简单解释一下xgboost这个模型
xg是一个非常强大,非常受欢迎的机器学习模型,其中最大的特色就是boosting(改进、推进),怎么改进呢?就是xgboost这个算法,它会先建立一颗简单的决策树,然后看这个决策树的预测结果,有哪些地方算错了,针对这些错误,来进行一些改进,又拿到一颗决策树,然后看第二颗决策树预测结果又哪些地方错了,然后再根据这些错误再做一些改进,通过这一次次的快速的改进,将错误最小化,最后xg可达到一个非常精确的结果。
上面一个非常精略的解释,如果细究的话,有很多的技术细节。我们可以把这些技术细节通通跳过,如何跟一个不懂技术的人来解释这个模型。
以做菜打比方,当我第一次做菜的时候,我也不知道应该怎么做,所以我会凭着我的直觉决定我需要加哪些材料,需要煮多长时间,结果大概率非常的不好吃,我尝过之后,判断是盐放多了,煮的时间也有些长。下一轮做菜的时候,我会把盐放少一些,煮的时间也会缩短5分钟的时间,第二轮品尝之后,觉着好像还是不够入味,可能是没有腌制,于是第三次尝试的时候,我先把自己的材料腌制三十分钟,然后再开始煮,尝试上百次之后,终于做出一道比较完美的菜。
这个时候,我会记录下来,我到底做了什么,比如放三克盐,煮了二十分钟,下一次做同样的菜的时候,我只需要按照我的菜谱来就可以了。
这种不断从错误中学习,不断改进的算法就是xg。而我记录下来的这个菜谱,就是这个菜所特定的模型参数parameter。
简介
想要知道,这个模型是在做什么,为什么要这么做
