目录
引言
一、XPath简介
二、XPath常用规则
三、实例讲解
四、节点的选取
4.1 所有节点的选取
4.2 子节点的选取
4.3 父节点选取
五、属性匹配获取及文本获取
5.1 属性匹配
5.2 文本获取
5.3 属性获取
5.4 属性多值匹配
5.5 多属性匹配
六、按序选择
七、节点轴选择
八、总结
引言
在上一节中,我们创建了一个基础的爬虫程序,并使用正则表达式来提取页面信息。然而,这种方法存在一定的局限性:如果正则表达式的编写不准确,可能会导致无法正确匹配所需内容。因此,在实际应用中,使用正则表达式进行页面信息提取并不是最方便的选择。
网页中的节点通常具有id、class等属性,且节点之间存在着层次关系。为了更高效地解析页面并定位特定节点,我们可以利用XPath或CSS选择器来进行操作。通过这些工具,我们可以轻松地从HTML文档中提取出所需的节点及其相关信息。
Python提供了多种强大的解析库,如lxml、BeautifulSoup和pyquery等,它们能够帮助我们更加便捷地处理HTML数据。借助这些库,我们无需担心复杂的正则表达式编写问题,同时还能显著提高解析效率。接下来,我们将重点探讨如何在Python中使用lxml库实现XPath功能。
XPath(XML Path Language)是一种专门用于在XML文档中查找信息的语言。尽管它最初是为XML设计的,但后来发现其同样适用于HTML文档的搜索需求。因此,在开发网络爬虫时,我们可以充分利用XPath来抽取网页上的相关数据。下面将详细介绍XPath的基本用法。
一、XPath简介
XPath以其简洁明了的路径选择表达式著称,并提供超过100个内置函数,涵盖了字符串、数值、时间等多种类型的匹配与处理能力。几乎任何想要定位的节点都可以通过XPath进行选择。
自1999年11月16日成为W3C标准以来,XPath被广泛应用于XSLT、XPointer以及其他XML解析软件的设计中。若想深入了解其详细规范及相关文档,请访问官方网址:https://www.w3.org/TR/xpath/。
二、XPath常用规则
下表列举了XPath的几个常用规则:
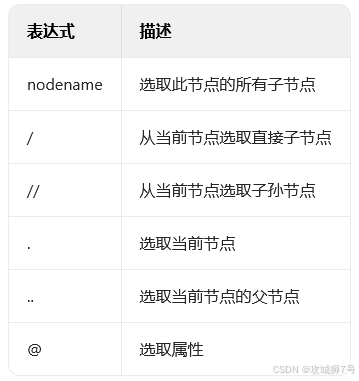
这里列出了XPath的常用匹配规则,示例如下:
//title[@lang='eng']
这条XPath规则的作用是,把所有名称是title,同时属性lang的值为eng的节点都选出来。后面我们会借助Python的lxml库,运用XPath对HTML进行解析。
三、实例讲解
在开始使用XPath之前,确保已经安装了lxml库。如果没有安装,请自行查阅相关资料完成安装过程。
以下是一个简单的实例,展示了如何使用XPath解析HTML文档:
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1">second item</li>
<li class="item-inactive">third item</li>
<li class="item-1">fourth item</li>
<li class="item-0">
<a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
result = etree.tostring(html)
print(result.decode('utf-8'))这里先把lxml库的etree模块导进来,接着弄了一段HTML文本,再用HTML类去初始化这段文本,这样就成功做出了一个XPath解析对象。要留意的是,那段HTML文本里最后一个li节点没闭合,不过etree模块能自动把这个HTML文本修正过来。
然后我们用tostring()方法,能输出修正后的HTML代码,只是输出的结果是bytes类型。再用decode()方法把它转成str类型,得到的结果如下:
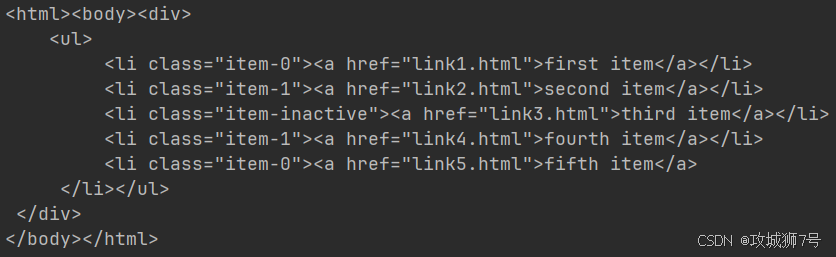
