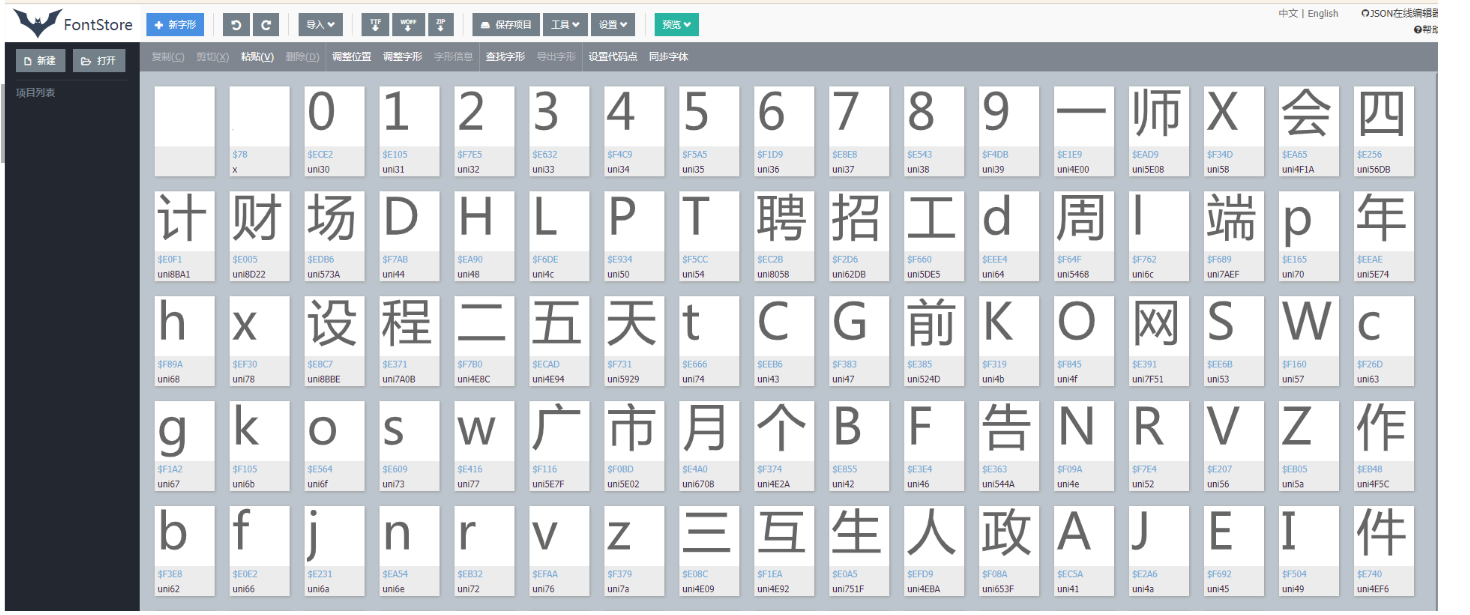
对应页面的数字。页面源码的字符前缀是&#x,woff文件的前缀是uni
三. python处理字体
1. 工具库
pip install fontTools # 使用这个包处理字体文件2. 字体读取
from fontTools.ttLib import TTFont
# 加载字体文件:
font = TTFont('file.woff')
# 转为xml文件:可以用来查看字体的字形轮廓、字符映射、元数据等字体相关的信息
font.saveXML('file.xml')3. 字体读取
from fontTools.ttLib import TTFont
# 加载字体文件:
font = TTFont('file.woff')
kv = font.keys()
print(kv)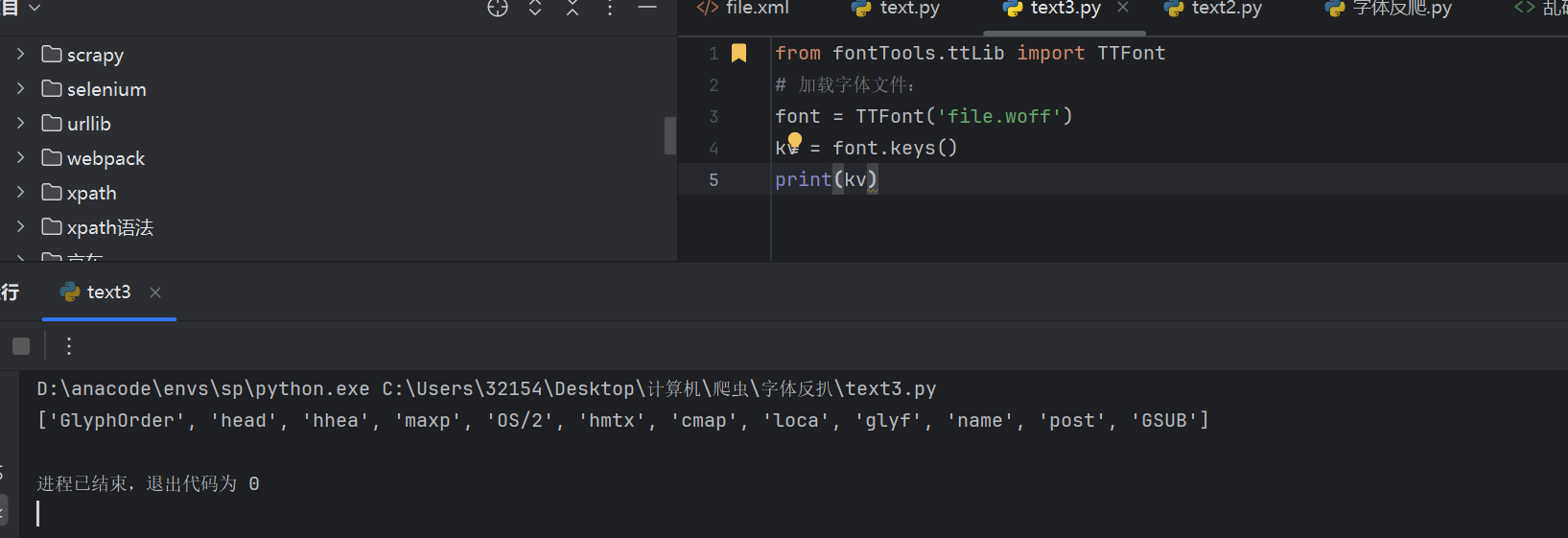
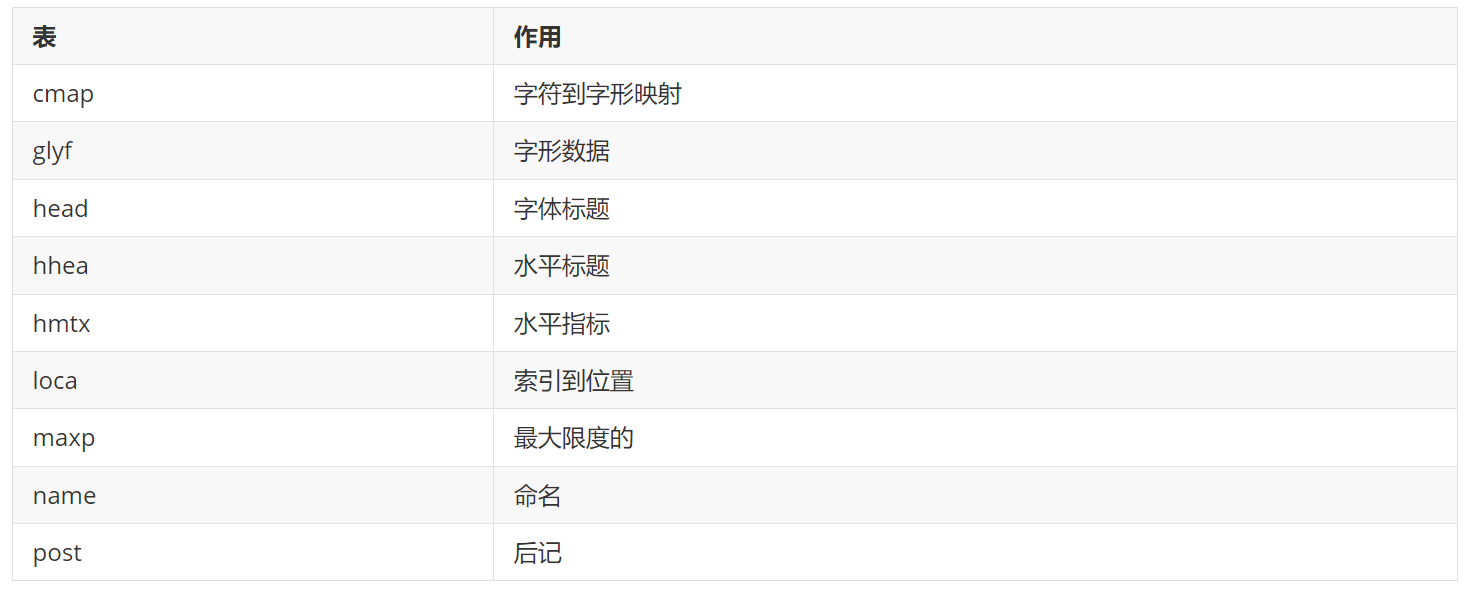
字体文件不仅包含字形数据和点信息,还包括字符到字形映射、字体标题、命名和水平指标等,这些信息存在对应的表中:
然后一些常见方法见 Python_FontTools使用-CSDN博客
3. 处理字体
如果想要把自定义的字体文字变化为系统能够识别的内容,就需要获取自定义字体与通用字体的映射规则,经过转化后就能得到正常文字信息。
字体解密的大致流程:
先找到字体文件的位置,查看源码大概就是xxx.woff这样的文件
