项目背景
网络全部是分割了没有检测。
自动驾驶的车道线和可行驶区域在数据集中的表示
自动驾驶系统中的车道线和可行驶区域的表示方式主要有以下几种:
-
基于几何模型:使用几何模型来描述车道线和可行驶区域的形状和位置,例如直线、曲线、多边形等。车道线和可行驶区域的几何模型可以通过传感器获取的数据进行拟合和计算,例如摄像头图像、激光雷达点云等。
-
基于图像分割:使用图像分割技术来将图像中的像素分为不同的类别,例如车道线、道路表面、背景等。这种方法通常需要使用深度学习模型进行训练,以提高分割的准确性。
-
基于语义地图:使用语义地图来描述车道线和可行驶区域的位置和形状。语义地图是一种高级地图,其中包含丰富的语义信息,例如道路结构、交通标志、路口、建筑物等。车道线和可行驶区域可以作为语义地图中的一个层次,以提供更精确的位置和形状信息。
-
基于点云:使用激光雷达或者毫米波雷达等传感器获取的点云数据,通过点云处理算法来提取车道线和可行驶区域的位置和形状信息。点云数据通常包含大量的点,需要使用点云处理算法进行降噪、分割、拟合等操作,以提取有用的信息。
总之,自动驾驶系统中车道线和可行驶区域的表示方式是多种多样的,选择合适的表示方式可以提高自动驾驶系统的性能和可靠性。
- 就是首先先做一个,就是不是联邦的一个学习版本儿,就是要对路上的一个东西进行一个分割和检测,还有跟踪,就比如说我分割这个汽车,然后这个路可形式区域车道线什么灯,然后还有什么建筑,天空还有什么,一共有19个类,分割的一共是就是18个类,外加上车道线跟可行驶区域,就一共算是20个类。然后,检测,就是检测的话,就是除了车道线缆行驶区的话都要检测出来,然后,也要跟踪下来,这个的话用一个V8其实就可以做,然后,因为现在现在做的是就是现在是在一个数据集上去训练那个18个类的类的分割情况,然后再用这个训练出来的模型作为再用训练出来的这个back棒,然后去去训练车道线可行驶区域,因为这个数据集现在还没有整合,但是后这是现在做的,现在做的情况就做到这儿,但是后续,可能会把这个车道线跟行驶区域,都就是用一个模型就把数据集合并,然后用一个模型来做,这个是下一阶段的一个任务,就是这个这个做好了,如果需然后,还需要看一看就是其他的这个模型的好优点。然后,尽量争取把我们这个跟他们这个精度的话会提高一点,然后就是参考别的模型,改我们这个模型,可能也会是下下阶段的一个东西,然后这个准确率啥的都差不多了以后,就进行联邦学习,就是做一个能保护数据的一个,然后把查分隐私,什么联邦学习直接都加进去,然后来保护数据,这个是最终目标儿。明儿的话你就来公司,然后正正好儿有一个人,就是现在做到这个程度的话,有一个人做的,然后,你们就是跟他去对接一下,最好是你能把这个v5
v6v8的模型看一看,但是你也可以后后补,因为另一个人,他已经提前看了两三天了,之后再补也可以,然后明天就都来听一下这个对接,然后里面的现在做到什么程度,明天就过来一起听一下。好像是70
miou
因为yolop之前做的就是那个车道线和可行驶区域的任务
yolox没考虑过啊
至于用什么模型好的话 是得把这个训练模式搞定了以后下一步再思考的
现在的话数据里 一个是18类 city还有一个是可行驶区域和车道线的bdd
这俩数据做的
现在是分着训练的 先把这俩看看怎么能一个模型训练好
至于模型用哪个的话都行的
只要能把任务做出来就行
因为之前看到了那个v8
有检测有分割
但是他那个检测是分割标的框
所以可以参考city那个数据里的榜单改yolo8的
就是他其实训练的就是分割 但是推理有检测的效果而已 任务最后的效果能达到任务要求就行
因为分割的类不全 那天看的是所有类的效果
我们现在只用的是精标签
那个就10个g好像
5000张照片?
yolop的分割头用了yolo8的backbone
因为现在的数据 要是不能合起来做的话 真就标签有问题 合不上 就得换数据的
之前看的是 这俩数据不是很能合上
因为bdd数据那个车道线的label就是一条线
硬合的话就是把线变粗很高提取多边形标签 这个是我猜的
bdd100k
https://blog.csdn.net/qq_41185868/article/details/100146709
https://zhuanlan.zhihu.com/p/110191240
BDD100K数据集总大小约为约约40TB。该数据集包含超过10万张图像和动态场景的视频,每个场景都有高分辨率的图像和视频。此外,它还包含各种类型的标注信息,包括对象检测和跟踪标注、语义分割标注、实例分割标注、行人和车辆行为预测等。
由于BDD100K数据集非常大,需要大量的存储和计算资源来处理和分析。为方便研究人员使用,BDD100K提供了多种数据格式和工具,如图像、视频、标注文件等。同时,BDD100K还提供了一个基准测试平台,方便用户进行场景理解和自动驾驶等领域的研究和开发。
BDD100K是一个大规模的自动驾驶数据集,包含超过10万个在城市环境下采集的高分辨率图像和视频。该数据集由加州大学伯克利分校(UC Berkeley)的计算机视觉和机器学习实验室(BAIR)发布,旨在为自动驾驶研究提供丰富的数据资源。
BDD100K数据集包含以下内容:
-
图像和视频:BDD100K包含超过10万个采集自不同城市的高分辨率图像和视频。
-
多种标注信息:BDD100K提供了多种标注信息,包括对象检测、语义分割、实例分割、行人行为预测、车辆行为预测等。
-
多种场景:BDD100K涵盖了多种城市场景,包括城市街道、高速公路、停车场等。
-
多样化的对象:BDD100K包含了多种不同的对象,包括行人、车辆、自行车、交通标志等。
BDD100K数据集的发布为自动驾驶领域的研究提供了宝贵的数据资源,可以用于训练和评估自动驾驶系统的性能。同时,BDD100K也为计算机视觉和机器学习领域的研究提供了一个丰富的数据集,可以用于训练和评估各种视觉算法和模型的性能。
BDD100K数据集涵盖了多种城市街道环境下的场景和对象,包括但不限于:
-
场景:城市街道、高速公路、停车场、城市广场、城市交叉口等。
-
对象:行人、自行车、汽车、卡车、公交车、摩托车、交通标志、建筑物等。
-
天气:晴天、阴天、雨天、夜晚等。
-
道路情况:道路标线、隧道、桥梁、交通灯、路障等。
BDD100K数据集提供了多种数据格式,包括图像、视频和标注信息等。下面是BDD100K数据集中常用的几种数据格式:
-
图像格式:BDD100K中的图像格式为JPEG格式,每张图像大小为720x1280像素或者1080x1920像素。
-
视频格式:BDD100K中的视频格式为MP4格式,每个视频的时长不定,一般在30秒到5分钟之间。
-
标注信息格式:BDD100K提供了多种标注信息,包括对象检测、语义分割、实例分割、行人行为预测、车辆行为预测等。标注信息以JSON格式保存,每个JSON文件对应一个图像或视频的标注信息。
在BDD100K数据集中,每个图像或视频都有一个唯一的ID,所有的标注信息都与这个ID相关联。此外,BDD100K还提供了一个数据集索引文件,该文件列出了所有图像和视频的ID以及它们的路径和标注信息文件的路径,方便用户快速访问数据集中的数据。
cityspace
Cityscapes是一个用于计算机视觉领域的大规模数据集,它包含高分辨率的街景图像,旨在为城市街景分割和场景理解等任务提供数据支持。该数据集由德国斯图加特大学计算机视觉中心(MPI-IS)和德国马克斯·普朗克计算机科学研究所(MPI-INF)联合发布。
Cityscapes数据集总大小约为350GB。具体来说,它包含5000张2048x1024像素的高分辨率RGB图像,以及与每张图像相关联的多种标注信息,包括像素级别的语义分割标注、实例级别的语义分割标注、2D和3D边界框标注等。此外,它还包含相机参数、车辆轨迹、城市地图等其他数据。
Cityscapes数据集是一个相对较大的数据集,需要大量的存储和计算资源来处理和分析。为了方便用户使用,Cityscapes数据集提供了多种数据格式和工具,如图像、标注信息、相机参数、城市地图等。同时,Cityscapes还提供了一个基准测试平台,方便用户进行城市街景分割和场景理解等任务的评估和比较。
Cityscapes数据集包含以下数据:
-
图像数据:Cityscapes包含5000张高分辨率的街景图像,每张图像大小为2048x1024像素。
-
标注信息:Cityscapes提供了精细的标注信息,包括像素级别的语义分割标注、实例级别的语义分割标注、2D和3D边界框标注等。标注信息使用JSON和PNG格式保存。
-
其他数据:Cityscapes还提供了相机参数、车辆轨迹、城市地图等其他数据,用于辅助研究和开发城市街景分割和场景理解等任务。
Cityscapes数据集包含以下内容:
-
图像数据:Cityscapes包含5000张高分辨率的街景图像,每张图像大小为2048x1024像素。
-
标注信息:Cityscapes提供了精细的标注信息,包括像素级别的语义分割标注、实例级别的语义分割标注、2D和3D边界框标注等。
-
多样化的场景:Cityscapes涵盖了德国和其他欧洲城市的多样化场景,包括城市中心、郊区、高速公路等。
-
多样化的天气和时间:Cityscapes数据集中的图像采集于不同的天气和时间,包括晴天、阴天、夜晚等。
Cityscapes数据集是计算机视觉领域中一个重要的数据集,它可以用于训练和评估各种视觉算法和模型的性能。该数据集的发布也为城市街景分割和场景理解等任务提供了宝贵的数据资源。
Cityscapes数据集提供了精细的标注信息,包括像素级别的语义分割标注、实例级别的语义分割标注、2D和3D边界框标注等。下面是Cityscapes数据集中常用的标注格式:
-
像素级别的语义分割标注格式:对于每张图像,Cityscapes提供了一个像素级别的语义分割标注图,其中每个像素都被标注为属于某一个类别。标注图使用PNG格式保存,每个像素的值代表该像素所属的类别ID。
-
实例级别的语义分割标注格式:Cityscapes提供了实例级别的语义分割标注,其中每个实例都被标注为一个独立的对象。标注信息使用JSON格式保存,每个JSON文件对应一个图像的标注信息,其中包含每个实例的ID、类别、像素坐标等信息。
-
2D和3D边界框标注格式:Cityscapes提供了2D和3D边界框标注,用于表示物体在图像中的位置和大小。标注信息使用JSON格式保存,每个JSON文件对应一个图像的标注信息,其中包含每个物体的ID、类别、2D边界框和3D边界框等信息。
总之,Cityscapes数据集提供了多种精细的标注信息格式,方便用户进行城市街景分割和场景理解等任务的研究和开发。

以下是一些可以加快训练速度的方法:
-
GPU加速:使用GPU加速训练可以极大地提高训练速度。选择在性能较高的GPU上训练,并使用CUDA或OpenCL等GPU计算框架可以加速深度学习计算。
-
数据增强:通过数据增强技术,如随机裁剪、旋转、翻转、缩放等,可以增加训练样本的多样性,减少过拟合现象,提高训练效果和速度。
-
分布式训练:使用分布式训练技术可以将训练任务分布到多个计算节点上,从而加快训练速度。目前,TensorFlow、PyTorch等深度学习框架都支持分布式训练。
-
小批次训练:使用小批次训练可以减少计算量和存储需求,提高训练速度。同时,使用动态调整批量大小的方法,可以根据模型和数据的特性来自适应地调整批量大小。
-
模型剪枝和量化:通过模型剪枝和量化等技术,可以减少模型参数和计算量,从而提高模型的计算效率和速度。
-
预训练模型:使用预训练模型可以减少训练时间和数据需求,同时提高模型的泛化能力和表现。
总之,通过合理的算法设计和优化,以及合适的硬件设备和软件工具,可以加快深度学习模型的训练速度并提高效果。
联邦学习可以在某些情况下加快训练速度。与传统的集中式机器学习不同,联邦学习将模型分布在多个设备或用户上进行训练,通过在本地训练和更新模型,再将本地模型聚合成全局模型,从而实现模型的更新和优化。
联邦学习的优点之一是可以避免数据集中化带来的隐私泄露和安全问题,同时还可以利用分布式计算的优势,加快训练速度和提高模型的泛化能力。特别是在大规模数据集和复杂模型的情况下,联邦学习可以减少数据传输和存储需求,从而提高训练效率。
然而,联邦学习也存在一些挑战和限制。例如,在联邦学习中,每个设备或用户可能具有不同的数据分布和特性,这可能导致模型的收敛速度和效果不稳定。此外,联邦学习还需要处理模型合并和安全性等问题,需要一定的技术和算法支持。
综上所述,联邦学习可以在特定情况下加快训练速度,但需要根据具体场景和应用需求进行选择和优化。
yolov8
YOLOv8是一个用于目标检测、图像分割和图像分类任务的深度学习模型。它基于深度学习和计算机视觉的前沿进展构建,具有速度和准确性方面的卓越性能。其简化的设计使其适用于各种应用程序,并易于适应不同的硬件平台,从边缘设备到云API。YOLOv8旨在支持任何YOLO架构,而不仅仅是v8。
YOLOv8和YOLOv5都是快速的目标检测模型,能够实时处理图像。然而,YOLOv8比YOLOv5更快,因此对于需要实时目标检测的应用程序来说,它是更好的选择1。此外,YOLOv5比YOLOv8更易于使用,因为它是基于PyTorch框架构建的,使开发人员可以轻松使用和部署1。YOLOv8为训练执行目标检测、实例分割和图像分类的模型提供了统一的框架1。
YOLOv8在准确性方面表现优异。在COCO数据集上,YOLOv8s模型的平均精度为51.4%,而YOLOv8m模型的平均精度为54.2%。此外,YOLOv8在检测小物体方面表现出色,并解决了YOLOv5的一些局限性。
YOLOv8和YOLOv5都是快速的目标检测模型,能够实时处理图像。然而,YOLOv8比YOLOv5更快,因此对于需要实时目标检测的应用程序来说,它是更好的选择1。此外,YOLOv5比YOLOv8更易于使用,因为它是基于PyTorch框架构建的,使开发人员可以轻松使用和部署。YOLOv8为训练执行目标检测、实例分割和图像分类的模型提供了统一的框架1。
YOLOv8在准确性方面表现优异。在COCO数据集上,YOLOv8s模型的平均精度为51.4%,而YOLOv8m模型的平均精度为54.2%。此外,YOLOv8在检测小物体方面表现出色,并解决了YOLOv5的一些局限性。
p5 640
p6 1280
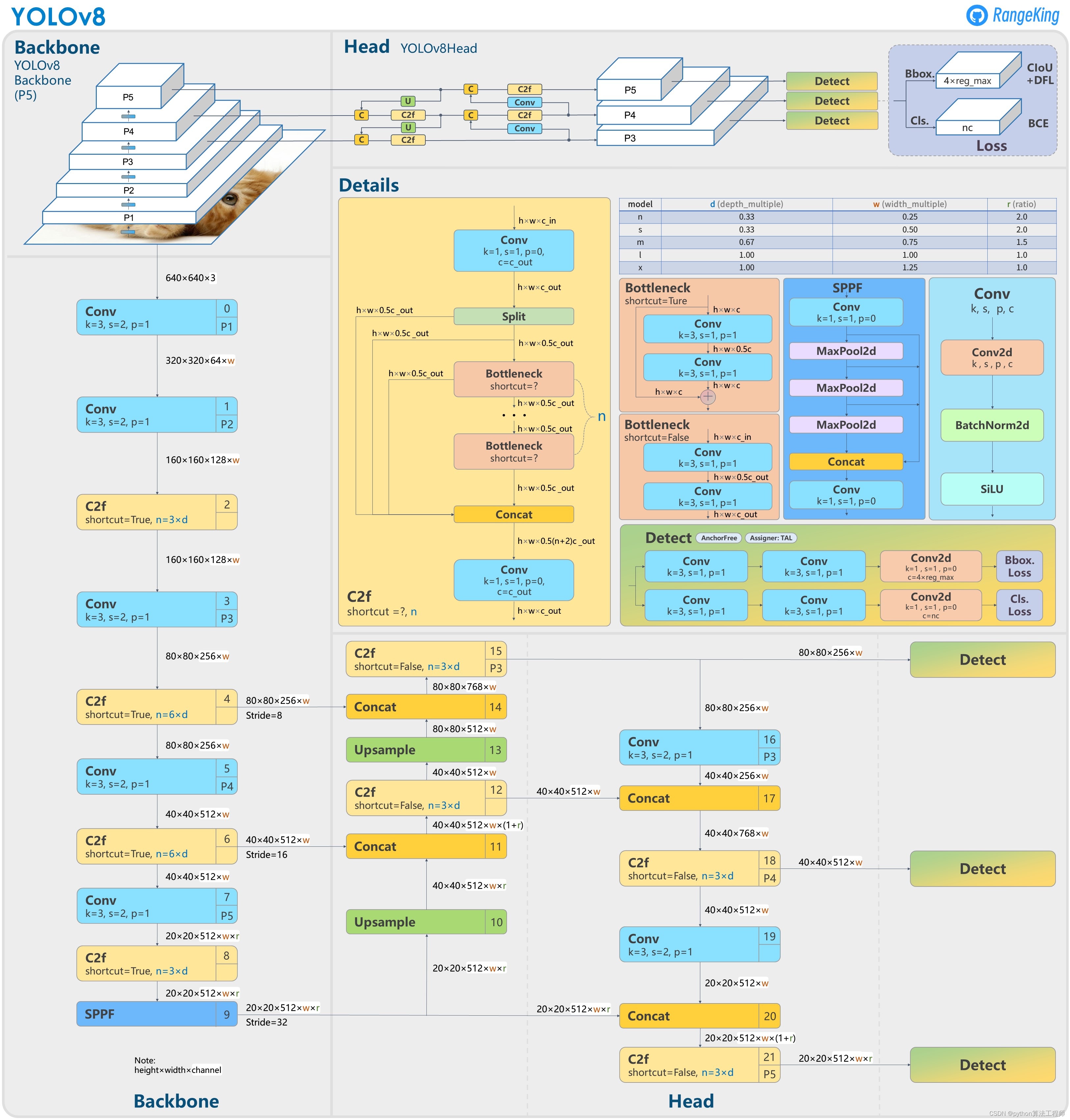 YOLOv8-Seg 模型是 YOLOv8 对象检测模型的扩展,它还对输入图像进行语义分割。YOLOv8-Seg 模型的主干是一个 CSPDarknet53 特征提取器,其后是一个新颖的 C2f 模块,而不是传统的 YOLO 颈部架构。C2f 模块之后是两个分割头,它们学习预测输入图像的语义分割掩码。该模型具有与 YOLOv8 类似的检测头,由五个检测模块和一个预测层组成。YOLOv8-Seg 模型已被证明可以在各种对象检测和语义分割基准测试中取得最先进的结果,同时保持高速和高效。
YOLOv8-Seg 模型是 YOLOv8 对象检测模型的扩展,它还对输入图像进行语义分割。YOLOv8-Seg 模型的主干是一个 CSPDarknet53 特征提取器,其后是一个新颖的 C2f 模块,而不是传统的 YOLO 颈部架构。C2f 模块之后是两个分割头,它们学习预测输入图像的语义分割掩码。该模型具有与 YOLOv8 类似的检测头,由五个检测模块和一个预测层组成。YOLOv8-Seg 模型已被证明可以在各种对象检测和语义分割基准测试中取得最先进的结果,同时保持高速和高效。
与 YOLOv5 相比的变化:
C3用模块C2f替换模块
将第一个替换6x6 Conv为3x3 ConvBackbone
删除两个Conv(YOLOv5 config中的No.10和No.14)
将第一个替换1x1 Conv为3x3 ConvBottleneck
使用 decoupled head 并删除objectness分支
YOLOv3的backbone是DarkNet53,而YOLOv8是Ultralytics的一个新模型,它采用了新的backbone网络、新的无锚点分割头和新的损失函数,使其在速度、大小和准确性方面都有所提高。
yolop
https://cloud.tencent.com/developer/article/2115041
YOLOP是一种全景驾驶感知网络,它是一个高效的多任务网络,可以一个网络模型同时处理自动驾驶中的三个关键任务:物体检测、可行驶区域分割和车道检测,减少推理时间的同时提高了每项任务的性能,显著节省计算成本
YOLOP的分割头是可行驶区域分割和车道线检测。
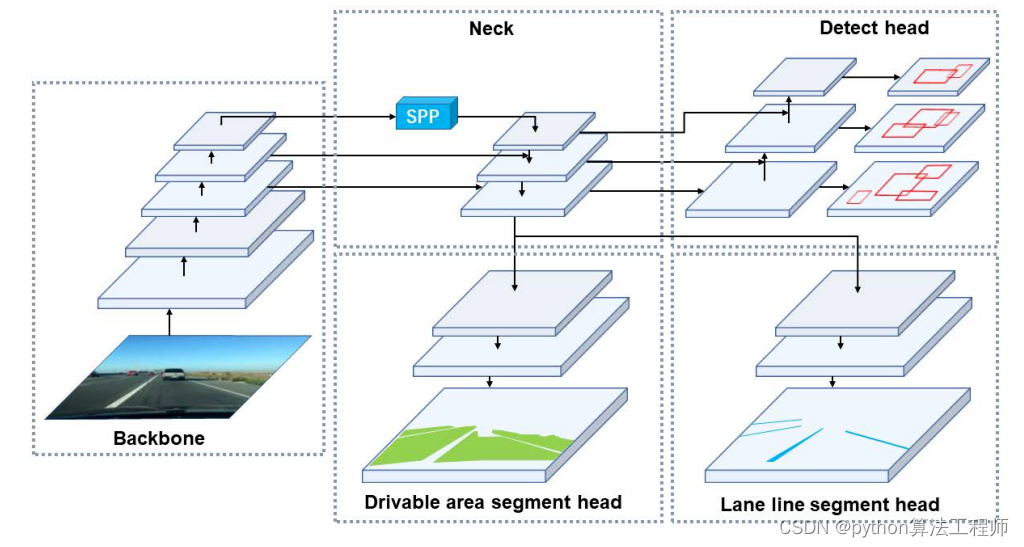
我们提出了一种简单高效的前馈网络,它可以同时完成交通目标检测、可行驶区域分割和车道检测任务。如图2所示,我们的全景驾驶感知单次网络,称为YOLOP,包含一个共享编码器和三个后续解码器,用于解决特定任务。不同解码器之间没有复杂和冗余的共享块,这减少了计算消耗,并使我们的网络能够轻松地进行端到端训练。3.1、编码器我们的网络共享一个编码器,由骨干网络和瓶颈网络组成。3.1.1骨干网骨干网用于提取输入图像的特征。通常,一些经典的图像分类网络作为骨干。由于YOLOv4[1]在对象检测方面的优异性能,我们选择CSPDarket[26]作为骨干,解决了优化过程中梯度重复的问题[27]。它支持特征传播和特征重用,从而减少了参数和计算的数量。因此,有利于保证网络的实时性能。
颈部用于融合主干生成的特征。我们的颈部主要由空间金字塔池(SPP)模块[8]和特征金字塔网络(FPN)模块[11]组成。SPP生成并融合不同尺度的特征,FPN融合不同语义层次的特征,使生成的特征包含多个尺度和多个语义层次的信息。我们在工作中采用了串联的方法来融合特征。
我们网络中的三个头是用于这三项任务的特定解码器。
{0: ‘person’, 1: ‘bicycle’, 2: ‘car’, 3: ‘motorcycle’, 4: ‘airplane’, 5: ‘bus’, 6: ‘train’, 7: ‘truck’, 8: ‘boat’, 9: ‘traffic light’, 10: ‘fire hydrant’, 11: ‘stop sign’, 12: ‘parking meter’, 13: ‘bench’, 14: ‘bird’, 15: ‘cat’, 16: ‘dog’, 17: ‘horse’, 18: ‘sheep’, 19: ‘cow’, 20: ‘elephant’, 21: ‘bear’, 22: ‘zebra’, 23: ‘giraffe’, 24: ‘backpack’, 25: ‘umbrella’, 26: ‘handbag’, 27: ‘tie’, 28: ‘suitcase’, 29: ‘frisbee’, 30: ‘skis’, 31: ‘snowboard’, 32: ‘sports ball’, 33: ‘kite’, 34: ‘baseball bat’, 35: ‘baseball glove’, 36: ‘skateboard’, 37: ‘surfboard’, 38: ‘tennis racket’, 39: ‘bottle’, 40: ‘wine glass’, 41: ‘cup’, 42: ‘fork’, 43: ‘knife’, 44: ‘spoon’, 45: ‘bowl’, 46: ‘banana’, 47: ‘apple’, 48: ‘sandwich’, 49: ‘orange’, 50: ‘broccoli’, 51: ‘carrot’, 52: ‘hot dog’, 53: ‘pizza’, 54: ‘donut’, 55: ‘cake’, 56: ‘chair’, 57: ‘couch’, 58: ‘potted plant’, 59: ‘bed’, 60: ‘dining table’, 61: ‘toilet’, 62: ‘tv’, 63: ‘laptop’, 64: ‘mouse’, 65: ‘remote’, 66: ‘keyboard’, 67: ‘cell phone’, 68: ‘microwave’, 69: ‘oven’, 70: ‘toaster’, 71: ‘sink’, 72: ‘refrigerator’, 73: ‘book’, 74: ‘clock’, 75: ‘vase’, 76: ‘scissors’, 77: ‘teddy bear’, 78: ‘hair drier’, 79: ‘toothbrush’}
yolov8训练代码训练数据集cityspaces
# Ultralytics YOLO 🚀, GPL-3.0 license
from copy import copyimport torch
import torch.nn.functional as Fimport sys
sys.path.append("/home/shenlan08/lihanlin_shijian/ultralytics")
