4、mysql架构
开始编程语言进行调度,获取连接池,调用类型DML(操作数据),DDL(操作表)选择引擎,mysql默认inodb,读取磁盘。
5、sql约束
| 约束类型 | 描述 |
| NOT NULL | 确保某列的值不能为 NULL。 |
| UNIQUE | 确保某列或某些列的值唯一,不能重复。 |
| PRIMARY KEY | 唯一标识表中的每一行记录,隐含了 NOT NULL 和 UNIQUE。 |
| FOREIGN KEY | 保证引用关系的完整性,用于维护两个表之间的关联性。 |
| CHECK | 确保字段的值满足特定的条件。 |
| DEFAULT | 为字段设置默认值,在未显式赋值时会使用默认值。 |
| INDEX | 提升查询效率,不是完整性约束,但常用于快速检索数据。 |
6、mysql数据类型介绍
- 整数:tinyint 一个字节 smallint 两个字节 ==int== 4个字节 ==bigint== 8个字节
- 小数:float 单精度 double 双精度 decimal 可以指定小数的位数 可以设置长度 10,2 表示总长度为10位小数位为2位
- varchar 可变长度 指定长度表示最大长度,该列的数据按照实际长度进行存储 这种可变长度最大的优势就是节省空间
- char 定长:该列下所有数据按照统一的长度进行存储,如果数据长度不够则补充空格,这种类型的优势是查询的效率非常高
- text:也属于文本的一种,一般是用来保存大文本信息
-
date、datetime:DATE类型只存储日期,而DATETIME类型存储日期和时间。
7、增删改查语法
- select 内容 from 表名 where 条件
- insert into 表名 (字段名1,字段名2,。。。。) values(值1, 值2,.....)
- delete from 表名 [where 条件]
- update 表名 set 字段名1=值1,.... where 条件
-
表
建表:CREATE TABLE students ( id INT PRIMARY KEY AUTO_INCREMENT, `name` VARCHAR(50) NOT NULL , gender CHAR(1) NOT NULL DEFAULT '男', telephone CHAR(11) NOT NULL UNIQUE KEY )
删除表:drop table 表名
修改表的结构:ALTER TABLE students ADD COLUMN age INT
删除表数据不删结构:truncate
8、事物
8.2、四个特征
- 原子性:不可再分,(undo日志)
- 一致性:从一种一致状态切换到另一种
- 持久性:redolog的日志保证的
- 隔离性:一个事务在执行的过程不应该受到其他事务的影响
-
8.4、读锁和写锁
- 读锁:是共享的,多个事物可以共同获取一把锁, 但不允许写入数据
- 写锁:阻塞其他的读锁和写锁
- 串行化底层原理就是加了一把锁
8.3、隔离级别
-
读未提交:一个事务可以读取到另一个事务暂未提交的数据,会出现"脏读"问题
-
读已提交:[在同一个事务期间对同一个数据先后读取的结果不一致]
-
可重复读:”幻读“的问题,幻读当另一个插入了提交,另一个select不到,可通过upload修改
-
串行化 :当一个客户端访问数据库,而没有commit是另一个无法进行操作
8.5、mvcc
定义:
解决并发冲突问题,通过undo log版本记录链,形成一条日志多个版本,读历史快照旧数据,写是最新数据
进行数据操作,会有连个隐藏字段,数据链指向的是操作之前的数据(数据链),如果需要回滚,会读取之前数据。
使用undo log记录上一条日志,如果需要回滚
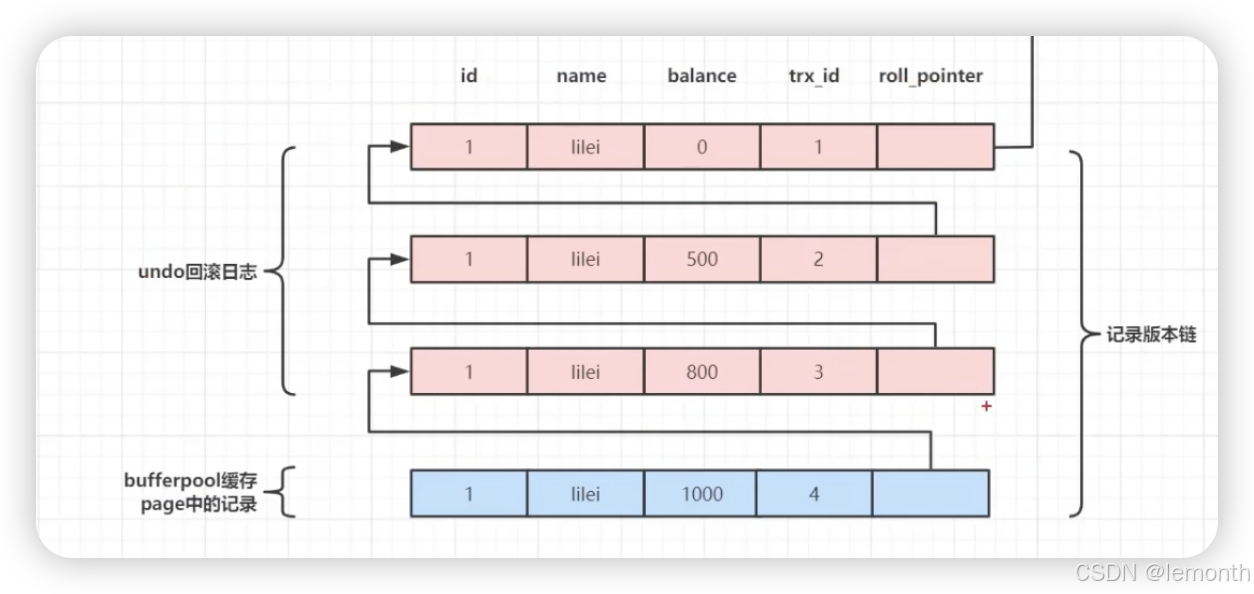
