目录
Java集合(三)
Java双列集合体系介绍
HashMap类
HashMap类介绍
HashMap类常用方法
HashMap类元素遍历
LinkedHashMap类
LinkedHashMap类介绍
LinkedHashMap类常用方法
LinkedHashMap类元素遍历
Map接口自定义类型去重的方式
Set接口和Map接口无索引操作原因分析
HashMap无序但LinkedHashMap有序原因分析
Map练习案例
案例1:统计字符串每一个字符出现的次数
案例2:斗地主案例HashMap版本
哈希表结构存储过程分析
哈希表结构源码分析
使用无参构造创建HashMap对象
第一次插入元素
使用有参构造创建HashMap对象
哈希值相同时比较源码
TreeSet类
TreeMap类
HashTable与Vector
Properties类
Properties类介绍
Properties类特有方法
Java集合(三)
Java双列集合体系介绍
在Java中,双列集合的顶级接口是Map接口,其下有下面的分类:
HashMap类LinkedHashMap类TreeMap类HashTable类Properties类
其体系及特点如下图所示:
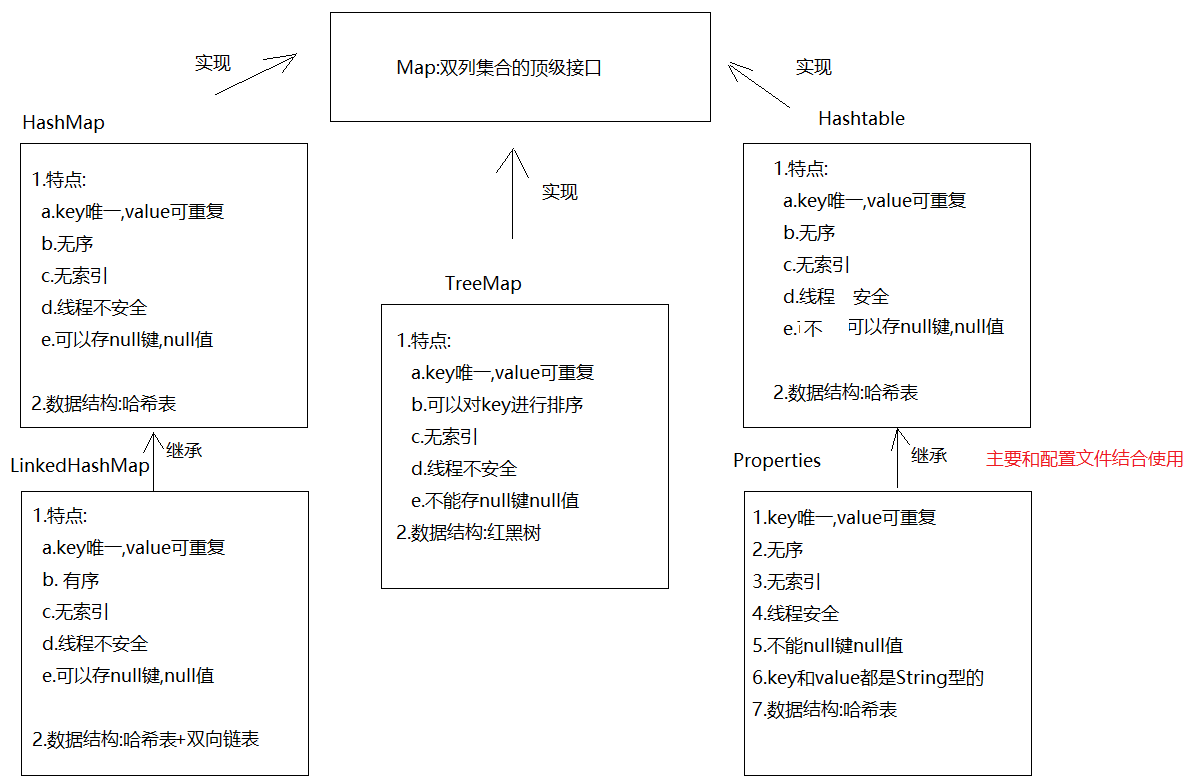
HashMap类
HashMap类介绍
HashMap类是Map接口的实现类,其特点如下:
key唯一但value不唯一- 插入顺序与存储顺序不一定相同
- 没有索引方式操作元素的方法
- 线程不安全
- 可以存
null值
对应的数据结构为哈希表
需要注意,如果出现key重复会保留最后一个键值对的value,即「发生value覆盖」
HashMap类常用方法
V put(K key, V value):向HashMap中插入元素,返回被参数value覆盖的valueV remove(Object key):根据key值移除HashMap中指定的元素,返回被删除的键值对对应的valueV get(Object key):根据key值获取对应的valueboolean containsKey(Object key):判断HashMap中是否还有指定key元素Collection<V> values():获取HashMap中所有的value,将其值存储到单列集合中
基本使用如下:
public class Test01 {public static void main(String[] args) {HashMap<String, String> map = new HashMap<>();// 1. V put(K key, V value):向HashMap中插入元素,返回被参数value覆盖的valueSystem.out.println(map.put("老大", "张三"));System.out.println(map.put("老二", "李四"));System.out.println(map.put("老三", "王五"));// 2. V remove(Object key):根据key值移除HashMap中指定的元素,返回被删除的键值对对应的valueSystem.out.println(map.remove("老二"));// 3. V get(Object key):根据key值获取对应的valueSystem.out.println(map.get("老大"));// 4. boolean containsKey(Object key):判断HashMap中是否还有指定key元素System.out.println(map.containsKey("老大"));// 5. Collection<V> values():获取HashMap中所有的value,将其值存储到单列集合中Collection<String> values = map.values();for (String value : values) {System.out.println(value);}}
}HashMap类元素遍历
HashMap遍历方式有以下两种:
- 通过
key值获取到对应的value,通过Set<K> keySet()方法将获取到的key存入到Set中,再使用Set集合的迭代器获取对应的value - 通过
Set<Map.Entry<K,V>> entrySet()获取到HashMap中的键值对存入到Set中,再通过Map的内部静态接口Map.Entry中的getKey方法和getValue方法分别获取到Map中对应的键值对