重复上面那个操作,将两个字体文件保存下来
用上面的软件或者网址打开,并且通过 Python fontTools 将字体文件解析为 xml 文件
根据字体文件解析出来的 xml 文件与类似上面的字体界面找出相同内容的映射规律(重点)
在 Python 代码中把找出的规律实现出来,让你的代码能够通过这个规律还原源代码与展示内容的映射
案例1:起点
import re
import requestsurl = 'https://www.qidian.com/rank/yuepiao/'
headers = {'Cookie': '_yep_uuid=16401b3f-da18-36f9-250b-44791c444165; e1=%7B%22l6%22%3A%22%22%2C%22pid%22%3A%22qd_P_rank_19%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A5%7D; e2=%7B%22l6%22%3A%22%22%2C%22pid%22%3A%22qd_P_rank_19%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A5%7D; newstatisticUUID=1689595424_1606659668; _csrfToken=6aCHItSuH6xVc1FVDCb7nGXnnDYFr6r6UdurzC7a; fu=801177549; traffic_utm_referer=; Hm_lvt_f00f67093ce2f38f215010b699629083=1689595425; Hm_lpvt_f00f67093ce2f38f215010b699629083=1689595425; _ga=GA1.2.225339841.1689595425; _gid=GA1.2.485020634.1689595425; _ga_FZMMH98S83=GS1.1.1689595425.1.1.1689595594.0.0.0; _ga_PFYW0QLV3P=GS1.1.1689595425.1.1.1689595594.0.0.0','Host': 'www.qidian.com','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}response = requests.get(url=url, headers=headers)
# print(response.text)with open('乱码.html', mode='w', encoding='utf-8') as f:f.write(response.text)"""下载字体文件"""
# format\('eot'\); src: url\('(.*?)'\) format\('woff'\), url\('
font_results = re.findall("format\('eot'\); src: url\('(.*?)'\) format\(