目录
1. 面向字节流
思考:对于UDP协议来说,是否也存在“粘包问题”呢?
2.TCP 异常情况
3.知识
1.UDP实现可靠传输(经典面试题)
2. 网络抓包 | 爬虫
3.打通文件和 socket 的关系
4.网络层:IP
前置知识
1. 面向字节流
- udp 是面向数据报的
- 文件和 tcp 都是面向字节流的
- 面向字节流:发什么就按照序号收什么,放在缓冲区,用户层决定一次读取多少
- udp 发一个,上层就读一个数据报
- 用户层才有报文的概念,对报文进行处理必须一个一个的处理!将字节流变成一个一个完成的请求
引出了数据包粘包问题:
- 解决思想:明确报文和报文之间的边界
方法:由应用层来解决粘包问题
- 定长报文
- 特殊符号隔开
- 自描述字段(如前面网络版本计数器报头中放着有效载荷长度,我们以\r\n作为间隔把有效载荷长度读到,然后根据有效载荷长度拿到有效载荷)
解释:
- 对于定长的包, 保证每次都按固定大小读取即可; 如Request结构, 是固定大小的, 那么就从缓冲区从头开始按sizeof(Request)依次读取即可;
- 对于变长的包, 可以在包头的位置, 约定一个包总长度的字段, 从而就知道了包的结束位置;
- 对于变长的包, 还可以在包和包之间使用明确的分隔符(应用层协议, 是程序猿自己来定的, 只要保证分隔符不和正文冲突即可)
思考:对于UDP协议来说,是否也存在“粘包问题”呢?
答:不存在
UDP的数据边界:
- UDP报头中包含报文长度字段。
- 每个UDP报文独立地被交付给应用层,具有明确的数据边界。
- 从应用层角度来看,使用UDP时要么收到完整的报文,要么不收,不会出现“半个或多个”报文的情况。
TCP与有效载荷长度:
- TCP是面向字节流的协议,其报头仅包含首部长度而没有有效载荷长度字段。
- TCP通过序号来表征数据起始位置,并利用校验和保证报文完整性。
- 收到TCP报文后,TCP将报头和有效载荷分离,把数据放入缓冲区形成连续的字节流。
- TCP不需要区分每个报文的边界,这些由上层应用程序自行处理。
总结:
- UDP:不存在“粘包问题”,因为每个报文都是独立的且有明确边界。
- TCP:由于其字节流特性及缺乏有效载荷长度字段,依赖于序号和校验和来管理数据传输,并不负责维护报文边界。报文边界需要应用层处理,例如 http 协议~
2.TCP 异常情况
进程终止
- 连接本身是和文件相关的,文件的生命周期是随进程的
- 进程终止:进行正常的四次挥手,连接正常自动断开
机器重启
- 先要杀掉所有的进程
- 再四次挥手。然后OS在慢慢关机在重启
机器断电/网线断开
- 客户端马上就识别到网络发生变化了,但没有机会在和服务器进行四次挥手了,但服务器为连接还在, 一旦服务器有写入操作, 服务器发现连接已经不在了, 就会进行reset.
