CCF等级:A
发布时间:2018年
代码位置
25年4月21日交
目录
一、简介
二、原理
1.注意力系数
2.归一化
3.特征组合与非线性变换
4.多头注意力
4.1特征拼接操作
4.2平均池化操作
三、实验性能
四、结论和未来工作
一、简介
图注意力网络(GATs),可以在图结构数据上操作的神经网络架构。在GAT模型中,节点能够在它们的邻域特征上进行“关注”,从而隐式地为邻域中的不同节点指定不同的权重。简单理解为节点能够知道关联的每个节点对自己的影响权重是多少。
二、原理
首先将节点转化为向量,然后通过自我注意机制计算每个节点对其邻居的重要性权重(即注意力系数),并通过softmax函数进行归一化。接下来,利用这些归一化的注意力系数对邻近节点的特征加权求和,得到每个节点的新特征表示,并通常应用非线性激活函数进一步处理。为了增强模型的表现力和稳定性,GAT可以采用多头注意力机制独立执行上述过程多次,并将结果拼接或平均,最终生成用于分类或其他任务的节点特征表示。
1.注意力系数
先将节点转化为向量,节点的向量为
。(这一部分不重要,就不展开讲解)
和
分别是节点
和节点
的特征向量。
是一个权重矩阵,用于线性变换这些特征向量。
是一个注意力机制函数,用于计算两个变换后的特征向量之间的相似度或相关性。
使用权重矩阵对节点进行线性变换,再通过注意力机制函数
计算这两个变换后特征向量之间的注意力分数
。
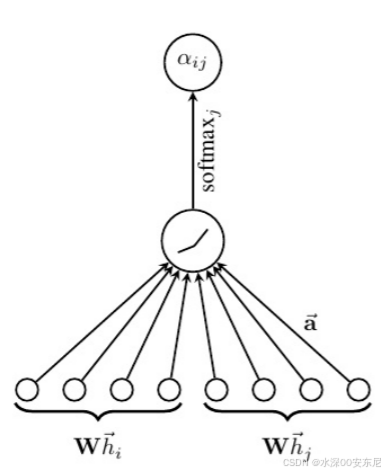
节点对其邻居节点
的注意力系数
注意:只衡量了节点
关注节点
的程度,而不是同时考虑
对
关注程度。换句话说
和
是独立计算的,它们分别代表了从节点
到节点
和从节点
到节点
的注意力权重,这允许模型对每个方向的重要性进行不同的赋值。
2.归一化
是注意力分数
的指数函数值。
是节点
的注意力分数的指数函数值之和。
表示节点
通过函数,每个节点
对其邻居节点
的注意力权重
被归一化到
区间内,并且所有邻居节点的注意力权重之和为 1。归一化不仅提高了模型性能,还增强了模型的鲁棒性和解释性。
计算注意力系数和归一化的公式可以合并为
3.特征组合与非线性变换
利用标准化后的注意力系数,对邻近节点
的特征进行加权求和,从而得到每个节点的新特征表示。
是节点
表示经过
归一化后,邻居节点
表示节点
是一个非线性激活函数,例如
或
,用于引入非线性。
通过上述步骤,图注意力网络(GATs)能够动态地调整每个节点对其邻居节点的关注度,并据此更新自身的特征表示,以捕捉更丰富的局部结构信息。
4.多头注意力
通过为每个注意力头使用不同的权重矩阵,模型可以捕捉到不同类型的特征关系。
类似于卷积神经网络中使用不同的卷积核计算。
多头注意力机制 类似于多尺度特征提取,不同尺度的特征通过不同的卷积核提取。
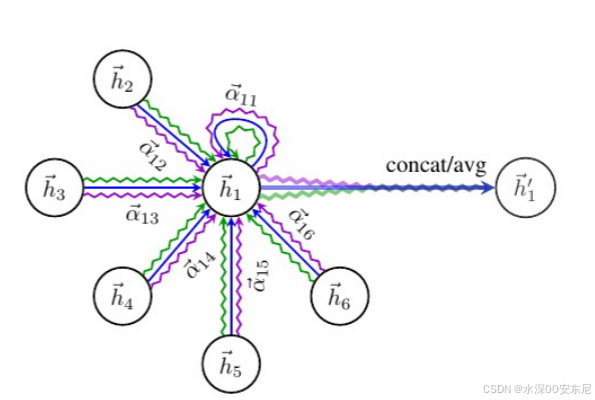
多头注意力机制来计算节点的新特征表示
4.1特征拼接操作
表示将
个注意力头的结果进行拼接,形成最终的特征表示。
是第
表示对所有邻居节点
4.2平均池化操作
表示对
总结:
使用单一的注意力权重和权重矩阵,适用于简单的注意力机制。
使用多头注意力机制,特征拼接操作,并通过特征拼接操作组合多个注意力头的结果,从而增强模型的表达能力。
使用多头注意力机制,平均池化操作,并通过平均池化操作组合多个注意力头的结果,从而增强模型的表达能力。
三、实验性能
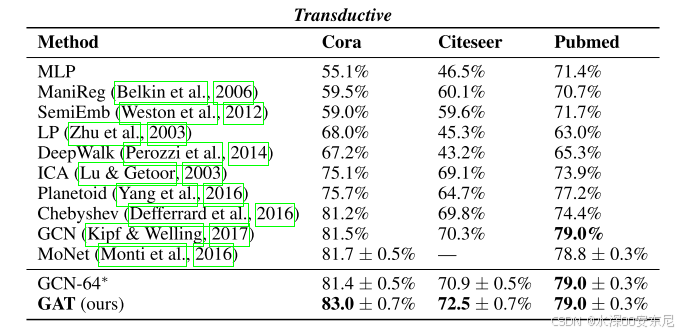
Cora、Citeseer和Pubmed分类准确率的结果总结。GCN-64 *对应于计算64个隐藏特征的最佳GCN结果。
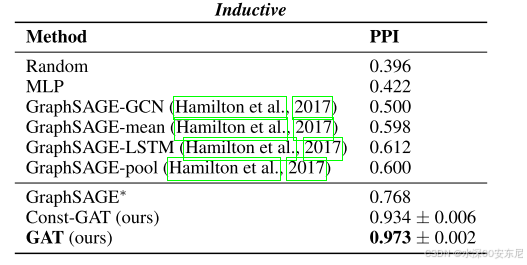
对于PPI数据集,以微平均F1分数表示的结果摘要。GraphSAGE*对应于我们仅通过修改其架构即可获得的最佳GraphSAGE结果。
四、结论和未来工作
1.解决稀疏矩阵运算限制的问题:使用的张量操作框架仅支持秩2张量的稀疏矩阵乘法,这限制了批次处理的能力。
2.扩展模型深度:采用跳连接等技术可以适当扩展模型的深度,从而提高其表达能力。