有一个事物id,trx_id 和回滚指针 ,mvcc解决读已提交,通过版本找到最新的数据
8.6、不可重复读,读到最开始的快照数据,进行数据处理,而数据已经改变怎么解决。

使用乐观锁,加一个版本,每次修改更行版本,根据版本更新

使用悲观锁,直接用最新数据更新
8.7、各事物具体应用场景
可重复读
多条查询语句需要开启事物,如统计报表,需要各个数据都是同一时刻
读已提交
不需要同一时间,对性能并发要求较高的事物
8.9、怎么实现持久化
redo日志
更新数据,从磁盘读取数据到buffer pool缓存池中,在讲数据写到redo日志文件中国呢,同时有一个线程io将根据空闲时间更新的数据写入磁盘(如果发生宕机,会通过redo日志恢复)
为什么不直接写入磁盘:
(磁盘顺序写很快比如,rabbitmq,kafka),但这里面是随机写,日志是顺序写
为什么不能idb磁盘顺序写,每个表的idb文件都不同,数据可能突然操作a表又操作b表,所以无法顺序写
update 更新流程
判断buffer pool缓存池是否有记录,如果没有从ibd获取加载到缓存池中
同步协redo日志
存储idb会有一个ibd线程随机写入
11、sql优化
11.1、explain执行计划
语法:explain+sql
![]()
id
-
id列结合table列,可以查看表的加载顺序
-
id相同,按table列从上到下顺序加载
-
id列不同,id值越大越先被加载
type
index(全索引扫描)和all(全硬盘扫描、没用上索引)需要优化
效率从好到次:system>const(主键查询)>eq_ref(多表连接中被驱动表的连接列上有primary key或者unique index的检索)>ref(非主键非唯一索引等值扫描)>range(范围查询)>index>all
SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,如果可以是 consts
最好。
说明:
1)consts 单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
2)ref 指的是使用普通的索引(normal index)。
3)range 对索引进行范围检索。
反例:explain 表的结果,type=index,索引物理文件全扫描,速度非常慢,这个 index 级
别比较 range 还低,与全表扫描是小巫见大巫。
possible_keys
> 理论上会用到哪些索引
keys
> 实际上用到的索引
rows
当前查询,扫描了多少行数,也是性能评估的重要依据
extra
sql排序是查看
Using index(索引排序效率高)
Using filesort(文件排序效率低)
Using temporary(分组排序效率较低)走索引分组高
Using where(条件排序效率较低)
11.3、sql优化操作
使用count只能用count(*)*会统计值为null,count列明不会统计null
最左前缀法则:where a=? and b=? ,a 列的几乎接近于唯一值,那么只需要单建 idx_a 索引即
可,使用最频繁的一列放在最左边。(mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配),不包括in
比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c字段是一个范围查询,它之后的字段会停止匹配。如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
索引列不能运算:where left(e.name,4)='Lucy' 改为:where e.name like 'Lucy%'
where salary*12>120000 改为:where salary>120000/12
