论文:CLIP-KD: An Empirical Study of CLIP Model Distillation
链接:https://arxiv.org/pdf/2307.12732
CVPR 2024
Introduction
- Motivation:使用大的Teacher CLIP模型有监督蒸馏小CLIP模型,出发点基于在资源受限的应用中,通过teacher模型改进有价值的小CLIP模型。
- 贡献点:提出了多种蒸馏策略,包括relation, feature, gradient and contrastive paradigms四种,检查CLIP-Knowledge Distillation (KD)的有效性
- MSE(Mean Squared Error)loss有效,但是文中证明teacher和student encoder间通过交互式对比学习也很有效。原因归结为最大化了teacher和student模型的特征相似性。
- 在zero shot上取得了较好的效果
- 主要对比基线:TinyCLIP,作者认为该模型受限于weight inheritance,teacher和student模型必须same architecture-style。
- 整个过程分为两个视角:mimicry learning和interactive learning
a. Mimicry learning阶段引导student对齐teacher生成的对应知识,其核心问题在于如何构建有意义的知识。contrastive image-to-text relationships, (image, text) features and gradients
b. Interactive learning阶段将teacher和student结合起来进行联合对比学习,进行隐式学习。aggregate the student and teacher features
Method
-
CLIP,其目标为图像到文本的对比损失和文本到图像的对比损失。

