业务背景
在企业智能化升级的浪潮中,信息的获取方式正从关键词匹配向语义理解转变。传统的基于反向索引的搜索引擎依赖于字符串级别的匹配机制,难以捕捉用户查询背后的真实语义。
这对于搜索体验、推荐精准度、客服响应以及知识问答系统的智能化程度造成了明显的制约。以电商平台为例,用户在检索适合夏季穿的白色连衣裙时,平台若仅通过关键词匹配商品标题或类目,将难以捕捉适合夏季这一包含面料、版型等多维语义的信息。
类似的问题也广泛存在于金融文档检索、智能客服问答、知识图谱关联等多种业务场景中。
为此,我们希望构建一个基于向量检索能力的语义搜索系统。核心目标是:将业务数据中的文本字段实时转化为语义向量,写入支持近似向量搜索的数据库,实现语义级别的信息检索能力。
这个过程需要解决以下几个关键挑战:
- 异构数据源的高性能接入与同步;
- 文本语义嵌入的在线生成与模型调用;
- 嵌入结果的结构化写入与向量索引构建;
- 支持向量搜索的高可用低延迟存储系统;
- 全链路的可观测性与扩展性。
技术选型与架构核心
为实现上述系统能力,我们基于现代数据工程范式选型如下技术栈,并实现了可落地的全链路解决方案:
Apache SeaTunnel:统一数据集成与同步中枢
Apache SeaTunnel 是一个面向实时和离线场景的开源高性能分布式数据集成平台,具备良好的扩展性和强大的异构数据源适配能力。其核心特性包括:
- 丰富的 Connector 插件体系:支持 100+ 数据源,包括主流数据库、消息队列、文件系统、对象存储、NoSQL 等,具备良好的接入能力;
- 批流一体的数据处理范式:支持离线全量、离线增量、CDC 以及实时流式同步等多种模式,适用于全量建库与增量更新等场景;
- 多引擎支持:支持 SeaTunnel 自研 Zeta 引擎、Flink 和 Spark,具备高度灵活性与资源适配性;
- 插件式 Transform 机制:可通过自定义 Transform 插件,灵活嵌入中间处理逻辑,如文本预处理、调用外部 API 获取嵌入向量等;
- 完善的监控与运维支持:通过 SeaTunnel Web 提供图形化作业编排与实时任务监控能力。
在本方案中,我们以 Apache SeaTunnel 为数据处理主干,利用其 Source 模块从业务数据库/对象存储中实时提取原始数据,使用 Transform 模块调用 Amazon Bedrock 接口完成文本向量化,最终通过 Sink 模块将结果写入 Amazon OpenSearch,构建支持语义检索的向量索引。
Amazon Bedrock:企业级向量生成服务平台
Amazon Bedrock 是 AWS 提供的统一大模型调用与管理平台,支持直接通过 API 访问多个主流厂商的 Foundation Model(如 Anthropic Claude、Cohere、Stability AI、Mistral、Amazon Titan 等),无需构建和部署模型基础设施。
在文本向量生成场景中,我们重点考虑以下两种嵌入模型:
- Cohere Embed v3
支持文本与图像的多模态嵌入能力,覆盖 100+ 语言,适用于构建跨语言、高语义表达力的搜索系统。Embed v3 在多种评测任务上表现优异,尤其适合复杂场景下的多域语义匹配。 - Amazon Titan Embeddings v2
由 AWS 原生提供,支持小维度(256/512/1024)的高质量嵌入输出,具备良好的压缩率和检索精度平衡,适合低延迟、高并发、对存储成本敏感的场景。
借助 Bedrock 的 API 接口,我们可在 SeaTunnel 的 Transform 阶段调用嵌入模型服务,完成原始文本字段到高维稠密向量的转换,并保留 ID、标签、元数据等信息用于后续入库。
Amazon OpenSearch:支持向量检索的云原生存储系统