# print(sys.path)from ultralytics.nn.tasks import SegmentationModel
from ultralytics.yolo import v8
from ultralytics.yolo.utils import DEFAULT_CFG, RANK, IterableSimpleNamespace, yaml_loadDEFAULT_CFG_DICT = yaml_load('/home/shenlan08/lihanlin_shijian/ultralytics/ultralytics/yolo/cfg/default.yaml')
DEFAULT_CFG = IterableSimpleNamespace(**DEFAULT_CFG_DICT)from ultralytics.yolo.utils.ops import crop_mask, xyxy2xywh
from ultralytics.yolo.utils.plotting import plot_images, plot_results
from ultralytics.yolo.utils.tal import make_anchors
from ultralytics.yolo.utils.torch_utils import de_parallel
from ultralytics.yolo.v8.detect.train import Loss此代码似乎是segmentation trainer的类定义,它继承自 detection trainer 类。
该方法使用配置字典初始化类并覆盖,并将任务设置为“段”。该方法创建一个分割模型并加载预训练的权重(如果提供)。该方法
返回一个分段验证器对象,供训练期间使用。该方法使用 SegLoss 函数计
算分割损失。该方法通过绘制输入图像、掩码、类标签、边界框和文件路径
来可视化训练样本。这__init__get_modelget_validatorcriterionplot_training_sam
plesplot_metrics方法绘制训练指标,保存在CSV 文件中,用于分割任务。# BaseTrainer python usage
class SegmentationTrainer(v8.detect.DetectionTrainer):def __init__(self, cfg=DEFAULT_CFG, overrides=None):if overrides is None:overrides = {}overrides['task'] = 'segment'super().__init__(cfg, overrides)def get_model(self, cfg=None, weights=None, verbose=True):model = SegmentationModel(cfg, ch=3, nc=self.data['nc'], verbose=verbose and RANK == -1)if weights:model.load(weights)return modeldef get_validator(self):self.loss_names = 'box_loss', 'seg_loss', 'cls_loss', 'dfl_loss'return v8.segment.SegmentationValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))def criterion(self, preds, batch):if not hasattr(self, 'compute_loss'):self.compute_loss = SegLoss(de_parallel(self.model), overlap=self.args.overlap_mask)return self.compute_loss(preds, batch)def plot_training_samples(self, batch, ni):images = batch['img']masks = batch['masks']cls = batch['cls'].squeeze(-1)bboxes = batch['bboxes']paths = batch['im_file']batch_idx = batch['batch_idx']plot_images(images, batch_idx, cls, bboxes, masks, paths=paths, fname=self.save_dir / f'train_batch{ni}.jpg')def plot_metrics(self):plot_results(file=self.csv, segment=True) # save results.png这段代码定义了SegLoss类,它是该类的子类Loss。该方法使用分割模型和
指示是否计算掩码重叠的标志来__init__初始化类。该方法使用预测的和真
实的掩码和框来计算分割损失。它首先将预测特征拆分为预测分布、预测分
数和预测掩码。然后它计算目标,这些目标由针对给定图像大小进行预处理
的地面实况标签和地面实况框组成。预测框SegLoss__call__然后解码,
并将预测分数和真实分数分配给彼此以计算分类损失。如果存在前景蒙版,
则计算边界框和分割损失。最后,将损失乘以相应的收益,求和并返回。该
single_mask_loss方法计算一幅图像的预测掩模和真实掩模之间的二元交
叉熵损失。# Criterion class for computing training losses
class SegLoss(Loss):def __init__(self, model, overlap=True): # model must be de-paralleledsuper().__init__(model)self.nm = model.model[22].nm # number of masksself.overlap = overlapdef __call__(self, preds, batch):loss = torch.zeros(4, device=self.device) # box, cls, dflfeats, pred_masks, proto = preds if len(preds) == 3 else preds[1]batch_size, _, mask_h, mask_w = proto.shape # batch size, number of masks, mask height, mask widthpred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split((self.reg_max * 4, self.nc), 1)# b, grids, ..pred_scores = pred_scores.permute(0, 2, 1).contiguous()pred_distri = pred_distri.permute(0, 2, 1).contiguous()pred_masks = pred_masks.permute(0, 2, 1).contiguous()dtype = pred_scores.dtypeimgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)# targetstry:batch_idx = batch['batch_idx'].view(-1, 1)targets = torch.cat((batch_idx, batch['cls'].view(-1, 1), batch['bboxes']), 1)targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxymask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)except RuntimeError as e:raise TypeError('ERROR ❌ segment dataset incorrectly formatted or not a segment dataset.\n'"This error can occur when incorrectly training a 'segment' model on a 'detect' dataset, ""i.e. 'yolo train model=yolov8n-seg.pt data=coco128.yaml'.\nVerify your dataset is a ""correctly formatted 'segment' dataset using 'data=coco128-seg.yaml' "'as an example.\nSee https://docs.ultralytics.com/tasks/segmentation/ for help.') from e# pboxespred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)_, target_bboxes, target_scores, fg_mask, target_gt_idx = self.assigner(pred_scores.detach().sigmoid(), (pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),anchor_points * stride_tensor, gt_labels, gt_bboxes, mask_gt)target_scores_sum = max(target_scores.sum(), 1)# cls loss# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL wayloss[2] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCEif fg_mask.sum():# bbox lossloss[0], loss[3] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes / stride_tensor,target_scores, target_scores_sum, fg_mask)# masks lossmasks = batch['masks'].to(self.device).float()if tuple(masks.shape[-2:]) != (mask_h, mask_w): # downsamplemasks = F.interpolate(masks[None], (mask_h, mask_w), mode='nearest')[0]for i in range(batch_size):if fg_mask[i].sum():mask_idx = target_gt_idx[i][fg_mask[i]]if self.overlap:gt_mask = torch.where(masks[[i]] == (mask_idx + 1).view(-1, 1, 1), 1.0, 0.0)else:gt_mask = masks[batch_idx.view(-1) == i][mask_idx]xyxyn = target_bboxes[i][fg_mask[i]] / imgsz[[1, 0, 1, 0]]marea = xyxy2xywh(xyxyn)[:, 2:].prod(1)mxyxy = xyxyn * torch.tensor([mask_w, mask_h, mask_w, mask_h], device=self.device)loss[1] += self.single_mask_loss(gt_mask, pred_masks[i][fg_mask[i]], proto[i], mxyxy,marea) # seg loss# WARNING: Uncomment lines below in case of Multi-GPU DDP unused gradient errors# else:# loss[1] += proto.sum() * 0 + pred_masks.sum() * 0# else:# loss[1] += proto.sum() * 0 + pred_masks.sum() * 0loss[0] *= self.hyp.box # box gainloss[1] *= self.hyp.box / batch_size # seg gainloss[2] *= self.hyp.cls # cls gainloss[3] *= self.hyp.dfl # dfl gainreturn loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)def single_mask_loss(self, gt_mask, pred, proto, xyxy, area):# Mask loss for one imagepred_mask = (pred @ proto.view(self.nm, -1)).view(-1, *proto.shape[1:]) # (n, 32) @ (32,80,80) -> (n,80,80)loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction='none')return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).mean()此代码定义train函数,可用于使用Ultralytics的 YOLO 库训练分割
模型。该函数接受一个配置对象,该对象指定用于训练的模型、数据集和设
备。如果设置为,则该函数使用YOLO的Python API来训练模型。否则,
它会创建该类的实例并使用其方法训练模型。该类是 的包装器,它提供了使
用 YOLO训练分割模型的附加功能。 cfguse_pythonTrueSegmentationTrainertrainSegmentationTrainertorch.nn.Moduledef train(cfg=DEFAULT_CFG, use_python=False):model = cfg.model or 'best(1).pt'data = cfg.data or 'cityspaces.yaml' # or yolo.ClassificationDataset("mnist")device = cfg.device if cfg.device is not None else '2'args = dict(model=model, data=data, device=device)if use_python:from ultralytics import YOLOYOLO(model).train(**args)else:trainer = SegmentationTrainer(overrides=args)trainer.train()if __name__ == '__main__':train()ylov8训练输出结果
root@notebook-rn-20230301115620425bi81-k2w3o-0:/home/shenlan08/lihanlin_shijian/last_task/ultralytics# /root/miniconda3/bin/python /home/shenlan08/lihanlin_shijian/last_task/ultralytics/ultralytics/yolo/v8/segment/train.py
WARNING ⚠️ Ultralytics settings reset to defaults. This is normal and may be due to a recent ultralytics package update, but may have overwritten previous settings.
View and update settings with 'yolo settings' or at '/root/.config/Ultralytics/settings.yaml'
New https://pypi.org/project/ultralytics/8.0.81 available 😃 Update with 'pip install -U ultralytics'
Ultralytics YOLOv8.0.61 🚀 Python-3.8.5 torch-1.8.0+cu111 CUDA:2 (GeForce RTX 2080 Ti, 11019MiB)CUDA:3 (GeForce RTX 2080 Ti, 11019MiB)
yolo/engine/trainer: task=segment, mode=train, model=yolov8m-seg.pt, data=cityspaces.yaml, epochs=100, patience=50, batch=6, imgsz=640, save=True, save_period=-1, cache=False, device=2,3, workers=8, project=None, name=None, exist_ok=False, pretrained=False, optimizer=SGD, verbose=True, seed=0, deterministic=True, single_cls=False, image_weights=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, show=False, save_txt=False, save_conf=False, save_crop=False, hide_labels=False, hide_conf=False, vid_stride=1, line_thickness=3, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, boxes=True, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, fl_gamma=0.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0, cfg=None, v5loader=False, tracker=botsort.yaml, save_dir=/home/shenlan08/lihanlin_shijian/last_task/ultralytics/runs/segment/train6
Overriding model.yaml nc=80 with nc=18from n params module arguments 0 -1 1 1392 ultralytics.nn.modules.Conv [3, 48, 3, 2] 1 -1 1 41664 ultralytics.nn.modules.Conv [48, 96, 3, 2] 2 -1 2 111360 ultralytics.nn.modules.C2f [96, 96, 2, True] 3 -1 1 166272 ultralytics.nn.modules.Conv [96, 192, 3, 2] 4 -1 4 813312 ultralytics.nn.modules.C2f [192, 192, 4, True] 5 -1 1 664320 ultralytics.nn.modules.Conv [192, 384, 3, 2] 6 -1 4 3248640 ultralytics.nn.modules.C2f [384, 384, 4, True] 7 -1 1 1991808 ultralytics.nn.modules.Conv [384, 576, 3, 2] 8 -1 2 3985920 ultralytics.nn.modules.C2f [576, 576, 2, True] 9 -1 1 831168 ultralytics.nn.modules.SPPF [576, 576, 5] 10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 11 [-1, 6] 1 0 ultralytics.nn.modules.Concat [1] 12 -1 2 1993728 ultralytics.nn.modules.C2f [960, 384, 2] 13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 14 [-1, 4] 1 0 ultralytics.nn.modules.Concat [1] 15 -1 2 517632 ultralytics.nn.modules.C2f [576, 192, 2] 16 -1 1 332160 ultralytics.nn.modules.Conv [192, 192, 3, 2] 17 [-1, 12] 1 0 ultralytics.nn.modules.Concat [1] 18 -1 2 1846272 ultralytics.nn.modules.C2f [576, 384, 2] 19 -1 1 1327872 ultralytics.nn.modules.Conv [384, 384, 3, 2] 20 [-1, 9] 1 0 ultralytics.nn.modules.Concat [1] 21 -1 2 4207104 ultralytics.nn.modules.C2f [960, 576, 2] 22 [15, 18, 21] 1 5169446 ultralytics.nn.modules.Segment [18, 32, 192, [192, 384, 576]]