回归树及其数学表达式
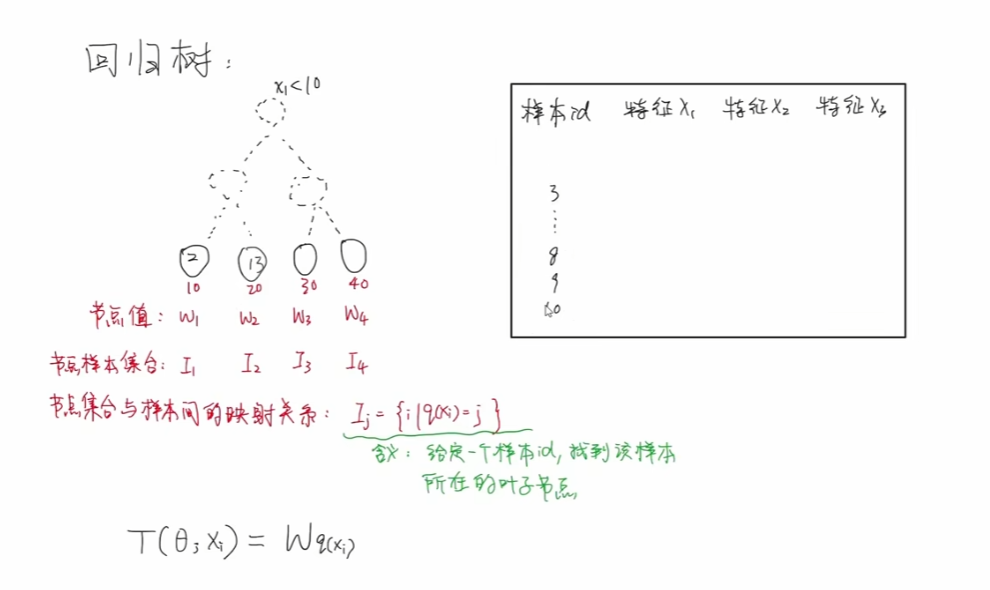
回归树:输入一个样本,得到这个样本对应的节点值,并不能将树结构表达出来,只能表达最终的叶子节点和节点的值。
目标函数
整体表达式
我们定义好一个模型之后,第一步是要确定其目标函数,然后把问题转化为求解最优值的问题。比如把损失函数降到最小,然后利用各种求解最优值的求解凸优化的一些方法,把基学习器的参数求解出来。
首先规定一些用到的数学符号和数学公式
首先定义一下加法模型
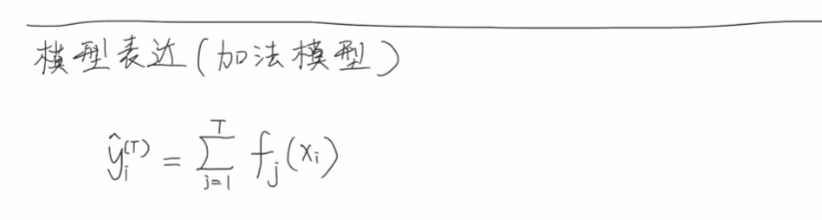
模型由T个基学习器累加,里面每一个基学习器就是我们上面的回归树,可以写成前T-1个基学习器加上最后一个基学习器的形式

前向分布算法采用的是贪心的策略,逐一颗树进行优化,先优化第一颗树,然后优化第二颗,依次类推。假设现在需要优化第t颗树,就可以写成前面t-1颗树加上第t颗待优化的树。第t颗树是一颗回归树,所以可以写成下面公式:
- t表示当前优化的是第t个回归树,其叶子节点有T个
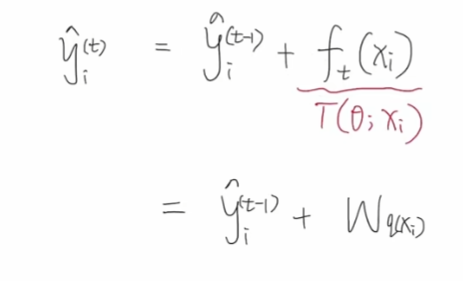
接下来我们定义一下目标函数,每一个样本输入模型之后,都能够得到一个预测值,预测值和真实值就可以计算中间的损失,假设我们一共有n个样本,我们将n个样本得到的损失累加起来,就得到了总体的一个损失。为了防止过拟合,我们会再后面增加一个正则项,即将t颗回归树的复杂度累加起来,后面会讲解复杂度如何定义。那么我们的优化目标就是希望得到我们目标函数的最小值【找到一组w,使得目标函数最小】。