- TCP自己也内置了一个保活定时器, 会定期询问对方是否还在. 如果对方不在, 也会把连接释放. 关电源也是一样。
3.知识
1.UDP实现可靠传输(经典面试题)
参考TCP的可靠性机制, 在应用层实现类似的逻辑;
例如:
- 引入序列号, 保证数据顺序;
- 引入确认应答, 确保对端收到了数据;
- 引入超时重传, 如果隔一段时间没有应答, 就重发数据;
- …
如果场景要求非常高,就直接使用 TCP
2. 网络抓包 | 爬虫
网络抓包(Network Packet Capture),指的是捕获在网络中传输的数据包的过程。这是网络监控、故障诊断、协议分析、网络安全审计等领域的常见做法。通过抓取并分析网络中的数据包,可以深入了解网络通信的细节,包括但不限于以下内容:
- 数据包内容:可以查看数据包中的具体信息,如源IP地址、目的IP地址、端口号、协议类型(如HTTP、HTTPS、TCP、UDP等)。
- 通信流程:分析数据包在通信过程中的时间顺序和流程,了解数据是如何在网络中流动的。
- 协议分析:对数据包中的应用层协议进行解码,理解应用程序之间的交互细节。
- 性能分析:通过捕获的数据包,可以分析网络延迟、丢包率等性能指标。
- 安全问题:检测网络攻击、异常流量、数据泄露等安全威胁。
网络抓包通常使用以下工具:
- Wireshark:一款流行的网络协议分析工具,功能强大,支持多种协议的解析。
- tcpdump:一个命令行式的数据包分析工具,常用于Linux系统中。
- Microsoft Network Monitor:微软提供的一款网络监控工具,适用于Windows系统。
- Charles:一个针对HTTP/HTTPS的代理抓包工具,常用于移动应用开发和调试。
进行网络抓包时,通常需要以下步骤:
- 选择工具:根据需要选择合适的抓包工具。
- 设置过滤器:根据监控目标设置过滤条件,如只捕获特定IP地址或端口号的数据包。
- 开始捕获:启动抓包工具开始捕获网络中的数据包。
- 分析数据:捕获完成后,分析数据包内容,查找问题所在或获取所需信息。
- 保存和分析结果:将捕获的数据包保存下来,以便后续进一步分析。
网络抓包是一项重要的技能,对于网络管理员、开发人员和网络安全分析师来说尤其如此。然而,需要注意的是,未经授权进行网络抓包可能会侵犯隐私,因此在实际操作时必须遵守相关法律法规和道德规范。