YOLOv8m-seg summary: 331 layers, 27250070 parameters, 27250054 gradients, 110.4 GFLOPsTransferred 531/537 items from pretrained weights
Running DDP command ['/root/miniconda3/bin/python', '-m', 'torch.distributed.launch', '--nproc_per_node', '2', '--master_port', '57941', '/home/shenlan08/lihanlin_shijian/last_task/ultralytics/ultralytics/yolo/v8/segment/train.py', 'task=segment', 'mode=train', 'model=yolov8m-seg.pt', 'data=cityspaces.yaml', 'epochs=100', 'patience=50', 'batch=6', 'imgsz=640', 'save=True', 'save_period=-1', 'cache=False', 'device=2,3', 'workers=8', 'project=None', 'name=None', 'exist_ok=False', 'pretrained=False', 'optimizer=SGD', 'verbose=True', 'seed=0', 'deterministic=True', 'single_cls=False', 'image_weights=False', 'rect=False', 'cos_lr=False', 'close_mosaic=10', 'resume=False', 'amp=True', 'overlap_mask=True', 'mask_ratio=4', 'dropout=0.0', 'val=True', 'split=val', 'save_json=False', 'save_hybrid=False', 'conf=None', 'iou=0.7', 'max_det=300', 'half=False', 'dnn=False', 'plots=True', 'source=None', 'show=False', 'save_txt=False', 'save_conf=False', 'save_crop=False', 'hide_labels=False', 'hide_conf=False', 'vid_stride=1', 'line_thickness=3', 'visualize=False', 'augment=False', 'agnostic_nms=False', 'classes=None', 'retina_masks=False', 'boxes=True', 'format=torchscript', 'keras=False', 'optimize=False', 'int8=False', 'dynamic=False', 'simplify=False', 'opset=None', 'workspace=4', 'nms=False', 'lr0=0.01', 'lrf=0.01', 'momentum=0.937', 'weight_decay=0.0005', 'warmup_epochs=3.0', 'warmup_momentum=0.8', 'warmup_bias_lr=0.1', 'box=7.5', 'cls=0.5', 'dfl=1.5', 'fl_gamma=0.0', 'label_smoothing=0.0', 'nbs=64', 'hsv_h=0.015', 'hsv_s=0.7', 'hsv_v=0.4', 'degrees=0.0', 'translate=0.1', 'scale=0.5', 'shear=0.0', 'perspective=0.0', 'flipud=0.0', 'fliplr=0.5', 'mosaic=1.0', 'mixup=0.0', 'copy_paste=0.0', 'cfg=None', 'v5loader=False', 'tracker=botsort.yaml']
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
New https://pypi.org/project/ultralytics/8.0.81 available 😃 Update with 'pip install -U ultralytics'
Overriding model.yaml nc=80 with nc=18
Transferred 531/537 items from pretrained weights
DDP settings: RANK 0, WORLD_SIZE 2, DEVICE cuda:0
TensorBoard: Start with 'tensorboard --logdir /home/shenlan08/lihanlin_shijian/last_task/ultralytics/runs/segment/train6', view at http://localhost:6006/
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed ✅
optimizer: SGD(lr=0.01) with parameter groups 86 weight(decay=0.0), 97 weight(decay=0.000515625), 96 bias
train: Scanning /home/shenlan08/lihanlin_shijian/cityspaces/labels/train... 2975 images, 0 backgrounds, 3 corrupt: 100%|██████████| 2975/2975 [00:22<00:00, 129.88it/s]
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000000_000019_leftImg8bit.png: 6 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000026_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000030_000019_leftImg8bit.png: 4 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000031_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000034_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000042_000019_leftImg8bit.png: 3 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000054_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000058_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000060_000019_leftImg8bit.png: 24 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000061_000019_leftImg8bit.png: 40 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000062_000019_leftImg8bit.png: 9 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000064_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000070_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000072_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000078_000019_leftImg8bit.png: 4 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000079_000019_leftImg8bit.png: 5 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000080_000019_leftImg8bit.png: 45 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000090_000019_leftImg8bit.png: 2 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/aachen_000092_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_020655_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_022645_leftImg8bit.png: 4 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_026356_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_034015_leftImg8bit.png: 2 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_034141_leftImg8bit.png: 2 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_036051_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_038927_leftImg8bit.png: 2 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_043102_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_047499_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_047870_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_051152_leftImg8bit.png: 2 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_051271_leftImg8bit.png: 2 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/hanover_000000_051536_leftImg8bit.png: 2 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/ulm_000056_000019_leftImg8bit.png: 2 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/ulm_000058_000019_leftImg8bit.png: 3 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/ulm_000067_000019_leftImg8bit.png: 3 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/ulm_000068_000019_leftImg8bit.png: 3 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/ulm_000069_000019_leftImg8bit.png: 3 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/ulm_000078_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/ulm_000079_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/ulm_000084_000019_leftImg8bit.png: 2 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/weimar_000013_000019_leftImg8bit.png: ignoring corrupt image/label: non-normalized or out of bounds coordinates [ 1.001]
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/weimar_000024_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/zurich_000027_000019_leftImg8bit.png: 1 duplicate labels removed
train: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/train/zurich_000107_000019_leftImg8bit.png: 1 duplicate labels removed
train: New cache created: /home/shenlan08/lihanlin_shijian/cityspaces/labels/train.cache
val: Scanning /home/shenlan08/lihanlin_shijian/cityspaces/labels/val... 500 images, 0 backgrounds, 3 corrupt: 100%|██████████| 500/500 [00:04<00:00, 113.83it/s]
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/frankfurt_000001_016273_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/frankfurt_000001_017101_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/frankfurt_000001_028232_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/frankfurt_000001_044787_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/frankfurt_000001_046272_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/frankfurt_000001_077434_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/lindau_000000_000019_leftImg8bit.png: ignoring corrupt image/label: non-normalized or out of bounds coordinates [ 1.0034]
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/lindau_000013_000019_leftImg8bit.png: ignoring corrupt image/label: non-normalized or out of bounds coordinates [ 1.0005]
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/lindau_000018_000019_leftImg8bit.png: ignoring corrupt image/label: non-normalized or out of bounds coordinates [ 1.001]
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/munster_000015_000019_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/munster_000026_000019_leftImg8bit.png: 2 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/munster_000029_000019_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/munster_000049_000019_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/munster_000108_000019_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/munster_000140_000019_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/munster_000141_000019_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/munster_000142_000019_leftImg8bit.png: 1 duplicate labels removed
val: WARNING ⚠️ /home/shenlan08/lihanlin_shijian/cityspaces/images/val/munster_000167_000019_leftImg8bit.png: 1 duplicate labels removed
val: New cache created: /home/shenlan08/lihanlin_shijian/cityspaces/labels/val.cache
Plotting labels to /home/shenlan08/lihanlin_shijian/last_task/ultralytics/runs/segment/train6/labels.jpg...
