
“lmage outpainting”这一概念是由斯坦福大学 CS230 课程的 Mark Sabini 等人提出,相较于图像修复技术,lmage outpainting 更进一步,能够从给定的图像片段中“补全”出缺失的外延部分,以精妙的方式补全画面,从而构建出一个完整且连贯的视觉世界。
另外,所提出的论文Painting Outside the Box: Image Outpainting with GANs在吴恩达的斯坦福大学 CS230 课程中获得了期末 Poster 的第一名。
-
论文地址:https://arxiv.org/pdf/1808.08483
-
代码地址:https://github.com/bendangnuksung/Image-OutPainting
本文精心汇总了 Outpainting 技术的前沿开源模型与算法资源,旨在加速开发人员的研究进程,轻松获取所需算法与数据。
PQDiff
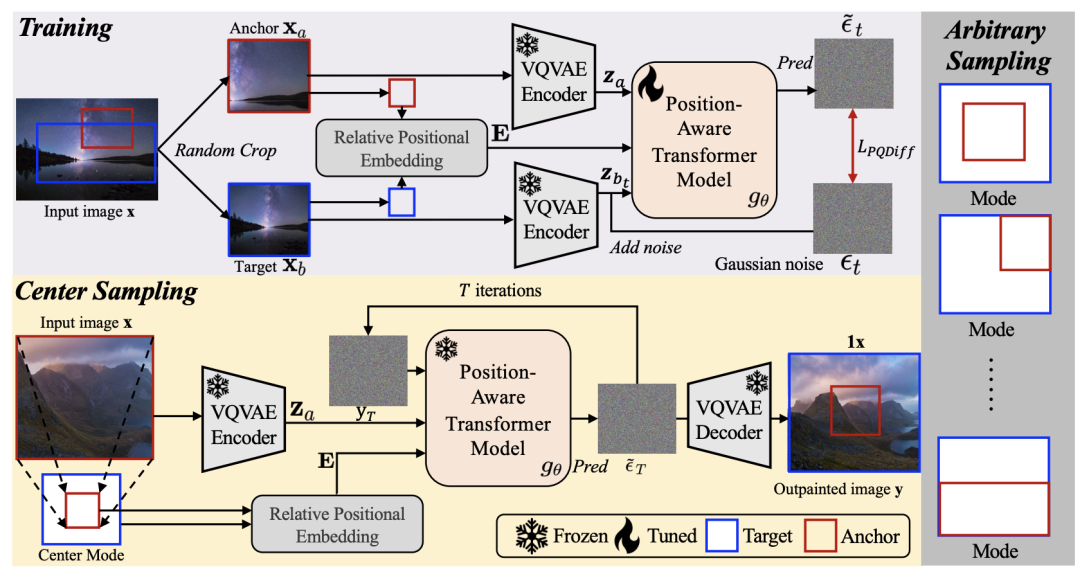
PQDiff 方法,用于图像超补全,具有以下创新点:
-
Continuous multiples for image outpainting:PQDiff 能够同时学习图像的位置信息和像素信息。在训练阶段,PQDiff 首先随机裁剪给定图像两次,生成两个视图。然后,PQDiff 通过预先计算的相对位置嵌入(RPE)从一个视图学习另一个视图的内容。由于 RPE 能够表示两个视图之间的连续关系,PQDiff可以实现连续倍数的图像超补全(例如1x、2.25x、3.6x、21.8x)。作者称 PQDiff 是首个实现连续倍数图像超补全的方法,而现有的 SOTA 方法 QueryOTR(Yao等,2022)只能进行离散倍数的超补全。
-
One-step image outpainting:提出一种基于相对位置嵌入与输入子图像块之间的跨注意力机制,帮助 PQDiff 在任意倍数设置下仅通过一步操作即可完成图像超补全。作者称 PQDiff 是首个实现此功能的方法,而现有的(Yao等,2022;Yang等,2019)只能逐步进行图像超补全,极大地限制了采样效率,即生成效率。在2.25x、5x和11.7x的超补全设置下,PQDiff 仅耗费了QueryOTR(Yao等,2022)所需时间的40.6%、20.3%和10.2%。