下载 wireshark
网络爬虫(Web Crawler),又称为网页蜘蛛(Web Spider)或网络机器人(Web Robot),是一种自动化程序,它按照一定的规则自动地浏览互联网上的网页,以搜集网页上的信息。网络爬虫通常用于以下目的:
- 搜索引擎:如谷歌(Google)、百度等搜索引擎使用网络爬虫来索引网页内容,以便用户搜索时能够快速找到相关信息。
- 数据挖掘:企业和研究人员可能使用网络爬虫来收集大量的网络数据,用于市场分析、社会研究或学术研究。
- 信息监控:监控特定网站或论坛的更新,比如新闻网站、股票市场信息等。
网络爬虫的工作原理通常包括以下几个步骤:
- 种子URLs:爬虫从一个或多个起始网页(种子URLs)开始工作。
- 抓取网页:爬虫访问这些网页,下载网页内容,通常是HTML格式。
- 解析内容:解析下载的网页内容,提取链接和需要的数据。
- 跟踪链接:从解析出的链接中选择下一批要访问的网页,并重复抓取和解析的过程。
- 存储数据:将提取的数据存储在数据库或文件中,供后续处理和分析。
- 去重和更新:在爬取过程中,爬虫会尽量避免重复访问相同的网页,并且会定期更新已抓取的网页内容。
网络爬虫需要遵守一些规则和协议,包括:
- Robots协议(/robots.txt):这是一个位于网站根目录下的文件,它告诉爬虫哪些页面或目录可以抓取,哪些不可以。
- 网站的使用条款:有些网站明确禁止或限制爬虫的活动,因此爬虫需要遵守这些条款。
- 法律法规:在某些国家和地区,网络爬虫的活动可能受到法律的限制,特别是在涉及个人隐私和数据保护方面。
网络爬虫可以是简单的脚本,也可以是复杂的系统,它们的设计和实现可以根据目标网站的结构、所需的抓取深度和广度、以及抓取数据的用途而有所不同。在使用网络爬虫时,应当尊重网站所有者的权利和用户的隐私,合理合法地使用爬取的数据。
3.打通文件和 socket 的关系
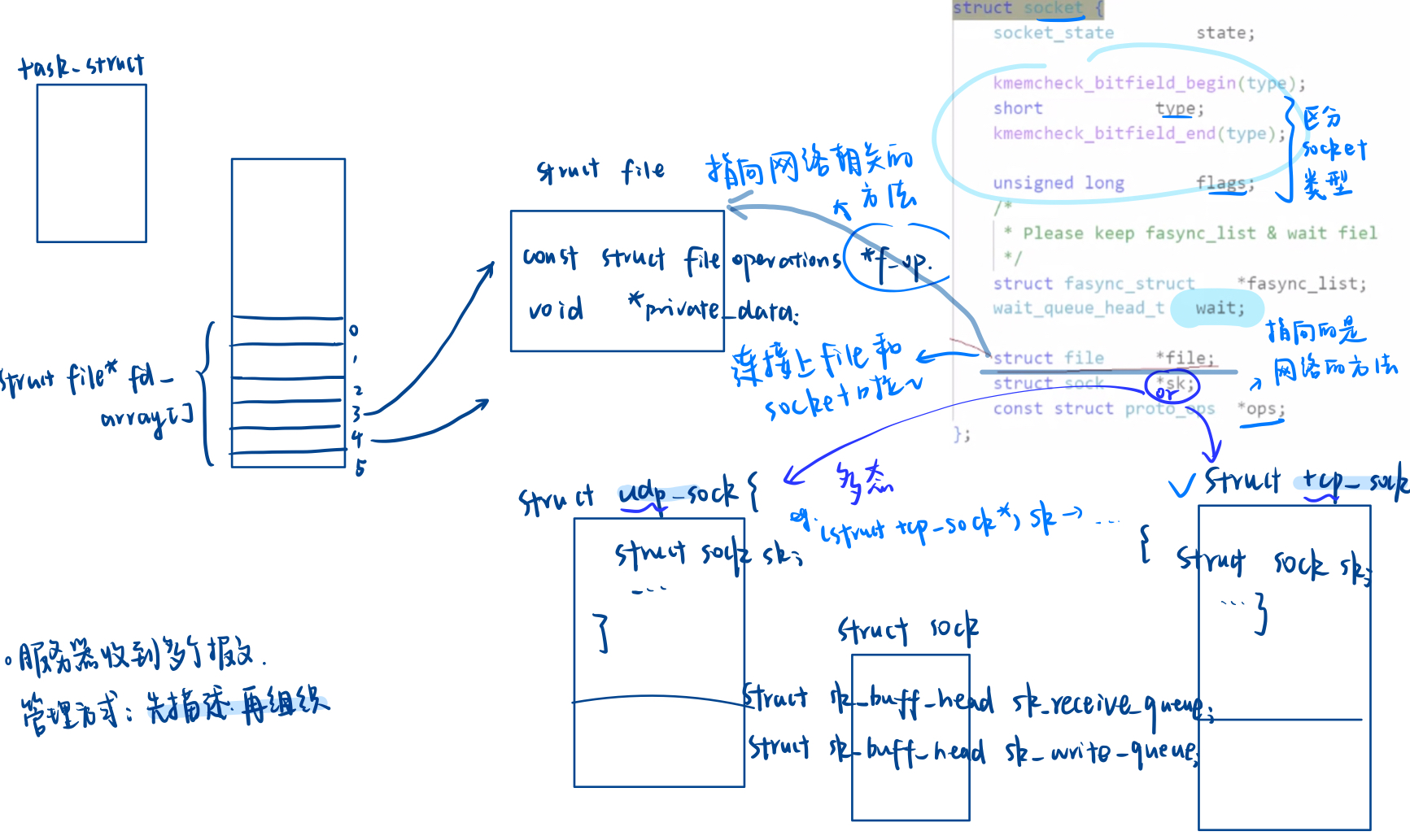
套接字的转化,就是 C 语言的多态
加深对于 传输层+网络层 的理解:
- 用特定数据结构表述的协议
- 和特定协议匹配的方法集
网络底层是:生产消费者模型
探究上图蓝色荧光笔标记的 wait:struct socket中wait_queue_head_t wait是什么?