Image sizes 640 train, 640 val
Using 6 dataloader workers
Logging results to /home/shenlan08/lihanlin_shijian/last_task/ultralytics/runs/segment/train6
Starting training for 100 epochs...Epoch GPU_mem box_loss seg_loss cls_loss dfl_loss Instances Size1/100 5.21G 1.501 3.665 1.669 1.309 172 640: 100%|██████████| 496/496 [04:18<00:00, 1.92it/s]Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 83/83 [00:20<00:00, 4.07it/s]all 497 32583 0.511 0.367 0.369 0.22 0.446 0.295 0.274 0.115Epoch GPU_mem box_loss seg_loss cls_loss dfl_loss Instances Size2/100 7.09G 1.375 3.271 1.17 1.228 54 640: 100%|██████████| 496/496 [04:18<00:00, 1.92it/s]Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 83/83 [00:12<00:00, 6.72it/s]all 497 32583 0.602 0.354 0.396 0.232 0.508 0.286 0.293 0.125Epoch GPU_mem box_loss seg_loss cls_loss dfl_loss Instances Size3/100 3.41G 1.41 3.316 1.172 1.252 233 640: 6%|▌ | 30/496 [00:16<03:02, 2.55it/s]
yolop训练代码,训练数据集bdd100k
import argparse
import os, sys
import math
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
#os.environ['RANK']='0'
#os.environ['WORLD_SIZE']='4'
#os.environ['MASTER_ADDR'] = 'localhost'
#os.environ['MASTER_PORT'] = '5678'import pprint
import time
import torch
import torch.nn.parallel
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.cuda import amp
import torch.distributed as dist
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import numpy as np
from lib.utils import DataLoaderX, torch_distributed_zero_first
from tensorboardX import SummaryWriterimport lib.dataset as dataset
from lib.config import cfg
from lib.config import update_config
from lib.core.loss import get_loss
from lib.core.function import train
from lib.core.function import validate
from lib.core.general import fitness
from lib.models import get_net
from lib.utils import is_parallel
from lib.utils.utils import get_optimizer
from lib.utils.utils import save_checkpoint
from lib.utils.utils import create_logger, select_device
from lib.utils import run_anchor这是一个为 Python 脚本定义和解析命令行参数的函数。它使用argparse模块来定义和解析将在脚本运行时传递给脚本的参数。该函数定义了几个参数,包括模型、日志和数据的目录,以及使用SyncBatchNorm 的标志和对象置信度阈值的参数以及非最大抑制 (NMS) 的IOU 阈值。parse_args()然后该函数使用该类argparse.ArgumentParser创建一个解析器对象并将定义的参数添加到它。然后它解析命令行参数并将它们作为args对象返回。此函数简化了将参数传递给脚本的过程,并且可以更轻松地根据用户需要自定义脚本的行为。def parse_args():parser = argparse.ArgumentParser(description='Train Multitask network')# general# parser.add_argument('--cfg',# help='experiment configure file name',# required=True,# type=str)# phillyparser.add_argument('--modelDir',help='model directory',type=str,default='')parser.add_argument('--logDir',help='log directory',type=str,default='runs/')parser.add_argument('--dataDir',help='data directory',type=str,default='')parser.add_argument('--prevModelDir',help='prev Model directory',type=str,default='')parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')parser.add_argument('--conf-thres', type=float, default=0.001, help='object confidence threshold')parser.add_argument('--iou-thres', type=float, default=0.6, help='IOU threshold for NMS')args = parser.parse_args()return argsdef main():
此代码块设置脚本的配置并初始化 DDP(分布式数据并行)变量。它首先调用parse_args()函数来解析命令行参数并相应地更新配置文件。接下来,它通过设置和基于环境变量来初始化DDP 变量。如果未设置这些变量,则设置为 1 并设置为 -1。world_sizeglobal_rankworld_sizeglobal_rank该脚本然后创建一个记录器并设置 tensorboard 日志目录。如果等级为 -1 或 0,则该函数将参数和配置打印到记录器并为张量板编写器设置字典。最后,它设置了 cudnn 相关设置。总的来说,此代码块为分布式训练设置了必要的配置和DDP变量,并设置了用于监控训练过程的记录器和张量板编写器。# set all the configurationsargs = parse_args()update_config(cfg, args)# Set DDP variablesworld_size = int(os.environ['WORLD_SIZE']) if 'WORLD_SIZE' in os.environ else 1global_rank = int(os.environ['RANK']) if 'RANK' in os.environ else -1# dist.init_process_group("nccl")# rank = dist.get_rank()# print(f"Start running basic DDP example on rank {rank}.")rank = global_rank#print(rank)# TODO: handle distributed training logger# set the logger, tb_log_dir means tensorboard logdirlogger, final_output_dir, tb_log_dir = create_logger(cfg, cfg.LOG_DIR, 'train', rank=rank)if rank in [-1, 0]:logger.info(pprint.pformat(args))logger.info(cfg)writer_dict = {'writer': SummaryWriter(log_dir=tb_log_dir),'train_global_steps': 0,'valid_global_steps': 0,}else:writer_dict = None此代码与CUDA相关设置并使用函数构建模型get_net()。将用于训练的get_net()函数神经网络模型。接下来,它定义了用于训练的损失函数和优化器。和函数用于根据配置获得适当的损失函数和优化器get_loss()。get_optimizer()然后,它使用实现余弦学习率退火策略的lambda 函数设置学习率调度程序。开始纪元被设置为配置中指定的值。如果等级为 -1 或 0,则该函数会尝试从日志目录加载检查点模型。如果在配置中指定了预训练模型路径,则会加载预训练模型。model使用函数将检查点模型或预训练模型加载到对象中load_state_dict()。最后,它初始化用于存储最佳性能、最佳模型和最后一个纪元的变量。# cudnn related settingcudnn.benchmark = cfg.CUDNN.BENCHMARKtorch.backends.cudnn.deterministic = cfg.CUDNN.DETERMINISTICtorch.backends.cudnn.enabled = cfg.CUDNN.ENABLED# bulid up model# start_time = time.time()print("begin to bulid up model...")# DP modedevice = select_device(logger, batch_size=cfg.TRAIN.BATCH_SIZE_PER_GPU* len(cfg.GPUS)) if not cfg.DEBUG \else select_device(logger, 'cpu')# device_id = rank % torch.cuda.device_count()if args.local_rank != -1:assert torch.cuda.device_count() > args.local_ranktorch.cuda.set_device(args.local_rank)device = torch.device('cuda', args.local_rank)dist.init_process_group(backend='nccl', init_method='env://', world_size=world_size, rank=rank) # distributed backendprint("load model to device")model = get_net(cfg).to(device)# model = DDP(model, device_ids=[device_id])# print("load finished")#model = model.to(device)# print("finish build model")# define loss function (criterion) and optimizercriterion = get_loss(cfg, device=device)optimizer = get_optimizer(cfg, model)# load checkpoint modelbest_perf = 0.0best_model = Falselast_epoch = -1Encoder_para_idx = [str(i) for i in range(0, 17)]Det_Head_para_idx = [str(i) for i in range(17, 25)]Da_Seg_Head_para_idx = [str(i) for i in range(25, 34)]Ll_Seg_Head_para_idx = [str(i) for i in range(34,43)]lf = lambda x: ((1 + math.cos(x * math.pi / cfg.TRAIN.END_EPOCH)) / 2) * \(1 - cfg.TRAIN.LRF) + cfg.TRAIN.LRF # cosinelr_scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)begin_epoch = cfg.TRAIN.BEGIN_EPOCHif rank in [-1, 0]:checkpoint_file = os.path.join(os.path.join(cfg.LOG_DIR, cfg.DATASET.DATASET), 'checkpoint.pth')if os.path.exists(cfg.MODEL.PRETRAINED):logger.info("=> loading model '{}'".format(cfg.MODEL.PRETRAINED))checkpoint_state_dict = torch.load(cfg.MODEL.PRETRAINED) # begin_epoch = checkpoint['epoch']# # best_perf = checkpoint['perf']# last_epoch = checkpoint['epoch']# model.load_state_dict(checkpoint['state_dict'])# checkpoint1 = checkpoint['state_dict'] #分割类别变化了,会影响模型参数加载# -------begin看起来这段代码是用于训练神经网络模型的PyTorch 脚本的一部分。以下是代码作用的简要总结:该脚本为模型加载一个预训练的检查点,其中包括神经网络的权重和优化器状态。
它检查检查点中层的形状是否与当前模型中层的形状匹配。如果不匹配,它会从检查点中删除该层。
它将检查点加载到模型中,或者针对整个模型,或者针对模型的特定分支,具体取决于配置。
它根据配置冻结模型的某些层。
如果有多个 GPU 可用,它会使用DataParallel或DistributedDataParallel跨多个 GPU 并行训练。
值得注意的是,用于冻结层和加载模型不同分支的特定配置选项可能特定于正在训练的特定模型,因此如果没有额外的上下文,很难详细说明这段代码的作用。 checkpoint_state_dict = checkpoint_state_dict['model']print(checkpoint_state_dict)checkpoint_state_dict = checkpoint_state_dict.float().state_dict()model_state_dict = model.state_dict()for k in list(checkpoint_state_dict.keys()):if k in model_state_dict:shape_model = tuple(model_state_dict[k].shape)shape_checkpoint = tuple(checkpoint_state_dict[k].shape)if shape_model != shape_checkpoint:# incorrect_shapes.append((k, shape_checkpoint, shape_model))checkpoint_state_dict.pop(k)print(k, shape_model, shape_checkpoint)else:print(k, ' layer is missing!')model.load_state_dict(checkpoint_state_dict, strict=False)freeze = [f'model.{x}.' for x in range(15)] # layers to freeze for k, v in model.named_parameters(): v.requires_grad = True # train all layers if any(x in k for x in freeze): print(f'freezing {k}') v.requires_grad = False# optimizer.load_state_dict(checkpoint['optimizer'])logger.info(f"=> loaded checkpoint '{cfg.MODEL.PRETRAINED}'")#cfg.NEED_AUTOANCHOR = False #disable autoanchorif os.path.exists(cfg.MODEL.PRETRAINED_DET):logger.info("=> loading model weight in det branch from '{}'".format(cfg.MODEL.PRETRAINED))det_idx_range = [str(i) for i in range(0,25)]model_dict = model.state_dict()checkpoint_file = cfg.MODEL.PRETRAINED_DETcheckpoint = torch.load(checkpoint_file)begin_epoch = checkpoint['epoch']last_epoch = checkpoint['epoch']checkpoint_dict = {k: v for k, v in checkpoint['state_dict'].items() if k.split(".")[1] in det_idx_range}model_dict.update(checkpoint_dict)model.load_state_dict(model_dict)logger.info("=> loaded det branch checkpoint '{}' ".format(checkpoint_file))if cfg.AUTO_RESUME and os.path.exists(checkpoint_file):logger.info("=> loading checkpoint '{}'".format(checkpoint_file))checkpoint = torch.load(checkpoint_file)begin_epoch = checkpoint['epoch']# best_perf = checkpoint['perf']last_epoch = checkpoint['epoch']model.load_state_dict(checkpoint['state_dict'])# optimizer = get_optimizer(cfg, model)optimizer.load_state_dict(checkpoint['optimizer'])logger.info("=> loaded checkpoint '{}' (epoch {})".format(checkpoint_file, checkpoint['epoch']))#cfg.NEED_AUTOANCHOR = False #disable autoanchor# model = model.to(device)if cfg.TRAIN.SEG_ONLY: #Only train two segmentation branchslogger.info('freeze encoder and Det head...')for k, v in model.named_parameters():v.requires_grad = True # train all layersif k.split(".")[1] in Encoder_para_idx + Det_Head_para_idx:print('freezing %s' % k)v.requires_grad = Falseif cfg.TRAIN.DET_ONLY: #Only train detection branchlogger.info('freeze encoder and two Seg heads...')# print(model.named_parameters)for k, v in model.named_parameters():v.requires_grad = True # train all layersif k.split(".")[1] in Encoder_para_idx + Da_Seg_Head_para_idx + Ll_Seg_Head_para_idx:print('freezing %s' % k)v.requires_grad = Falseif cfg.TRAIN.ENC_SEG_ONLY: # Only train encoder and two segmentation branchslogger.info('freeze Det head...')for k, v in model.named_parameters():v.requires_grad = True # train all layers if k.split(".")[1] in Det_Head_para_idx:print('freezing %s' % k)v.requires_grad = Falseif cfg.TRAIN.ENC_DET_ONLY or cfg.TRAIN.DET_ONLY: # Only train encoder and detection branchslogger.info('freeze two Seg heads...')for k, v in model.named_parameters():v.requires_grad = True # train all layersif k.split(".")[1] in Da_Seg_Head_para_idx + Ll_Seg_Head_para_idx:print('freezing %s' % k)v.requires_grad = Falseif cfg.TRAIN.LANE_ONLY: logger.info('freeze encoder and Det head and Da_Seg heads...')# print(model.named_parameters)for k, v in model.named_parameters():v.requires_grad = True # train all layersif k.split(".")[1] in Encoder_para_idx + Da_Seg_Head_para_idx + Det_Head_para_idx:print('freezing %s' % k)v.requires_grad = Falseif cfg.TRAIN.DRIVABLE_ONLY:logger.info('freeze encoder and Det head and Ll_Seg heads...')# print(model.named_parameters)for k, v in model.named_parameters():v.requires_grad = True # train all layersif k.split(".")[1] in Encoder_para_idx + Ll_Seg_Head_para_idx + Det_Head_para_idx:print('freezing %s' % k)v.requires_grad = Falseif rank == -1 and torch.cuda.device_count() > 1:model = torch.nn.DataParallel(model, device_ids=cfg.GPUS)# model = torch.nn.DataParallel(model, device_ids=cfg.GPUS).cuda()# # DDP modeif rank != -1:model = DDP(model, device_ids=[args.local_rank], output_device=args.local_rank,find_unused_parameters=True)这是用于训练计算机视觉模型的代码片段。代码初始化模型参数,加载数
