ceph基础搭建
存储基础
传统的存储类型:
- DAS设备:
SAS,SATA,SCSI,IDW,USB
无论是那种接口,都是存储设备驱动下的磁盘设备,而磁盘设备其实就是一种存储是直接接入到主板总线上去的。直连存储。
- NAS设备:
NFS CIFS FTP
几乎所有的网络存储设备基本上都是以文件系统样式进行使用,无法进一步格式化操作。nas是共享的。
- SAN:
SCSI协议 FC SAN ISCSI
基于san方式提供给客户端操作系统的是一种块设备接口,这些设备间主要要通过scsi协议来完成正常的通信。scsi的结构类似于tcp/ip协议 也有很多层,但是scsi协议主要是用来进行存储数据操作的。既然是分层方式实现的,那就是说,有部分层可以被代替。比如,将物理层基于fc方式来实现,就形成了fcsan,如果基于以太网方式来传递,就形成了iscsi模式,整体共享,单个独享。
DAS 和 SAN 都是以块的方式来管理存储的
传统的存储方式问题
- 存储处理能力不足
- 存储空间能力不足
- 单点问题
ceph简介
ceph是一个多版本存储系统,它把每一个待管理的数据流(例如一个文件),切分为一到多个固定大小的对象数据,并以其为原子单位完成数据库存取
ceph特性
ceph的组件
| 组件 | 解析 |
|---|---|
| Monitors | CephMonitor(守护进程ceph-mon)维护集群状态的映射,包括监视器映射,管理器映射,OSD映射,MDS映射和CRUSH映射.这些映射是Ceph守护进程相互协调所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。通常至少需要三个监视器才能实现冗余和高可用性。基于paxos协议实现节点间的信息同步 |
| Managers | Ceph管理器(守护进程ceph-mgr)负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载。Ceph管理器守护进程还托管基于Python的模块来管理和公开Ceph集群信息,包括基于web的ceph仪表板和rest api。高可用性通常至少需要两个管理器。基于raft协议实现节点间的信息同步 |
| CephOSDs | Ceph OSD(object storage daemon)对象存储守护进程(ceph-osd)存储数据,处理数据复制,回复,重新平衡,并通过检查其他ceph osd 守护进程的心跳来向ceph监视器和管理器来提供一些监控信息。通常至少需要3个ceph osd来实现冗余和高可用性。本质上osd就是一个个host主机上的存储磁盘 |
| MDSs | ceph元数据服务器(MDS,ceph-mds)代表ceph文件系统存储元数据。ceph元数据服务器允许posix(为应用程序提供的接口标准)文件系统用户执行基本命令(如ls,find等),而不会给ceph存储集群带来巨大的负担 |
Ceph 将数据作为对象存储在逻辑存储池中。使用 CRUSH算法,Ceph 计算出哪个归置组应该包含该对象,并进一步计算出哪个 Ceph OSD Daemon 应该存储该归置组。CRUSH 算法使 Ceph 存储集群能够动态扩展、重新平衡和恢复。
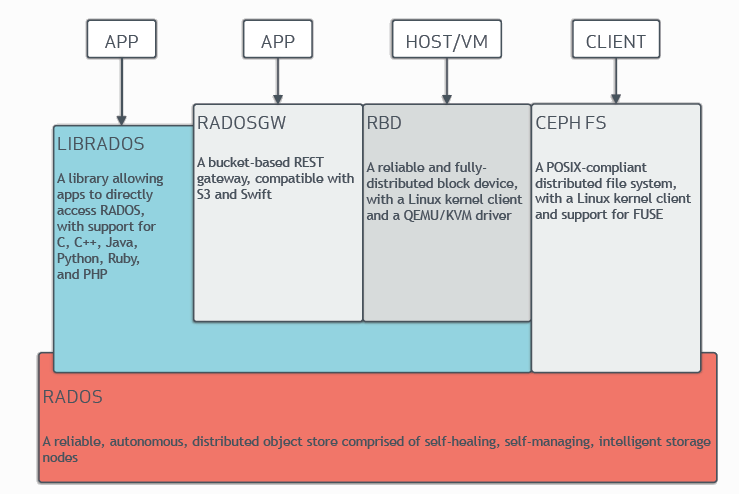
组件及其关系
- RADOS(Reliable Autonomic Distributed Object Storec)
- 功能:RADOS是ceph的底层存储引擎,负责数据的存储和管理。它提供了高度可靠和自我修复的对象存储能力
- 作用:RADIS处理数据的复制,重平衡和回复,确保数据在故障情况下仍然可用。他是所有上层组件(RBD CephFS RADOSGW)的基础
- LIBRADOS
- 功能:LIBRADOS是一个客户端库,允许应用程序直接与RADOS进行交互。它支持多种编程语言(c,c++,java,python,ruby,php)
- 作用:通过librados,开发者可以构建自己的应用程序,直接操作RADOS存储,从而实现定制化的数据存取
- RBD(RADOS Block Device)
- 功能:RBD提供块存储功能,允许虚拟机和数据库等应用使用块设备
- 作用:RBD利用RADOS的特性,提供高性能和可扩展的快存储。RBD通过linux的内核客户端和qemu/kvm的驱动程序进行访问,是的虚拟机能够直接使用ceph存储
- CEPHFS(Ceph File System)
- 功能: CEPHFS 是一个符合 POSIX 标准的分布式文件系统,支持 Linux 内核客户端和 FUSE。
- 作用: CEPHFS 允许用户通过文件系统接口访问存储在 RADOS 中的数据,使得 Ceph 不仅限于对象存储,还可以作为文件系统使用。
- RADOSGW(RADOS Gateway)
- 功能: RADOSGW 是基于存储桶的 REST 网关,兼容 S3 和 Swift API。
- 作用: RADOSGW 提供了一种简单的方式来通过 RESTful 接口访问 RADOS 存储。它使得用户能够利用现有的 S3 和 Swift 应用程序,轻松访问 Ceph 存储。
逻辑关系和作用
-
基础层(RADOS): 所有其他组件(LIBRADOS、RBD、CEPHFS、RADOSGW)都依赖于 RADOS 提供的存储能力和数据管理功能。
-
客户端访问(LIBRADOS、RBD、CEPHFS、RADOSGW):
- 应用程序可以通过 LIBRADOS 直接访问 RADOS,进行数据操作。