在Linux内核中,struct socket 结构体用于表示一个套接字。这个结构体定义在网络子系统的头文件中,例如 <linux/net.h> 或者 <net/sock.h>。其中的 wait_queue_head_t wait 成员是一个等待队列头(wait queue head),它用来管理一组等待特定事件发生的进程。
具体来说,wait_queue_head_t 是一种数据结构,它允许内核将一个或多个进程放入等待状态,直到某个条件满足为止。当条件满足时,内核可以唤醒这些等待的进程,使它们继续执行。在套接字上下文中,wait 通常用于处理读写操作的阻塞情况。
- 读操作:当应用程序尝试从一个空的接收缓冲区读取数据时,如果没有数据可读,那么读操作会被阻塞。此时,调用进程会被加入到与
socket相关的wait队列中。一旦有新的数据到达,内核会唤醒等待队列中的一个或多个进程。 - 写操作:如果发送缓冲区已满,写操作也会被阻塞。这时,调用进程同样会被放入
wait队列。当有足够的空间可用时,内核会唤醒等待的进程。
wait_queue_head_t 的定义如下(简化版):
typedef struct __wait_queue_head {spinlock_t lock;struct list_head task_list;
} __wait_queue_head_t;#define wait_queue_head_t __wait_queue_head_t这里:
spinlock_t lock是自旋锁,用来保护等待队列。(和生产消费者模型联动起来了~)struct list_head task_list是一个双向链表,用来存储等待该事件的所有进程的任务结构task_struct。
使用等待队列的基本步骤包括:
- 初始化等待队列头。
- 将进程添加到等待队列,并设置进程为睡眠状态。
- 当条件满足时,唤醒等待队列中的进程。
