欢迎来到雲闪世界。
聚类是任何数据科学家必备的技能,因为它对解决实际问题具有实用性和灵活性。本文概述了聚类和不同类型的聚类算法。
什么是聚类?
聚类是一种流行的无监督学习技术,旨在根据相似性将对象或观察结果分组。聚类有很多有用的应用,例如市场细分、推荐系统、探索性分析等。
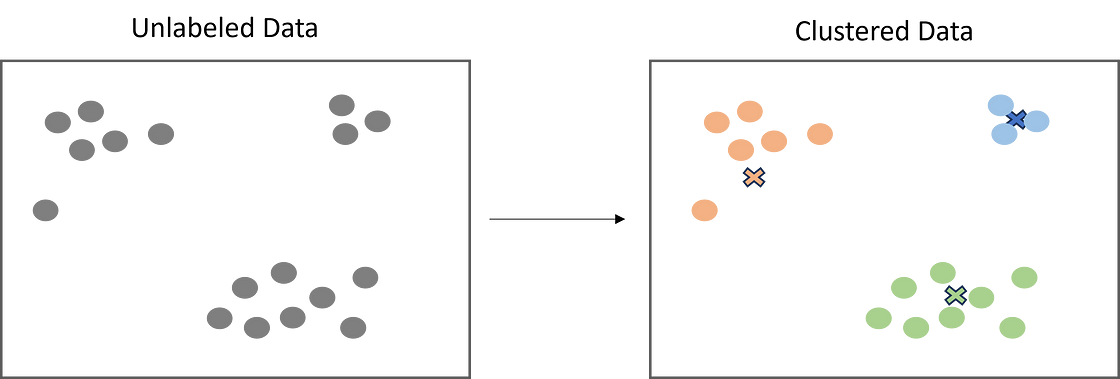
作者图片
虽然聚类是数据科学领域中一种众所周知且广泛使用的技术,但有些人可能不知道不同类型的聚类算法。虽然只有少数几种,但了解这些算法及其工作原理对于获得最适合您用例的结果非常重要。
基于质心的聚类
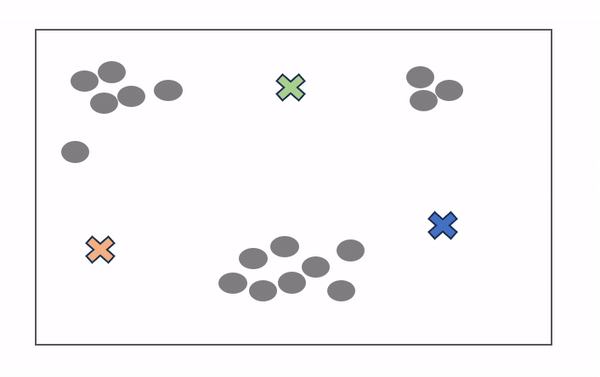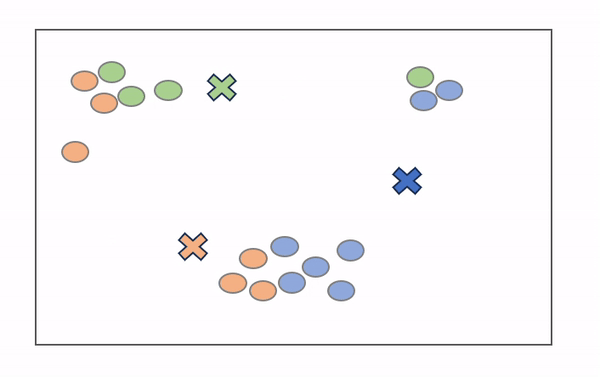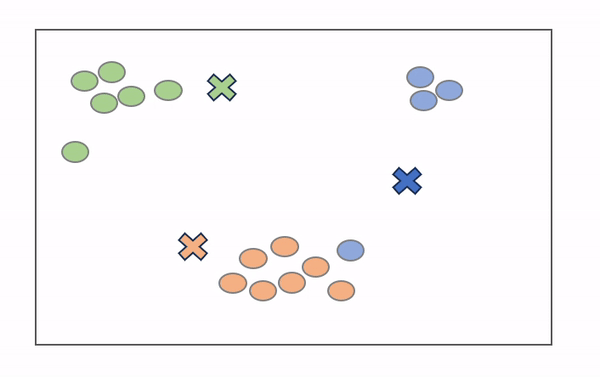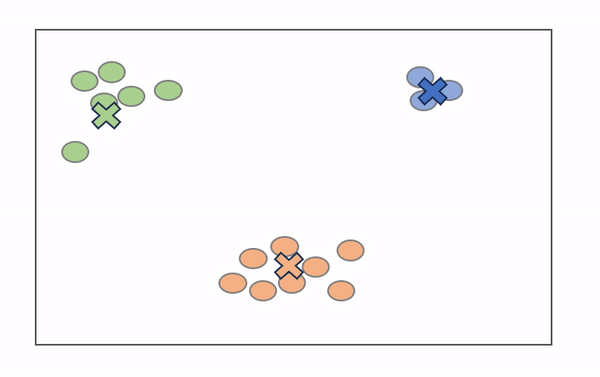
提到聚类,大多数人首先想到的是基于质心的聚类。这是使用一定数量的质心(中心)对数据点进行聚类的“传统”方法,根据数据点与每个质心的距离对数据点进行分组。质心最终成为其分配的数据点的平均值。虽然基于质心的聚类功能强大,但它对异常值不够稳健,因为异常值需要分配给一个聚类。
K-均值
K-Means 是最广泛使用的聚类算法,很可能是您作为数据科学家学习的第一个算法。如上所述,目标是最小化数据点与聚类质心之间的距离总和,以确定每个数据点应属于的正确组。它的工作原理如下:
- 将定义数量的质心随机放入未标记数据的向量空间中(初始化)。
- 每个数据点测量自身与每个质心之间的距离(通常使用欧几里得距离),并将自身分配到最接近的质心。
- 质心重新定位到其指定数据点的平均值。
- 重复步骤 2-3,直到产生“最佳”聚类。
从sklearn.cluster导入KMeans
导入numpy作为np #样本数据
X = np.array([[ 1 , 2 ], [ 1 , 4 ], [ 1 , 0 ], [ 10 , 2 ], [ 10 , 4 ], [ 10 , 0 ]]) #创建 k 均值模型
kmeans = KMeans(n_clusters = 2 , random_state = 0 , n_init = "auto" ).fit(X) #打印结果,用于预测,并打印中心
kmeans.labels_
kmeans.predict([[ 0 , 0 ], [ 12 , 3 ]])
kmeans.cluster_centers_K-均值++