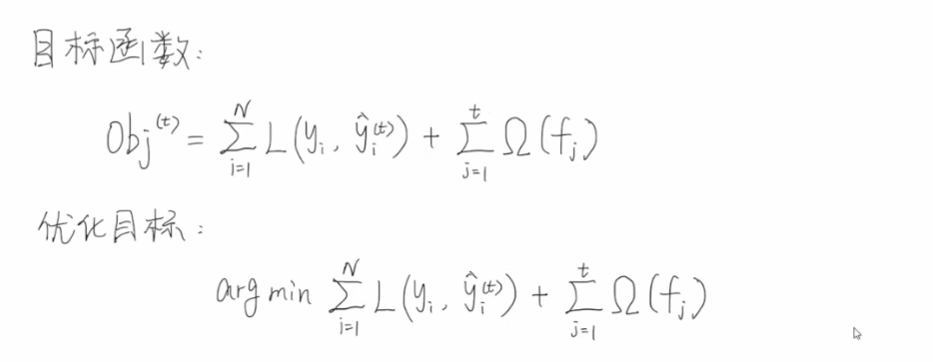
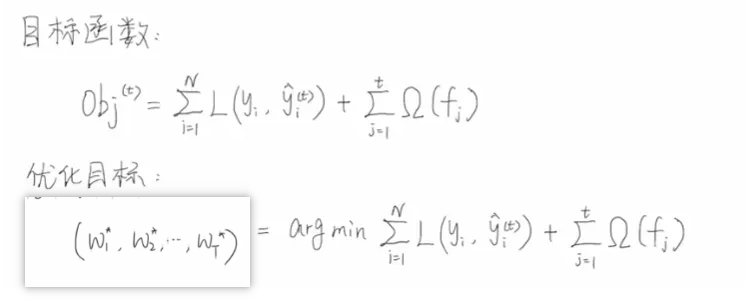
正则项处理
接下来我们分析一下目标函数中的正则项部分。
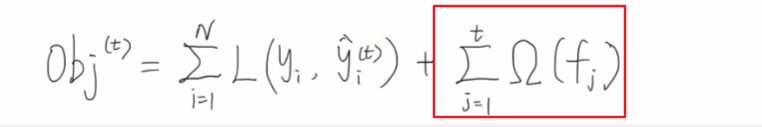
关于oumeiga的定义如下:
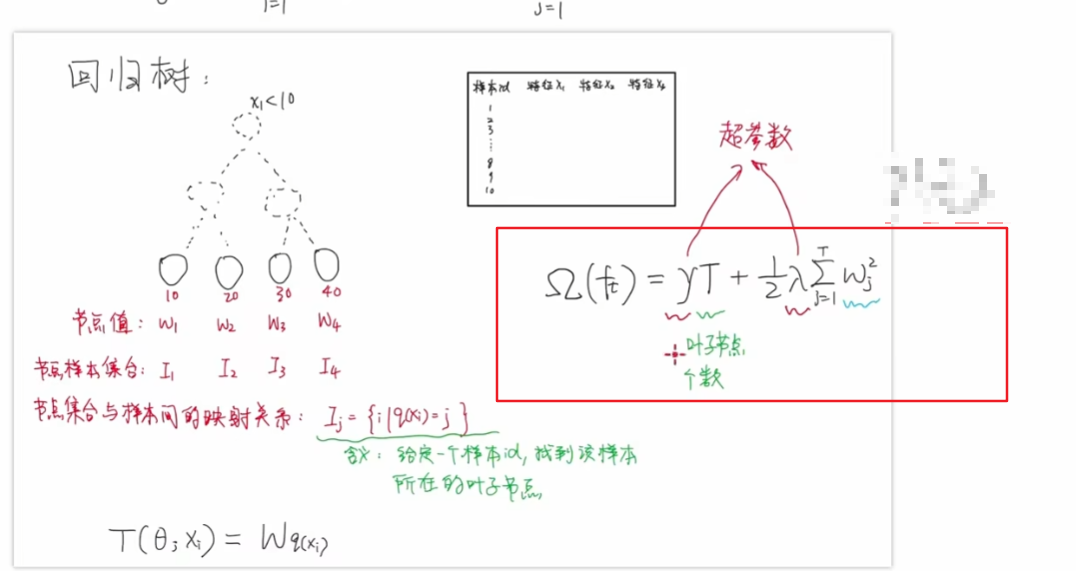
上面框中的函数:
- 有两个超参数,左侧的gama和后侧的lamda,这两个超参数可以控制我们惩罚的力度
- T指的是当前这颗回归树,叶子节点个数,图中是4个叶子节点
- lamda后面是各个节点值的平方累加和
正则项的作用是防止过拟合,当我们叶子节点的数量越来越多的时候,说明回归树的深度是越来越深的,这种情况下是越容易出现过拟合的情况,所以我们需要对其进行一个惩罚,惩罚的力度就可以通过gama来进行控制,同理如果我们后面节点值w比较大的情况下,表示这一颗回归树在我们所有的回归树当中,其值的占比会比较大,比如我们有5颗回归树,我们xgboost模型得到的结果,其中某一颗回归树贡献了80%,说明xgboost模型过拟合的风险是比较高的,所以也需要对其进行惩罚,惩罚的力度可以通过lamda进行控制。