- RBD 和 CEPHFS 提供了块和文件系统存储的抽象,使得用户可以以熟悉的方式使用 Ceph。
- RADOSGW 则使得对象存储的使用更加简便,通过兼容 S3 和 Swift 的接口,吸引更多开发者和用户。
-
自我修复和管理: RADOS 的自我修复和管理能力使得 Ceph 能够在节点故障或数据损坏时,自动处理数据的复制和恢复,确保高可用性和数据一致性。
以下是使用短视频的例子来解释 Ceph 的五个组件(RADOS、RADOSGW、RBD、CEPHFS、LIBRADOS):
1. RADOS
概念:RADOS(Reliable Autonomic Distributed Object Store)是 Ceph 的底层存储层,负责数据的存储、复制和管理。
短视频例子:所有用户上传的短视频文件首先存储在 RADOS 中。RADOS 负责将这些视频数据分散存储在多个 OSD(对象存储设备)上,并确保数据的可靠性和可用性。例如,当用户上传视频时,RADOS 会将视频数据划分为多个对象,并将它们分散存储在不同的节点上。
2. RADOSGW
概念:RADOSGW 是一个提供 S3 和 Swift 兼容的 RESTful API 的网关,允许应用程序通过 HTTP 协议访问 RADOS 存储。
短视频例子:短视频平台的前端应用可以通过 RADOSGW 上传和下载视频。比如,用户通过应用选择一个视频文件并点击上传,应用使用 RADOSGW 的 S3 API 发送 HTTP 请求,将视频存储到 Ceph 中。当用户观看视频时,应用会通过 RADOSGW 获取视频文件的 URL,并从 Ceph 下载视频。
3. RBD
概念:RBD(RADOS Block Device)是一个提供分布式块存储的组件,支持将对象存储作为块设备使用。
短视频例子:在短视频的后台,某些处理任务(如转码)可能需要更高效的存储访问。此时,可以使用 RBD 将 RADOS 存储作为虚拟机的块设备。比如,短视频处理的虚拟机可以将 RBD 作为数据盘,快速读取和写入视频文件。
4. CEPHFS
概念:CEPHFS 是一个基于 RADOS 的分布式文件系统,提供 POSIX 兼容的文件访问。
短视频例子:在短视频制作过程中,多个编辑人员可能需要同时访问和编辑同一个视频文件。使用 CEPHFS,团队成员可以通过标准的文件操作(如打开、编辑、保存)来管理视频文件,确保实时协作。例如,编辑人员可以将工作文件保存在 CEPHFS 中,所有人都可以看到最新版本的文件。
5. LIBRADOS
概念:LIBRADOS 是一个允许应用程序直接与 RADOS 进行交互的库,支持多种编程语言。
短视频例子:如果开发者需要在短视频应用中实现一些特定功能,比如直接从 RADOS 读取和写入视频元数据(如标题、描述、时长等),可以使用 LIBRADOS。开发者可以编写代码,通过 LIBRADOS 库直接与 RADOS 交互,进行数据的高效存取。
总结
通过短视频的例子,我们可以看到这五个组件如何协同工作:RADOS 作为基础存储,RADOSGW 提供 API 接口,RBD 用于块存储,CEPHFS 支持文件系统操作,而 LIBRADOS 允许开发者直接与 RADOS 交互。这种设计使得 Ceph 成为一个灵活且强大的存储解决方案。
搭建
cephadm
搭建使用cephadm 用于部署和管理cph集群,它通过ssh将manager将守护进程连接到主机来实现这一点。manager守护进程支持添加,删除和更新ceph容器。cephadm不依赖外部部署工具,例如ansible,rook和salt。
cephadm管理ceph集群的整个生命周期。此生命周期从引导过程开始,cephadm在单个节点上创建一个小型的ceph集群。此集群由一个监视器(MON)和一个管理器(MGR)组成。然后,cephadm使用编排接口扩展集群,添加所有主机并提供所有ceph守护进程和服务。此生命周期的管理可以通过ceph命令行接口或仪表盘执行适用版本是ceph(Octopus)版本
安装cephadm(在所有节点上执行)
设置主机名,关闭selinux。关闭防火墙(三台)
[root@localhost ~]# hostnamectl set-hostname ceph01
[root@localhost ~]# sed -i 's/SELINUC=enforcing/SELINUX=disabled/g' /etc/selinux/config
[root@localhost ~]# setenforce 0
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@localhost ~]#
deploy
[root@controller ~]# mkdir ceph 创建工作目录
[root@controller ceph]# yum install -y ceph-deploy 只在控制节点安装下载批量部署工具
所有节点安装ceph
yum install -y ceph进入ceph目录
[root@controller ceph]# ceph-deploy new controller compute1 compute2 //创建一个新的集群 并把相应节点加入到集群中
[root@controller ceph]# iptables -F 所有节点先执行这个
[root@controller ceph]# ceph-deploy mon create-initial 初始化认证文件创建osd