基本使用如下:
public class Test02 {public static void main(String[] args) {HashMap<String, String> map = new HashMap<>();map.put("老大", "张三");map.put("老二", "李四");map.put("老三", "王五");// 根据key获取value遍历Set<String> strings = map.keySet();for (String string : strings) {System.out.println(string+"="+map.get(string));}System.out.println();// 使用entrySet遍历Set<Map.Entry<String, String>> entries = map.entrySet();for (Map.Entry<String, String> entry : entries) {System.out.println(entry.getKey()+"="+entry.getValue());}}
}LinkedHashMap类
LinkedHashMap类介绍
key唯一但value不唯一- 插入顺序与存储顺序相同
- 没有索引方式操作元素的方法
- 线程不安全
- 可以存
null值
对应的数据结构为哈希表+双向链表
LinkedHashMap类常用方法
因为LinkedHashMap类继承自HashMap类,所以常用方法与HashMap基本一致
V put(K key, V value):向HashMap中插入元素,返回被参数value覆盖的valueV remove(Object key):根据key值移除HashMap中指定的元素,返回被删除的键值对对应的valueV get(Object key):根据key值获取对应的valueboolean containsKey(Object key):判断HashMap中是否还有指定key元素Collection<V> values():获取HashMap中所有的value,将其值存储到单列集合中
基本使用如下:
public class Test03 {public static void main(String[] args) {LinkedHashMap<String, String> map = new LinkedHashMap<>();// 1. V put(K key, V value):向HashMap中插入元素,返回被参数value覆盖的valueSystem.out.println(map.put("老大", "张三"));System.out.println(map.put("老二", "李四"));System.out.println(map.put("老三", "王五"));// 2. V remove(Object key):根据key值移除HashMap中指定的元素,返回被删除的键值对对应的valueSystem.out.println(map.remove("老二"));// 3. V get(Object key):根据key值获取对应的valueSystem.out.println(map.get("老大"));// 4. boolean containsKey(Object key):判断HashMap中是否还有指定key元素System.out.println(map.containsKey("老大"));// 5. Collection<V> values():获取HashMap中所有的value,将其值存储到单列集合中Collection<String> values = map.values();for (String value : values) {System.out.println(value);}}
}LinkedHashMap类元素遍历
遍历方式与HashMap类一致:
HashMap遍历方式有以下两种:
- 通过
key值获取到对应的value,通过Set<K> keySet()方法将获取到的key存入到Set中,再使用Set集合的迭代器获取对应的value - 通过
Set<Map.Entry<K,V>> entrySet()获取到HashMap中的键值对存入到Set中,再通过Map的内部静态接口Map.Entry中的getKey方法和getValue方法分别获取到Map中对应的键值对