这种机制是Linux内核实现I/O多路复用和异步I/O的基础之一。通过这种方式,内核能够有效地管理对资源的并发访问,并且能够在资源变为可用时及时通知相关进程。之后的文章会再详细讲解~
struct sk_buff(socket buffer的简称)是Linux内核网络子系统中的一个核心数据结构,用于表示和处理网络数据包。它是一个非常重要的结构体,贯穿了整个网络协议栈的数据传输过程,从网络接口接收数据到将数据发送出去,以及在不同协议层之间的数据传递。- 封装和解包:本质只要移动指针就可以(实现层和层之间的移动
- 一个进程的文件,一个缓冲区
- 传输层,网络层,数据链路层的解包操作都在接收缓冲区中操作,不需要繁琐的拷贝,只是指针移动
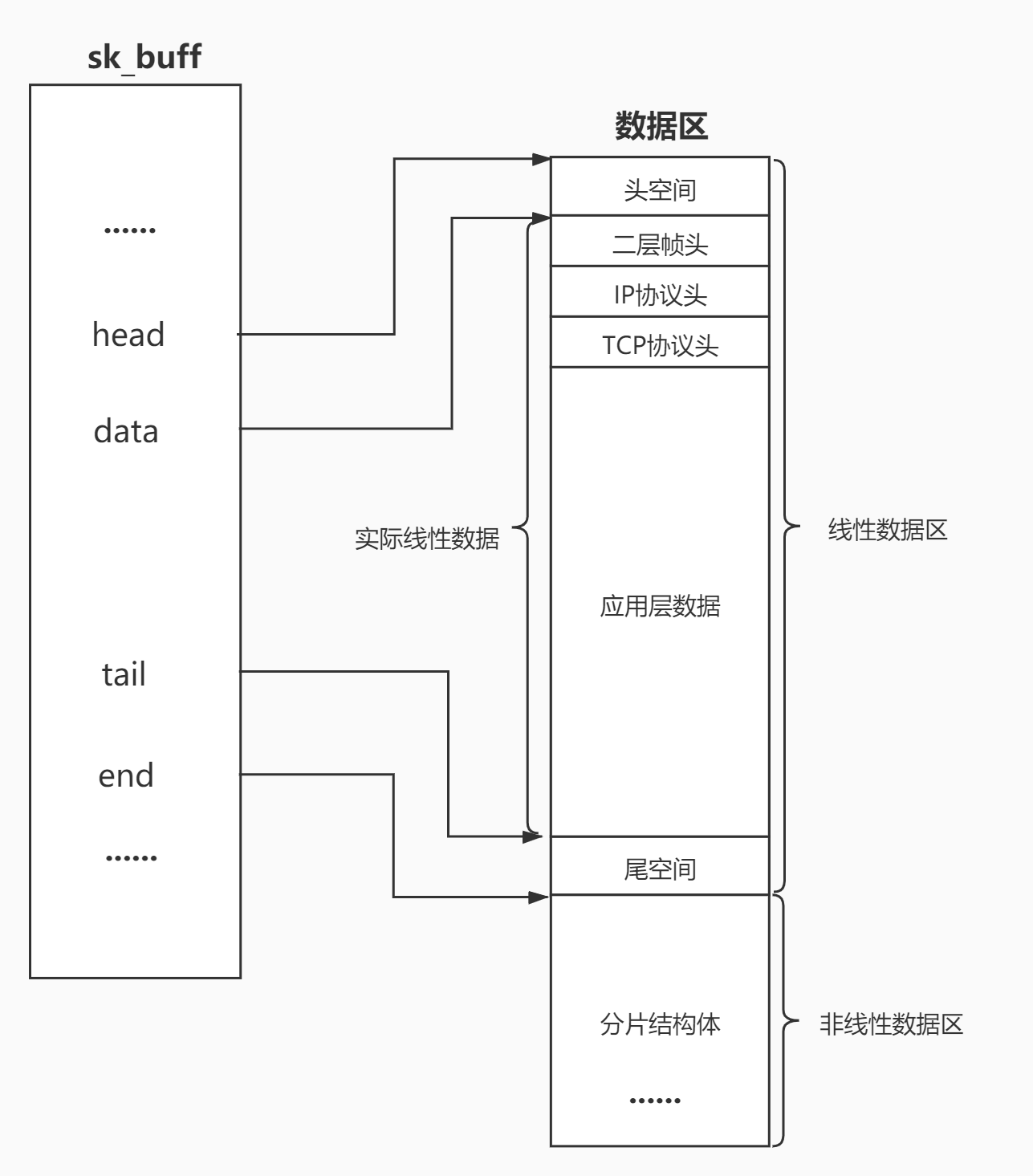
- 要在内核中重新创建大量的数据结构,所以说建立通信是有成本的
- ⭕ 用 C语言实现多态的场景:一切皆文件,进程间通信,网络 tcp/udp
4.网络层:IP
tcp究竟做了什么,ip 又扮演了什么角色?
一个故事:
张三老爹是教务处主任他要求张三每次数学考试都考100分,张三也很争气,10次数学考试8次都是100分,但是架不住意义可能考了95分。而张三老爹每次必须让张三数学考100分,那张三老爹怎么办呢?他决定之前考试作废,重新考试,如果张三还没有考到,那考试继续作废,直到张三考到100分。
刚才我们两个人,一个教务处主任(张三老爹),张三(儿子)。考试的是张三,他也有能力考到100分,但并不一定每次都考到100。张三没考到没事他还有他老爹,他可以让他儿子继续考。
- 张三老爹:tcp 协议,提供可靠性
- 张三:IP ,真正办事的
- IP 协议的本质:1. 定位主机 2.提供一种能力,将数据跨网络从 A 主机送到 B 主机
- 用户需要的是:可靠的送到的能力
- 老爹(tcp 可靠的策略)+张三(ip 传输的能力)
只有策略+能力一定能做到将数据从主机A可靠的跨网络送到主机B。
前面tcp学的超时重传、确认应答、流量控制等等全都是策略!具体怎么做有ip来执行!