K-Means++ 是对 K-Means 初始化步骤的改进。由于质心是随机放入的,因此有可能将多个质心初始化到同一个聚类中,从而导致结果不佳。
然而,K-Means ++ 通过随机分配最终会找到最大簇的第一个质心来解决这个问题。然后,其他质心被放置在距离初始簇一定距离的地方。K-Means ++ 的目标是将质心推得尽可能远。这样可以得到独特且定义明确的高质量簇。
from sklearn.cluster import KMeans
import numpy as np#sample data
X = np.array([[1, 2], [1, 4], [1, 0],[10, 2], [10, 4], [10, 0]])#create k-means model
kmeans = KMeans(n_clusters = 2, random_state = 0, n_init = "k-means++").fit(X)#print the results, use to predict, and print centers
kmeans.labels_
kmeans.predict([[0, 0], [12, 3]])
kmeans.cluster_centers_基于密度的聚类
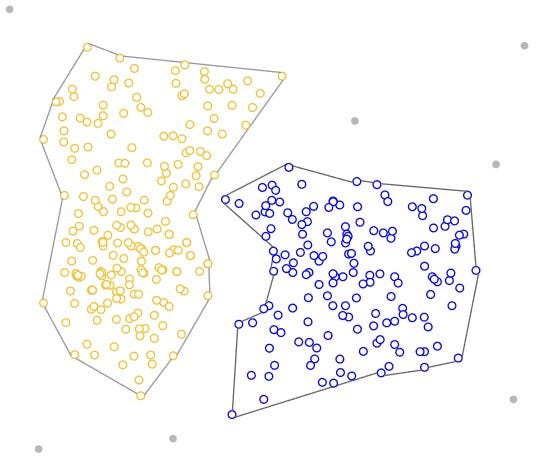
基于密度的算法也是一种流行的聚类形式。但是,它们不是从随机放置的质心进行测量,而是通过识别数据中的高密度区域来创建聚类。基于密度的算法不需要定义聚类数量,因此优化工作量较少。
虽然基于质心的算法在球形聚类中表现更好,但基于密度的算法可以采用任意形状,并且更灵活。它们也不包括聚类中的离群值,因此更稳健。然而,它们在处理不同密度和高维度的数据时会遇到困难。
作者图片
数据库扫描
DBSCAN 是最流行的基于密度的算法。DBSCAN 的工作原理如下:
- DBSCAN 随机选择一个数据点并检查它是否在指定半径内有足够的邻居。
- 如果该点有足够多的邻居,它就会被标记为聚类的一部分。
- DBSCAN 递归检查邻居在半径内是否也有足够的邻居,直到集群中的所有点都被访问过。
- 重复步骤 1-3,直到剩余数据点在半径内没有足够的邻居。
- 剩余的数据点被标记为异常值。
from sklearn.cluster import DBSCAN
import numpy as np#sample data
X = np.array([[1, 2], [2, 2], [2, 3],[8, 7], [8, 8], [25, 80]])#create model
clustering = DBSCAN(eps=3, min_samples=2).fit(X)#print results