Amazon OpenSearch 提供了原生的 knn_vector 字段类型,用于向量化数据的索引与相似度检索,支持 Faiss、NMSLIB 等主流 ANN 算法后端,具备以下特点:
- 高并发向量插入与检索性能;
- 支持结构化查询与向量检索混合执行;
- 向量字段可配置维度、距离类型(cosine/l2/dot_product)、索引参数等;
- 集成 KNN 插件支持 HNSW 等近似搜索算法,加速向量索引构建;
- 与标准 OpenSearch 查询语法无缝集成,便于复合搜索(如“价格范围 + 相似描述”)的场景实现。
通过 Apache SeaTunnel 的 OpenSearch Sink 插件,我们可将向量与相关结构化字段(如ID、标题、标签等)一并写入,实现低代码方式构建“语义+结构”的多维检索系统。
方案架构及操作步骤
整体架构
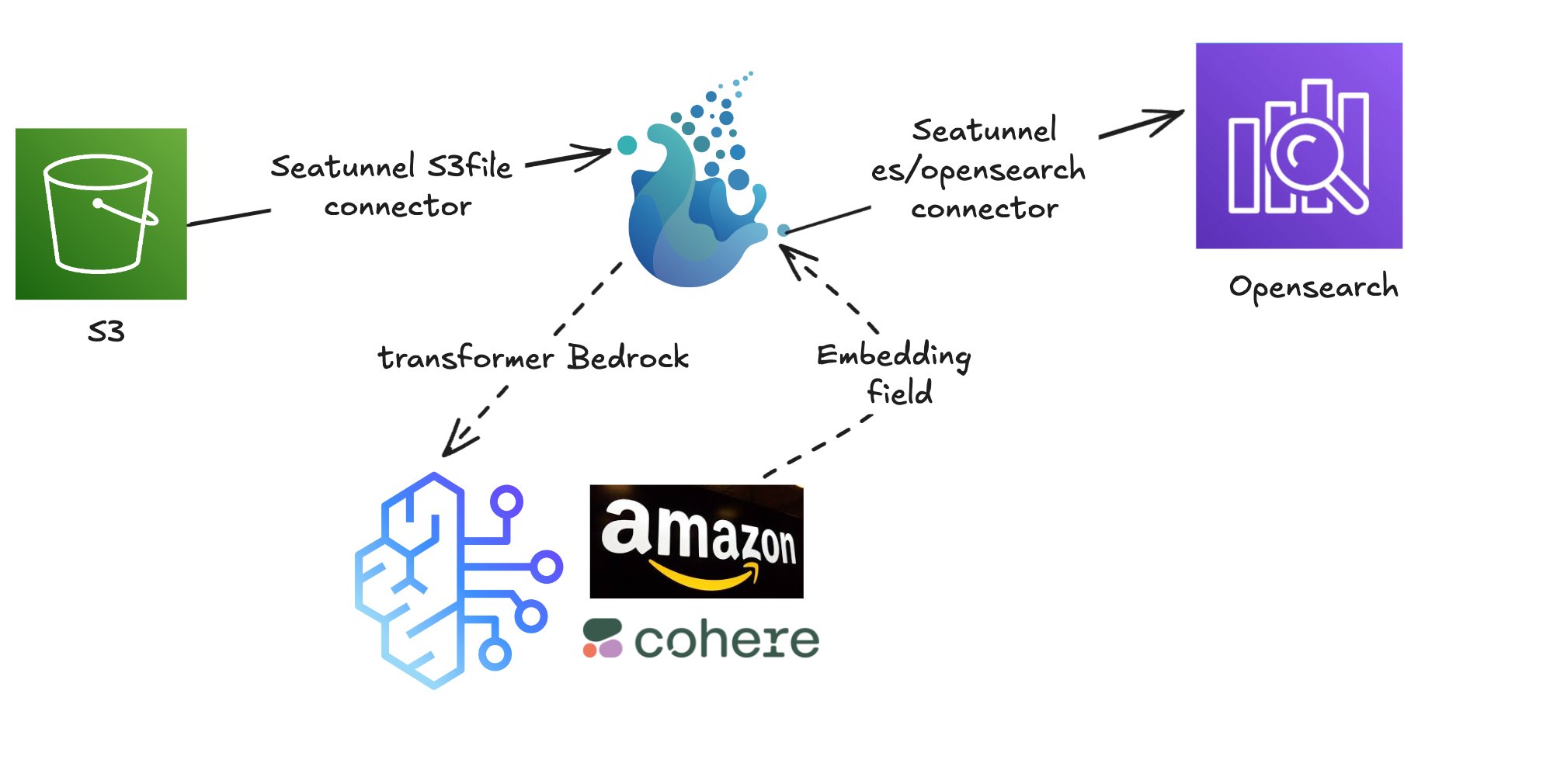
数据导入
以 Amazon 电商平台客户评论数据为例,原始数据格式及字段如下,文件为 json 数据格式。
{"Item":{"review_id":{"S":"AEEZL8Z5691IJ"},"date":{"S":"1215475200"},"customer":{"S":"Amazon Customer"},"asin":{"S":"B000Q6R4MK"},"review":{"S":"I can hear the caller just great -- but I get frequent \"what?\" \"I can't hear you\" \"it sounds like a lot of background noise\" , etc. comments. I'm trying to figure out the best way to have it arranged on my visor, etc. Not 100% sold yet."},"rating":{"S":"4.0"}}}
在电商场景中,经常需要搜索评论内容,即字段对应的 review 。现在我们需要将这个字段进行向量化,并且将向量化的结果写入到 opensearch 中。
在 SeaTunel 中编辑配文件如下:
env { # Set the execution engine to SeaTunnel Zeta Engine execution.engine = "seatunnel" # Set job mode to BATCH for processing the JSON file job.mode = "BATCH"
} source { S3File { path = "/data/3vk7gdzq6myxhn2kwexoiywjh4.json" bucket = "s3a://opensearch" file_format_type = "json" # AWS region configuration fs.s3a.endpoint = "s3.us-east-1.amazonaws.com" # Use SimpleAWSCredentialsProvider instead of InstanceProfileCredentialsProvider fs.s3a.aws.credentials.provider = "org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider" # Provide explicit AWS credentials - 请替换为您的实际访问密钥 access_key = "" secret_key = "" # Additional S3A configuration options hadoop_s3_properties { "fs.s3a.impl" = "org.apache.hadoop.fs.s3a.S3AFileSystem" "fs.s3a.connection.ssl.enabled" = "true" } # Required schema for JSON file format schema = { fields { Item = { review_id = { S = string } date = { S = string } customer = { S = string } asin = { S = string } review = { S = string } rating = { S = string } } } } # Register output table plugin_output = "s3_data" }
} transform { # First transform to extract the actual review text from the nested S field Sql { plugin_input = "s3_data" plugin_output = "extracted_data" query = "SELECT Item.review_id.S as review_id, Item.date.S as date, Item.customer.S as customer, Item.asin.S as asin, Item.review.S as review, Item.rating.S as rating FROM s3_data" } # Use Amazon Bedrock to generate embeddings for the review field Embedding { plugin_input = "extracted_data" plugin_output = "embedded_data" # Specify the model provider as AMAZON for Bedrock model_provider = "AMAZON" # Specify the model ID for Amazon Titan Embeddings model = "amazon.titan-embed-text-v2:0" # AWS region for Bedrock service region = "us-east-1" # AWS credentials for Bedrock service - 请替换为您的实际访问密钥 api_key = "" secret_key = "" # Define which fields to vectorize and their target fields vectorization_fields { review_embedding = review } # Batch size for processing single_vectorized_input_number = 10 dimension = 1024 }
} sink { Console { plugin_input = "embedded_data" # 使用 Embedding 转换后的数据 # 只打印少量记录以便于查看 limit = 10 } Elasticsearch { plugin_input = "embedded_data" # OpenSearch endpoint hosts = ["https://xxxxxx.us-east-1.es.amazonaws.com"] tls_verify_certificate = false # Index configuration index = "reviews" username = "" password = "" vectorization_fields = ["review_embedding"] # 指定向量维度(每个向量中的浮点数数量) vector_dimensions = 1024 }