public class Test04 {public static void main(String[] args) {LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap<>();linkedHashMap.put("老大", "张三");linkedHashMap.put("老二", "李四");linkedHashMap.put("老三", "王五");// 根据key获取value遍历Set<String> strings = linkedHashMap.keySet();for (String string : strings) {System.out.println(string+"="+linkedHashMap.get(string));}System.out.println();// 使用entrySet遍历Set<Map.Entry<String, String>> entries = linkedHashMap.entrySet();for (Map.Entry<String, String> entry : entries) {System.out.println(entry.getKey()+"="+entry.getValue());}}
}Map接口自定义类型去重的方式
以下面的自定义类为例:
public class Person {private int age;private String name;public Person(int age, String name) {this.age = age;this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}
}以下面的测试为例:
public class Test05 {public static void main(String[] args) {LinkedHashMap<Person, String> personHashMap = new LinkedHashMap<>();personHashMap.put(new Person(18, "张三"), "老大");personHashMap.put(new Person(19, "李四"), "老二");personHashMap.put(new Person(20, "王五"), "老三");personHashMap.put(new Person(20, "王五"), "老三");// 遍历Set<Map.Entry<Person, String>> entries = personHashMap.entrySet();for (Map.Entry<Person, String> entry : entries) {System.out.println(entry.getKey()+"="+entry.getValue());}}
}前面在Set部分提到HashSet的去重方式:
- 先计算元素的哈希值(重写
hashCode方法),再比较内容(重写equals方法) - 先比较哈希值,如果哈希值不一样,存入集合中
- 如果哈希值一样,再比较内容
- 如果哈希值一样,内容不一样,直接存入集合
- 如果哈希值一样,内容也一样,去重复内容,留一个存入集合
在Map接口中也是同样的方式去重,所以对于自定义类型来说,一样需要重写equals和hashCode方法
如果Person类没有重写hashCode和equals方法,此时Person对象比较方式是按照地址比较,所以对于第三个元素和第四个元素来说是两个元素,此时输出结果就会是下面的情况:
Person{age=18, name='张三'}=老大
Person{age=19, name='李四'}=老二
Person{age=20, name='王五'}=老三
Person{age=20, name='王五'}=老三而重写了hashCode和equals方法后,就可以避免上面的问题:
Person{age=18, name='张三'}=老大
Person{age=19, name='李四'}=老二
Person{age=20, name='王五'}=老三Set接口和Map接口无索引操作原因分析