[root@controller ceph]# ceph-deploy osd create --data /dev/sdb controller
[root@controller ceph]# ceph-deploy osd create --data /dev/sdb compute1
[root@controller ceph]# ceph-deploy osd create --data /dev/sdb compute2
[root@controller ceph]# ceph-deploy admin controller compute1 compute2 下载认证文件在compute1和compute2执行如下命令
[root@compute1 ~]# cd /etc/ceph/
[root@compute1 ceph]# chmod a+x ceph.client.admin.keyring 接下来我们将节点加入到mgr 里面
[root@controller ceph]# ceph-deploy mgr create controller compute1 compute2 启动dashboard界面
[root@controller ceph]# ceph mgr module enable dashboard
[root@controller ceph]# ceph dashboard create-self-signed-cert
Self-signed certificate created
[root@controller ceph]# ceph mgr services
{"dashboard": "https://controller:8443/"
}
[root@controller ceph]# ceph dashboard set-login-credentials admin 123
Username and password updated节点之间时间同步
[root@ceph01 ~]# yum -y install chrony (三台安装)[root@ceph01 ~]# head -n 8 /etc/chrony.conf
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server time1.aliyun.com iburst
server time2.aliyun.com iburst
server time3.aliyun.com iburst[root@ceph03 ~]# head -n 5 /etc/chrony.conf
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server 10.104.45.216 iburst[root@ceph02 ~]# ntpdate 10.104.45.216
# 手动同步一次systemctl restart chronyd.service
systemctl enable chronyd.service
systemctl status chronyd.service主机映射(三台)
[root@ceph03 ~]# cat >> /etc/hosts << EOF
> 10.104.45.216 ceph01
> 10.104.45.217 ceph02
> 10.104.45.218 ceph03
> EOF
安装docker
# 使用一键部署脚本包
[root@ceph03 ~]# cd offline_install_docker-main/
[root@ceph03 offline_install_docker-main]# ls
arm install_docker-compose.sh README.md x86
[root@ceph03 offline_install_docker-main]# bash install_docker-compose.sh
OS Version is : x86
which: no docker in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)
----------------------------------------------------
安装docker运行环境:
extendinstall/
extendinstall/docker-compose
extendinstall/docker.service
extendinstall/containerd.service
extendinstall/docker.socket
extendinstall/docker.tgz
docker/
docker/docker-proxy
docker/docker-init
docker/containerd
docker/containerd-shim
docker/dockerd
docker/runc
docker/ctr
docker/docker
docker/containerd-shim-runc-v2
groupadd: group 'docker' already exists
Created symlink from /etc/systemd/system/multi-user.target.wants/containerd.service to /etc/systemd/system/containerd.service.
