

-
作者: Navid Rajabi, Jana Kosecka
-
单位:乔治梅森大学计算机科学系
-
论文标题:TRAVEL: Training-Free Retrieval and Alignment for Vision-and-Language Navigation
-
论文链接:https://arxiv.org/pdf/2502.07306
主要贡献
-
提出了基于模块化方法的Vision-Language Navigation(VLN)任务解决方案,该方法在零样本设置下利用最先进的大型语言模型(LLMs)和视觉语言模型(VLMs),将问题分解为四个子模块,通过提取导航指令中的地标和访问顺序,检索最后地标的候选位置,生成路径假设,并计算与指令的对齐分数,最终评估路径保真度。
-
在复杂的R2RHabitat指令数据集上,与使用联合语义地图的方法(如VLMaps)相比,展示了优越的性能,并详细量化了视觉定位对导航性能的影响。
研究背景
-
VLN任务:要求控制智能体(在模拟环境或现实世界中)根据自然语言指令在环境中导航。例如,让智能体按照“在走廊左转,去厨房,在水槽边停下”这样的指令行动。该任务需要解析语言输入,将短语与视觉概念(场景、地标、动作等)以及时间线索(如“在……之前”)进行对应。
- 现有方法:
-
端到端方法:采用序列到序列模型,输入语言指令和视觉信息,输出低级导航动作序列。训练时使用强化学习和模仿学习的混合方法,但在新环境和复杂指令下性能受限,且需要大量高质量训练样本和计算资源。
-
基于LLM和VLM的模块化方法:将LLMs、VLMs与传统地图表示和机器人导航堆栈相结合。例如,CLIPNav利用CLIP VLMs和GPT-3进行指令分解和方向判断,但依赖于环境的可导航图,且CLIP在关联地标与图像方面能力有限;VLMaps构建联合视觉语言语义占用图,但指令简单,且需要额外数据集进行LLMs微调。
-
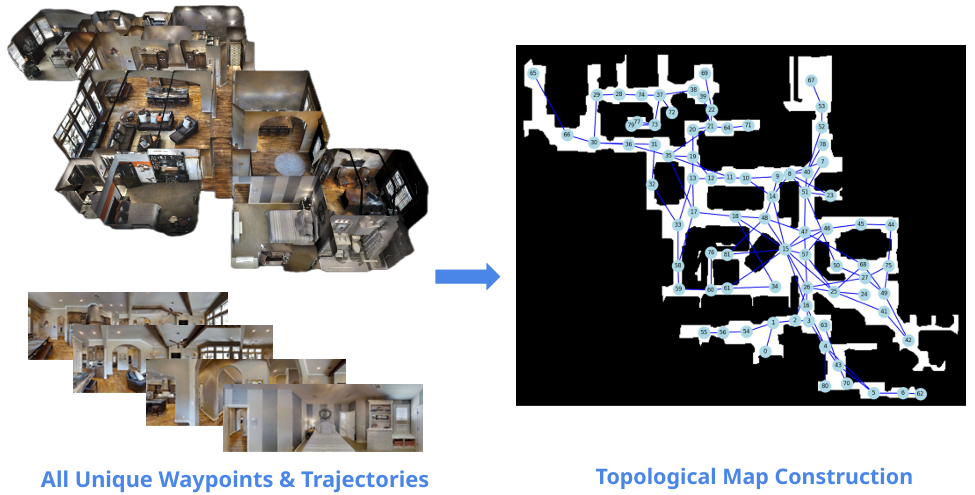
研究方法
-
整体框架:该方法包含八个主要步骤,基于R2R-Habitat数据集的复杂指令,利用预训练的LLMs和VLMs进行零样本导航。