能看到,处理完后,li节点的标签补齐了,还自动加上了body和html节点。另外,也能直接读取文本文件来解析,示例如下:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = etree.tostring(html, method='html')
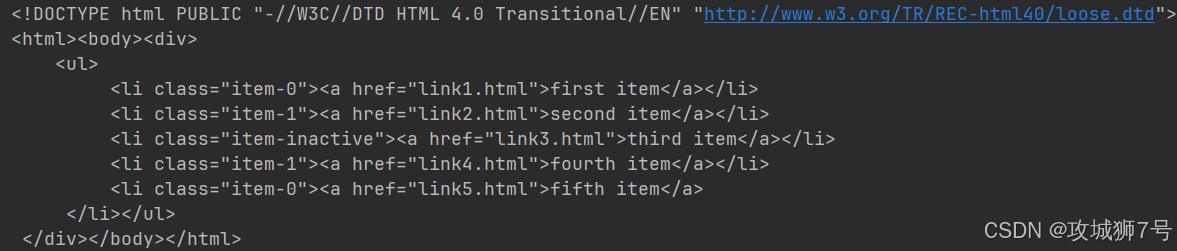
print(result.decode('utf-8'))其中test.html的内容就是上面例子中的HTML代码,内容如下:
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul></div>执行上述代码后,可以看到输出结果包含了额外的DOCTYPE声明,但这并不会影响到我们的解析工作。结果如下:
四、节点的选取
4.1 所有节点的选取
要选择HTML文档中的所有节点,可以使用以双斜杠(//)开头的XPath表达式。例如,对于前面提到的HTML文本,可以通过以下方式获取全部节点:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//*')
print(result)运行结果如下:

这里使用的*通配符表示匹配任意类型的节点,因此最终返回的结果会涵盖整个HTML文档中的每一个元素。每个匹配到的节点都会以Element对象的形式存储在一个列表中,便于进一步的操作和分析。
当然,也可以指定具体的节点类型作为筛选条件。比如,如果我们只关心所有的<li>节点,则可以这样写:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li')
print(result)
print(result[0])想要选出所有的li节点,办法很简单,用//,紧接着写上节点名称“li”就行。在程序里调用的时候,直接用xpath()这个方法。 运行之后得到的结果是:

从这里能看出,提取出来的结果呈现为列表形式。列表里的每一个元素,都是一个Element对象。要是你想从里面拿出某一个对象,直接用中括号加上对应的索引值就行,比如用[0]就能取出第一个对象 。
4.2 子节点的选取
在确定了父节点之后,我们可能需要进一步选择其下的子节点或子孙节点。这可以通过在XPath表达式中连续使用单斜杠(/)或双斜杠(//)来实现。
假设现在我们要找出所有<li>节点下直接嵌套的<a>子节点,可以这样做:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li/a')
print(result)在已有的XPath表达式后面加上/a ,就能选中所有li节点下的直接a子节点。这是因为//li能选中所有的li节点,而/a专门用来选中li节点的直接a子节点,把它们合起来,自然就获取到所有li节点的直接a子节点了。运行之后的结果如下:

这里的/是用来选取直接子节点的。要是想获取所有子孙节点,那就用//。举个例子,要是想获取ul节点下的所有子孙a节点,可以像下面这样操作:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//ul//a')
print(result)运行结果如下:

因此,我们要注意/和//的区别,其中/用于获取直接子节点,//用于获取子孙节点。
4.3 父节点选取
我们都知道,用连续的 / 或者 // 能查找子节点或者子孙节点。当我们已经定位到了某个具体节点时,有时也需要回溯至其上级节点进行操作。这时,可以利用点号(.)或者parent::关键字来实现这一目的。
举个例子来说,假如我们需要先找到链接地址为"link4.html"的那个<a>标签,然后再向上追溯到它的父级<li>元素,并从中提取出该元素的"class"属性值。对应的代码片段如下所示:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//a[@href="link4.html"]/../@class')
print(result)运行结果如下:
['item-1']