Created symlink from /etc/systemd/system/sockets.target.wants/docker.socket to /etc/systemd/system/docker.socket.
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /etc/systemd/system/docker.service.
Docker version 20.10.20, build 9fdeb9c
which: no docker-compose in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)
extendinstall/
extendinstall/docker-compose
extendinstall/docker.service
extendinstall/containerd.service
extendinstall/docker.socket
extendinstall/docker.tgz
Docker Compose version v2.27.0
[root@ceph03 offline_install_docker-main]#
拉去cephadm
# 挑选一个版本
[root@ceph01 ~]# curl --silent --remote-name https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm[root@controller ~]# wget https://download.ceph.com/rpm-15.2.17/el8/noarch/cephadm
给予执行权限
[root@ceph01 ~]# ls
anaconda-ks.cfg offline_install_docker-main
cephadm offline_install_docker-main.zip
[root@ceph01 ~]# chmod +x cephadm
[root@ceph01 ~]# ls
anaconda-ks.cfg offline_install_docker-main
cephadm offline_install_docker-main.zip
[root@ceph01 ~]# cp cephadm /usr/bin/locale
locale localectl localedef
[root@ceph01 ~]# cp cephadm /usr/local/bin/
error
[root@ceph01 ~]# cephadm add-repo --release octopus
bash: /usr/local/bin/cephadm: /usr/libexec/platform-python: bad interpreter: No such file or directory
[root@ceph01 ~]# which platform-python
/usr/bin/which: no platform-python in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)# 修改脚本第一行
# 使用python3
[root@ceph01 ~]# vim /usr/local/bin/cephadm#!/usr/bin/python3# 添加repo仓库 可以在安装cephadm之前也可以在之后,不过建议在之前 因为可以先更换为aliyun的源./cephadm add-repo --release octopus# 修改镜像源为国内阿里云地址
sed -i 's/download.ceph.com/mirrors.aliyun.com\/ceph/' /etc/yum.repos.d/ceph.repo
sed -i 's/release.gpg/release.asc/' /etc/yum.repos.d/ceph.repo[root@ceph01 ~]# cephadm add-repo --release octopus
Writing repo to /etc/yum.repos.d/ceph.repo...
Enabling EPEL...引导一个新集群
#该操作在引导节点上执行
# 创建新ceph集群的第一步是在ceph集群的第一台主机上运行cephadm bootstrap 命令,在ceph集群的第一台主机上运行#cephadm bootstrap命令会创建ceph集群的第一个“监视器(mon)守护进程“,并且该监视器守护进程需要一个ip地址
#因此需要知道该主机的ip地址。如果由多个网络和接口,请确保选择一个可供任何访问ceph集群的主机访问的网络和接口。[root@ceph01 ~]# cephadm bootstrap --mon-ip 10.104.45.216# 返回这个就可以登录dashboard了
Ceph Dashboard is now available at:URL: https://ceph01:8443/User: adminPassword: qux1otim5v# 可能拉不到镜像要配置docker源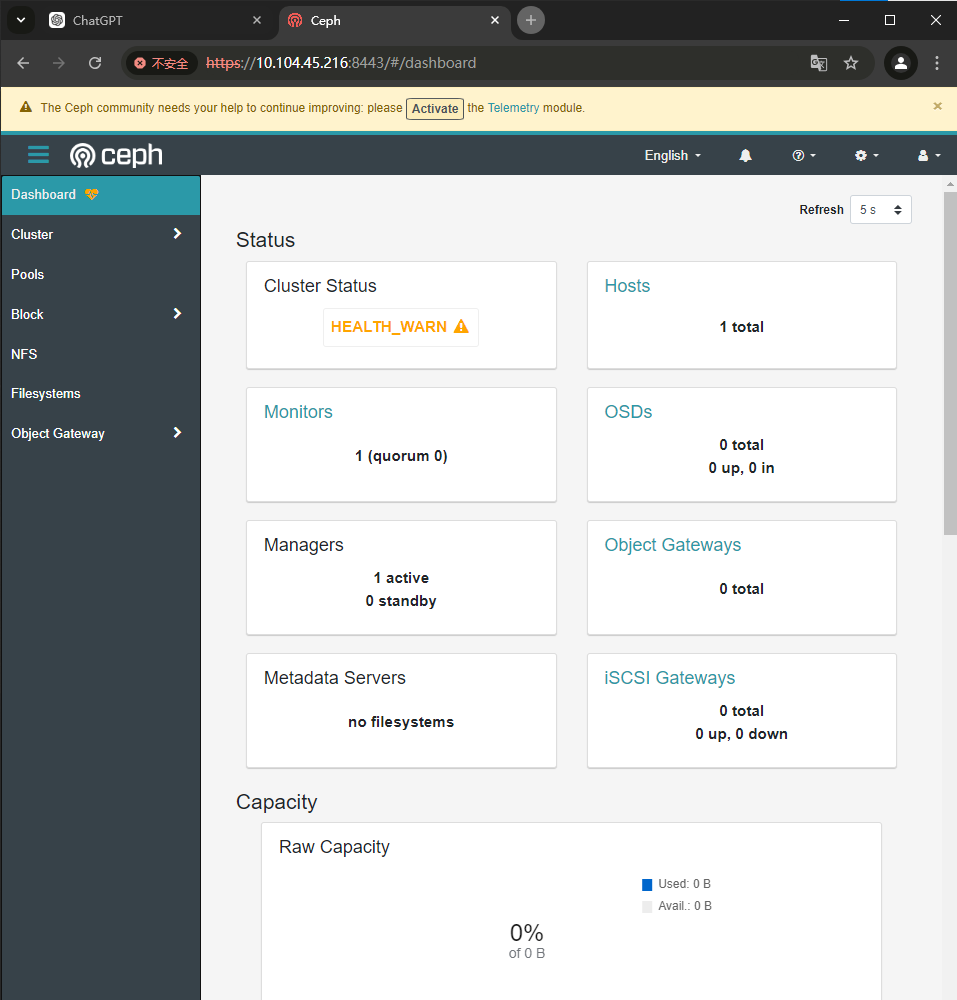
这个是ceph的dashboard(https://10.104.45.216:8443/)
这个是实时显示ceph集群状态的grafana展示页面(https://10.104.45.216:3000/)
[root@ceph01 ~]# ll /etc/ceph/
total 12
-rw-------. 1 root root 63 Oct 2 15:14 ceph.client.admin.keyring
-rw-r--r--. 1 root root 177 Oct 2 15:14 ceph.conf
-rw-r--r--. 1 root root 595 Oct 2 15:14 ceph.pub
[root@ceph01 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/ceph/ceph v15 93146564743f 2 years ago 1.2GB
quay.io/ceph/ceph-grafana 6.7.4 557c83e11646 3 years ago 486MB
quay.io/prometheus/prometheus v2.18.1 de242295e225 4 years ago 140MB
