最近旁边的同事老是跟我吐槽他的代码运行有点慢,什么开机用了好几秒,上位机点了好久才有反应,存几个字节数据花了几百毫秒之类的。确实,MCU(单片机)的程序往往都需要处理毫秒级别甚至微秒级别的数据逻辑,如果一个处理流程出现了几百毫秒甚至几秒的等待时间,那往往都是不能被接受的。今天我们就来看看到底哪些因素会影响到程序的运行速度。
1. MCU 的时钟频率
MCU 的时钟频率,常被称为主频,是指由外部晶振或者内部振荡器产生周期性信号的频率,这个信号为单片机提供了一切操作的基本时间单位。每一款型号的MCU都有其最大时钟频率的限值,如 STM32F1 最高为 72MHz,而 STM32F4 最高可达到 180MHz。

这是程序运行速度的硬性指标,其决定了速度的上限。时钟频率越高,其单位时间内能够执行的指令数量就越多,自然对于相同的程序来说运行的就更快。
因此,如果你对程序的运行速度或者数据的处理周期有严苛的需求,那么首先你要选一个合适型号的MCU,确保其最大时钟频率能够满足你的需求。
2. 内存访问速度
程序运行的本质就是不断地从内存中获取数据到 MCU 内部寄存器中进行一系列的运算,然后将运算结果再放回内存特定的位置中。因此,内存的访问速度也是影响程序运行速度的重要因素。
一般来说,外扩内存的访问速度会明显比 MCU 内置 RAM 的访问速度低,网上有小伙伴针对于 STM32 内部 SRAM 和外扩 SRAM 的数据读取速度做了验证和对比,最终得到的结果如下图:
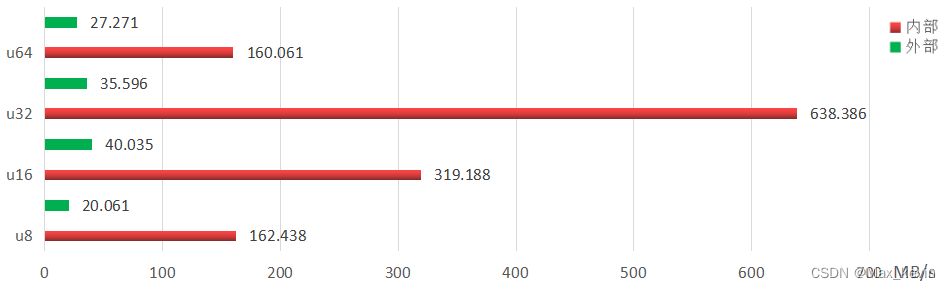
可见区别非常大,在 u32 数据类型的读取上甚至差了 18 倍!并且,即使是在片内,部分型号的 MCU 也会有多个内存区。如 STM32F407 就拥有 SRAM1、SRAM2 和 CCM data RAM 三块内存区:
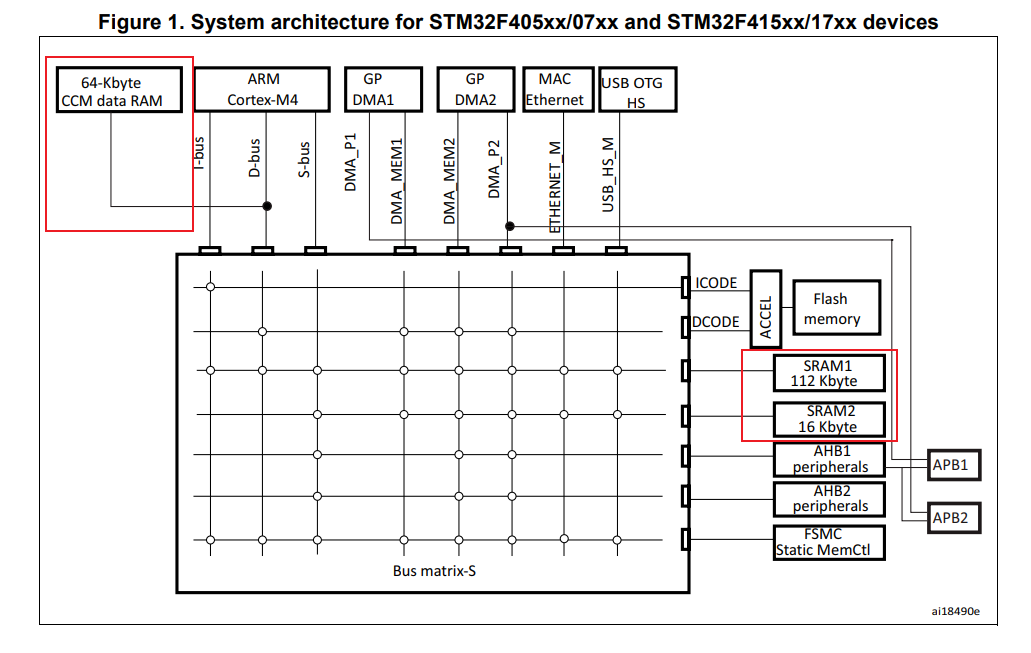
通过上面的总线架构图可以看出 SRAM1 和 SRAM2 非常类似,但是 CCM data RAM 却很奇怪,和上述两个内存块不在同一个位置,但却和内核(ARM Cortex-M4)挨得很近。官方对其的介绍如下:

翻译成中文就是核心耦合内存,并且只能由 CPU 通过 D-BUS 总线访问。网上有很多博文都说该片内存由于和 CPU 离得很近,所以定义在其内部的数据处理速度会非常快,然而经过我的实测,发现实际上在一般情况下定义在 CCM 中数据的运算反而比定义在 SRAM 中的要慢!而测试的代码也很简单:
// ... 省略上方代码
TEST(1); // IO 拉高
for (int i = 0; i < 100000; i++) cnt++;
TEST(0); // IO 拉低
// ... 省略下方代码
其中 TEST() 函数内部就是 IO 的电平控制,用于接入逻辑分析仪抓取中间代码执行的时间。而中间的循环就是对变量的计算。仅改变 cnt 变量的存储区可以发现,当 cnt 变量定义在 SRAM 中时,其耗时如下:

上面的高电平一段就是执行时间,为 7.7 毫秒左右。当 cnt 变量定义到 CCM 中后,其运行结果如下:

可以发现比在 SRAM 中慢了 1ms 多。两次代码差异仅在于变量 i 定义的位置:
#if 1
volatile uint32_t cnt __attribute__((at(0x10000000)));
#else
volatile uint32_t cnt = 0;
#endif
在此我们不展开讨论其原理(网上对于此的资料甚少,我也只是有个猜想,如果有了解的小伙伴可以点击文末的发消息与我讨论!),至少上述实验可以证明即使是数据定义在片内内存的不同区域,其代码执行的速度也是不同的。
因此,在优化代码执行速度的时候,数据或代码存放的位置也是值得考虑的重点。
3. 中断处理机制
在主程序正常运行的过程中,往往会有一些中断来打断其运行,抢夺 CPU 的控制权:

此时 CPU 会转头去处理中断逻辑,而主程序就被 “挂起”,简单来说就是暂停执行。
一般情况下,中断中的处理逻辑是非常短的,如修改一个标志位,或是从寄存器中取出一些数据。这些逻辑通常都是纳秒到几个微秒的级别,这对于主程序的运行不会造成太大的影响,并且很多非周期逻辑也需要中断的介入来提高实时性如外部信号捕获、串口数据传输完成、DMA缓冲区满等。
可见,用好中断可以提高程序的响应速度,但如果用不好中断,则会对你的程序运行速度造成负面影响:
-
中断服务函数的执行时间
上面提到中断中的处理逻辑一般需要非常短,如果你在中断中处理了大量的复杂运算,或者干脆使用了 delay 函数,那你的主程序可就高兴了,因为它们可以很长一段时间不用工作。而你会发现原来只需要几毫秒就能运行完的逻辑现在需要几百毫秒甚至更久,这就完全取决于你中断服务函数的运行时间。
-
中断频率
如果你已经注意了中断服务函数的运行时间,但发现主程序运行的速度还是没有你预期的快,排除主程序本身的逻辑外,你还需要注意中断的频率。
当中断发生时,CPU 需要保存当前主程序的上下文(即保存寄存器状态),然后跳转到中断服务程序中。当中断处理完毕后,再恢复上下文并返回到主程序被中断的位置继续执行。而这个保存和恢复上下文的过程会引入一定的延时,并且当中断服务函数内的执行逻辑非常少,比如只有一个标志位的设置,那么其保存于恢复上下文的耗时甚至会超过中断服务函数本身!此时如果频繁发生中断,则主程序会被频繁打断,并且此时大部分时间执行的都不是核心逻辑。也就是说此时的程序会被一些与业务逻辑完全无关的逻辑所拖慢。
因此控制中断的频率也很重要。
-
中断优先级
如果你的程序中有多个非周期、并且需要实时响应的逻辑,并且各个逻辑的重要性还不一样,如存在一个外部按键需要在按下时被响应,同时还有一个更重要的报警 IO 需要在检测到一个边沿型号的时候立刻去处理报警信息。那么此时就可以用到中断优先级的概念。
一般 MCU 中都能够配置中断优先级。高优先级的中断可以打断低优先级的中断,使得高优先级的中断能够得到更快速的处理。
通过为重要的逻辑分配高优先级,次要的逻辑分配低优先级,可以实现程序的快速响应。虽然你的低优先级任务被打断了,但是由于高优先级任务一般都和用户的交互相关,因此在用户看来你的程序运行仍然是非常 “快” 的。
4. 外设响应的处理方式
一般我们进行 MCU 编程都需要控制各种各样的外设,如串口,IIC,SPI 等等。当我们对外设进行了一些操作如数据的读取写入时往往会要等待各种各样的标志位,有些是准备就绪标志位,有些是可读标志,还有写入完成标志等等。
这些标志代表了外设或对端设备给我们的响应,标志位的变化也是需要时间的,有些是外设自身硬件处理的标志位,在满足一定条件后会自动置位,还有一些是对端设备给出的标志位,存在于返回的数据中。
此时如果我们的代码中存在大量的同步等待逻辑,即在顺序流程中用一段轮询来实时查询这些标志的状态,若标志不满足则继续查询,若满足则顺利执行下面的程序,则会导致 CPU 在外设响应期间都无法处理其他事务,显著降低代码的执行效率。
举个例子,假如用户需要通过屏幕上的一个按钮读取设备的配置信息,然而配置信息非常多,需要1秒才能读完,如果按照上述逻辑,在按下按键后屏幕会卡死,并且这时用户点其他任何按键都没有反应,直到1秒后信息读完显示出来。此时用户就会觉得你这个程序卡了一秒。
这里正确的处理方法是使用异步逻辑去处理,即在等待状态的过程中不会完全占用 CPU 的时间,比如不要使用如下语法:
while (flag != 1) {// 循环等待直到x=1才退出
}而是使用
if(flag == 1){// 标志位置位,处理对应的事件
}else{// 释放 CPU 处理其他事务
}这种方式在外设还没有给出响应之前仍能够继续执行其他任务,虽然外设响应的时间不会发生改变,但在这个过程中,系统是能够正常运行的,甚至还可以给出一些状态提示,以上面那个例子来说,屏幕上可以显示一个 “请等待” 的动画,或者界面可以被切换,等到读取成功后跳出一个读取完成的提示框等,对于用户来说,这个操作是非常流畅的。而且由于在等待过程中主程序仍然能够运行,因此也不会影响主程序的运行速度和效率。
5. 代码效率
你的代码决定了最终 CPU 执行的指令,毫无疑问,这一点对于程序运行速度的影响是最大的。毕竟即使是在十几 MHz 的 51 上实现一个点灯函数的执行速度,也要比在几 GHz 的 PC上跑一个大模型的训练要快上千万倍!
开个玩笑。我们自然是要比对同样逻辑的代码运行速度。这就涉及到以下几点:
-
函数调用
函数调用会涉及到参数的入栈出栈、栈帧的创建和销毁等等,一次的调用可能无关紧要,但若频繁进行函数的调用,尤其在循环中,每一次循环都要进行额外的函数调用操作,则会导致非常大的运行负担,从而拖慢程序运行速度。
此时可以借助于内联函数或者宏,甚至对于一些不会被复用的逻辑,直接去掉封装,减少函数调用所产生的额外开销,从而提高程序运行的速度。
-
循环逻辑
一些低效的代码往往会包含不必要的循环迭代,或是在循环内部进行复杂的运算,而实际上这些计算可以在循环外只执行一次。这种情况下频繁而又没有实际用处的重复逻辑必然会降低程序运行的速度。
同时,一些高级的编程技巧也可以提高代码的运行速度,如循环展开。这个技巧的原理是通过减少循环的迭代次数从而减少循环判断的次数来加快程序运行的速度。
-
编译优化
使用编译器优化选项如(-O3)可以生成更高效的机器码。此时编译器会通过自动在合适的地方使用内联函数,消除无效代码,自动进行循环展开等操作来精简你的代码,使最终的机器码更少,从而提高程序的运行速度。
我们以本文第二节中测试不同内存数据处理速度的例子来看,选取数据定义在 SRAM 中,不开优化,整体的执行时间为7.7毫秒:
打开 Level 3(-O3)优化,同样的代码执行速度如下:

竟然只用了4.4毫秒,加速了近57%!可见编译器优化可以带来很可观的速度提升。
但请注意,由于编译器优化是不可控的,特别是当原代码本身存在一些未定义的行为,那么就有可能导致优化后的代码出现一些问题,同时由于高级别的优化会使生成的代码与原代码之间的映射关系变差从而变得难以调试。这会增大代码维护的难度。
因此,即使编译器的优化确实会加快程序的运行速度,但也不能过度依赖于编译器优化,可以说能把编译器优化用好的前提是编码人员能够写出健壮的代码。从而避免编译器往错误的方向优化从而导致 BUG 的产生。