查看结果后会发现,这恰好就是我们要获取的目标li节点的class。此外,我们还能用parent::这种方式来获取父节点,代码如下:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//a[@href="link4.html"]/parent::*/@class')
print(result)五、属性匹配获取及文本获取
5.1 属性匹配
在选择节点时,我们可以用@符号来筛选属性。在选择节点的过程中,我们常常需要根据特定的属性值来进行过滤。这可以通过在XPath表达式中加入方括号([])以及相应的属性名和期望值来达成。
例如,如果我们只想挑选出那些拥有"class"属性等于"item-0"的所有<li>节点,就可以按照下面的方式来构造查询语句:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]')
print(result)我们加上[@class="item-0"],限定节点的class属性必须是item-0。在HTML文本里,符合这个条件的li节点有两个,所以结果应该会返回两个匹配到的元素。

结果如下:可以看到,匹配结果确实是两个,这俩是不是我们要的,后面再验证。
5.2 文本获取
除了属性之外,另一个常见的需求是从选定的节点中提取文本内容。在XPath中,这通常是通过调用text()函数来完成的。
让我们尝试一下从前面提到过的那些<li>节点内部获取文本信息吧:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]/text()')
print(result)运行结果如下:
['\r\n ']
挺奇怪的,我们啥文本都没获取到,这是为啥呢?因为在XPath里,text()前面是/,这里的/意思是选直接子节点。很明显,li的直接子节点都是a节点,文本都在a节点里面。所以这里匹配到的结果就是修正后的li节点里的换行符,毕竟自动修正时li节点的尾标签换行了。
即选中的是这两个节点:
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li>有个节点因为自动修正,添加li节点的尾标签时换行了,所以提取文本得到的就只有li节点尾标签和a节点尾标签之间的换行符。
所以,要是想获取li节点里面的文本,有两种办法。一种是先选到a节点,然后获取文本;另一种是用 //。下面,我们来看看这两种方法有啥不一样。
先看选到a节点再获取文本,代码如下:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]/a/text()')
print(result)运行结果如下:
['first item', 'fifth item']
能看到,这里返回了两个值,内容都是class属性为item-0的li节点里的文本,这也说明前面根据属性匹配得到的结果是对的。
我们在这儿是一层一层选的,先选了li节点,接着用/选了它的直接子节点a,然后再选a里的文本,得到的这两个结果,跟我们预想的一样。
接下来看看用另一种办法(也就是用//)选取的结果,代码如下:
from lxml import etree html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]//text()')
print(result)运行结果如下:
['first item', 'fifth item', '\r\n ']
果不其然,这儿返回了3个结果。不难想到,这是把所有子孙节点的文本都选出来了。其中前两个是li的子节点a里面的文本,还有一个是最后一个li节点里的文本,也就是换行符。
所以,要是想获取子孙节点里面的全部文本,直接用//加text()这种方式就行,这么做能确保获取到最完整的文本信息,不过可能会混进一些像换行符这样的特殊字符。要是只想获取某些特定子孙节点下的所有文本,可以先选到那些特定的子孙节点,接着调用text()方法来获取里面的文本,这样得到的结果会比较干净。
虽然这两种策略都能达到基本的目的,但在实际效果上却存在一定差异。前者倾向于产生较为干净整洁的结果集,因为它严格限制了搜索范围;相比之下,后者则有可能引入一些不必要的空白字符或其他干扰因素,因为它的包容性更强。因此,在具体实施过程中应当根据实际情况灵活调整策略,以期获得最佳的输出质量。