据,然后训练模型指定的 epoch 数。在训练期间,使用梯度下降优化模
型,并使用学习率调度程序调整学习率。该代码还以指定的频率在验证集上
评估模型,并保存性能最佳的模型检查点。训练过程的输出包括模型的性能
指标,例如准确性、IOU、精度、召回率和 mAP。它还将最终模型状态保存
到文件中。# assign model paramsmodel.gr = 1.0model.nc = 3 #13 #1# print('bulid model finished')print("begin to load data")# Data loadingnormalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])train_dataset = eval('dataset.' + cfg.DATASET.DATASET)(cfg=cfg,is_train=True,inputsize=cfg.MODEL.IMAGE_SIZE,transform=transforms.Compose([transforms.ToTensor(),normalize,]))train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset) if rank != -1 else Nonetrain_loader = DataLoaderX(train_dataset,batch_size=cfg.TRAIN.BATCH_SIZE_PER_GPU * len(cfg.GPUS),shuffle=(cfg.TRAIN.SHUFFLE & rank == -1),num_workers=cfg.WORKERS,sampler=train_sampler,pin_memory=cfg.PIN_MEMORY,collate_fn=dataset.AutoDriveDataset.collate_fn)num_batch = len(train_loader)if rank in [-1, 0]:valid_dataset = eval('dataset.' + cfg.DATASET.DATASET)(cfg=cfg,is_train=False,inputsize=cfg.MODEL.IMAGE_SIZE,transform=transforms.Compose([transforms.ToTensor(),normalize,]))valid_loader = DataLoaderX(valid_dataset,batch_size=cfg.TEST.BATCH_SIZE_PER_GPU * len(cfg.GPUS),shuffle=False,num_workers=cfg.WORKERS,pin_memory=cfg.PIN_MEMORY,collate_fn=dataset.AutoDriveDataset.collate_fn)print('load data finished')if rank in [-1, 0]:if cfg.NEED_AUTOANCHOR:logger.info("begin check anchors")run_anchor(logger,train_dataset, model=model, thr=cfg.TRAIN.ANCHOR_THRESHOLD, imgsz=min(cfg.MODEL.IMAGE_SIZE))else:logger.info("anchors loaded successfully")det = model.module.model[model.module.detector_index] if is_parallel(model) \else model.model[model.detector_index]logger.info(str(det.anchors))# trainingnum_warmup = max(round(cfg.TRAIN.WARMUP_EPOCHS * num_batch), 1000)scaler = amp.GradScaler(enabled=device.type != 'cpu')print('=> start training...')for epoch in range(begin_epoch+1, cfg.TRAIN.END_EPOCH+1):if rank != -1:train_loader.sampler.set_epoch(epoch)# train for one epochtrain(cfg, train_loader, model, criterion, optimizer, scaler,epoch, num_batch, num_warmup, writer_dict, logger, device, rank)lr_scheduler.step()# evaluate on validation setif (epoch % cfg.TRAIN.VAL_FREQ == 0 or epoch == cfg.TRAIN.END_EPOCH) and rank in [-1, 0]:# print('validate')da_segment_results,ll_segment_results,detect_results, total_loss,maps, times = validate(epoch,cfg, valid_loader, valid_dataset, model, criterion,final_output_dir, tb_log_dir, writer_dict,logger, device, rank)fi = fitness(np.array(detect_results).reshape(1, -1)) #目标检测评价指标msg = 'Epoch: [{0}] Loss({loss:.3f})\n' \'Driving area Segment: Acc({da_seg_acc:.3f}) IOU ({da_seg_iou:.3f}) mIOU({da_seg_miou:.3f})\n' \'Lane line Segment: Acc({ll_seg_acc:.3f}) IOU ({ll_seg_iou:.3f}) mIOU({ll_seg_miou:.3f})\n' \'Detect: P({p:.3f}) R({r:.3f}) mAP@0.5({map50:.3f}) mAP@0.5:0.95({map:.3f})\n'\'Time: inference({t_inf:.4f}s/frame) nms({t_nms:.4f}s/frame)'.format(epoch, loss=total_loss, da_seg_acc=da_segment_results[0],da_seg_iou=da_segment_results[1],da_seg_miou=da_segment_results[2],ll_seg_acc=ll_segment_results[0],ll_seg_iou=ll_segment_results[1],ll_seg_miou=ll_segment_results[2],p=detect_results[0],r=detect_results[1],map50=detect_results[2],map=detect_results[3],t_inf=times[0], t_nms=times[1])logger.info(msg)# if perf_indicator >= best_perf:# best_perf = perf_indicator# best_model = True# else:# best_model = False# save checkpoint model and best modelif rank in [-1, 0]:savepath = os.path.join(final_output_dir, f'epoch-{epoch}.pth')logger.info('=> saving checkpoint to {}'.format(savepath))save_checkpoint(epoch=epoch,name=cfg.MODEL.NAME,model=model,# 'best_state_dict': model.module.state_dict(),# 'perf': perf_indicator,optimizer=optimizer,output_dir=final_output_dir,filename=f'epoch-{epoch}.pth')save_checkpoint(epoch=epoch,name=cfg.MODEL.NAME,model=model,# 'best_state_dict': model.module.state_dict(),# 'perf': perf_indicator,optimizer=optimizer,output_dir=os.path.join(cfg.LOG_DIR, cfg.DATASET.DATASET),filename='checkpoint.pth')# save final modelif rank in [-1, 0]:final_model_state_file = os.path.join(final_output_dir, 'final_state.pth')logger.info('=> saving final model state to {}'.format(final_model_state_file))model_state = model.module.state_dict() if is_parallel(model) else model.state_dict()torch.save(model_state, final_model_state_file)writer_dict['writer'].close()else:dist.destroy_process_group()if __name__ == '__main__':main()
yolop训练输出
(base) root@notebook-rn-20230301115620425bi81-k2w3o-0:/home/shenlan08/lihanlin_shijian/YOLOP/tools# /home/shenlan08/miniconda3/bin/python /home/shenlan08/lihanlin_shijian/YOLOP/tools/train.py
=> creating runs/BddDataset/_2023-04-17-10-19
Namespace(modelDir='', logDir='runs/', dataDir='', prevModelDir='', sync_bn=False, local_rank=-1, conf_thres=0.001, iou_thres=0.6)
AUTO_RESUME: False
CUDNN:BENCHMARK: TrueDETERMINISTIC: FalseENABLED: True
DATASET:COLOR_RGB: FalseDATAROOT: /home/shenlan08/lihanlin_shijian/bdd100k/imagesDATASET: BddDatasetDATA_FORMAT: jpgFLIP: TrueHSV_H: 0.015HSV_S: 0.7HSV_V: 0.4#检测框LABELROOT: /home/shenlan08/lihanlin_shijian/bdd100k/det_annotations#ll这个是车道线LANEROOT: /home/shenlan08/lihanlin_shijian/bdd100k/ll_seg_annotations#掩码分割MASKROOT: /home/shenlan08/lihanlin_shijian/bdd100k/daORG_IMG_SIZE: [720, 1280]ROT_FACTOR: 10SCALE_FACTOR: 0.25SELECT_DATA: FalseSHEAR: 0.0TEST_SET: valTRAIN_SET: trainTRANSLATE: 0.1
DEBUG: False
GPUS: (0, 1)
LOG_DIR: runs/
LOSS:BOX_GAIN: 0.05CLS_GAIN: 0.5CLS_POS_WEIGHT: 1.0DA_SEG_GAIN: 0.2FL_GAMMA: 0.0LL_IOU_GAIN: 0.2LL_SEG_GAIN: 0.2LOSS_NAME: MULTI_HEAD_LAMBDA: NoneOBJ_GAIN: 1.0OBJ_POS_WEIGHT: 1.0SEG_POS_WEIGHT: 1.0
MODEL:EXTRA:HEADS_NAME: ['']IMAGE_SIZE: [640, 640]NAME: PRETRAINED: bes.ptPRETRAINED_DET: STRU_WITHSHARE: False
NEED_AUTOANCHOR: True
PIN_MEMORY: False
PRINT_FREQ: 20
TEST:BATCH_SIZE_PER_GPU: 24MODEL_FILE: NMS_CONF_THRESHOLD: 0.1NMS_IOU_THRESHOLD: 0.2PLOTS: TrueSAVE_JSON: FalseSAVE_TXT: False
TRAIN:ANCHOR_THRESHOLD: 4.0BATCH_SIZE_PER_GPU: 12BEGIN_EPOCH: 0DET_ONLY: FalseDRIVABLE_ONLY: FalseENC_DET_ONLY: FalseENC_SEG_ONLY: FalseEND_EPOCH: 240GAMMA1: 0.99GAMMA2: 0.0IOU_THRESHOLD: 0.2LANE_ONLY: FalseLR0: 0.001LRF: 0.2MOMENTUM: 0.937NESTEROV: TrueOPTIMIZER: adamPLOT: TrueSEG_ONLY: FalseSHUFFLE: TrueVAL_FREQ: 1WARMUP_BIASE_LR: 0.1WARMUP_EPOCHS: 3.0WARMUP_MOMENTUM: 0.8WD: 0.0005
WORKERS: 8
num_seg_class: 2
begin to bulid up model...
Using torch 1.13.1+cu117 CUDA:0 (GeForce RTX 2080 Ti, 11019MB)CUDA:1 (GeForce RTX 2080 Ti, 11019MB)CUDA:2 (GeForce RTX 2080 Ti, 11019MB)CUDA:3 (GeForce RTX 2080 Ti, 11019MB)load model to device
begin to load data
building database...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20000/20000 [00:25<00:00, 785.99it/s]
database build finish
building database...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3000/3000 [00:02<00:00, 1302.99it/s]
database build finish
load data finished
begin check anchors
WARNING: Extremely small objects found. 7434 of 246279 labels are < 3 pixels in width or height.
Running kmeans for 9 anchors on 246273 points...
thr=0.25: 0.9987 best possible recall, 4.53 anchors past thr
n=9, img_size=640, metric_all=0.309/0.729-mean/best, past_thr=0.488-mean: 5,15, 10,31, 11,74, 20,44, 34,74, 28,176, 57,115, 84,208, 124,345
Evolving anchors with Genetic Algorithm: fitness = 0.7592: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:35<00:00, 28.03it/s]
thr=0.25: 0.9992 best possible recall, 5.26 anchors past thr
n=9, img_size=640, metric_all=0.349/0.759-mean/best, past_thr=0.502-mean: 4,12, 7,18, 5,39, 11,29, 17,41, 24,63, 39,89, 70,146, 102,272
tensor([[[0.5445, 1.4860],[0.8506, 2.2737],[0.6714, 4.9291]],[[0.6855, 1.7993],[1.0550, 2.5667],[1.5176, 3.9344]],[[1.2133, 2.7916],[2.2017, 4.5758],[3.1775, 8.5005]]], device='cuda:0')
New anchors saved to model. Update model config to use these anchors in the future.
=> start training...
Traceback (most recent call last):File "/home/shenlan08/lihanlin_shijian/YOLOP/tools/train.py", line 436, in <module>main()File "/home/shenlan08/lihanlin_shijian/YOLOP/tools/train.py", line 363, in maintrain(cfg, train_loader, model, criterion, optimizer, scaler,File "/home/shenlan08/lihanlin_shijian/YOLOP/lib/core/function.py", line 77, in traintotal_loss, head_losses = criterion(outputs, target, shapes,model)File "/home/shenlan08/miniconda3/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1194, in _call_implreturn forward_call(*input, **kwargs)File "/home/shenlan08/lihanlin_shijian/YOLOP/lib/core/loss.py", line 50, in forwardtotal_loss, head_losses = self._forward_impl(head_fields, head_targets, shapes, model)File "/home/shenlan08/lihanlin_shijian/YOLOP/lib/core/loss.py", line 70, in _forward_impltcls, tbox, indices, anchors = build_targets(cfg, predictions[0], targets[0], model) # targetsFile "/home/shenlan08/lihanlin_shijian/YOLOP/lib/core/postprocess.py", line 74, in build_targetsindices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
RuntimeError: result type Float can't be cast to the desired output type long int
bd100k.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: yolo train data=coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/shenlan08/lihanlin_shijian/10k/images # dataset root dir
train: val # train images (relative to 'path') 128 images
val: val # val images (relative to 'path') 128 images
test: # test images (optional)# Classes
names:0: person1: bicycle2: car3: motorcycle4: airplane5: bus6: train7: truck8: boat9: traffic light10: fire hydrant11: stop sign12: parking meter13: bench14: bird15: cat16: dog17: horse18: sheep19: cow20: elephant21: bear22: zebra23: giraffe24: backpack25: umbrella26: handbag27: tie28: suitcase29: frisbee30: skis31: snowboard32: sports ball33: kite34: baseball bat35: baseball glove36: skateboard37: surfboard38: tennis racket39: bottle40: wine glass41: cup42: fork43: knife44: spoon45: bowl46: banana47: apple48: sandwich49: orange50: broccoli51: carrot52: hot dog53: pizza54: donut55: cake56: chair57: couch58: potted plant59: bed60: dining table61: toilet62: tv63: laptop64: mouse65: remote66: keyboard67: cell phone68: microwave69: oven70: toaster71: sink72: refrigerator73: book74: clock75: vase76: scissors77: teddy bear78: hair drier79: toothbrush先训练好yolov8,然后把v8的模型参数恢复到yolop上,冻结车道线以及可行驶区域这两个分割头之前的参数,然后训练这两个分割头
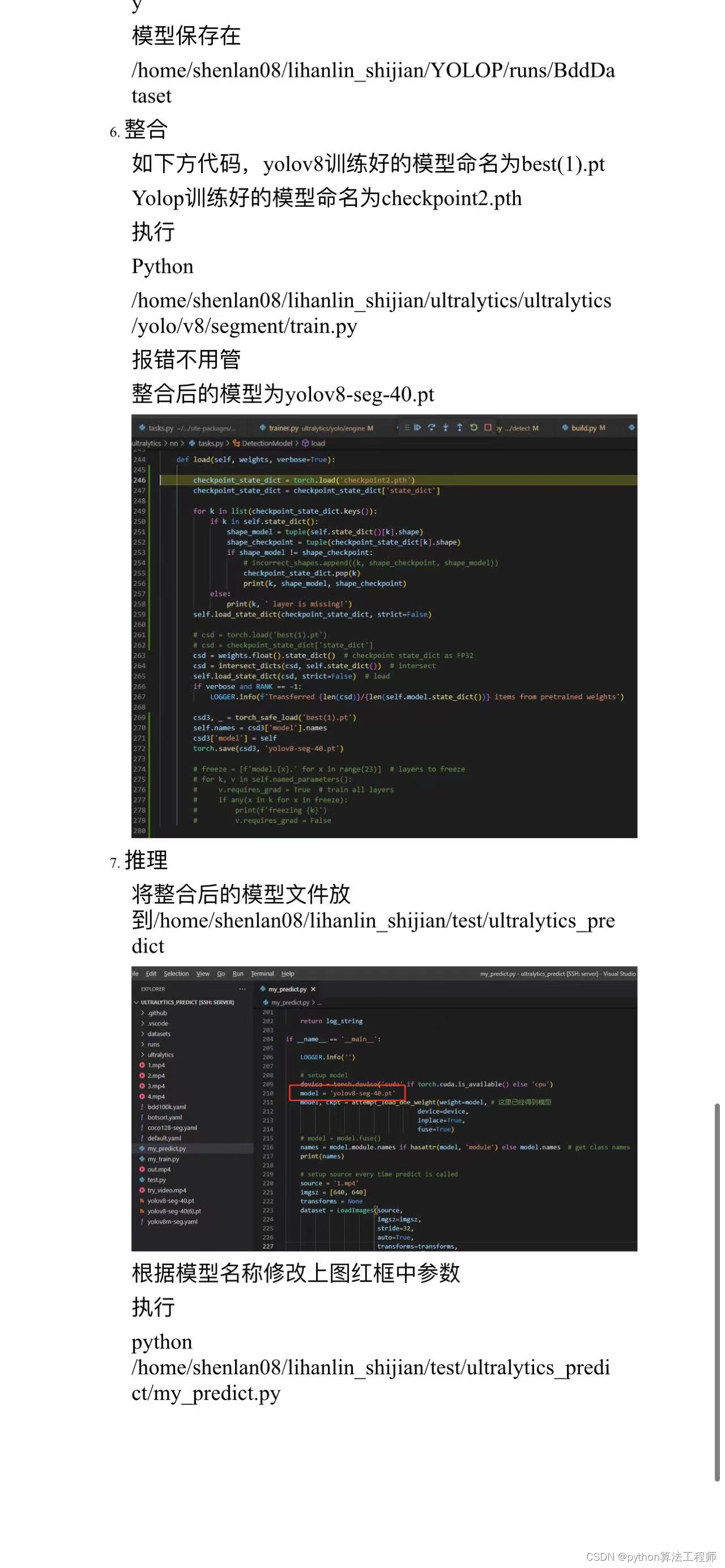
v8 vp整合训练代码
# Ultralytics YOLO 🚀, GPL-3.0 license
from copy import copyimport torch
import torch.nn.functional as F
import sys
sys.path.append("/home/shenlan08/lihanlin_shijian/last_task/ultralytics/")from ultralytics.nn.tasks import SegmentationModel
from ultralytics.yolo import v8
from ultralytics.yolo.utils import DEFAULT_CFG, RANK
from ultralytics.yolo.utils.ops import crop_mask, xyxy2xywh
from ultralytics.yolo.utils.plotting import plot_images, plot_results
from ultralytics.yolo.utils.tal import make_anchors
from ultralytics.yolo.utils.torch_utils import de_parallel