当第一颗到第t-1颗回归数都训练好了之后,下面红框中部分就变成了一个常量,在我们对第t颗回归树优化的时候,是没有价值的,可以直接删除掉,并且代入第t颗回归树正则项的公式:

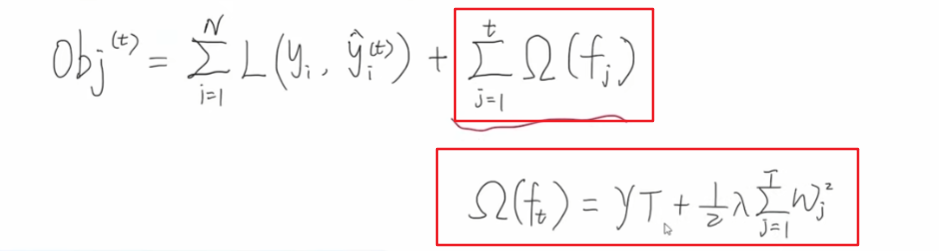
得到下面的目标函数公式,可以看出当前待优化的正则项部分,只与当前要优化的这颗回归数的节点值w和节点个数T有关系。
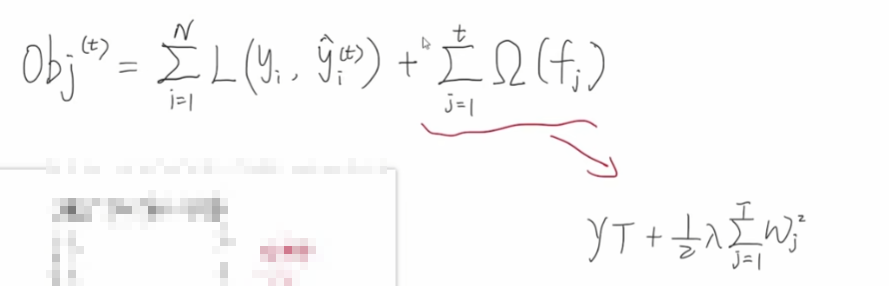
目标拆解
接下来我们分析下,除了正则项外,左侧部分的处理

按照常规的机器学习思路,优化的时候可以使用梯度下降方法优化其中的参数,多次迭代就可以得到最后的结果,这个是常规训练模型的思路。但是我们的树模型是不适合使用梯度下降来做优化的,因为我们的树模型都是阶跃的,是不连续的。
但是我们的树模型是不适合使用梯度下降来做优化的,因为我们的树模型都是阶跃的,是不连续的。比如,下面这颗树,当x小于1时,为1,x大于等于1时为-1,可以看到其不是连续函数,我们是没法办法对其进行求导,梯度下降也是没有意义的。
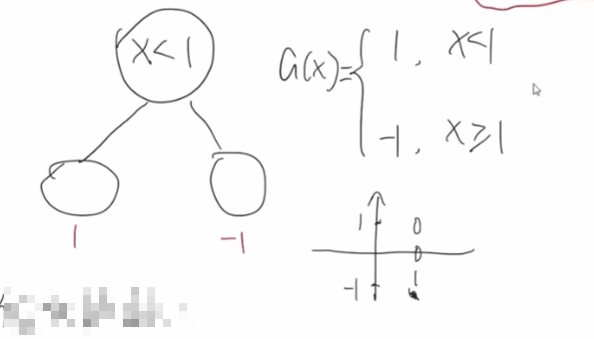
那么,针对树模型,我们可以怎么做呢?首先我们回顾下回归树的工作流程,假设我们有5个训练样本,有两个特征x1和x2,其真实值为y,我们使用树模型的时候,每一个样本都会被划分到回归树其中的一个叶子节点。

此时,我们就可以得到每个样本的预测值,比如3和5,预测值为w1