quay.io/prometheus/alertmanager v0.20.0 0881eb8f169f 4 years ago 52.1MB
quay.io/prometheus/node-exporter v0.18.1 e5a616e4b9cf 5 years ago 22.9MB
[root@ceph01 ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3f0c156dcb25 quay.io/ceph/ceph-grafana:6.7.4 "/bin/sh -c 'grafana…" About an hour ago Up About an hour ceph-97ed7984-808d-11ef-bc80-000c29509a00-grafana.ceph01
de2b6c468163 quay.io/prometheus/alertmanager:v0.20.0 "/bin/alertmanager -…" About an hour ago Up About an hour ceph-97ed7984-808d-11ef-bc80-000c29509a00-alertmanager.ceph01
454cb95241a0 quay.io/prometheus/prometheus:v2.18.1 "/bin/prometheus --c…" About an hour ago Up About an hour ceph-97ed7984-808d-11ef-bc80-000c29509a00-prometheus.ceph01
e30985be1112 quay.io/prometheus/node-exporter:v0.18.1 "/bin/node_exporter …" About an hour ago Up About an hour ceph-97ed7984-808d-11ef-bc80-000c29509a00-node-exporter.ceph01
ffcaf1216cf0 quay.io/ceph/ceph:v15 "/usr/bin/ceph-crash…" About an hour ago Up About an hour ceph-97ed7984-808d-11ef-bc80-000c29509a00-crash.ceph01
65853fe0356e quay.io/ceph/ceph:v15 "/usr/bin/ceph-mgr -…" About an hour ago Up About an hour ceph-97ed7984-808d-11ef-bc80-000c29509a00-mgr.ceph01.hqozuo
29a952b7c708 quay.io/ceph/ceph:v15 "/usr/bin/ceph-mon -…" About an hour ago Up About an hour ceph-97ed7984-808d-11ef-bc80-000c29509a00-mon.ceph01由以上信息,可以知道,在引导节点上运行了
- mgr:ceph管理器(MGR)程序
- mon:ceph监视器
- crash:崩溃数据采集模块
- prometheus:prometheus监控组件
- alertmanager:prometheus告警组件
- node-exporter:prometheus节点监控数据采集组件
- grafana:监控数据展示仪表盘grafana
启动ceph命令(所有节点)
默认情况下,cephadm不会在主机上安装任何ceph软件包,需运行cephadm shell命令在安装了所有ceph软件包的容器中启动bash shell(运行exit 即退出shell),在此特定的shell中运行ceph相关命令
cephadm shell 命令提供了一个交互式环境,允许你直接与 Ceph 集群进行交互。通过这个环境,你可以执行管理命令、查看集群状态、配置设置等。它相当于一个集成的管理工具,让你更方便地操作和监控 Ceph 集群
默认情况下,如果在主机上的/etc/ceph中找到ceph.conf配置文件和ceph.client.admin.keyring文件,则会将它们传递到容器环境中,以便shell能够完全正常工作。但是若在MON主机上执行时,cephadm shell将会从mon容器查找配置,而不是使用默认配置
[root@ceph01 ~]# cephadm shell
Inferring fsid 97ed7984-808d-11ef-bc80-000c29509a00
Inferring config /var/lib/ceph/97ed7984-808d-11ef-bc80-000c29509a00/mon.ceph01/config
Using recent ceph image quay.io/ceph/ceph@sha256:c08064dde4bba4e72a1f55d90ca32df9ef5aafab82efe2e0a0722444a5aaacca# 查看集群的状态
[ceph: root@ceph01 /]# ceph -scluster:id: 97ed7984-808d-11ef-bc80-000c29509a00health: HEALTH_WARNOSD count 0 < osd_pool_default_size 3services:mon: 1 daemons, quorum ceph01 (age 101m)mgr: ceph01.hqozuo(active, since 101m)osd: 0 osds: 0 up, 0 indata:pools: 0 pools, 0 pgsobjects: 0 objects, 0 Busage: 0 B used, 0 B / 0 B availpgs: [ceph: root@ceph01 /]# # 或者安装ceph-common
[root@ceph01 ~]# yum -y install ceph-common
添加主机(在引导节点)
列出当前与集群关联的主机
[root@ceph01 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph01 ceph01
配置集群的公共ssh公钥至其他ceph节点
[root@ceph01 ~]# for i in 7 8 ;do ssh-copy-id -f -i /etc/ceph/ceph.pub root@10.104.45.21$i;done