clustering.labels_层次聚类
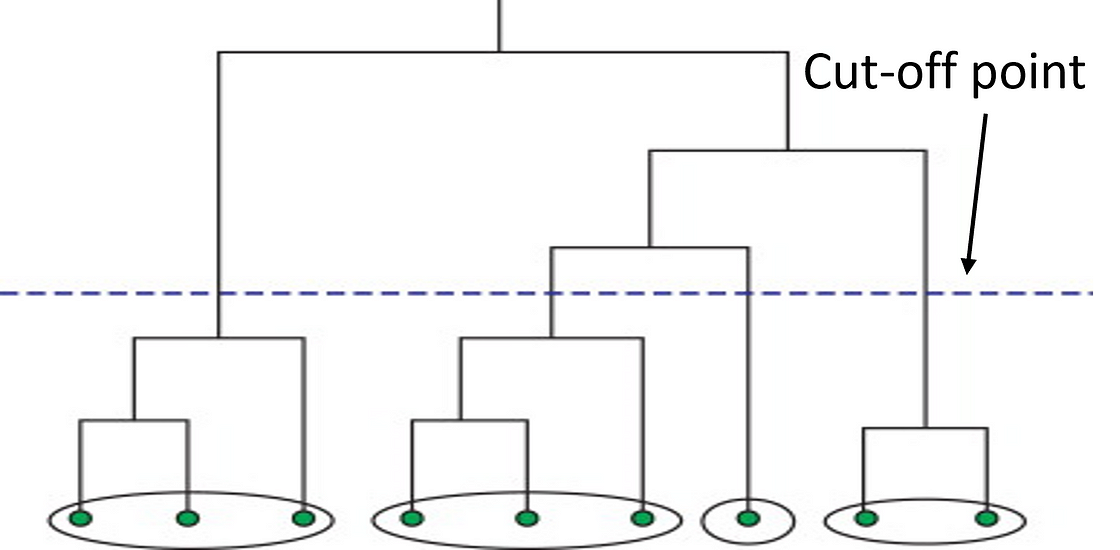
接下来,我们进行层次聚类。此方法首先从原始数据计算距离矩阵。此距离矩阵是最好的,通常通过树状图可视化(见下文)。通过找到最近的邻居,数据点逐个链接在一起,最终形成一个巨大的集群。因此,通过阻止所有数据点链接在一起来识别集群的截止点。
作者图片
通过使用此方法,数据科学家可以通过定义异常值并将其排除在其他聚类中来构建稳健的模型。此方法非常适合分层数据,例如分类法。聚类的数量取决于深度参数,可以是 1-n 之间的任意值。
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster.hierarchy import fcluster#create distance matrix
linkage_data = linkage(data, method = 'ward', metric = 'euclidean', optimal_ordering = True)#view dendrogram
dendrogram(linkage_data)
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Data point')
plt.ylabel('Distance')
plt.show()#assign depth and clusters
clusters = fcluster(linkage_data, 2.5, criterion = 'inconsistent', depth = 5)基于分布的聚类
最后,基于分布的聚类考虑了距离和密度以外的指标,即概率。基于分布的聚类假设数据由概率分布(例如正态分布)组成。该算法创建了表示置信区间的“带”。数据点距离聚类中心越远,我们对数据点属于该聚类的信心就越低。

作者图片
基于分布的聚类由于其假设而很难实现。通常不建议使用这种方法,除非已经进行过严格的分析来确认其结果。例如,使用它来识别营销数据集中的客户细分,并确认这些细分遵循某种分布。这也是一种很好的探索性分析方法,不仅可以查看聚类中心的组成,还可以查看边缘和异常值。
结论
聚类是一种无监督机器学习技术,在许多领域都有越来越广泛的应用。它可用于支持数据分析、细分项目、推荐系统等。上面我们探讨了它们的工作原理、优缺点、代码示例,甚至一些用例。我认为,由于聚类算法的实用性和灵活性,数据科学家必须具备该算法的经验。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)