当我们得到每个样本的预测值之后,就可以计算每个样本真实值和预测值的损失值是多少了,假设我们使用平方误差损失
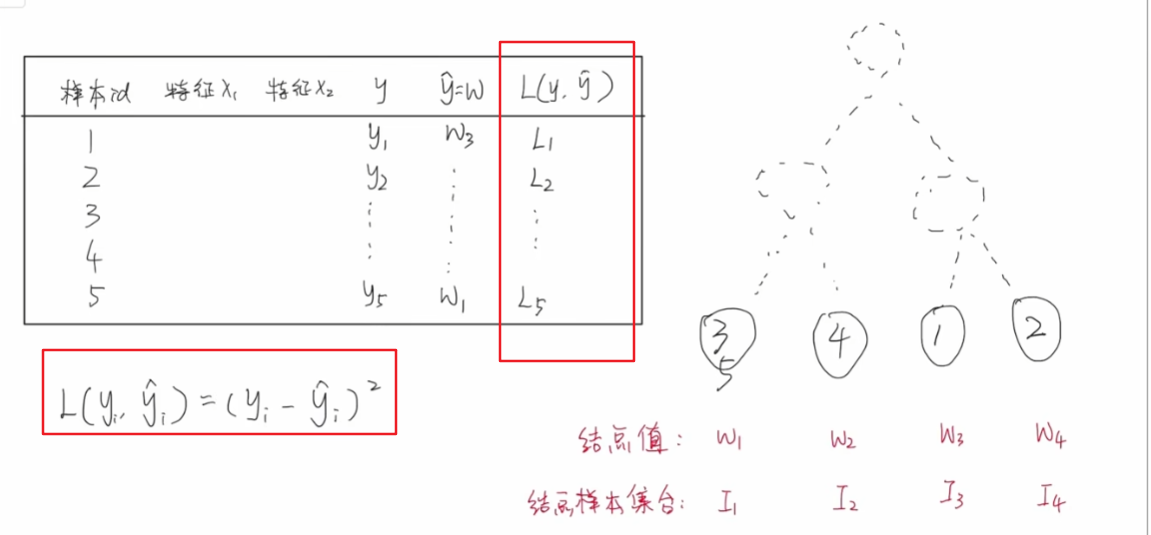
再次看一下我们的目标函数,可以看到我们需要将所有样本的损失值累加起来,需要注意的是,遍历的顺序是按照样本的顺序来进行遍历的。

我们目标函数优化方向是希望找到一些合适的w,让所有样本损失值加起来是最小的,我们会发现,我们每一个损失值,只跟当前节点的节点值有关系,比如L3和L5只跟w1有关系。
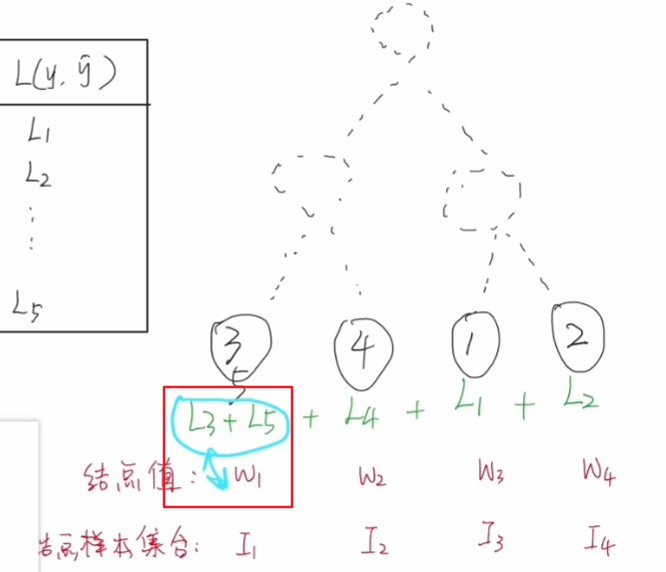
每个w只能影响当前的叶子节点,我们只需要按照一个叶子节点为单位,将我们模型整体的损失值,换算成每个叶子节点的损失值累加也是可以的,目标函数优化目标就变成了每个叶子节点对应的损失值累加最小。

我们以第一个叶子节点为例,探讨其对应的损失值最小值怎么计算,第一个节点的损失函数累加变成了一个关于w1的一元二次方程,y3和y5都是已知的数据。w1很容易找到最值点【w1= y3+y5】。

沿着这个思想,我们可以将我们的目标函数改写成,从遍历样本改成遍历叶子节点,一共有T个叶子节点。

可以将上面的目标函数改写为下面的公式,将其拆解为以叶子节点的损失值累计和为单位的一个个的小目标。每一个小目标中只有一个变量w。
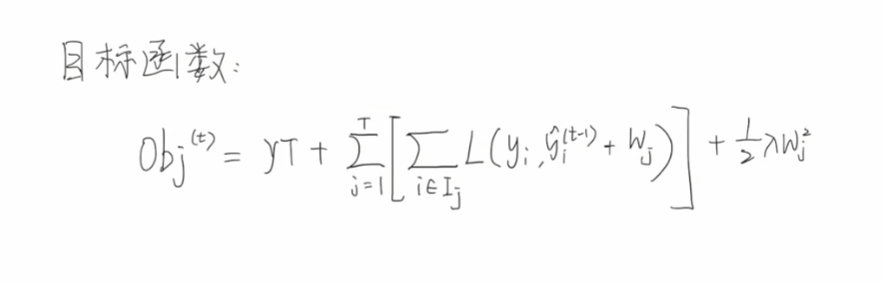
泰勒二级展开