- 步骤详解:
-
步骤1:使用数据集的训练集构建环境的拓扑地图,将每个节点表示为360°RGB全景图,边的权重为1,确保训练集中每个真实路径节点在拓扑地图中有对应节点。
-
步骤2:使用预训练的LLM(LLama-3.1-8B-Instruct)从自然语言指令中提取地标序列,并识别最后地标短语,搜索最后地标的候选目标节点。
-
步骤3:利用最先进的VLM(SigLIP)进行目标/最后地标识别,通过计算全景图与地标文本描述的余弦相似度来完成。与VLMaps方法相比,在127个地标上的平均Precision@10从34.4%提升到70.0%,优势在于使用SigLIP代替CLIP进行地标识别。
-
步骤4:根据前k个目标位置,从起始位置到目标节点计算BFS最短路径,得到k条路径假设。
-
步骤5(方法一):将路径与指令对齐问题视为序列到序列对齐问题,构建全景图序列与地标短语序列的矩阵A,使用VLM(GPT-4o)获取地标在全景图中的二值定位分数,然后通过动态规划算法(Pano2Land)计算路径的归一化对齐分数,类似于最长公共子序列问题。
-
步骤6(方法二):直接提示GPT-4o根据全景图序列、原始自然语言指令和提取的地标短语序列,对路径进行1到5的评分,跳过了单独地标定位和Pano2Land算法计算对齐分数的步骤,但性能略低于方法一,且结果可解释性较差。
-
步骤7:对于每种方法的输出,计算真实路径与最佳对齐路径之间的归一化动态时间规整(nDTW)度量,以评估路径保真度,nDTW比成功率(SR)更符合任务目标,因为SR仅考虑智能体最后位置与真实目标的距离,而不考虑智能体按顺序访问的中间地标。
-

实验
-
实验设置:在R2R-Habitat数据集的五个环境中进行实验,使用上述两种方法对路径进行排名和选择。
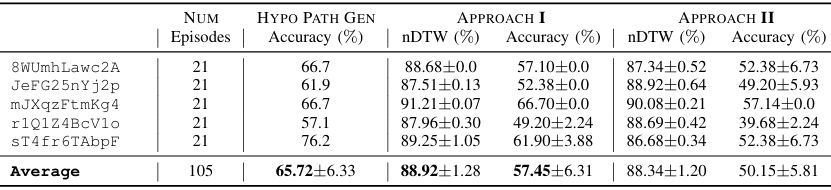
- 实验结果:
-
路径假设生成准确率:平均准确率为65.72%,表明在大多数情况下,真实路径或高度相似的路径能够被选为路径假设之一。
-
nDTW分数:方法一的平均nDTW分数为88.92%,方法二为88.34%,且方法一的成功率(nDTW分数高于87%)更高,说明方法一在路径与指令对齐方面表现更好。
-
标准差:两种方法的标准差均较小,表明结果具有一定的稳定性。
-
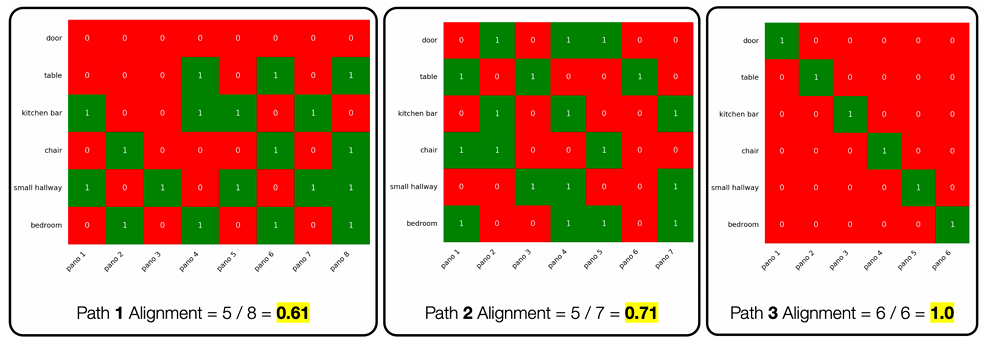
讨论与未来工作
- 局限性:
-
该方法仅适用于之前探索过的环境,并且需要拓扑地图。
-
当自然语言指令不是基于地标,而是包含大量空间和时间短语、动作短语以及绝对距离时,该方法可能不适用。
-
由于管道是模块化的,不是端到端训练的,因此早期阶段(如LLM地标提取和VLM检索)的缺点会传播到后续阶段的Pano2Land对齐或GPT-4o排名中,路径假设的质量最终决定了GPT-4o或其他VLM计算的排名上限。
-
-
未来工作:可以通过对现有的VLMs在导航任务上进行微调,以及将智能体的探索和导航部分无缝整合,使其能够在以前未见过的环境中部署,从而实现性能提升。