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/etc/ceph/ceph.pub"
The authenticity of host '10.104.45.217 (10.104.45.217)' can't be established.
ECDSA key fingerprint is SHA256:YuFp/UuxY5oYrzHaq35xR4dcXGVuxE060bgRYMYLHNA.
ECDSA key fingerprint is MD5:e4:54:fb:8c:63:6e:ae:e3:c5:8b:79:ec:1d:cd:0e:55.
Are you sure you want to continue connecting (yes/no)? yes
root@10.104.45.217's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'root@10.104.45.217'"
and check to make sure that only the key(s) you wanted were added./usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/etc/ceph/ceph.pub"
The authenticity of host '10.104.45.218 (10.104.45.218)' can't be established.
ECDSA key fingerprint is SHA256:YuFp/UuxY5oYrzHaq35xR4dcXGVuxE060bgRYMYLHNA.
ECDSA key fingerprint is MD5:e4:54:fb:8c:63:6e:ae:e3:c5:8b:79:ec:1d:cd:0e:55.
Are you sure you want to continue connecting (yes/no)? yes
root@10.104.45.218's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'root@10.104.45.218'"
and check to make sure that only the key(s) you wanted were added.[root@ceph01 ~]# # ceph -s 是查看集群的健康和基本状态,而 ceph orch ls 是查看和管理具体的服务实例
如果不加 -i 选项,ssh-copy-id 默认会使用用户主目录下的 ~/.ssh/id_rsa.pub 或 ~/.ssh/id_dsa.pub 等公钥文件。具体行为如下:
-
默认使用:它会查找当前用户的 SSH 公钥,如果找到就将其复制到目标主机的
~/.ssh/authorized_keys文件中。 -
不指定公钥:这意味着如果用户没有生成过 SSH 密钥对,可能会出现错误,因为没有公钥可供复制。
总之,加不加 -i 取决于你想复制哪个公钥。如果你使用的是默认的公钥文件,就可以省略这个选项。
添加新的节点
[root@ceph01 ~]# ceph orch host add ceph02
Added host 'ceph02'
[root@ceph01 ~]# ceph orch host add ceph03
Added host 'ceph03'
#可以使用主机名映射 也可以用ip地址这个时候查看
[root@ceph01 ceph]# ceph -scluster:id: 97ed7984-808d-11ef-bc80-000c29509a00health: HEALTH_WARNOSD count 0 < osd_pool_default_size 3services:mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 27m)mgr: ceph01.hqozuo(active, since 3h), standbys: ceph02.mlmmgposd: 0 osds: 0 up, 0 indata:pools: 0 pools, 0 pgsobjects: 0 objects, 0 Busage: 0 B used, 0 B / 0 B availpgs:
# mon会自动生成,但是要等一下(有点久,耐心等待)
标签
# 添加标签[root@ceph01 ~]# ceph orch host label add ceph01 mon
Added label mon to host ceph01
[root@ceph01 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph01 ceph01 _admin mon
ceph02 ceph02
ceph03 ceph03 _admin
[root@ceph01 ~]# ceph orch host label add ceph02 mon
Added label mon to host ceph02
[root@ceph01 ~]# ceph orch host label add ceph03 mon
Added label mon to host ceph03[root@ceph01 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph01 ceph01 _admin mon
ceph02 ceph02 mon
ceph03 ceph03 _admin mon # 删除标签[root@ceph01 ~]# ceph orch host label rm ceph01 hmm
Removed label hmm from host ceph01
[root@ceph01 ~]# [root@ceph01 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph01 ceph01 _admin mon
ceph02 ceph02
ceph03 ceph03 _admin
[root@ceph01 ~]# 部署 MON
# 关闭mon自动分配
[root@ceph01 ~]# ceph orch apply mon --unmanaged
Scheduled mon update...