前置知识
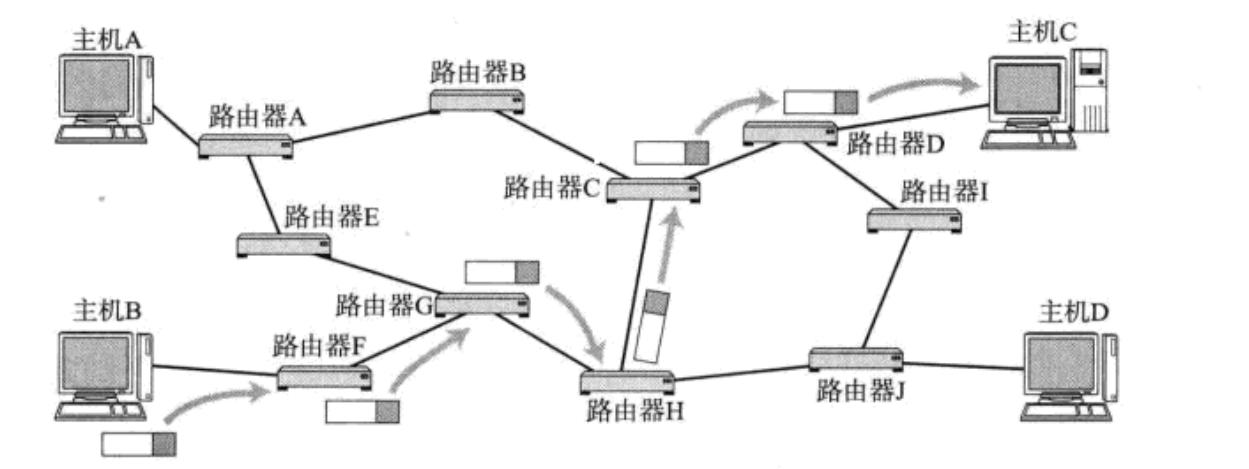
- 要对所有的主机进行的唯一标识
- 源 IP:源主机
- 目的 IP:目的主机
故事:
1.去目标城市 --> 2.去目标地点
- IP=目标网络+目标主机
- IP 设计原因:构建网络
- 路径选择中,目标IP还决定了我们的路径该如何走。
- 相当于是拿着目的 IP,主机——>进行路径选择路由器——>目标主机
这是一套精心设计过的网络体系!
一个故事
背景:
- 每个学校都有很多学院如计算机学院、理学院、化工学院、机械学院、电子信息工程学院等等,每个学生也都有自己的学号,这个学号其实是经过精心设置的。这里我们简化一下把学号分成学院号+自己所在院系内的编号。每个学院也都有自己的编号。
- 每一个学院都有自己院学生会主席并且他还是院群里面的群主,而且他也有属于自己的学号。并且这个学号在全校范围内唯一。每个院学生会主席都还要在加一个校学生会主席群。
事件:
- 今天电子信息工程学院的一名普通学生李四同学把自己学生证丢了,学生证上面其他信息都模糊看不清了,只有学号(101 00101)可以看得清。