-
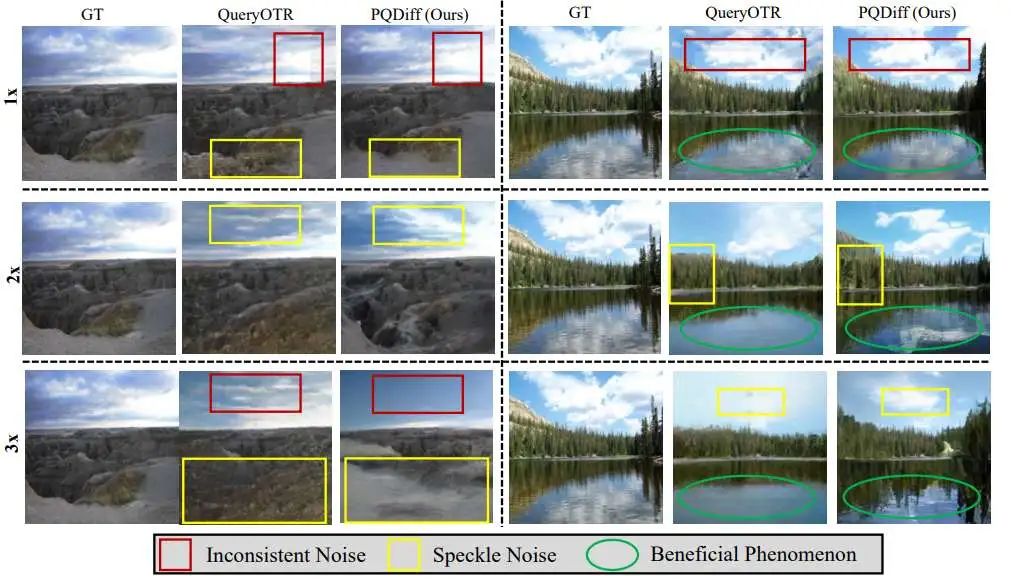
New SOTA performance:在图像超补全的基准测试中(Gao et al., 2023; Yang et al., 2019),实验结果显示,PQDiff 显著超越了QueryOTR(Yao et al., 2022),在Scenery、Building Facades和WikiArts数据集上,PQDiff在11.7倍扩展设置下分别取得了新的最先进FID分数21.512、25.310和36.212。此外,PQDiff在大多数设置下(包括2.25倍、5倍和11.7倍扩展)也取得了新的最先进结果。
-
参考论文:Continuous-Multiple Image Outpainting in One-Step via Positional Query and A Diffusion-based Approach(ICLR 2024)
-
论文地址:https://arxiv.org/pdf/2401.15652
-
开源地址:https://github.com/Sherrylone/PQDiff
QueryOTR
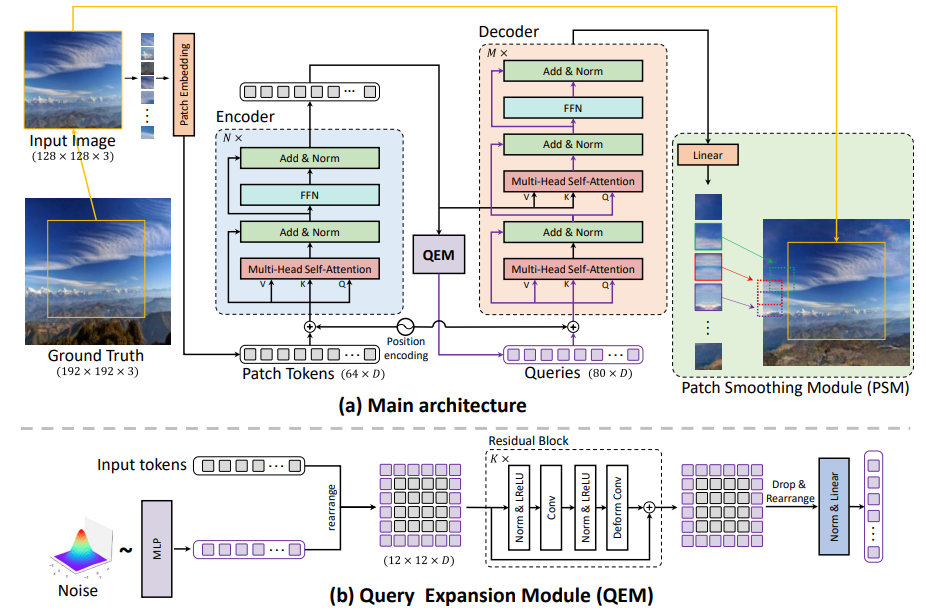
基于 vision-transformer 的图像超补全方法,具有以下创新点:
-
将 Outpainting 问题重新表述为一个基于补丁的序列到序列自回归问题,并开发了一种新的混合 transformer 编码器-解码器框架——QueryOTR,用于基于查询的图像外推预测,同时最小化来自 CNN 结构的归纳偏差所导致的退化。
-
提出 Query Expansion 和 Patch Smoothing 模块,解决纯 Transformer 模型中的慢收敛问题,并生成平滑且无缝的逼真外推图像。
-
与当时及已有的 image outpainting 方法相比,QueryOTR 在one-step 和 multi-step outpainting任务上均达到了SOTA。

-
参考论文:Outpainting by Queries(ECCV2022)