# 设置mon数量
[root@ceph01 ~]# ceph orch apply mon 3
Scheduled mon update...
[root@ceph01 ~]# ceph orch ls
NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID
alertmanager 1/1 27s ago 19h count:1 quay.io/prometheus/alertmanager:v0.20.0 0881eb8f169f
crash 3/3 28s ago 19h * quay.io/ceph/ceph:v15 93146564743f
grafana 1/1 27s ago 19h count:1 quay.io/ceph/ceph-grafana:6.7.4 557c83e11646
mgr 2/2 28s ago 17h ceph01;ceph02 quay.io/ceph/ceph:v15 93146564743f
mon 3/3 28s ago 4s count:3 quay.io/ceph/ceph:v15 93146564743f
node-exporter 3/3 28s ago 19h * quay.io/prometheus/node-exporter:v0.18.1 e5a616e4b9cf
osd.None 3/0 27s ago - <unmanaged> quay.io/ceph/ceph:v15 93146564743f
osd.osd_spec_default 6/6 28s ago 15h ceph01;ceph02;ceph03 quay.io/ceph/ceph:v15 93146564743f
prometheus 1/1 27s ago 19h count:1 quay.io/prometheus/prometheus:v2.18.1 de242295e225
# 启动标签匹配
[root@ceph01 ~]# ceph orch apply mon label:mon
Scheduled mon update...部署 MGR
[root@ceph01 ceph]# ceph orch ls mgr
NAME RUNNING REFRESHED AGE PLACEMENT IMAGE NAME IMAGE ID
mgr 2/2 9m ago 75m ceph01;ceph02 quay.io/ceph/ceph:v15 93146564743f
[root@ceph01 ceph]#
[root@ceph01 ceph]# ceph orch apply mgr ceph01,ceph02,ceph03
# 指定的主机列表一定要包含原来的主机
部署 OSD
[root@ceph01 ceph]# ceph orch device ls
Hostname Path Type Serial Size Health Ident Fault Available
ceph01 /dev/sdb hdd 107G Unknown N/A N/A Yes
ceph01 /dev/sdc hdd 107G Unknown N/A N/A Yes
ceph01 /dev/sdd hdd 107G Unknown N/A N/A Yes
ceph03 /dev/sdb hdd 107G Unknown N/A N/A Yes
ceph03 /dev/sdc hdd 107G Unknown N/A N/A Yes
ceph03 /dev/sdd hdd 107G Unknown N/A N/A Yes
[root@ceph01 ceph]# ceph orch device ls --wide
Hostname Path Type Transport RPM Vendor Model Serial Size Health Ident Fault Available Reject Reasons
ceph01 /dev/sdb hdd Unknown Unknown VMware, VMware Virtual S 107G Unknown N/A N/A Yes
