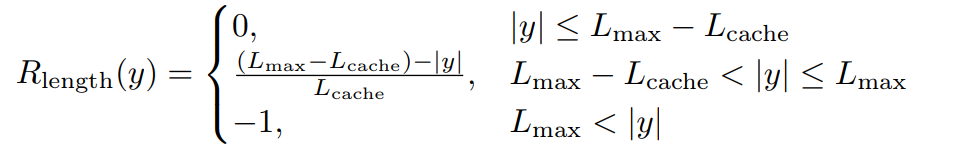今天总结较新的DAPO的核心内容
一、简介
DAPO在公开的数学数据集上做
对于GRPO算法加入了一些改进,以很少的训练步数达到了R1蒸馏的qwen32B的性能: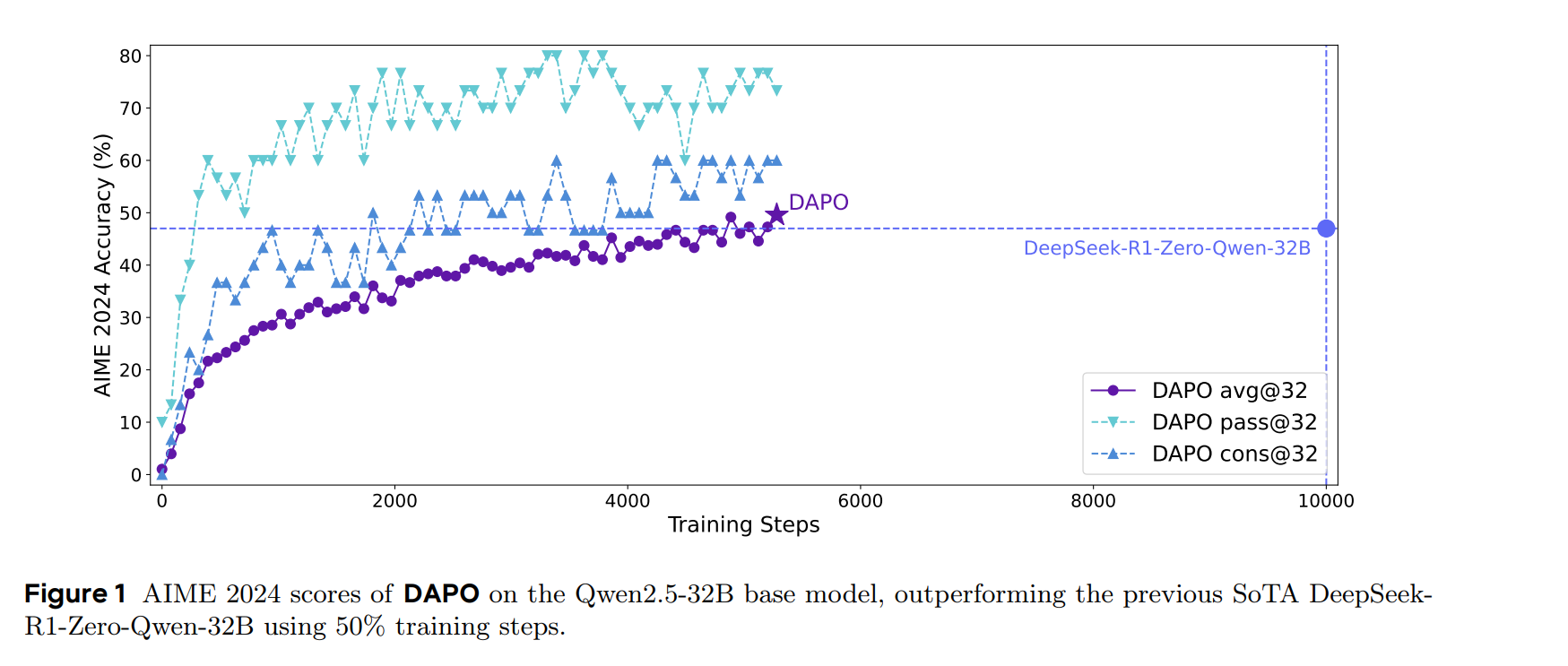
对GRPO加入以下改进,以解决GRPO实际中的熵崩溃、奖励噪声和训练不稳定性:
1.将GRPO中的裁剪上限提高,鼓励模型探索(当上线过低时,模型出现较大的采样比时不会梯度反传)
2.动态采样
3.token级别的策略梯度损失
4.过长奖励惩罚
用verl框架进行了该训练方法的实现
二、方法
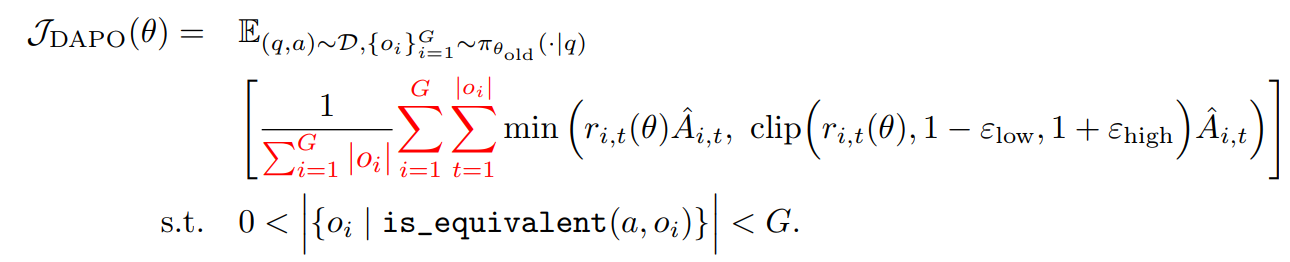
去除了KL散度约束,
1.提高裁剪上限:在PPO和GRPO中,存在随着训练的过程,模型的熵急剧下降的熵崩溃现象,采样的响应很多都是相同的,表现出极少的探索和确定的策略,可能限制了模型的扩展
clip的上界可能限制了模型的探索,具体来说,有一个例子,对于旧策略模型而言,其生成概率较小的token被抑制得很严重,重要性采样比超过很小的比例,就不会在这个采样上进行梯度反传
作者的做法是将裁剪的上下阈值分开,鼓励模型探索
2.动态采样
在训练过程中,去除组内完全相同的采样,防止所有样本跟均值相同导致梯度消失的现象:
3.token级别的策略梯度损失
将先每个样本先计算采样结果长度上的平均,改为计算token级别的损失,使得每个token对于训练的损失贡献相同,以此防止长样本中的token对于训练的低贡献的问题
4.过长损失