-
论文地址:https://arxiv.org/abs/2207.05312
-
开源地址:https://github.com/Kaiseem/QueryOTR
U-Transformer
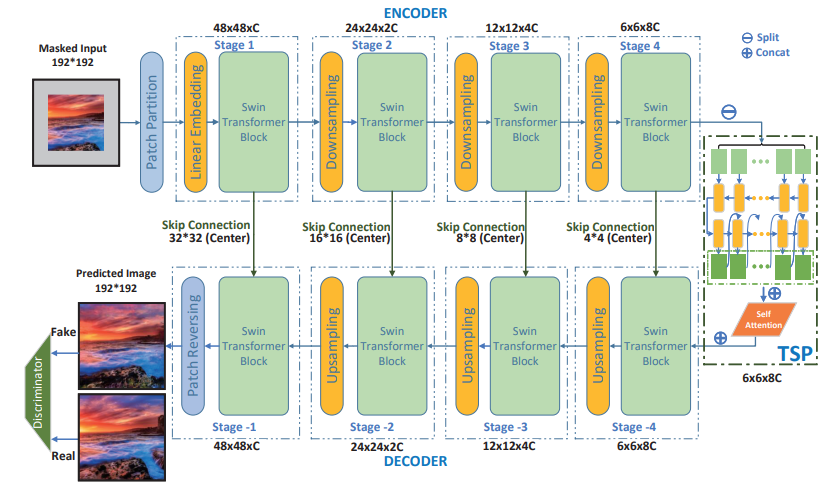
此工作是研究一种通用图像超补全问题,旨在全方位地扩展图像中的视觉内容,突破传统方法仅局限于水平方向扩展的局限,实现图像在全方位的无缝延伸与丰富,为图像处理领域带来前所未有的灵活性和广阔的应用前景。
具体创新如下:
-
U-Transformer 是首个基于Transformer的图像超补全框架。Swin transformer 模块能够获取全局特征并保持高分辨率。U 形结构和 TSP 模块能够平滑而真实地增强图像的自我重建能力以及对未知部分的预测,从而提升网络的能力。
-
TSP 模块连接了编码器和解码器,通过多视角 LSTM 网络和自注意力块,传递考虑潜在时间关系和空间关联的不完整潜在特征。此外,TSP 块可调整被遮掩特征图的预测步骤,从而支持生成任意输出分辨率。
-
创建了三个数据集,
-
Scenery:包含约6,000张图像
-
Building:包含不同风格的复杂建筑结构。训练集中约有16,000张图像,测试集中有1,500张图像。
-
Wikiart:包含45,503张训练图像和19,492张测试图像
-

-
参考论文:Generalised Image Outpainting with U-Transformer
-
论文地址:https://arxiv.org/abs/2201.11403
-
开源地址:https://github.com/PengleiGao/UTransformer
In&Out
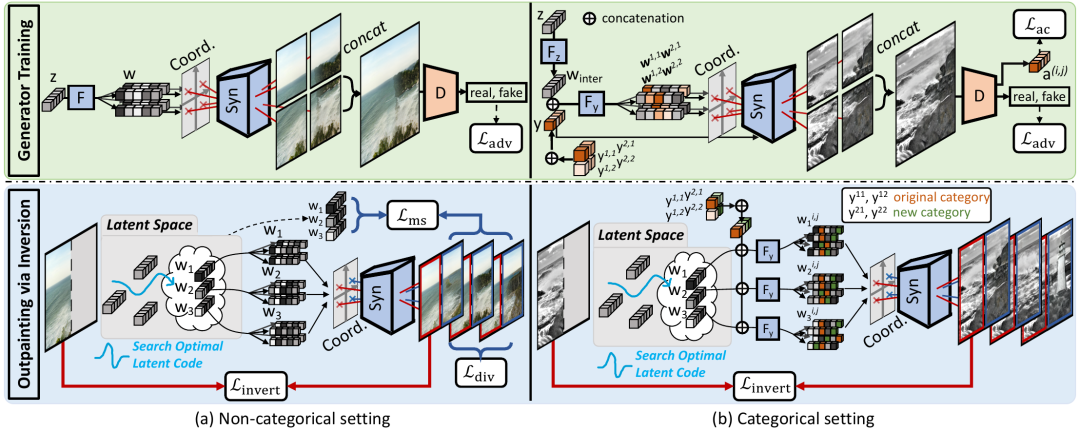
In&Out 是通过 inverting(逆转)GAN 的方式来解决 Outpainting 问题。首先训练一个生成器来合成以其位置为条件的 micro-patches 。在此基础上,提出一个 inversion(逆映射)过程,寻找多个 latent codes(隐藏码)恢复可用区域以及预测 outpainting(补全)区域。

-