ceph01 /dev/sdc hdd Unknown Unknown VMware, VMware Virtual S 107G Unknown N/A N/A Yes
ceph01 /dev/sdd hdd Unknown Unknown VMware, VMware Virtual S 107G Unknown N/A N/A Yes
ceph03 /dev/sdb hdd Unknown Unknown VMware, VMware Virtual S 107G Unknown N/A N/A Yes
ceph03 /dev/sdc hdd Unknown Unknown VMware, VMware Virtual S 107G Unknown N/A N/A Yes
ceph03 /dev/sdd hdd Unknown Unknown VMware, VMware Virtual S 107G Unknown N/A N/A Yes
[root@ceph01 ceph]#
存储设备可用的条件
- 设备必须没有分区
- 设备不得具有任何lvm状态
- 设备必须没有被挂载
- 设备必须没有包含任何文件系统
- 设备不得包含ceph bluestore OSD
- 设备必须大于5GB
创建OSD
- 方式一
自动使用任何可用且未使用的存储设备
ceph orch apply osd --all-available-devices命令会在整个集群中自动应用 OSD(对象存储守护进程),并在所有可用的设备上进行配置。它会查找所有节点上的可用存储设备,然后在这些设备上创建 OSD。因此,这个操作是全局性的,而不是仅限于单个节点。
- 方法二
从指定的主机的指定设备创建OSD
ceph orch daemon add osd ceph01:/dev/sdc
- 方法三
使用高级的OSD服务规范根据设备的属性对设备进行分类。(yaml)
[root@ceph01 osd]# cat ll.yaml
service_type: osd
service_id: osd_spec_default
data_devices:paths:- /dev/sdb- /dev/sdc- /dev/sdd
placement:hosts:- ceph01- ceph02- ceph03
检查OSD和集群状态
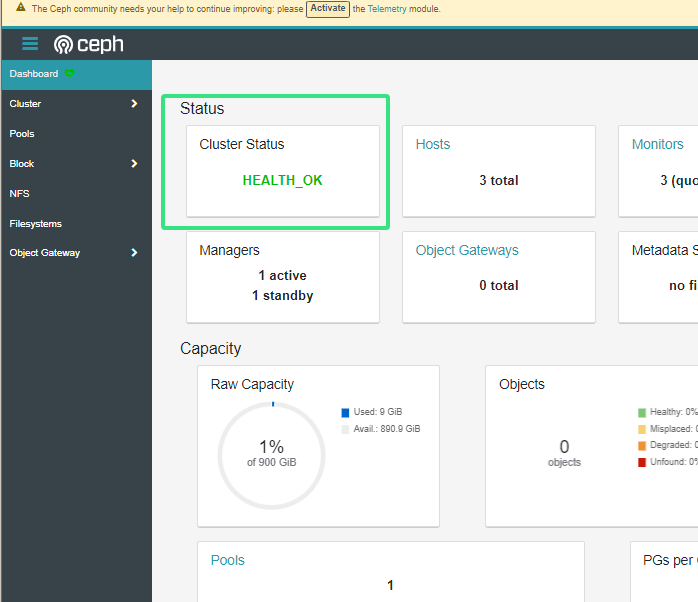
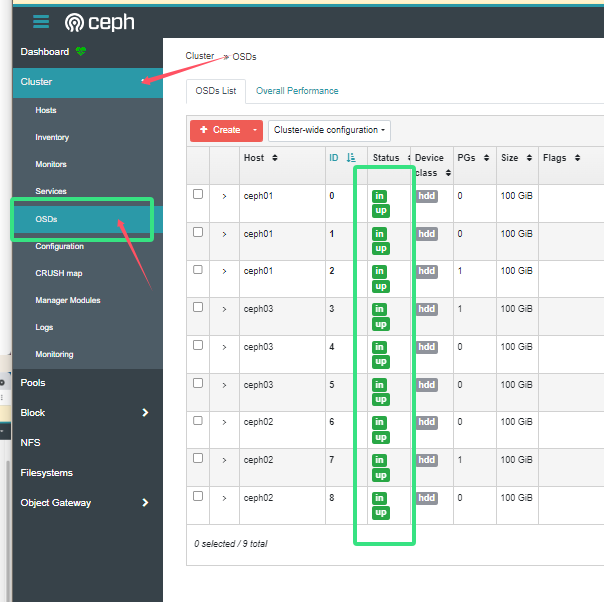
[root@ceph01 osd]# ceph -scluster:id: 97ed7984-808d-11ef-bc80-000c29509a00health: HEALTH_OKservices:mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 14h)mgr: ceph01.hqozuo(active, since 18h), standbys: ceph02.mlmmgposd: 9 osds: 9 up (since 14h), 9 in (since 14h)data:pools: 1 pools, 1 pgsobjects: 0 objects, 0 Busage: 9.0 GiB used, 891 GiB / 900 GiB availpgs: 1 active+clean#OSD状态为up 集群状态为health_OK# 集群健康的三种状态
HEALTH_OK 健康
HEALTH_WARN 有警告
HEALTH_ERR 错误 无法提供服务#up 是osd的状态 由up|down
#in 是osd里有没有pg 有in|out#集群健康详情
[root@ceph01 ~]#
[root@ceph01 ~]# ceph health detail
HEALTH_OK
[root@ceph01 ~]# # ceph orch 是用来管理节点以及orch信息的
ceph orch lsceph orch ps # ps 可以看到具体的进程,运行在拿个节点上,内存占用等,cephadm部署出来的集群是基于容器的
也可以看dashboard