上面我们已经假设我们的损失函数是平方误差函数,那么每个叶子节点在求损失值累加和的时候,都可以得到一个一元二次方程,通过求解w得到损失最小值。但是往往我们不会提前给定损失函数,我们可能会猜想有么有这么一种方法可以无视我们具体的损失函数,能够将目标函数中框出来部分,分解为包含w的一个公式。
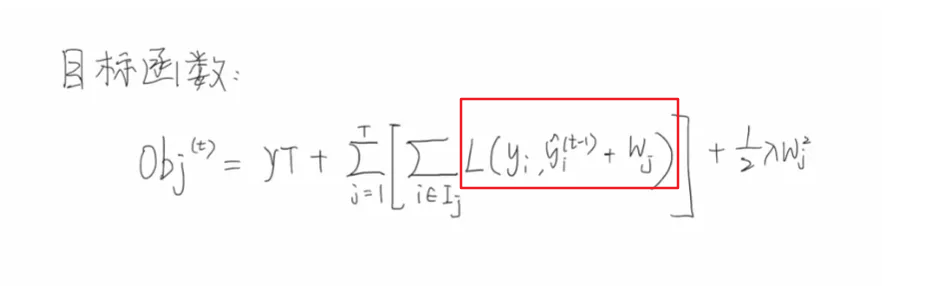
其实可以采用泰勒公式实现我们的想法,在GBDT中我们使用的是泰勒一阶展开公式,在xgboost中我们需要使用的是泰勒二级展开公式【在不知道损失函数的情况,泰勒展开确实很给力】。
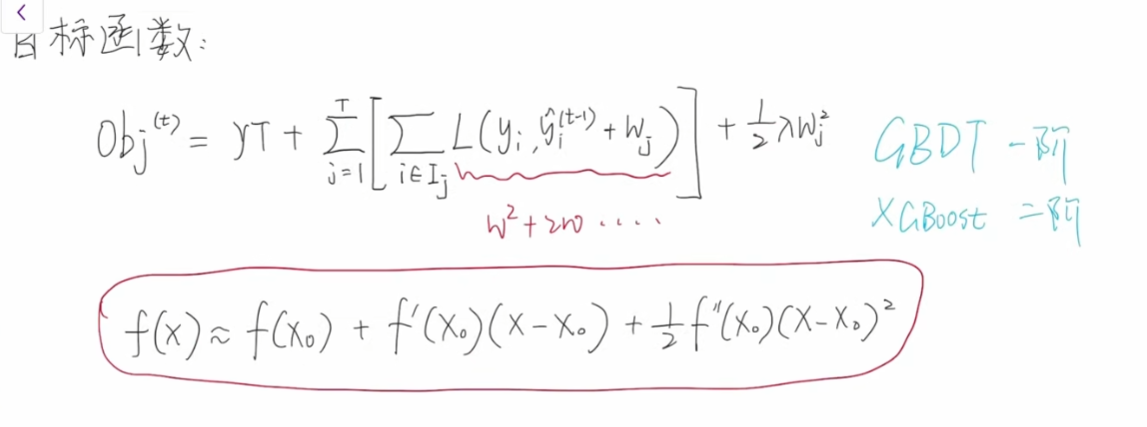
泰勒公式的作用是将一个函数展开成为一个多项式方式,做一个近似的表示【约等于】,阶数越高越精确。
下面举例:
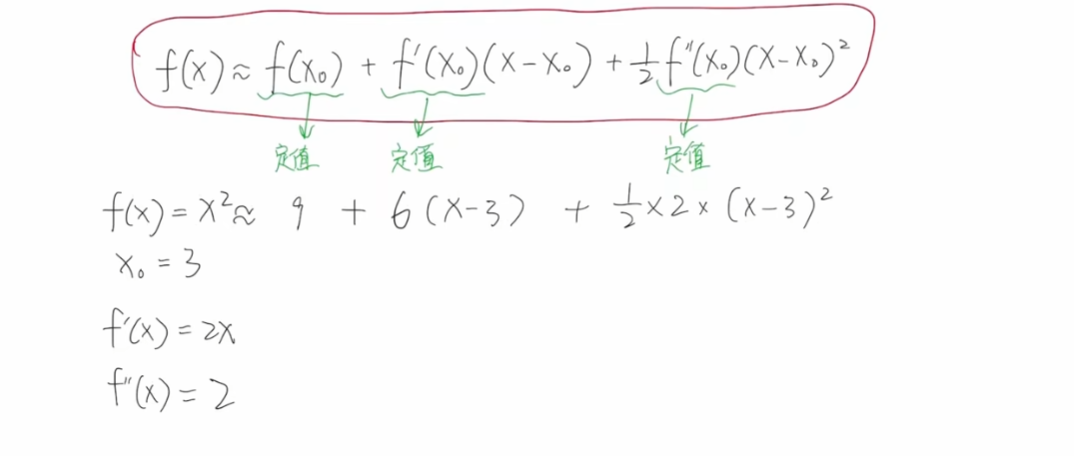
那么对于我们的损失函数而言,yi 是一个常两,变量只有右侧的,其相当于多项式中的x,其中t-1那部分又是一个定值,wj 就相当于x-x0 ,
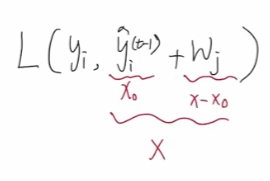
那么我们的目标函数按照泰勒二阶展开,就变成了一个关于wj 的一元二次函数。
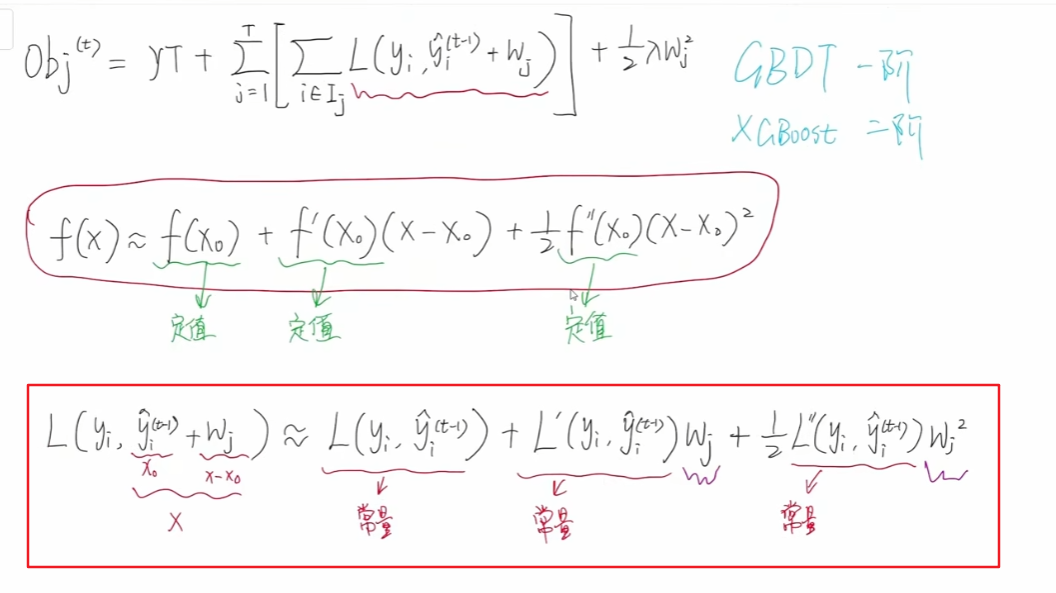
第一个常量对于我们求最优解是没有任何意义的,我们可以直接将其删除。一阶梯度我们用gi 表示,二阶梯度我们使用hi 表示。