参考论文:In&Out : Diverse Image Outpainting via GAN Inversion
-
论文地址:https://arxiv.org/abs/2104.00675
-
开源地址:https://github.com/yccyenchicheng/InOut
-
项目地址:https://yccyenchicheng.github.io/InOut/
-
数据集:https://drive.google.com/file/d/1kYd0qHaMRoqFCsZA50uvNpsyWXya0eOj/view
Wide-Context Semantic Image Extrapolation
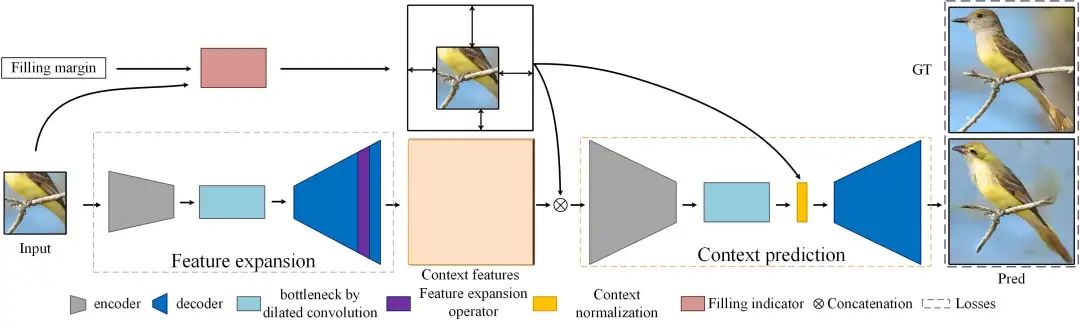
网络结构
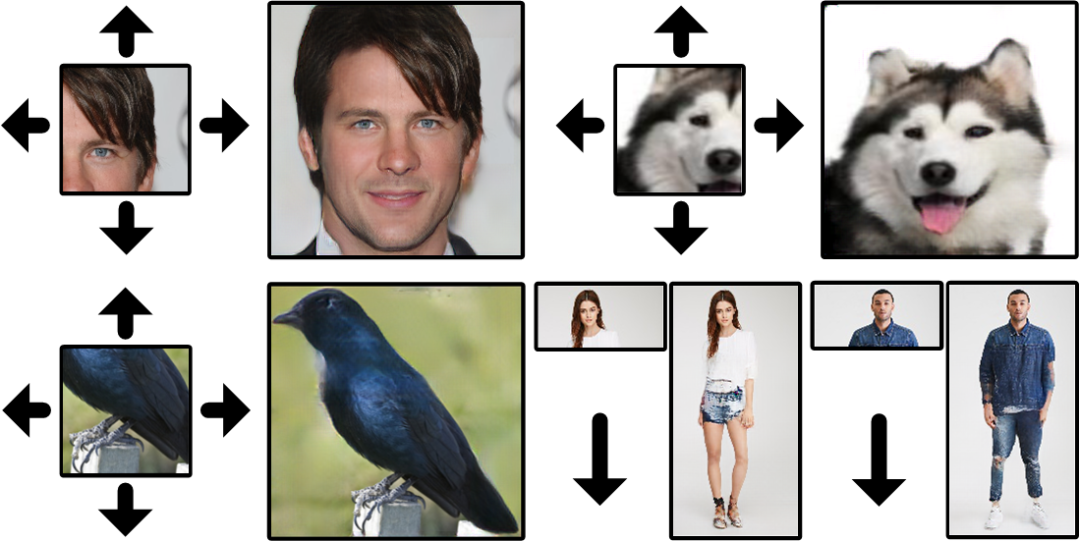
Wide-Context Semantic Image Extrapolation 是一个基于 PyTorch 的开源项目,旨在通过深度学习技术实现图像的补全(outpainting),可以在图像边界之外扩展语义敏感的物体(如面部、身体)或场景。
-
参考论文:Wide-Context Semantic Image Extrapolation(CVPR 2019)
-
论文地址:https://openaccess.thecvf.com/content_CVPR_2019/papers/Wang_Wide-Context_Semantic_Image_Extrapolation_CVPR_2019_paper.pdf
-
开源地址:https://github.com/dvlab-research/outpainting_srn
✎往 期 推 荐
图像修复(Inpainting)技术的前沿模型与数据集资源汇总
趋动云是面向企业、科研机构和个人 AI 开发者构建的开发和推理训练服务,也是全球首个基于 GPU 算力池化云的服务。
趋动云的使命是连接算力 · 连接人:
📍通过连接全球算力,趋动云可以为用户提供便宜、好用的 AI 算力。
📍通过为AI算法开发全流程提供优化服务、构建全球开发者项目和数据社区,趋动云可以帮助AI开发者接入丰富的生态,快速实现最佳实践。