哈希表中虽然有数组,但是Set和Map却没有索引,因为存数据的时候有可能在同一个索引下形成链表,如果1索引上有一条链表,根据Set和Map的遍历方式:「依次遍历每一条链表」,那么要是按照索引1获取,此时就会遇到多个元素,无法确切知道哪一个元素是需要的,所以就取消了按照索引操作的机制

HashMap无序但LinkedHashMap有序原因分析
HashMap底层的哈希表是数组+单向链表+红黑树,因为单向链表只有一个节点引用执行下一个节点,此时只能保证当前链表上的节点元素可能与插入顺序相同,但是如果使用双向链表就可以解决这个问题,过程如下:

Map练习案例
案例1:统计字符串每一个字符出现的次数
统计字符串:abcdsaasdhubsdiwb中每一个字符出现的次数
思路:
遍历字符串依次插入HashMap<String, Integer>(或者LinkedHashMap<String, Integer>)中,这个过程中会出现两种情况:
- 字符不存在与
HashMap中,属于第一次插入,将计数器记为1 - 字符存在于
HashMap中,代表非第一次插入,将计数器加1重新插入到HashMap中
代码实例:
public class Test01 {public static void main(String[] args) {String str = "abcdsaasdhubsdiwb";HashMap<Character, Integer> counter = new HashMap<>();// 将字符串存入数组中,注意存入的是字符,而不是字符对应的ASCII码char[] chars = str.toCharArray();for (char c : chars) {// 遍历HashMap,如果不存在字符就插入,存在就将value值加1if (!counter.containsKey(c)) {counter.put(c, 1);} else {counter.put(c, counter.get(c) + 1);}}// 打印结果Set<Character> characters = counter.keySet();for (Character character : characters) {System.out.println(character + "=" + counter.get(character));}}
}案例2:斗地主案例HashMap版本
思路:
使用HashMap存储每一张牌(包括值和样式),key存储牌的序号(从0开始),value存储牌面,使用前面同样的方式组合牌并存入HashMap中,存储过程中每存一张牌,key位置的数值加1。为了保证可以打乱牌,需要将牌面对应的序号存入一个单列容器,再调用shuffle方法。打乱后的牌通过序号从HashMap中取出,此时遍历HashMap通过key获取value即可
其中,有些一小部分可以适当修改,例如每一个玩家的牌面按照序号排序,查看玩家牌可以通过调用一个函数完成相应的行为等
此处当 key是有序数值,会出现插入顺序与存储数据相同
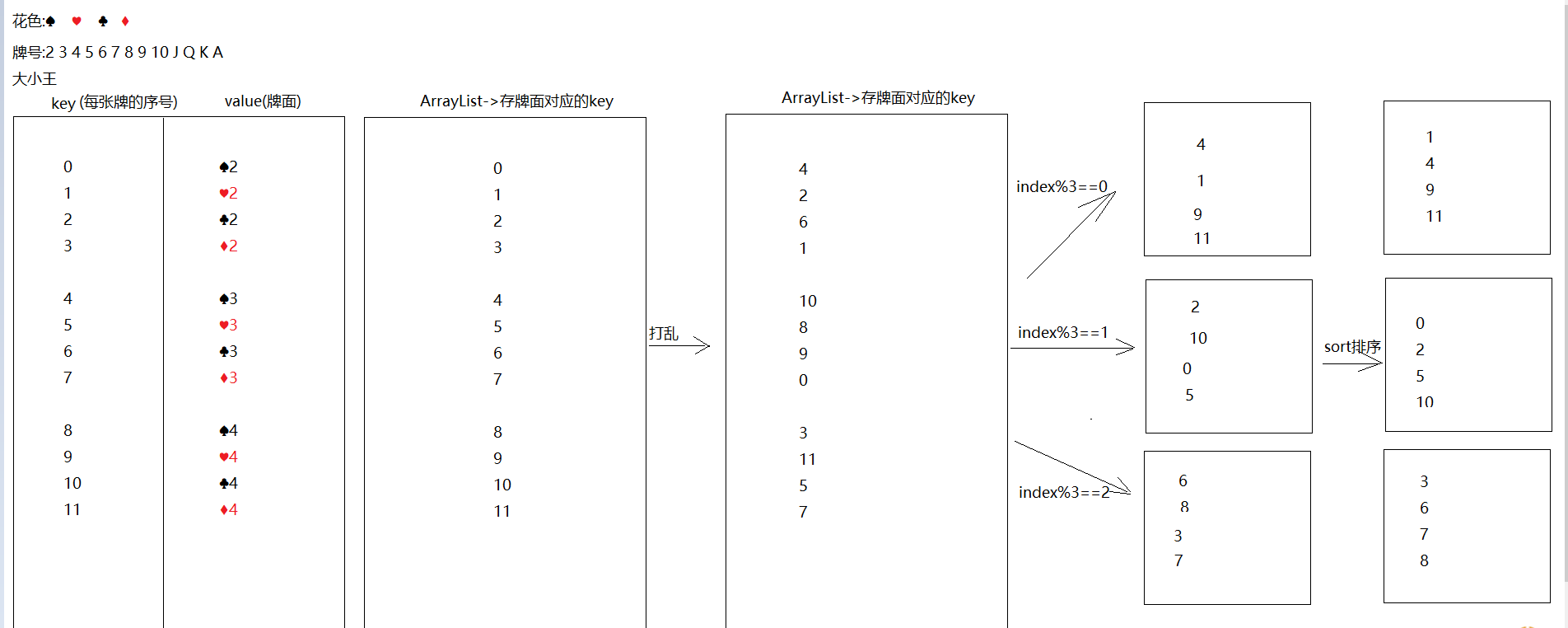
示例代码:
public class Test_Poker02 {public static void main(String[] args) {// 创建花色String[] color = "黑桃-红心-梅花-方块".split("-");// 创建号牌String[] number = "2-3-4-5-6-7-8-9-10-J-Q-K-A".split("-");HashMap<Integer, String> count_poker = new HashMap<Integer, String>();int key = 2;// 从2开始,保留两张牌给大王和小王// 组合牌for (String c : color) {for (String n : number) {// 插入到HashMap中count_poker.put(key++, c+n);}}count_poker.put(0, "大王");count_poker.put(1, "小王");// 创建一个ArrayList专门存牌号,便于打乱牌面ArrayList<Integer> count = new ArrayList<>();Set<Integer> integers = count_poker.keySet();for (Integer integer : integers) {count.add(integer);}// 