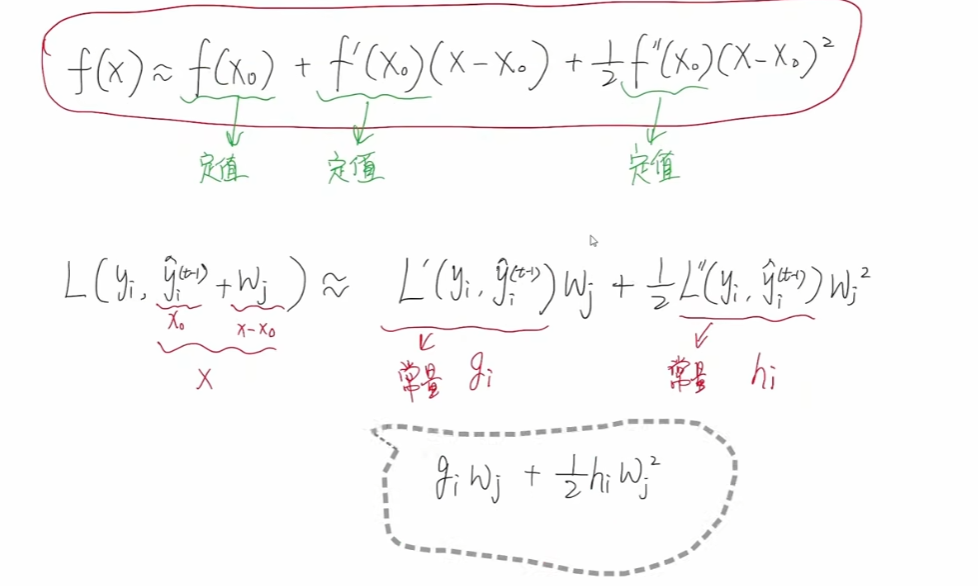
整理一下,得到下面的公式:
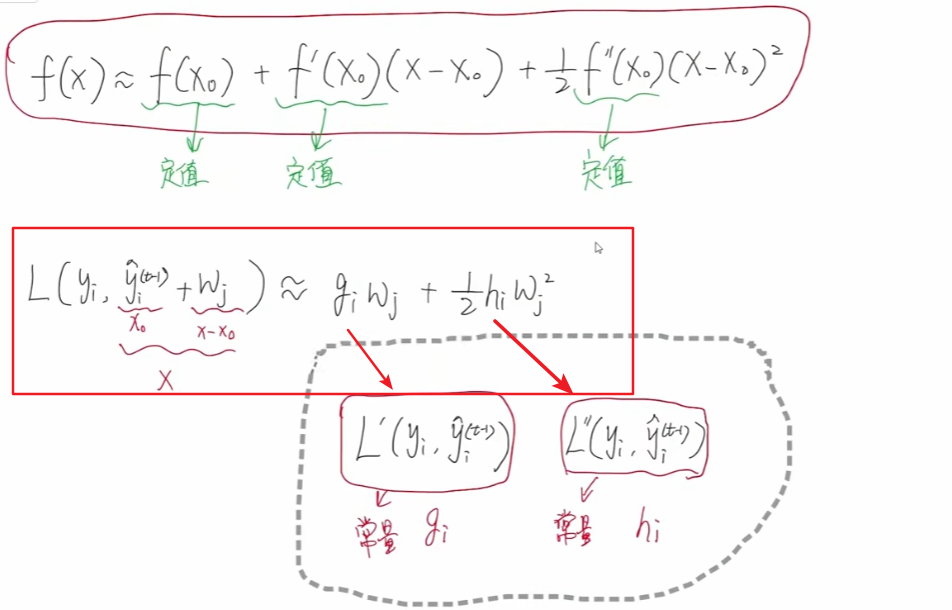
所以我们得到最后的目标函数为:

并且可以进一步去掉中括号:
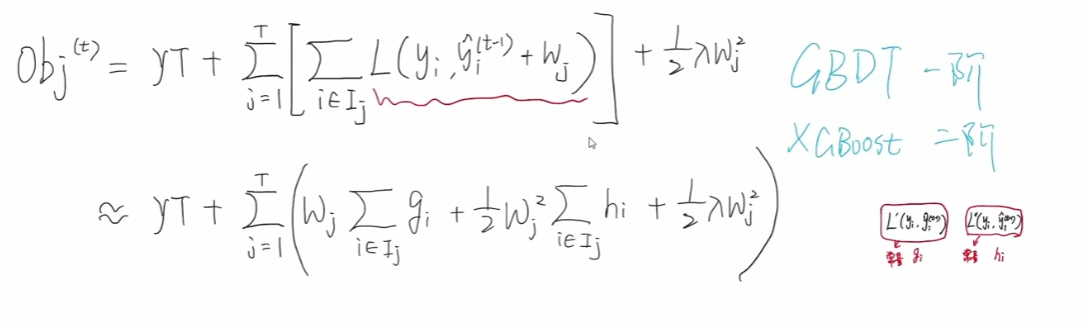
合并 (1/2)λwj2 ,可得到:
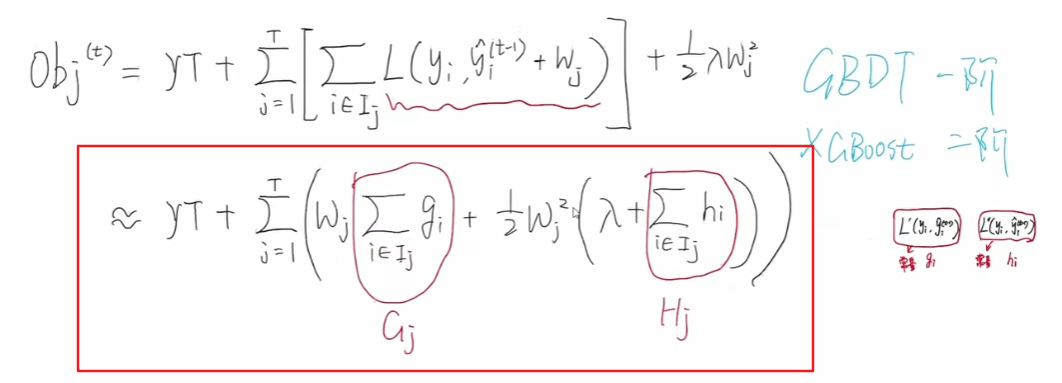
小写的gi 表示一阶梯度,小写的 hi 表示二阶梯度。每一个样本我们都可以得到其gi 和 hi 。

那么一阶梯度和二阶梯度求和结果,用大写字母G和H表示,那么G1 就表示第一个节点中,g3 和 g5 之和,同样的H1 就表示H3和H5 之和。
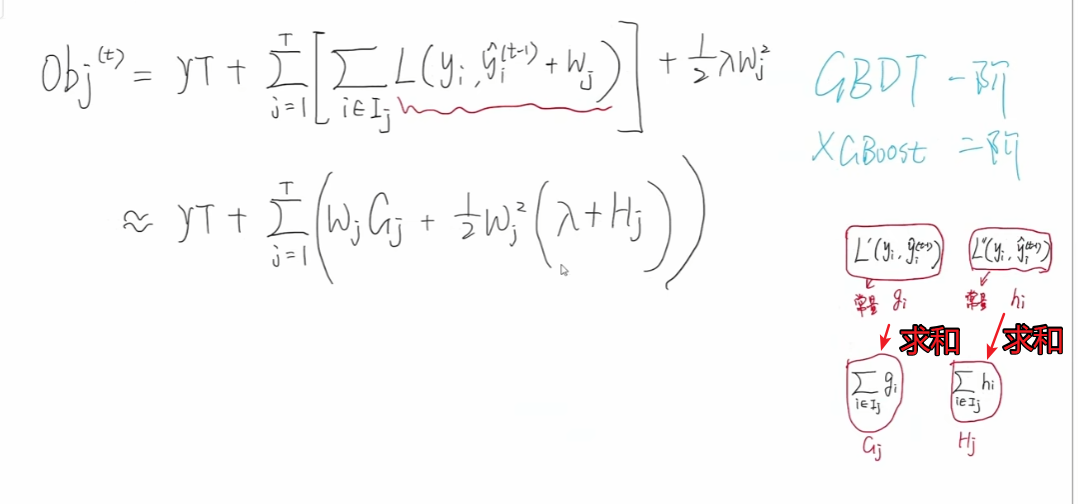
可以看到,我们利用泰勒二级展开,将目标函数成功转化为了一个关于wj 有关的公式,因为我们使用的泰勒二级展开,所以其最高只能是二次幂,这样对我们接下来的优化和计算提供很大的便利。
最优的wj 和最优的目标函数obj
上面我们把目标函数利用泰勒二级展开,改写成了关于wj 有关的公式,本次讨论如何求解w,使得目标函数最小。
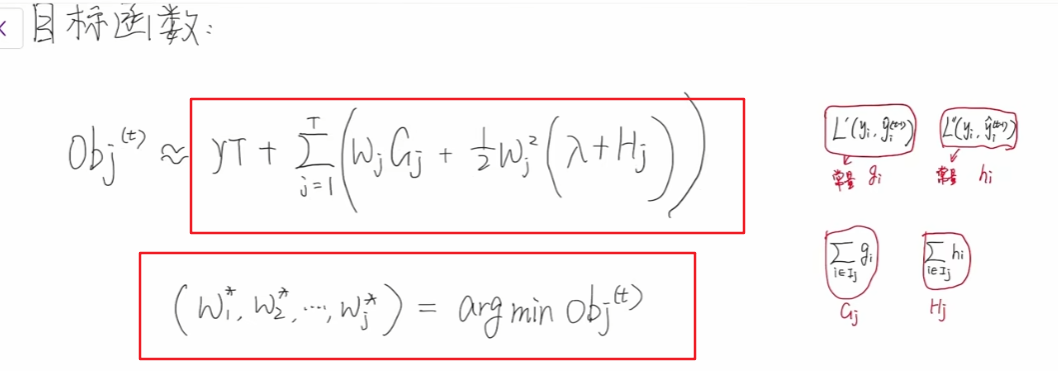