-
Overview
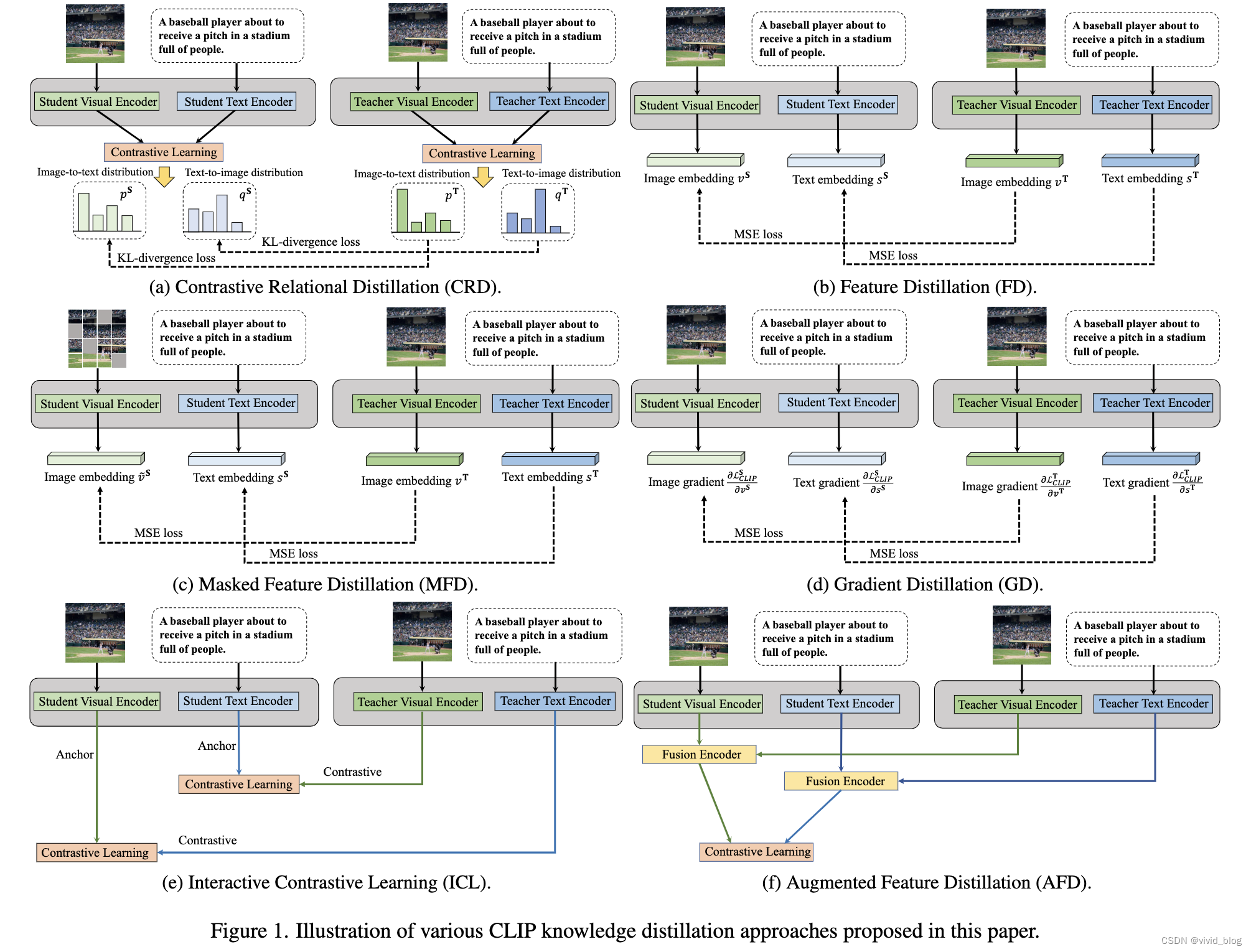
-
Contrastive Relational Distillation(CRD):对比关系蒸馏
一个好的teacher模型将有a well-structured feature space,所以让student更好地模仿 structured semantic relations from the teacher。
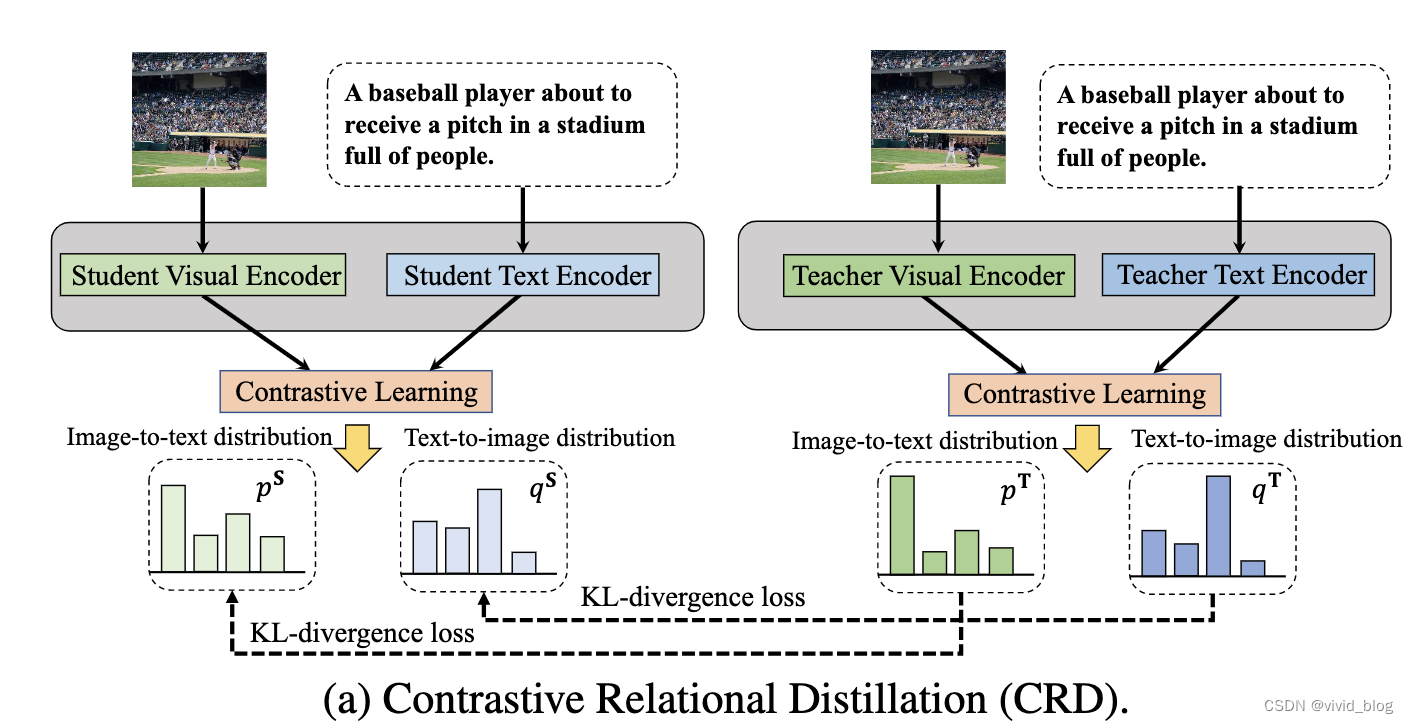
a. 以图像为anchor

b. 以文本为anchor
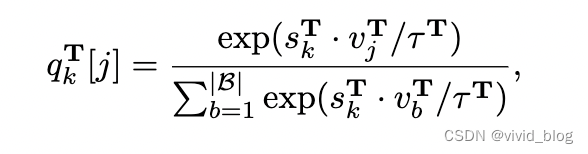
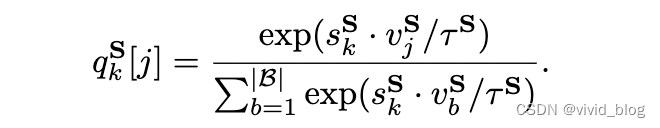
c. 最终损失,KL散度损失