打乱牌号,从而实现打乱牌面Collections.shuffle(count);// 创建玩家ArrayList<Integer> player1 = new ArrayList<>();ArrayList<Integer> player2 = new ArrayList<>();ArrayList<Integer> player3 = new ArrayList<>();// 创建底牌ArrayList<Integer> last = new ArrayList<>();// 发牌for (int i = 0; i < count.size(); i++) {if(i >= 51) {last.add(count.get(i));} else if(i % 3 == 0) {player1.add(count.get(i));} else if(i % 3 == 1) {player2.add(count.get(i));} else if(i % 3 == 2) {player3.add(count.get(i));}}// 对玩家的牌进行排序Collections.sort(player1);Collections.sort(player2);Collections.sort(player3);// 显示玩家牌show("玩家1", player1, count_poker);show("玩家2", player2, count_poker);show("玩家3", player3, count_poker);show("底牌", last, count_poker);}public static void show(String name, ArrayList<Integer> any, HashMap<Integer, String> poker) {System.out.print(name + ":" +"[ ");for (Integer i : any) {System.out.print(poker.get(i)+" ");}System.out.println("]");}
}哈希表结构存储过程分析
HashMap底层的数据结构是哈希表,但是不同的JDK版本,实现哈希表的方式有所不同:
- JDK7时的哈希表:数组+单链表
- JDK8及之后的哈希表:数组+链表+红黑树
以JDK8及之后的版本为例,存储过程如下:
- 先计算哈希值,此处哈希值会经过两部分计算:1. 对象内部的
hashCode方法计算一次 2.HashMap底层再计算一次 - 如果哈希值不一样或者哈希值一样但内容不一样(哈希冲突),直接存入
HashMap - 如果哈希值一样且内容也一样,则发生
value覆盖现象
在Java中,HashMap在实例化对象时,如果不指定大小,则默认会开辟一个长度为16的数组。但是该数组与ArrayList一样,只有在第一次插入数据时才会开辟容量
而哈希表扩容需要判断加载因子loadfactor,默认负载因子loadfactor大小为0.75,如果插入过程中加载因子loadfactor超过了0.75,就会发生扩容
存储数据的过程中,如果出现哈希值一样,内容不一样的情况,就会在数组同一个索引位置形成一个链表,依次链接新节点和旧节点。如果链表的长度超过了8个节点并且数组的长度大于等于64,此时链表就会转换为红黑树,同样,如果后续删除节点导致元素个数小于等于6,红黑树就会降为链表
哈希表结构源码分析
查看源码时可能会使用到的常量:
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认加载因子
static final int TREEIFY_THRESHOLD = 8; // 转化为红黑树的节点个数
static final int MIN_TREEIFY_CAPACITY = 64; // 转化为红黑树时最小的数组长度
static final int UNTREEIFY_THRESHOLD = 6; // 红黑树退化为链表的节点个数
static final int MAXIMUM_CAPACITY = 1 << 30; // 最大容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 最小容量查看源码时会看到的底层节点结构:
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}// ...