}
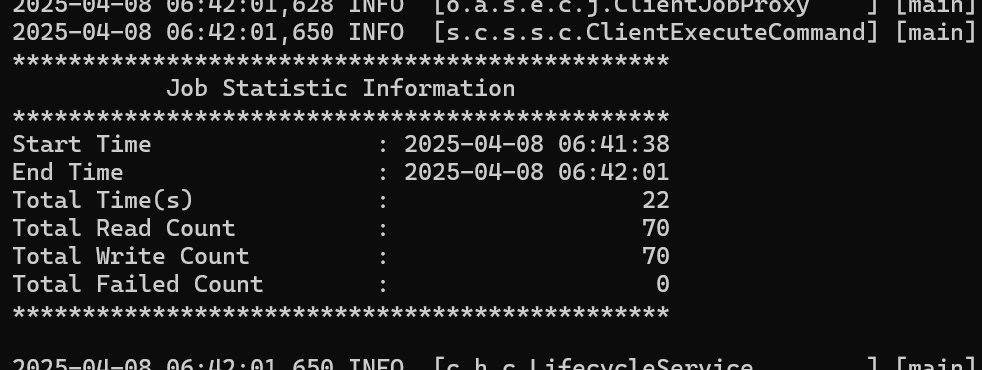
在 SeaTunnel 中运行任务,这里我们将输出进行了日志 console 打印,可以看到日志里将添加了一个字段 review_embedding

直到任务完成,看到统计信息
数据检索
使用 Opensearch 的 knn 检索及神经网络检索都可以进行向量匹配查询,您可以参考这个 workshop 进行Opensearch与 Bedrock 的模型对接。
查询示例
GET reviews/_search
{ "size": 5, "query": { "neural": { "review_embedding": { "query_text": "Installed and connected pretty well. Works good and keeps my eyes on the road. Took a few weeks to see the on and off button, but overall I like this and would suggest it.", "model_id": "8xwrFJYB5648rVcWvwIU", "k": 10 } } }
}
总结与展望
本文通过 Apache SeaTunnel + Amazon Bedrock + Amazon OpenSearch 的组合,构建了一套高可扩展性、低耦合的语义搜索数据处理链路,成功实现了从结构化/非结构化文本数据到向量检索系统的全流程集成。
该方案具有如下优势:
- 松耦合架构设计:SeaTunnel 的插件式 Transform 和 Sink 机制,使得模型调用与向量写入逻辑保持解耦,方便后续替换嵌入模型或变更底层向量数据库;
- 模型能力云原生接入:借助 Bedrock 提供的 API 网关与 IAM 权限体系,无需自行维护嵌入模型推理服务,简化了 AI 能力的接入门槛;
- 向量检索与结构检索融合:通过 OpenSearch 的混合查询能力,支持多维筛选与语义相似度排序的组合场景,覆盖从“找商品”到“问知识”的多类业务需求。
面向大规模生产的实践建议
若要将该方案推广至企业级生产环境,建议从以下几个维度进一步优化和演进:
嵌入缓存与批量推理优化
对于模型调用阶段,建议增加文本去重与缓存机制(如基于 MD5 哈希或 LRU 缓存)以避免重复嵌入,同时支持按批次对文本进行推理(Batch Inference),提升吞吐量并降低 Bedrock 调用成本。
嵌入字段维度规划与压缩策略
根据不同业务对检索精度/响应速度/存储成本的权衡,建议为不同场景配置不同维度的嵌入模型(如 Titan Embedding 512 适用于中小规模应用场景),必要时可引入 PCA 等压缩手段进一步降低向量维度。
向量索引管理与生命周期控制*
在 OpenSearch 中合理设置向量索引的 Refresh Interval、Segment Merge 策略、HNSW 参数(如 M、EF)、以及定期重建索引机制,以保障检索精度与写入性能间的平衡。
向量搜索效果评估与持续优化*
构建离线评估数据集(包含 Query、Ground Truth)、并设计 Recall@K、MRR、nDCG 等指标用于嵌入模型的效果评估。同时,结合 A/B 测试不断迭代模型与索引参数。
通过本文所示的技术路径,企业可实现将传统的结构化数据处理平台向“智能语义理解平台”演进,为搜索引擎、推荐系统、问答系统、企业知识中台等场景提供强大支撑。
未来,随着多模态嵌入模型的发展、RAG 架构的进一步普及,Apache SeaTunnel + Bedrock 的结合将在 AI 数据工程领域展现出更大的潜力。