from ultralytics.yolo.v8.detect.train import Loss这段代码定义了一个名为 `SegmentationTrainer` 的类,它继承自 `v8.detect.DetectionTrainer` 类。`SegmentationTrainer` 类覆盖了一些方法,以便根据分割任务的需要进行调整。具体来说,这个类的实现如下:1. `__init__` 方法:该方法在类实例化时调用,用于初始化训练器。它首先调用父类 `DetectionTrainer` 的 `__init__` 方法并传递配置和覆盖参数。然后将任务类型设置为 `segment`。2. `get_model` 方法:该方法用于创建一个新的分割模型。它首先创建一个 `SegmentationModel` 的实例,并传递通道数和类别数。如果有指定的权重,则加载权重并返回模型。3. `get_validator` 方法:该方法用于创建一个新的分割验证器。它返回一个 `v8.segment.SegmentationValidator` 的实例,并传递测试数据集和保存目录参数。4. `criterion` 方法:该方法用于计算训练损失。它首先创建一个 `SegLoss` 的实例,并传递模型和重叠参数。然后将预测值和批次数据作为输入,通过 `SegLoss` 实例计算损失并返回。5. `plot_training_samples` 方法:该方法用于将训练数据集中的一批样本绘制成图像。它从批次数据中提取图像、掩码、类别、边界框和文件路径,并调用 `plot_images` 函数将它们绘制成图像并保存。6. `plot_metrics` 方法:该方法用于绘制训练和验证期间的度量指标。它调用 `plot_results` 函数,并传递 CSV 文件和 `segment=True` 参数,以便绘制分割任务的度量指标。# BaseTrainer python usage
class SegmentationTrainer(v8.detect.DetectionTrainer):def __init__(self, cfg=DEFAULT_CFG, overrides=None):if overrides is None:overrides = {}overrides['task'] = 'segment'super().__init__(cfg, overrides)def get_model(self, cfg=None, weights=None, verbose=True):model = SegmentationModel(cfg, ch=3, nc=self.data['nc'], verbose=verbose and RANK == -1)if weights:model.load(weights)return modeldef get_validator(self):self.loss_names = 'box_loss', 'seg_loss', 'cls_loss', 'dfl_loss'return v8.segment.SegmentationValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))def criterion(self, preds, batch):if not hasattr(self, 'compute_loss'):self.compute_loss = SegLoss(de_parallel(self.model), overlap=self.args.overlap_mask)return self.compute_loss(preds, batch)def plot_training_samples(self, batch, ni):images = batch['img']masks = batch['masks']cls = batch['cls'].squeeze(-1)bboxes = batch['bboxes']paths = batch['im_file']batch_idx = batch['batch_idx']plot_images(images, batch_idx, cls, bboxes, masks, paths=paths, fname=self.save_dir / f'train_batch{ni}.jpg')def plot_metrics(self):plot_results(file=self.csv, segment=True) # save results.png这是用于训练计算机视觉模型的分段损失函数的Python 代码。损失函数旨在计算执行对象检测和分割的模型训练期间的训练损失。损失函数接受模型的预测值和训练数据中相应的真实值。预测值包括预测掩码、边界框和类别分数。地面实况值包括类标签、边界框坐标和分割掩码。损失函数计算四种损失:框损失、类别损失、分割损失和变形损失。框损失衡量预测的边界框坐标与地面真值边界框坐标之间的差异。类损失衡量预测的类分数和真实类标签之间的差异。分割损失衡量预测的分割掩码和地面真值分割掩码之间的差异。最后,变形损失衡量预测蒙版和地面真值蒙版之间的差异应用变形场后。损失函数还包括一些额外的步骤,例如对分割蒙版进行下采样、将预测值分配给地面真值以及计算预测蒙版的面积。这些步骤对于确保损失函数准确且稳健是必要的。总的来说,这种损失函数是训练执行对象检测和分割的计算机视觉模型的关键组成部分。通过准确测量预测值和真实值之间的差异,损失函数帮助模型学习更好地识别和分割图像中的对象。
# Criterion class for computing training losses
class SegLoss(Loss):def __init__(self, model, overlap=True): # model must be de-paralleledsuper().__init__(model)self.nm = model.model[-1].nm # number of masksself.overlap = overlapdef __call__(self, preds, batch):loss = torch.zeros(4, device=self.device) # box, cls, dflfeats, pred_masks, proto = preds if len(preds) == 3 else preds[1]batch_size, _, mask_h, mask_w = proto.shape # batch size, number of masks, mask height, mask widthpred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split((self.reg_max * 4, self.nc), 1)# b, grids, ..pred_scores = pred_scores.permute(0, 2, 1).contiguous()pred_distri = pred_distri.permute(0, 2, 1).contiguous()pred_masks = pred_masks.permute(0, 2, 1).contiguous()dtype = pred_scores.dtypeimgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)# targetstry:batch_idx = batch['batch_idx'].view(-1, 1)targets = torch.cat((batch_idx, batch['cls'].view(-1, 1), batch['bboxes'].to(dtype)), 1)targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxymask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)except RuntimeError as e:raise TypeError('ERROR ❌ segment dataset incorrectly formatted or not a segment dataset.\n'"This error can occur when incorrectly training a 'segment' model on a 'detect' dataset, ""i.e. 'yolo train model=yolov8n-seg.pt data=coco128.yaml'.\nVerify your dataset is a ""correctly formatted 'segment' dataset using 'data=coco128-seg.yaml' "'as an example.\nSee https://docs.ultralytics.com/tasks/segment/ for help.') from e# pboxespred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)_, target_bboxes, target_scores, fg_mask, target_gt_idx = self.assigner(pred_scores.detach().sigmoid(), (pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),anchor_points * stride_tensor, gt_labels, gt_bboxes, mask_gt)target_scores_sum = max(target_scores.sum(), 1)# cls loss# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL wayloss[2] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCEif fg_mask.sum():# bbox lossloss[0], loss[3] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes / stride_tensor,target_scores, target_scores_sum, fg_mask)# masks lossmasks = batch['masks'].to(self.device).float()if tuple(masks.shape[-2:]) != (mask_h, mask_w): # downsamplemasks = F.interpolate(masks[None], (mask_h, mask_w), mode='nearest')[0]for i in range(batch_size):if fg_mask[i].sum():mask_idx = target_gt_idx[i][fg_mask[i]]if self.overlap:gt_mask = torch.where(masks[[i]] == (mask_idx + 1).view(-1, 1, 1), 1.0, 0.0)else:gt_mask = masks[batch_idx.view(-1) == i][mask_idx]xyxyn = target_bboxes[i][fg_mask[i]] / imgsz[[1, 0, 1, 0]]marea = xyxy2xywh(xyxyn)[:, 2:].prod(1)mxyxy = xyxyn * torch.tensor([mask_w, mask_h, mask_w, mask_h], device=self.device)loss[1] += self.single_mask_loss(gt_mask, pred_masks[i][fg_mask[i]], proto[i], mxyxy, marea) # seg# WARNING: lines below prevents Multi-GPU DDP 'unused gradient' PyTorch errors, do not removeelse:loss[1] += (proto * 0).sum() + (pred_masks * 0).sum() # inf sums may lead to nan loss# WARNING: lines below prevent Multi-GPU DDP 'unused gradient' PyTorch errors, do not removeelse:loss[1] += (proto * 0).sum() + (pred_masks * 0).sum() # inf sums may lead to nan lossloss[0] *= self.hyp.box # box gainloss[1] *= self.hyp.box / batch_size # seg gainloss[2] *= self.hyp.cls # cls gainloss[3] *= self.hyp.dfl # dfl gainreturn loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)def single_mask_loss(self, gt_mask, pred, proto, xyxy, area):# Mask loss for one imagepred_mask = (pred @ proto.view(self.nm, -1)).view(-1, *proto.shape[1:]) # (n, 32) @ (32,80,80) -> (n,80,80)loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction='none')return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).mean()这是一个Python 函数,用于训练用于对象检测和分割的计算机视觉模型。该函数将配置字典作为参数,它指定模型架构、要使用的数据集以及用于训练的设备。如果“use_python”标志设置为 True,该函数将使用Ultralytics YOLO 库进行训练。它创建一个具有指定模型架构的YOLO 对象,并调用其“train”方法,传入模型、数据和设备参数。这使用指定的设备在指定的数据集上训练YOLO 模型。如果“use_python”标志设置为 False,则该函数假定正在使用分段训练器的自定义实现。它使用指定的参数创建一个 SegmentationTrainer 对象并调用其“train”方法。这使用指定的设备在指定的数据集上训练分割模型。总的来说,此函数提供了一种方便的方法来训练用于对象检测和分割的计算机视觉模型,使用流行的库或自定义实现。
def train(cfg=DEFAULT_CFG, use_python=True):model = cfg.model or 'yolov8m-seg.pt'data = cfg.data or 'cityspaces.yaml' # or yolo.ClassificationDataset("mnist")device = cfg.device if cfg.device is not None else '2,3'args = dict(model=model, data=data, device=device)if use_python:from ultralytics import YOLOYOLO(model).train(**args)else:trainer = SegmentationTrainer(overrides=args)trainer.train()if __name__ == '__main__':train()cityspaces.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: yolo train data=coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/shenlan08/lihanlin_shijian/cityspaces/images # dataset root dir
train: train # train images (relative to 'path') 128 images
val: val # val images (relative to 'path') 128 images
test: # test images (optional)# Classes
names:#0: road0: sidewalk1: building2: wall3: fence4: pole5: traffic light6: traffic sign7: vegetation8: terrain9: sky10: person11: rider12: car13: truck14: bus15: train16: motorcycle17: bicyclev8推理代码
from ultralytics.nn.modules import Detect, Segment
from ultralytics.tracker.trackers.bot_sort import BOTSORT
from ultralytics.hub.utils import traces
from ultralytics.yolo.data.dataloaders.stream_loaders import LoadImages
from ultralytics.yolo.utils import ops, LOGGER, yaml_load
from ultralytics.yolo.utils.plotting import Annotator, colors
from ultralytics.yolo.engine.results import Boxes
import torch
import torch.nn as nn
from pathlib import Path
import numpy as np
import cv2
import os
os.environ['CUDA_VISIBLE_DEVICES']='2'
done_warmup = False
video_flag = False
vid_writer = None
这是一个Python 函数,它加载单个模型权重文件并返回加载的PyTorch 模型和检查点字典。该函数接受要加载的权重文件的路径、加载模型的设备、指示是否就地执行操作的标志以及指示是否融合层的标志。该函数首先使用PyTorch的“torch.load”方法加载检查点和权重文件。然后它从检查点加载模型,将其转换为 float32 并将其移动到指定的设备。如果“fuse”标志设置为 True 并且模型具有“fuse”方法,则该函数使用“fuse”方法融合模型中的层。该函数还对正在使用的 PyTorch 版本执行兼容性更新。它为某些模块设置“inplace”标志以确保与 torch 1.7.0 兼容,并向 nn.Upsample 添加“recompute_scale_factor”属性以与 torch 1.11.0 兼容。最后,该函数返回加载的模型和检查点字典。总的来说,此功能提供了一种方便的方法来加载单个模型权重文件并准备加载的模型以用于推理或进一步训练。
def attempt_load_one_weight(weight, device=None, inplace=True, fuse=False):# Loads a single model weightsckpt, weight = torch.load(weight, map_location='cpu'), weight # load ckptmodel = ckpt['model'].to(device).float() # FP32 model 显存增加if not hasattr(model, 'stride'):model.stride = torch.tensor([32.])model = model.fuse().eval() if fuse and hasattr(model, 'fuse') else model.eval() # model in eval mode# Module compatibility updatesfor m in model.modules():t = type(m)if t in (nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Segment):m.inplace = inplace # torch 1.7.0 compatibilityelif t is nn.Upsample and not hasattr(m, 'recompute_scale_factor'):m.recompute_scale_factor = None # torch 1.11.0 compatibility# Return model and ckptreturn model, ckpt #加载模型权重
这个Python 函数将numpy 数组转换为PyTorch 张量和该函数接受一个 numpy 数组和要将张量移动到的设备。它首先使用“isinstance”方法检查输入是否为 numpy 数组。如果它是一个 numpy 数组,该函数使用“torch.tensor”方法将其转换为 PyTorch 张量,并使用“to”方法将其移动到指定设备。如果输入不是 numpy 数组,则该函数仅按原样返回输入。总的来说,这个函数提供了一种将numpy 数组转换为PyTorch 张量并将它们移动到所需设备的便捷方法。
def from_numpy(x, device):"""Convert a numpy array to a tensor.Args:x (np.ndarray): The array to be converted.Returns:(torch.Tensor): The converted tensor"""return torch.tensor(x).to(device) if isinstance(x, np.ndarray) else x
这是一个Python 函数,它对PyTorch 模型执行预热过程以初始化其参数并在设备上分配内存。该函数接受要预热的模型、用于预热通道的设备以及格式为(batch_size、channels、height、width)的虚拟输入张量的形状。该函数使用指定的形状创建一个虚拟输入张量,数据类型设置为 float,设备设置为指定的设备。然后它使用前向传递将虚拟输入张量传递给模型并返回输出。如果输出是列表或元组,则该函数使用“from_numpy”函数将输出的第一个元素转换为PyTorch 张量,并将其移动到指定的设备。如果输出不是列表或元组,该函数只需使用“from_numpy”函数将其转换为 PyTorch 张量并将其移动到指定设备。总的来说,此函数提供了一种方便的方法来预热 PyTorch 模型并在运行推理或训练之前在设备上分配内存。
def warmup(model, device, imgsz=(1, 3, 640, 640)):"""Warm up the model by running one forward pass with a dummy input.Args:imgsz (tuple): The shape of the dummy input tensor in the format (batch_size, channels, height, width)Returns:(None): This method runs the forward pass and don't return any value"""if device.type != 'cpu':im = torch.empty(*imgsz, dtype=torch.float, device=device) # inputy = model(im)if isinstance(y, (list, tuple)):return from_numpy(y[0], device) if len(y) == 1 else [from_numpy(x, device) for x in y]else:return from_numpy(y, device)
这是一个Python 函数,用于预处理输入图像以用于PyTorch模型。该函数将输入图像作为numpy 数组和用于处理的设备。它首先使用“torch.from_numpy”方法将numpy 数组转换为PyTorch 张量,然后使用“to”方法将其移动到指定设备。然后该函数将张量转换为浮点数并将其除以 255 以将像素值缩放到 0.0 到 1.0 的范围内。这是计算机视觉模型的常见预处理步骤。最后,该函数返回预处理后的张量。总的来说,这个函数提供了一种方便的方法来预处理输入图像以用于PyTorch 模型。
def preprocess(img, device):img = torch.from_numpy(img).to(device)img = img.float() # uint8 to fp16/32img /= 255 # 0 - 255 to 0.0 - 1.0return img
这是一个Python 函数,可生成并保存分割结果图像以用于可视化目的。该函数将输入图像作为一个numpy 数组,将分割结果作为一个 numpy 数组,batch 的索引,epoch 编号,结果图像的保存目录以及几个可选参数。如果未提供“调色板”参数,则该函数会为分割类生成一个随机调色板。该函数首先检查“is_demo”参数是否设置为 True。如果是,该函数会为分割结果生成一个二值颜色掩码,并将其与输入图像组合以生成结果图像。如果不是,该函数使用调色板生成颜色分割图像并将其与输入图像组合。然后该函数将结果图像转换为BGR 格式,并使用加权平均将其与输入图像混合。最后,该函数将结果图像保存到指定目录,文件名基于批次索引和纪元号。总的来说,此功能提供了一种方便的方式来生成和保存分割结果图像,以便在训练或测试期间进行可视化。