}使用无参构造创建HashMap对象
测试代码:
HashMap<String, String> map = new HashMap<>();对应源码:
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}第一次插入元素
测试代码:
HashMap<String, String> map = new HashMap<>();
map.put("1", "张三");对应源码:
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);// ...++modCount;if (++size > threshold)resize();// ...return null;
}// 创建新节点
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {return new Node<>(hash, key, value, next);
}// 扩容
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {// ... }else if (oldThr > 0)// ...else { newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}// ...threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;// ...return newTab;
}threshold代表扩容边界,是HashMap中的成员变量,由容量和负载因子相乘计算得到
在上面的代码中,插入数据调用put方法,底层会调用putVal方法,进入putVal后,首先会判断当前表是否为空,而此时因为是第一次插入元素,元素还没有进入表中,当前表为空,所以会走第一个if语句,进入内部执行n = (tab = resize()).length;会执行resize方法为当前的tab扩容
进入resize方法中,当前的成员table即为HashMap底层的哈希表,因为不存在元素,所以为空,从而oldTab也为空,执行后面的代码后oldCap和oldThr均为0,直接进入else语句中,将newCap置为16,同时将newThr赋值为12,执行完毕后,将成员threshold更新为newThr的值,将新容量16作为数组长度创建一个新的数组newTab,将newTab给成员变量table返回给调用处继续执行
此处需要注意,对于 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];来说,因为Java不支持创建泛型数组,所以先创建原始类型数组再通过强制转换将其转换为泛型数组
回到调用处n = (tab = resize()).length;,此时tab即为成员变量table的值,获取其长度即为16。接着执行第二个if语句,此处的i = (n - 1) & hash用于计算哈希表的映射位置,即数组索引,进入if语句,创建节点并插入到指定索引位置,改变size并比较是否超过threshold,此处未超过不用扩容,改变并发修改控制因子,返回被覆盖的null
使用有参构造创建HashMap对象
测试代码:
HashMap<String, String> map1 = new HashMap<>(5)对应源码:
public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);
}public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;// ... this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);
}static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}当执行有一个参数的构造时,底层调用内部的有两个参数的构造,第一个参数即为初始容量大小,第二个参数传递默认的加载因子
在有两个参数的构造中,首先判断初始容量initialCapacity是否小于0,如果小于则抛出异常,再判断初始容量initialCapacity是否大于最大值,如果大于则修正为最大值。
在执行完所有判断后,将加载因子赋值给成员变量loadfactor,再根据初始容量计算扩容前最大的容量
哈希值相同时比较源码
Node<K,V> e; K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))e = p;首先比较哈希值,如果哈希值相同,则比较key对应的value,为了防止出现key为空导致的空指针问题,先判断key不为空,再比较key
上面过程即「先比较哈希值,相同再比较内容」
TreeSet类
TreeSet类是Set接口的实现类,其有如下的特点:
- 默认会对插入的数据进行排序
- 没有索引的方式操作元素
- 不可以存
null值 - 相同元素不重复出现
- 线程不安全
底层数据结构为红黑树
常用构造方法:
- 无参构造方法:
TreeSet(),默认按照ASCII码对元素进行比较 - 使用传递比较器作为参数的有参构造方法:
TreeSet(Comparator<? super E> comparator)
基本使用如下:
// 自定义类
public class Person {private String name;private int age;public Person() {}public Person(String name, int age) {super();this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return age == person.age && Objects.equals(name, person.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}// 测试