我们上面提到过,在求总体损失的时候,可以换算成求每一个叶子节点的损失累加和,只需要每一个叶子节点的损失值最小就好了。
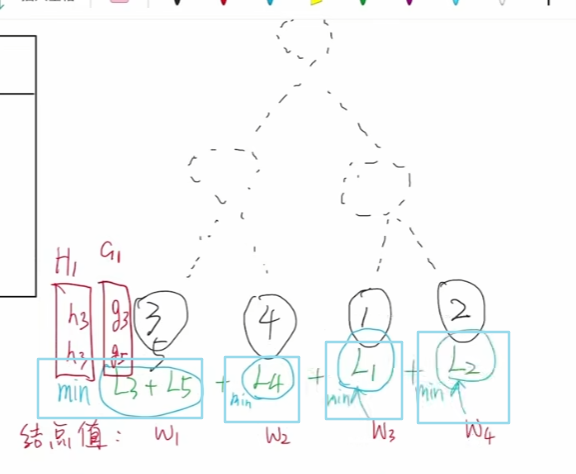
用公式就可以表示为,将每一个w各个击破,分别求解即可:
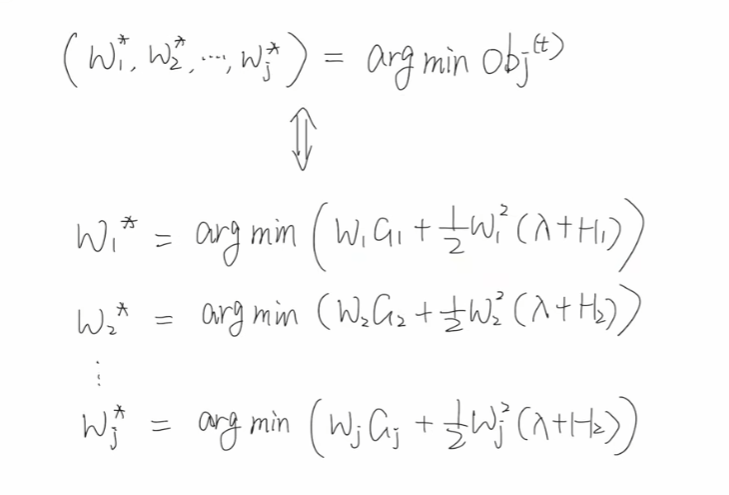
因为其为一元二次方程,我们可以利用w = -(b/2a) 直接求解,但是我们需要知道这个一元二次方程的图像开口是向上的还是向下的。因为hi 是损失函数的二阶导,而我们的损失函数都是凸函数【都是有最小值的那种,对于凸函数,任意两点之间的函数值总是位于这两点连线下方或刚好在连线上】,不然就跟损失函数的含义相冲突了。凸函数的二阶导数一定是大于0 的,所以Hj 一定也是大于0 的。
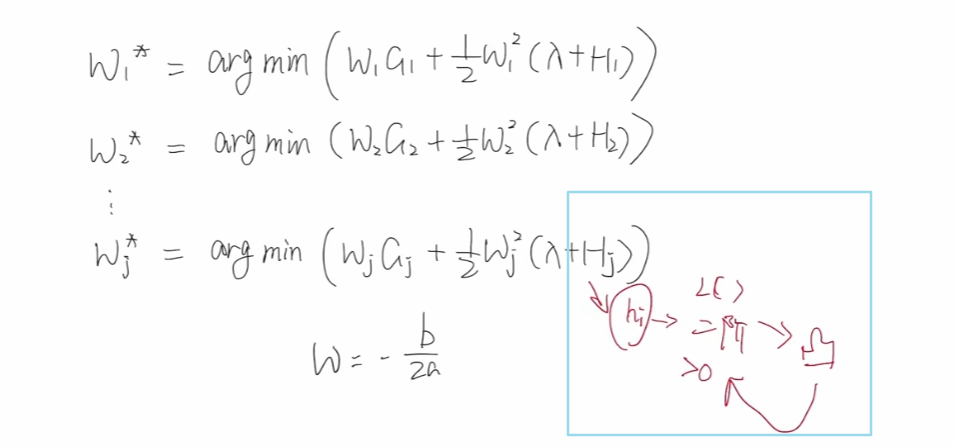
λ作为超参数, 也是大于0 的,所以整体上二项式系数大于0,开口向上,可以利用w = -(b/2a) 直接求解每个叶子节点损失值最小值对应的w。
所以最优解w和最小目标函数可以表示为:
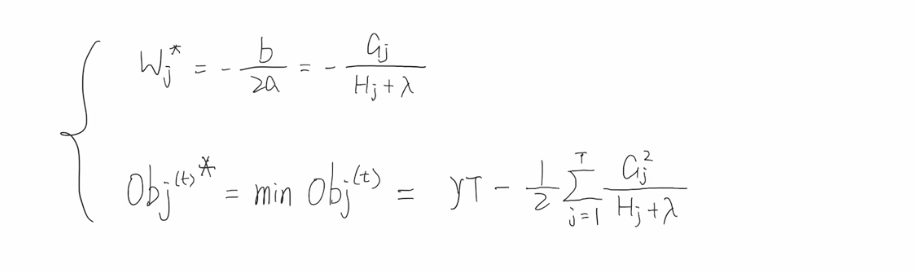
综上,我们在拿到一个个的样本之后,应该先计算出每个样本的一阶梯度【gj】和二阶梯度【hj】,进而计算每一个叶子节点对应的一阶梯度累加和【Gj】 and 二阶梯度累加和【Hj】。那么就可以计算出每个叶子节点的w值了,并且也可以计算出最小的目标函数。