5.3 属性获取
除了文本内容外,我们还经常需要从节点中提取各种各样的属性值。幸运的是,XPath为我们提供了一种非常直观的方式来完成这项任务——只需简单地在节点名称后面附加一个@符号再加上所感兴趣的属性名即可。
举例来说,如果我们想要收集所有<li>节点下属<a>标签的href属性值,可以这样做:
from lxml import etreehtml = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li/a/@href')
print(result)在这儿,用@href就能拿到节点的href属性。要注意,这和属性匹配的方法不一样。属性匹配是用中括号加上属性名和值来限定某个属性,像[@href="link1.html"];而这里的@href是获取节点的某个属性,这两种情况要区分清楚。
运行结果如下:

能看到,我们成功拿到了所有li节点下面a节点的href属性,这些属性以列表形式返回。
这样一来,系统就会遍历整个文档树,寻找所有符合条件的<a>节点,并逐一记录下它们各自的href属性值。最终,这些值将以列表的形式呈现出来,供我们进一步分析或处理。
需要注意的是,此处使用的@href标记与前面介绍过的属性匹配机制有所不同。在属性匹配中,我们是在方括号内使用@符号加属性名的方式来设定筛选条件;而在属性获取场景下,@符号则直接紧跟在节点名称之后,用来指示我们关注的重点所在。理解这两者之间的区别对于正确编写XPath表达式至关重要。
5.4 属性多值匹配
在某些情况下,一个节点的某个属性可能会包含多个不同的值。例如,考虑以下HTML片段:
from lxml import etree
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[@class="li"]/a/text()')
print(result)在这段HTML文本里,li节点的class属性有两个值,分别是li和li - first。要是还用之前那种属性匹配的方法,就匹配不上了,运行结果如下:
[ ]
这时候就得用contains()函数了,代码可以改成下面这样:
from lxml import etree
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class, "li")]/a/text()')
print(result)用contains()方法的时候,第一个参数填属性名,第二个参数填属性值。只要这个属性包含你填的属性值,就能完成匹配。
现在运行结果如下:
['first item']
这种方法在节点的某个属性有多个值的时候经常会用到,像节点的class属性就常常有好几个值。
这一次,我们不再拘泥于"class"属性必须完全等于某一个固定值,而是转而考察它是否至少包含"li"这个关键词。如此一来,即便面对像上面那样的复合型属性值,我们也能够从容应对,确保不会遗漏任何一个有价值的线索。
5.5 多属性匹配
除了处理单个属性的多值情形外,我们还可能遇到需要同时考量多个属性的情况。在这种场合下,单纯依靠contains()函数或许不足以解决问题,因为我们还需要保证所有相关的属性都满足各自独立的约束条件。
为此,XPath允许我们在同一个方括号内串联起多个由and连接的布尔表达式,以此来表达更为精细的筛选逻辑。例如,假设有这样一个HTML片段:
from lxml import etree
text = '''
<li class="li li-first" name="item"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class, "li") and @name="item"]/a/text()')
print(result)这里的`li`节点多了一个`name`属性。要精准找到这个节点,得同时依据`class`和`name`属性来筛选。一个条件是`class`属性里得包含`li`这个字符串,另一个条件是`name`属性得是`item`这个字符串,这两个条件必须同时满足,所以要用`and`操作符把它们连起来,连好后放在中括号里当作筛选条件。运行结果如下:
['first item']
这里的`and`属于XPath里的运算符。其实,XPath还有不少其他运算符,像`or`、`mod`等等,下面整理成表格供参考。
运算符及其介绍
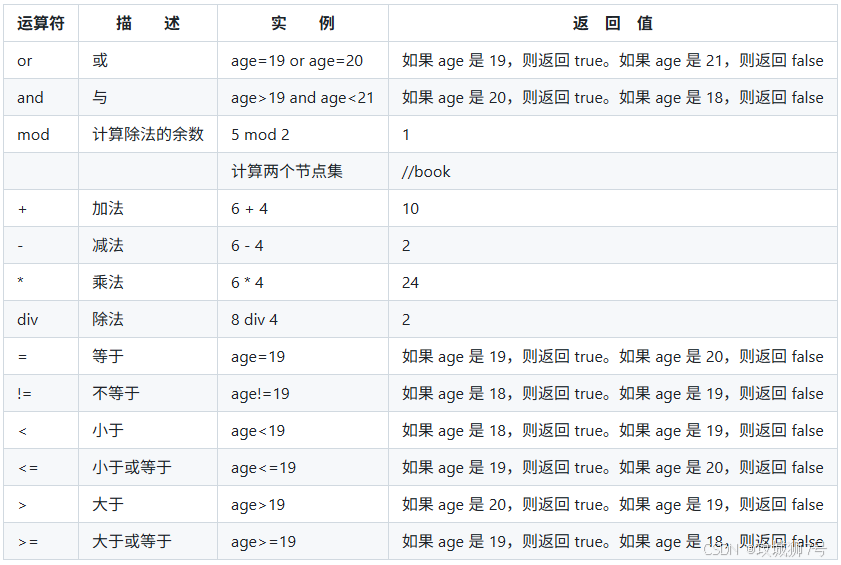
参考来源:http://www.w3school.com.cn/xpath/xpath_operators.asp
六、按序选择
有时候,我们选节点时,某些属性可能会匹配到好几个节点,但我们只想要其中特定的一个,比如第二个节点或者最后一个节点,这时候咋整呢?
在实际工作中,我们往往不仅仅关心某一类节点的整体分布状况,还会特别留意其中某些特定成员的位置信息。例如,当我们面对一组有序排列的项目列表时,可能只对其中的第一个、最后一个或是中间某个特定编号的条目感兴趣。针对这种情况,XPath提供了一系列基于序列位置的查询技巧,使我们能够精准地锁定目标节点。
最基本的用法是在中括号内填入一个整数索引来获取指定顺序的节点,例子如下:
from lxml import etreetext = '''
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul></div>
'''
html = etree.HTML(text)
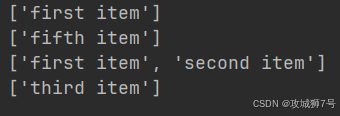
result = html.xpath('//li[1]/a/text()')
print(result)
result = html.xpath('//li[last()]/a/text()')
print(result)
result = html.xpath('//li[position()<3]/a/text()')
print(result)
result = html.xpath('//li[last()-2]/a/text()')
print(result)第一次选的时候,我们要选第一个`li`节点,在中括号里写数字`1`就行。要注意,这里和代码里不一样,序号是从`1`开始,不是从`0`开始的。
第二次选的时候,我们要选最后一个`li`节点,在中括号里写`last()`就可以,这样返回的就是最后一个`li`节点。
第三次选的时候,我们要选位置序号小于`3`的`li`节点,也就是序号为`1`和`2`的节点,结果就是前两个`li`节点。
第四次选的时候,我们要选倒数第三个`li`节点,在中括号里写`last() - 2`就行。因为`last()`代表最后一个,所以`last() - 2`就是倒数第三个。
运行结果如下:
这里我们用到了`last()`、`position()`这些函数。在XPath里,有100多个函数,能处理存取、数值、字符串、逻辑、节点、序列等方面的操作。这些函数具体有啥用,可以参考:http://www.w3school.com.cn/xpath/xpath_functions.asp 。
七、节点轴选择
除了常规的父子关系查询外,XPath还提供了一些特殊的“轴”(axis)概念,用于描述节点间更为复杂的空间布局特征。借助这些轴的概念,我们可以沿着不同的方向探索文档树,从而发现更多隐藏在深处的信息宝藏。
以下是一些常用的轴选择示例:
- ancestor:选择当前节点的所有祖先节点。
- attribute:选择当前节点的所有属性。
- child:选择当前节点的所有直接子节点。
- descendant:选择当前节点的所有子孙节点。
- following:选择当前节点之后的所有节点。
- following-sibling:选择当前节点之后的所有同级节点。
- parent:选择当前节点的父节点。
- preceding:选择当前节点之前的所有节点。
- preceding-sibling:选择当前节点之前的所有同级节点。
XPath有很多选节点轴的方法,能获取子元素、兄弟元素、父元素、祖先元素这些,例子如下:
from lxml import etreetext = '''
<div><ul><li class="item-0"><a href="link1.html"><span>first item</span></a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul></div>
'''
html = etree.HTML(text)
result = html.xpath('//li[1]/ancestor::*')
print(result)
result = html.xpath('//li[1]/ancestor::div')
print(result)
result = html.xpath('//li[1]/attribute::*')
print(result)
result = html.xpath('//li[1]/child::a[@href="link1.html"]')
print(result)
result = html.xpath('//li[1]/descendant::span')
print(result)
result = html.xpath('//li[1]/following::*[2]')
print(result)
result = html.xpath('//li[1]/following-sibling::*')
print(result)运行结果如下:

第一次选节点时,我们用了`ancestor`轴,它能获取所有祖先节点。使用时后面要跟两个冒号,然后写节点选择器,这里我们直接用`*`,意思是匹配所有节点,所以返回的是第一个`li`节点的所有祖先节点,有`html`、`body`、`div`和`ul`。
第二次选节点,我们加了个条件,在冒号后面写了`div`,这样结果就只有`div`这一个祖先节点了。
第三次选节点,我们用了`attribute`轴,它能获取所有属性值。后面跟着的选择器还是`*`,就是获取节点的所有属性,返回的就是`li`节点的所有属性值。
第四次选节点,我们用了`child`轴,它能获取所有直接子节点。这里我们加了条件,选`href`属性是`link1.html`的`a`节点。因为示例文本里第一个`li`节点下面的`a`节点,`href`属性值不是`link1.html`,所以返回的是空列表。
第五次选节点,我们用了`descendant`轴,它能获取所有子孙节点。这里我们加了条件,只要`span`节点,所以结果里只有`span`节点,没有`a`节点。
第六次选节点,我们用了`following`轴,它能获取当前节点后面的所有节点。这里虽然用`*`匹配,但我们加了索引来选,所以只拿到了第二个后续节点。
第七次选节点,我们用了`following - sibling`轴,它能获取当前节点后面的所有同级节点。这里用`*`匹配,所以拿到了所有后续同级节点。
上面就是XPath轴的简单用法,更多轴的用法可以参考:http://www.w3school.com.cn/xpath/xpath_axes.asp 。
八、总结
至此,我们已经大致介绍了XPath语言的核心特性和主要用途。作为一种强大而又灵活的查询工具,XPath无疑为我们提供了许多便利之处,尤其是在处理大规模、高复杂度的HTML文档时更是如此。然而,要想充分发挥其潜力,还需不断实践积累经验,并时刻保持对新技术的关注和学习热情。
在此基础上,我们强烈推荐读者朋友们继续深入研究XPath的相关知识体系,包括但不限于其丰富的内置函数库、先进的模式匹配算法以及与其他编程语言的良好集成能力等方面。相信随着大家技术水平的不断提高,一定能够在未来的网络爬虫开发实践中取得更加丰硕的成果!
参考资料:
XPath官方文档:http://www.w3.org/TR/xpath/
W3Schools XPath教程:http://www.w3school.com.cn/xpath/index.asp
Python lxml库文档:http://lxml.de/
参考书籍:
《Python 3网络爬虫开发实战》