public class Test02 {public static void main(String[] args) {TreeSet<String> set = new TreeSet<>();set.add("1");set.add("112");set.add("13");// 使用增强for遍历for (String s : set) {System.out.println(s);}System.out.println();TreeSet<Person> people = new TreeSet<>(new Comparator<Person>() {@Overridepublic int compare(Person o1, Person o2) {return o1.getAge() - o2.getAge();}});people.add(new Person("张三", 23));people.add(new Person("李四", 24));people.add(new Person("王五", 25));// 使用增强for遍历for (Person person : people) {System.out.println(person);}}
}TreeMap类
TreeMap类是Map接口的实现类,其特点如下:
- 默认会对插入的数据进行排序
- 没有索引的方式操作元素
key唯一,value不唯一- 不可以存
null值 - 相同元素不重复出现
- 线程不安全
底层数据结构为红黑树
常用构造方法:
- 无参构造方法:
TreeMap(),默认按照ASCII码对元素进行比较 - 使用传递比较器作为参数的有参构造方法:
TreeMap(Comparator<? super E> comparator)
// 自定义类
public class Person {private String name;private int age;public Person() {}public Person(String name, int age) {super();this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return age == person.age && Objects.equals(name, person.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}// 测试
public class Test02 {public static void main(String[] args) {TreeSet<String> set = new TreeSet<>();set.add("1");set.add("112");set.add("13");// 使用增强for遍历for (String s : set) {System.out.println(s);}System.out.println();TreeSet<Person> people = new TreeSet<>(new Comparator<Person>() {@Overridepublic int compare(Person o1, Person o2) {return o1.getAge() - o2.getAge();}});people.add(new Person("张三", 23));people.add(new Person("李四", 24));people.add(new Person("王五", 25));// 使用增强for遍历for (Person person : people) {System.out.println(person);}}
}HashTable与Vector
HashTable类是Map接口的实现类,其特点如下:
key唯一,value可重复- 插入顺序与存储顺序不一定相同
- 没有索引的方式操作元素
- 线程安全
- 不能存储
null值
底层数据结构:哈希表
Vector类是Collection接口的实现类,其特点如下:
- 元素插入顺序与存储顺序相同
- 有索引的方式操作元素
- 元素可以重复
- 线程安全
底层数据结构:数组
因为HashTable和Vector现在已经不经常使用了,所以使用及特点自行了解即可
Properties类
Properties类介绍
Properties类是HashTable类的子类,其特点如下:
key唯一,value可重复- 插入顺序与存储顺序不一定相同
- 没有索引的方式操作元素
- 线程安全
- 不能存储
null值 Properties类不是泛型类,默认元素是String类型
底层数据结构:哈希表
Properties类特有方法
常用方法与HashMap等类似,此处主要考虑特有方法:
Object setProperty(String key, String value):存键值对String getProperty(String key):根据key获取对应的valueSet<String> stringPropertyNames():将所有key对应的value存储到Set中,类似于HashMap中的KeySet方法void load(InputStream inStream):将流中的数据加载到Properties类中(具体见IO流部分)
基本使用如下:
public class Test08 {public static void main(String[] args) {Properties properties = new Properties();//Object setProperty(String key, String value)properties.setProperty("username","root");properties.setProperty("password","1234");System.out.println(properties);//String getProperty(String key)System.out.println(properties.getProperty("username"));//Set<String> stringPropertyNames()Set<String> set = properties.stringPropertyNames();for (String key : set) {System.out.println(properties.getProperty(key));}}
}