def show_seg_result(img, result, index, epoch, save_dir=None, is_ll=False,palette=None,is_demo=False,is_gt=False):if palette is None:palette = np.random.randint(0, 255, size=(3, 3))palette[0] = [0, 0, 0]palette[1] = [0, 255, 0]palette[2] = [255, 0, 0]palette = np.array(palette)assert palette.shape[0] == 3 # len(classes)assert palette.shape[1] == 3assert len(palette.shape) == 2if not is_demo:color_seg = np.zeros((result.shape[0], result.shape[1], 3), dtype=np.uint8)for label, color in enumerate(palette):color_seg[result == label, :] = colorelse:color_area = np.zeros((result[0].shape[0], result[0].shape[1], 3), dtype=np.uint8)color_area[result[0] == 1] = [0, 255, 0]color_area[result[1] ==1] = [255, 0, 0]color_seg = color_area# convert to BGRcolor_seg = color_seg[..., ::-1]# print(color_seg.shape)color_mask = np.mean(color_seg, 2)img[color_mask != 0] = img[color_mask != 0] * 0.5 + color_seg[color_mask != 0] * 0.5# img = img * 0.5 + color_seg * 0.5img = img.astype(np.uint8)# img = cv2.resize(img, (1280,720), interpolation=cv2.INTER_LINEAR)if not is_demo:if not is_gt:if not is_ll:cv2.imwrite(save_dir+"/batch_{}_{}_da_segresult.png".format(epoch,index), img)else:cv2.imwrite(save_dir+"/batch_{}_{}_ll_segresult.png".format(epoch,index), img)else:if not is_ll:cv2.imwrite(save_dir+"/batch_{}_{}_da_seg_gt.png".format(epoch,index), img)else:cv2.imwrite(save_dir+"/batch_{}_{}_ll_seg_gt.png".format(epoch,index), img) return img
这是一个Python 函数,它通过执行非最大抑制并将预测的边界框缩放到原始图像大小来对对象检测预测进行后处理。该函数将对象检测预测作为PyTorch 张量列表、输入图像作为numpy 数组、原始图像作为 numpy 数组、输入图像的路径和类名称。该函数首先使用“ops.non_max_suppression”方法对预测框执行非最大抑制。然后,它使用“ops.process_mask”方法处理预测的掩码,并使用“ops.scale_boxes”方法缩放预测的框。该函数创建一个结果列表,其中每个结果都是一个元组,其中包含单个图像的预测掩码和框。该函数将每个结果附加到结果列表并返回最终列表。总体而言,此功能提供了一种对对象检测预测进行后处理并获得最终预测掩码和边界框的便捷方法。
def postprocess(preds, img, orig_img, path, names):# TODO: filter by classesp = ops.non_max_suppression(prediction=preds[0][0],conf_thres=0.1,iou_thres=0.7,agnostic=False,max_det=300,nc=len(names),classes=None )results = []proto = preds[0][1][-1] if len(preds[0][1]) == 3 else preds[0][1] # second output is len 3 if pt, but only 1 if exportedfor i, pred in enumerate(p):orig_img = orig_img[i] if isinstance(orig_img, list) else orig_imgshape = orig_img.shapeimg_path = path[i] if isinstance(path, list) else pathif not len(pred): # save empty boxes# results.append(Results(orig_img=orig_img, path=img_path, names=names, boxes=pred[:, :6]))continuemasks = ops.process_mask(proto[i], pred[:, 6:], pred[:, :4], img.shape[2:], upsample=True) # HWCpred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], shape).round()boxes = pred[:, :6].detach()boxes = Boxes(boxes, orig_img.shape[:2]) if boxes is not None else None # native size boxesresults.append(masks)results.append(boxes)return results这是一个Python 函数,可将对象检测结果写入图像和/或视频文件。该函数接受当前图像的索引、对象检测结果列表、作为PyTorch 张量的输入图像、到目前为止处理的图像数量、数据集、类名称和视频捕获对象。它首先扩展输入图像张量以包含批处理维度并将日志字符串设置为空字符串。该函数然后从结果中获取预测的蒙版和框,并创建一个Annotator 对象以在图像上绘制蒙版和框。该函数遍历检测到的类别并计算每个类别的检测次数。然后,该函数使用 Annotator 对象将蒙版和框添加到图像,并将生成的图像写入视频编写器对象(如果指定了一个)。最后,该函数返回一个日志字符串,其中包含有关每个类的检测信息以及目前已处理的图像数量。总体而言,此功能提供了一种在推理过程中可视化和保存对象检测结果的便捷方式。def write_results(idx, results, batch, seen, dataset, names, vid_cap):p, im, im0 = batchlog_string = ''if len(im.shape) == 3:im = im[None] # expand for batch dimseen += 1# txt_path = f'_{frame}'log_string += '%gx%g ' % im.shape[2:] # print stringannotator = Annotator(im0, line_width=3, example=str(names))result = resultsif len(result) == 0:return f'{log_string}(no detections), 'det, masks = result[1], result[0] # getting tensors TODO: mask mask,box inherit for tensor# Print resultsfor c in det.cls.unique():n = (det.cls == c).sum() # detections per classlog_string += f"{n} {names[int(c)]}{'s' * (n > 1)}, "# Mask plottingim_gpu = im[idx]annotator.masks(masks=masks, colors=[colors(x, True) for x in det.cls], im_gpu=im_gpu)# Write resultsfor j, d in enumerate(reversed(det)):cls, conf = d.cls.squeeze(), d.conf.squeeze()# Add bbox to imagec = int(cls) # integer classname = f'id:{int(d.id.item())} {names[c]}' if d.id is not None else names[c]label = f'{name} {conf:.2f}'annotator.box_label(d.xyxy.squeeze(), label, color=colors(c, True))# save_predsglobal video_flag, vid_writerim0 = annotator.result()if vid_cap and not video_flag: # videofps = int(vid_cap.get(cv2.CAP_PROP_FPS)) # integer required, floats produce error in MP4 codecw = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))vid_writer = cv2.VideoWriter("out.mp4", cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))video_flag = Truevid_writer.write(im0)return log_string
这是对视频执行对象检测和跟踪的Python 脚本的主要功能。该脚本首先设置模型并从文件加载其权重。它还会设置输入源(在本例中为视频文件),并初始化数据集加载器以遍历视频帧。然后,脚本通过运行示例图像来预热模型。接下来,脚本使用配置文件初始化对象跟踪器,并在每一帧中检测到的对象上运行它。然后脚本通过模型运行输入图像并对输出执行后处理以获得检测到的对象的边界框和类标签。然后,脚本使用检测到的对象的边界框更新跟踪器,并将相应的类标签分配给被跟踪的对象。然后该脚本可视化并保存视频每一帧的检测和跟踪结果。最后,脚本释放视频编写器对象并退出。总的来说,这个脚本提供了一个完整的视频对象检测和跟踪管道,并且可以很容易地适应不同的模型和输入源。
if __name__ == '__main__':LOGGER.info('')# setup modeldevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = 'yolov8-seg-40.pt'model, ckpt = attempt_load_one_weight(weight=model, # 这里已经得到模型device=device,inplace=True,fuse=True)# model = model.fuse()names = model.module.names if hasattr(model, 'module') else model.names # get class names# print(names)#这个是模型# setup source every time predict is calledsource = '1.mp4'imgsz = [640, 640]transforms = Nonedataset = LoadImages(source,imgsz=imgsz,stride=32,auto=True,transforms=transforms,vid_stride=1)# warmup modelif not done_warmup:warmup(model, device, imgsz=(1, 3, *imgsz))done_warmup = Trueseen, windows, dt, batch = 0, [], (ops.Profile(), ops.Profile(), ops.Profile()), None# init tracktracker = 'botsort.yaml'cfg = yaml_load(tracker)tracker = BOTSORT(args=cfg, frame_rate=30)traces(traces_sample_rate=1.0)# predict_startfor batch in dataset:path, im, im0s, vid_cap, s = batchim_copy = im.transpose(1, 2, 0)# preprocesswith dt[0]:im = preprocess(im, device)if len(im.shape) == 3:im = im[None] # expand for batch dim# inferencewith dt[1]:preds = model(im)# da and ll_, da_seg_out,ll_seg_out = preds_, da_seg_mask = torch.max(da_seg_out, 1)da_seg_mask = da_seg_mask.int().squeeze().cpu().numpy()_, ll_seg_mask = torch.max(ll_seg_out, 1)ll_seg_mask = ll_seg_mask.int().squeeze().cpu().numpy()im = show_seg_result(im_copy, (da_seg_mask, ll_seg_mask), _, _, is_demo=True)im = im.transpose(2, 0, 1)im = preprocess(im, device)if len(im.shape) == 3:im = im[None] # expand for batch dim# postprocesswith dt[2]:results = postprocess(preds, im, im0s, path, names)# do trackim0s_track = im0sdet = results[1].cpu().numpy()if len(det) == 0:continuetracks = tracker.update(det, im0s_track)if len(tracks) == 0:continueboxes=torch.as_tensor(tracks[:, :-1])if boxes is not None:results[1] = Boxes(boxes=boxes, orig_shape=im0s_track.shape[:2])if results[0] is not None:idx = tracks[:, -1].tolist()results[0] = results[0][idx]# visualize, save, write resultsn = len(im)for i in range(n):results[i].speed = {'preprocess': dt[0].dt * 1E3 / n,'inference': dt[1].dt * 1E3 / n,'postprocess': dt[2].dt * 1E3 / n}p, im0 = (path, im0s.copy())p = Path(p)# saves += write_results(i, results, (p, im, im0), seen, dataset, names, vid_cap)LOGGER.info(f'{s}{dt[1].dt * 1E3:.1f}ms')vid_writer.release() # release final video writervideo 1/1 (2627/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 6 cars, 1 bus, 19.4ms video 1/1 (2628/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.2ms video 1/1 (2629/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 bus, 19.1ms video 1/1 (2630/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.2ms video 1/1 (2631/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.0ms video 1/1 (2632/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.2ms video 1/1 (2633/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.1ms video 1/1 (2634/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.2ms video 1/1 (2635/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.3ms video 1/1 (2636/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 6 cars, 19.3ms video 1/1 (2637/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 6 cars, 19.1ms video 1/1 (2638/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 6 cars, 19.3ms video 1/1 (2639/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.1ms video 1/1 (2640/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.4ms video 1/1 (2641/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.6ms video 1/1 (2642/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.3ms video 1/1 (2643/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.9ms video 1/1 (2644/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.6ms video 1/1 (2645/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.3ms video 1/1 (2646/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.1ms video 1/1 (2647/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.2ms video 1/1 (2648/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.0ms video 1/1 (2649/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.1ms video 1/1 (2650/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
384x640 5 cars, 1 truck, 19.1ms video 1/1 (2651/3553)
/home/shenlan08/lihanlin_shijian/test/ultralytics_predict/4.mp4:
SegmentationModel(
(model): Sequential(
(0): Conv(
(conv): Conv2d(3, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(48, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): C2f(
(cv1): Conv(
(conv): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(48, 48, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(48, 48, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(48, 48, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(48, 48, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
)
)
(3): Conv(
(conv): Conv2d(96, 192, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(4): C2f(
(cv1): Conv(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(576, 192, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(3): Bottleneck(
(cv1): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
)
)
(5): Conv(
(conv): Conv2d(192, 384, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(6): C2f(
(cv1): Conv(
(conv): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(1152, 384, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(3): Bottleneck(
(cv1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
)
)
(7): Conv(
(conv): Conv2d(384, 576, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(8): C2f(
(cv1): Conv(
(conv): Conv2d(576, 576, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(1152, 576, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
)
)
(9): SPPF(
(cv1): Conv(
(conv): Conv2d(576, 288, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(1152, 576, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
)
(10): Upsample(scale_factor=2.0, mode=nearest)
(11): Concat()
(12): C2f(
(cv1): Conv(
(conv): Conv2d(960, 384, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(768, 384, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
)
)
(13): Upsample(scale_factor=2.0, mode=nearest)
(14): Concat()
(15): C2f(
(cv1): Conv(