-
特征蒸馏Feature Distillation
对齐teacher和student的feature embedding,如果teacher和student的embedding维度不同,需要一个额外的线性层将其映射到同一个维度。
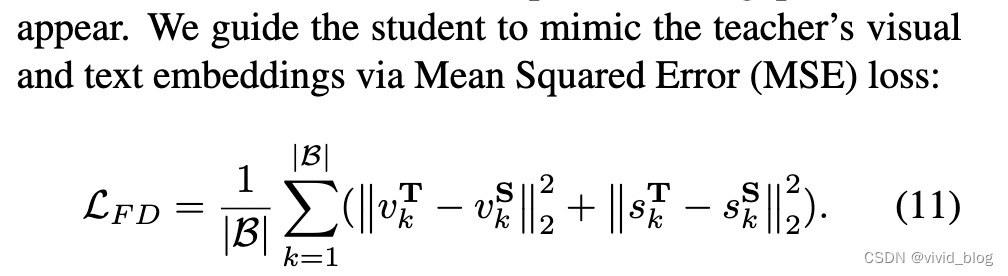
-
Masked Feature Distillation
根据上下文信息恢复masked视觉区域的embedding,mask策略同MAE。

-
Gradient Distillation
保持teacher和student视觉和文本embedding的梯度一致性。the student could better understand how the output should change according to the input。

-
Interactive Contrastive Learning
为了利用teacher和student之间的交互行,对encoders进行交互式对比学习。It regards the student as an anchor to contrast the teacher’s embeddings.
- 举例:给定student的图像embedding,对比的文本embedding为teacher文本编码器输出的embedding而非student。同理,给定student的文本embedding,对比teacher的图像embedding。公式如下



最小化该损失等于最大化教师网络和学生网络之间的互信息的下界。以stundet的embedding为anchor,互信息衡量teacher的对比特征的不确定性降低。作者认为这可以learns more common knowledge from teacher。
- Augmented Feature Distillation
引入fusion encoder强化student embedding,teacher可以指导student优化一个visual-text向量空间。引入visual fusion encoder和text fusion encoder。|| is the concatenation operator,the fusion encoder is a simple linear projection layer。然后融合后的视觉和文本特征计算通用clip的对比损失函数。

- Overall Loss of CLIP Distillation
集合所有损失函数。

Experiment
- 实验配置
- 视觉文本预训练数据:Conceptual Captions 3M (CC3M) and Conceptual 12M (CC12M)
- run over 8 NVIDIA A800 GPUs. The batch size is 1024, where each GPU holds 128 samples.
- set λCRD = 1, λF D = λM F D = 2000,λGD = 108 and λICL = 1. The learnable temperature τis initialized from 0.07.

- 消融实验
表一显示Feature Distillation (FD) 只用一个简单的 MSE损失就达到了最好的效果,MFD效果与其最接近。其次是ICL和CRD。
进一步融合这些损失,FD+CRD+ICL效果最好。FD+ICL超过单纯FD效果,可以看出这两个损失函数互补。基础上再加CRD,效果继续得到了提高。将GD or AFD 到FD+ICL+CRD未有新的提高。

- 实验结果
改变不同的模型结构如下所示。可以看到蒸馏对于以下模型均有提升。(检索任务)

Zero-Shot ImageNet-Related Classification(分类任务):

为了证明本方法可以有效地将知识从大规模数据集转移到改进在小规模数据集上训练,实行以下实验:
实验中分别使用了两个teacher模型,ViT-T/16实验中小的teacher模型的蒸馏效果更好,可能是因为teacher与student的gap过大,不易学习。整体上,clip-kd均超过了tiny-clip的结果。

- 结果分析
左图为收敛曲线,右图正样本减负样本相似度曲线,其相对距离越大越好说明正负样本区分度越高

- 解释为什么不同的KD方法性能不同:下图是蒸馏后teacher和student的相似度统计。FD相似度最高,因为其蒸馏目标就是增加teacher 和student的特征相似度。