- 然后计算机学院张三同学(学号:000 01001)在校园内捡到这个学生证。张三同学就想把学生证归还给该同学,但这个学生证只有学号看的请。可是张三除了自己院学生号清楚并不清楚其他院的学号。
方法:
- 他知道学号在全校范围内唯一,他要找这个人,因此张三就在食堂门口抓住一个人就问同学你的学号
查找本质是在做排除。如果进行线性遍历,效率太低了,所以就有了我们的方法二
- 张三把这张学习卡拍张照片放到院群里@一下院学生会主席王五,他知道王五可以对接外部。然后让王五到校学生会群中去找,确定这个同学是哪个院的
网络通信本质是把数据交给目标主机。
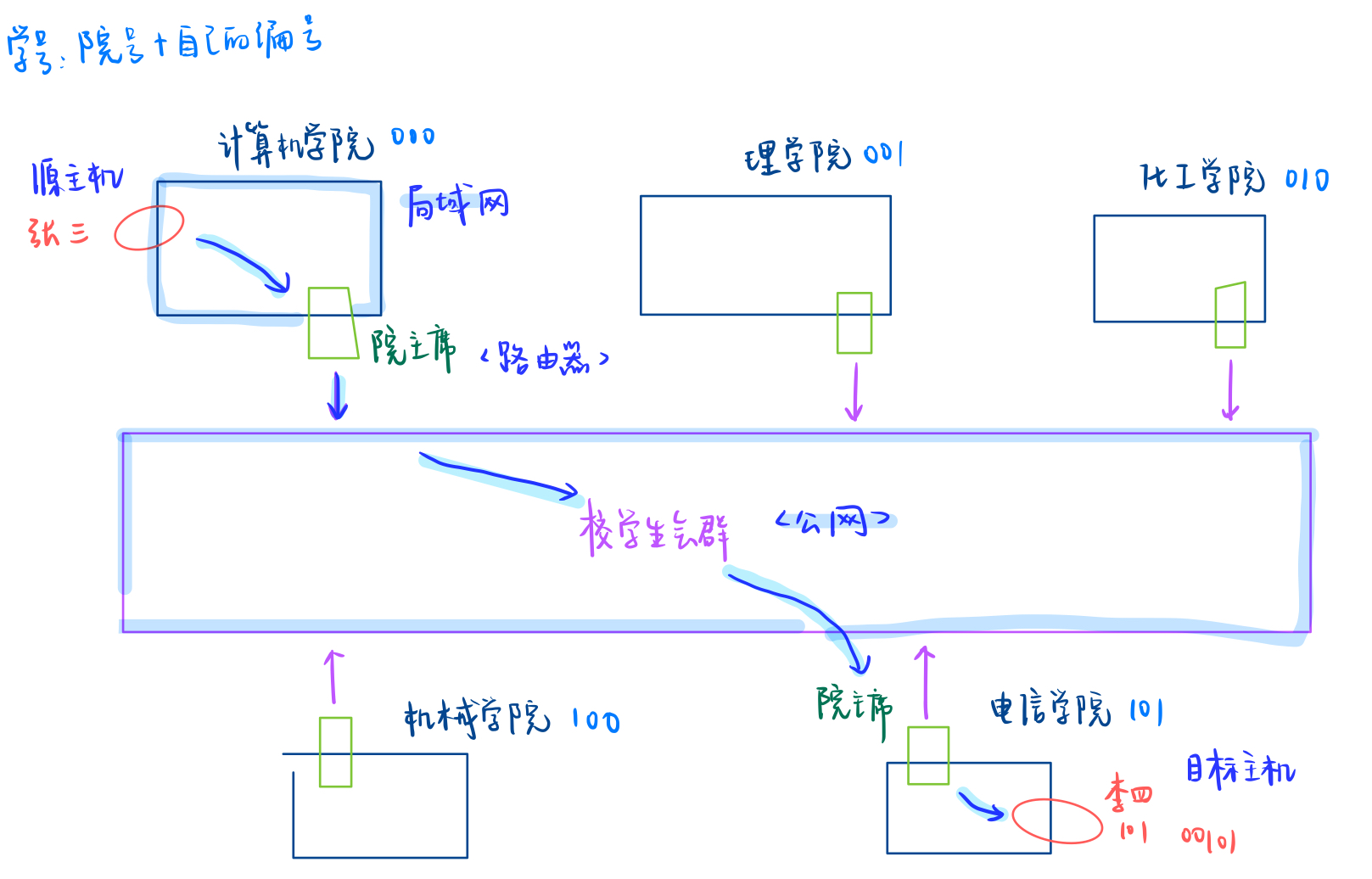
- 张三:源主机
- 李四:目表主机
- 院学生会主席:路由器
- 院内的群:局域网
- 校学生会群:公网
- 捡到的李四钱包中的学号(ip):学院(目标网络)+学号(目标主机)
路由器,认识主机,认识网络目标中的转接,局域网到公网中的查找
为什么第二种方法这么快?因为一次排除一群,做排除的效率更高了。通过校学生会可以直接锁定了电信学院,排除了其他学院
下篇文章继续学习 IP 协议的报头~