(conv): Conv2d(576, 192, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(384, 192, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
)
)
(16): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(17): Concat()
(18): C2f(
(cv1): Conv(
(conv): Conv2d(576, 384, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(768, 384, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
)
)
(19): Conv(
(conv): Conv2d(384, 384, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(20): Concat()
(21): C2f(
(cv1): Conv(
(conv): Conv2d(960, 576, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(1152, 576, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(288, 288, kernel_size=(3, 3), stride=(1, 1), padding=[1, 1])
(act): SiLU(inplace=True)
)
)
)
)
(22): Segment(
(cv2): ModuleList(
(0): Sequential(
(0): Conv(
(conv): Conv2d(192, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(1): Sequential(
(0): Conv(
(conv): Conv2d(384, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(2): Sequential(
(0): Conv(
(conv): Conv2d(576, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
)
(cv3): ModuleList(
(0): Sequential(
(0): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(192, 80, kernel_size=(1, 1), stride=(1, 1))
)
(1): Sequential(
(0): Conv(
(conv): Conv2d(384, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(192, 80, kernel_size=(1, 1), stride=(1, 1))
)
(2): Sequential(
(0): Conv(
(conv): Conv2d(576, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(192, 80, kernel_size=(1, 1), stride=(1, 1))
)
)
(dfl): DFL(
(conv): Conv2d(16, 1, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
(proto): Proto(
(cv1): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(upsample): ConvTranspose2d(192, 192, kernel_size=(2, 2), stride=(2, 2))
(cv2): Conv(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv3): Conv(
(conv): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
)
(cv4): ModuleList(
(0): Sequential(
(0): Conv(
(conv): Conv2d(192, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(48, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(48, 32, kernel_size=(1, 1), stride=(1, 1))
)
(1): Sequential(
(0): Conv(
(conv): Conv2d(384, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(48, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(48, 32, kernel_size=(1, 1), stride=(1, 1))
)
(2): Sequential(
(0): Conv(
(conv): Conv2d(576, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(48, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(48, 32, kernel_size=(1, 1), stride=(1, 1))
)
)
)
(23): Conv(
(conv): Conv2d(576, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(24): Upsample(scale_factor=2.0, mode=nearest)
(25): C3(
(cv1): Conv(
(conv): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv3): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(26): Conv(
(conv): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(27): Upsample(scale_factor=2.0, mode=nearest)
(28): Conv(
(conv): Conv2d(32, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(29): C3(
(cv1): Conv(
(conv): Conv2d(16, 4, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(16, 4, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv3): Conv(
(conv): Conv2d(8, 8, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(4, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(4, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(30): Upsample(scale_factor=2.0, mode=nearest)
(31): Conv(
(conv): Conv2d(8, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(32): Conv(
(conv): Conv2d(576, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(33): Upsample(scale_factor=2.0, mode=nearest)
(34): C3(
(cv1): Conv(
(conv): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv3): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(35): Conv(
(conv): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(36): Upsample(scale_factor=2.0, mode=nearest)
(37): Conv(
(conv): Conv2d(32, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(38): C3(
(cv1): Conv(
(conv): Conv2d(16, 4, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(16, 4, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv3): Conv(
(conv): Conv2d(8, 8, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(4, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(4, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(39): Upsample(scale_factor=2.0, mode=nearest)
(40): Conv(
(conv): Conv2d(8, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
模型训练及导出onnx
包含18个类和车道线与可行驶区域的数据集,只是用yolov8做分割
车道线膨胀
怎么将两个数据集进行合并
将两个数据集合并的具体方法取决于数据集的格式和内容。以下是一些常用的数据集合并方法:
-
数据集拼接:如果两个数据集的内容和格式相同,可以通过将它们拼接在一起来合并数据集。这种方法适用于数据集的大小和结构相似的情况。例如,如果两个数据集都是由图像和其对应的标签组成,可以将它们拼接在一起,形成一个更大的数据集。
-
数据集扩充:如果两个数据集的内容和格式不同,可以将它们合并后进行扩充。这种方法适用于需要增加数据集类别或样本数量的情况。例如,如果一个数据集只包含人和车辆的图像,另一个数据集包含人、车辆和动物的图像,可以将它们合并后,通过数据增强和样本复制等方法扩充数据集,以增加模型的泛化能力。
-
数据集融合:如果两个数据集的内容和格式相似,但存在重叠的部分,可以将它们融合成一个数据集。这种方法适用于需要减少标注重复度和提高数据集质量的情况。例如,两个数据集都包含人和车辆的图像,但它们的标注存在差异,可以通过将它们融合成一个数据集,然后对标注进行验证和修正,以提高数据集的准确性。
需要注意的是,在进行数据集合并时,应注意保持数据集的平衡性和多样性,避免数据集中存在类别偏斜和重复样本,以提高模型的泛化能力和鲁棒性。同时,应根据具体的任务需求和数据集特点,选择合适的数据集合并方法,并进行充分的数据预处理和后处理,以确保合并后的数据集质量和效果。
import json
import osdef bdd2yolo5(categorys,jsonFile,writepath):strs=""f = open(jsonFile)info = json.load(f)#print(len(info))#print(info["name"])write = open(writepath + "%s.txt" % info["name"], 'w')for obj in info["frames"]:#print(obj["objects"])for objects in obj["objects"]:#print(objects)if objects["category"] in categorys:dw = 1.0 / 1280dh = 1.0 / 720strs += str(categorys.index(objects["category"]))strs += " "strs += str(((objects["box2d"]["x1"] + objects["box2d"]["x2"]) / 2.0) * dw)[0:8]strs += " "strs += str(((objects["box2d"]["y1"] + objects["box2d"]["y2"]) / 2.0) * dh)[0:8]strs += " "strs += str(((objects["box2d"]["x2"] - objects["box2d"]["x1"])) * dw)[0:8]strs += " "strs += str(((objects["box2d"]["y2"] - objects["box2d"]["y1"])) * dh)[0:8]strs += "\n"write.writelines(strs)write.close()print("%s has been dealt!" % info["name"])if __name__ == "__main__":####################args#####################categorys = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck'] # 自己需要从BDD数据集里提取的目标类别readpath = "/home/shenlan08/lihanlin_shijian/bdd100k/det_annotations/train/" # BDD数据集标签读取路径,这里需要分两次手动去修改train、val的地址writepath = "/home/shenlan08/lihanlin_shijian/bdd100k/labels/train/" # BDD数据集转换后的标签保存路径fileList = os.listdir(readpath)#print(fileList)for file in fileList:print(file)filepath = readpath + filebdd2yolo5(categorys,filepath,writepath)这个错误通常是由于CUDA显存不足导致的。当GPU尝试分配内存时,如果内存不足,则会引发此错误。
以下是一些可能导致此错误的原因和解决方法:
-
内存不足:确保你的GPU有足够的空闲内存来运行你的程序。如果你运行的任务需要大量的显存,可以尝试减少批次大小、减少模型大小或使用更小的模型来减少显存占用。
-
程序错误:如果你的程序存在错误,可能会导致内存泄漏或者显存占用过高。确保你的程序没有错误,或者尝试使用更简单的程序来排除问题。
-
CUDA驱动程序问题:可能是因为CUDA驱动程序版本不兼容或存在问题。尝试更新或降级CUDA驱动程序版本,或者重新安装CUDA驱动程序以解决问题。
-
GPU硬件问题:如果你的GPU存在硬件问题,也可能导致此错误。尝试使用其他GPU或者联系GPU制造商进行修理或更换。
总之,这个错误通常是由于显存不足引起的。如果你的程序需要大量的显存,请确保你的GPU有足够的空闲内存来运行程序。如果问题仍然存在,可以尝试使用其他GPU或者联系GPU制造商进行修理或更换。
def train(cfg=DEFAULT_CFG, use_python=False):model = cfg.model or 'yolov8m-seg.pt'data = cfg.data or 'cityspaces.yaml' # or yolo.ClassificationDataset("mnist")device = cfg.device if cfg.device is not None else '0,1,2'print(device)Ultralytics YOLOv8.0.61 🚀 Python-3.8.5 torch-1.8.0+cu111 CUDA:0 (GeForce RTX 2080 Ti, 11019MiB)CUDA:1 (GeForce RTX 2080 Ti, 11019MiB)CUDA:2 (GeForce RTX 2080 Ti, 11019MiB)
Running DDP command ['/root/miniconda3/bin/python', '-m', 'torch.distributed.launch', '--nproc_per_node', '3', '--master_port', '37427', '/home/shenlan08/lihanlin_shijian/last_task/ultralytics/ultralytics/yolo/v8/segment/train.py', 'task=segment', 'mode=train', 'model=yolov8m-seg.pt', 'data=cityspaces.yaml', 'epochs=100', 'patience=50', 'batch=6', 'imgsz=640', 'save=True', 'save_period=-1', 'cache=False', 'device=0,1,2', 'workers=8', 'project=None', 'name=None', 'exist_ok=False', 'pretrained=False', 'optimizer=SGD', 'verbose=True', 'seed=0', 'deterministic=True', 'single_cls=False', 'image_weights=False', 'rect=False', 'cos_lr=False', 'close_mosaic=10', 'resume=False', 'amp=True', 'overlap_mask=True', 'mask_ratio=4', 'dropout=0.0', 'val=True', 'split=val', 'save_json=False', 'save_hybrid=False', 'conf=None', 'iou=0.7', 'max_det=300', 'half=False', 'dnn=False', 'plots=True', 'source=None', 'show=False', 'save_txt=False', 'save_conf=False', 'save_crop=False', 'hide_labels=False', 'hide_conf=False', 'vid_stride=1', 'line_thickness=3', 'visualize=False', 'augment=False', 'agnostic_nms=False', 'classes=None', 'retina_masks=False', 'boxes=True', 'format=torchscript', 'keras=False', 'optimize=False', 'int8=False', 'dynamic=False', 'simplify=False', 'opset=None', 'workspace=4', 'nms=False', 'lr0=0.01', 'lrf=0.01', 'momentum=0.937', 'weight_decay=0.0005', 'warmup_epochs=3.0', 'warmup_momentum=0.8', 'warmup_bias_lr=0.1', 'box=7.5', 'cls=0.5', 'dfl=1.5', 'fl_gamma=0.0', 'label_smoothing=0.0', 'nbs=64', 'hsv_h=0.015', 'hsv_s=0.7', 'hsv_v=0.4', 'degrees=0.0', 'translate=0.1', 'scale=0.5', 'shear=0.0', 'perspective=0.0', 'flipud=0.0', 'fliplr=0.5', 'mosaic=1.0', 'mixup=0.0', 'copy_paste=0.0', 'cfg=None', 'v5loader=False', 'tracker=botsort.yaml']
*****************************************
Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
*****************************************
0,1,2
0,1,2
0,1,2
DDP settings: RANK 0, WORLD_SIZE 3, DEVICE cuda:0
TensorBoard: Start with 'tensorboard --logdir /home/shenlan08/lihanlin_shijian/last_task/ultralytics/runs/segment/train14', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=19
Transferred 531/537 items from pretrained weights
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed ✅
数据整理一个把发群里 之后你看看 咋能把模型先跑起来
yolo8
的 那个跑过了之前
但是好像没加路的
把路的标签加里面在训练一下子
最后的那个的地方改一下估计就行
完了评估指标你在看一眼 看看那个代码细节是不是这几个

分割的
好的
你自己做的太多的话 你看看 咋让他们配合一下
论文现在没做这个图像的
做的是轨迹的
图像这个创新的话比较难 也不是比较难 因为实验不是很好做
什么是PA?
PA和mIOU都是用于评估语义分割模型性能的指标,但它们分别从不同的角度对模型的性能进行评价。
PA是Pixel Accuracy的缩写,是计算所有像素中分类正确的像素占总像素数的比例。它只关注像素级别的准确性,因此无法区分不同类别之间的差异。具体计算方法如下:
P A = T P + T N T P + T N + F P + F N PA = \frac{TP + TN}{TP + TN + FP + FN} PA=TP+TN+FP+FNTP+TN
其中,TP表示真正例的像素数,TN表示真负例的像素数,FP表示假正例的像素数,FN表示假负例的像素数。
什么是MIOU?
mIOU是Mean Intersection over Union的缩写,是计算所有类别的平均Intersection over Union的值。Intersection over Union是判断模型分割结果与真实结果的重合程度的指标,它计算预测结果和真实结果相交部分与相并部分之间的比例。mIOU综合了所有类别的IoU值,因此能够更全面地评估模型的性能。具体计算方法如下:
m I O U = 1 n ∑ i = 1 n T P i T P i + F P i + F N i mIOU = \frac{1}{n}\sum_{i=1}^{n}\frac{TP_i}{TP_i + FP_i + FN_i} mIOU=n1i=1∑nTPi+FPi+FNiTPi
其中,n表示类别总数,TP_i表示第i个类别的真正例像素数,FP_i表示第i个类别的假正例像素数,FN_i表示第i个类别的假负例像素数。
综上所述,PA和mIOU都是用于评估语义分割模型性能的指标,但前者关注的是像素级别的准确性,后者则更关注不同类别之间的差异。在实际应用中,需要根据任务需求和场景特点选择合适的评价指标。
语义分割的指标计算
https://blog.csdn.net/sinat_29047129/article/details/103642140
yolov8数据集处理
Cityscapes 数据集:Cityscapes 数据集是一个广泛使用的自动驾驶数据集,包含来自城市道路、广场和建筑物等多种场景的高分辨率图像。该数据集包含标注的道路、车辆、行人和建筑物等对象的标签,可以用于训练和测试YOLO目标检测算法。
ApolloScape 数据集:ApolloScape 数据集由百度公司提供,包含高分辨率的自动驾驶图像和激光雷达数据。该数据集包含多种场景,包括城市道路、高速公路和停车场等。该数据集还包含标注的车辆、行人、自行车和交通灯等对象的标签,可以用于训练和测试YOLO目标检测算法。
Mapillary Vistas 数据集:Mapillary Vistas 数据集是一个由 Mapillary 公司提供的自动驾驶数据集,包含来自全球各地的高分辨率图像。该数据集包含多种场景,包括城市街道、公园和农村地区等。该数据集还包含标注的道路、车辆、行人和建筑物等对象的标签,可以用于训练和测试YOLO目标检测算法。
https://blog.csdn.net/ruleng8662/article/details/129522449
cvat等工具标注的数据集,标签一般都是json格式的。
而yolo训练的得标签是txt格式,所以不兼容
需要将json转为yolo,当如v8本身也有数据处理得工具