索引列类型自动转换:-- explain select * from employee where name='250'
-- explain select * from employee where name=250(name为string)
!=、ont in索引失效: where e.name!='Lucy' 、 where e.name not in ('Lucy')
非空判断失效:where e.name is not NULL、where e.name is NULL 改为:将null字段为-1或其他
模糊查询:只有右模糊不会失效 where e.name like 'Lu%'
少用or
order by group by 优化最左前缀法
12.6、为什么建议使用自增长主键作为索引?
在插入过程中尽量减少页分裂
14、日志区别
binlog
• 主从复制:主库会将写入的变更记录到 Binlog,供从库同步。
• 数据恢复:用于基于时间点的增量恢复(如在崩溃后恢复到某个时间点)。
• 特点:
• 是 Server 层 的日志,独立于存储引擎。
• 记录的是 逻辑日志,表示数据变更的具体 SQL 操作,例如 INSERT、UPDATE 等。
• 按顺序追加写入。
• 持久性:
• Binlog 的写入通常是延迟提交,可能与事务完成不完全同步。
• 作用范围:
• 全局范围,记录数据库的所有变更。
• redolog
写入时机:
• 在事务提交前,必须确保 Redo Log 已经写入磁盘。
• 作用范围:
局部范围,仅适用于 InnoDB 存储引擎。
主要用于保证事务的持久性,支持事务的崩溃恢复,它记录的是物理数据层的修改操作。
• undolog
• 用途:
• 支持 事务回滚:用于撤销事务的修改,恢复数据到之前的状态。
• 实现 MVCC(多版本并发控制):保留数据的历史版本供读操作使用。
主要用于事务回滚,保证事务的隔离性,它记录的是反向的操作。
• 特点:
• 是 InnoDB 存储引擎 的日志。
• 记录的是 逻辑日志,表示如何撤销某个操作(如将插入改为删除,将更新改为还原为旧值)。
• 与事务绑定,事务完成后可以释放空间(或延迟清理)。
• 写入时机:
• 在事务执行过程中实时写入。
• 作用范围:
• 局部范围,仅适用于 InnoDB 存储引擎。
1、数据类型
- string
- 底层
增删改查
- set key value
- get key
- del k
- strlen k
加减
取v中特定位置数据
- getrange name 0 -1
- getrange name 0 1
- setrange name 0 x
设置过期时间
在分布式系统里面可以使用如下命令实现分布式锁
- setnx(set if not exist)
- 如果返回1:设置成功
- 如果返回0:设置失败
- List 有序、可重复
存
- lpush num 1 2 3 4 5
- rpush num2 1 2 3 4 5
弹出(获取数据的同时将数据从list中删除)
- lpop
- rpop
查
- lrange num 0 -1
- lrange num2 0 -1
根据下标获取元素
- LINDEX key index
大小
- LLEN key
队列:先进先出
栈:先进后出
- set无序,不可重复
存
- sadd ips '192.168.22.1' '192.168.22.2' '192.168.22.2'
查
- smembers ips
查看某个元素在集合中是否存在
- SISMEMBER key member
删
- srem ips '192.168.22.1'
大小
- scard ips #获取set的长度
随机
- sadd nums 3 4 5 0 9 8 9 0 8 6
- srandmember nums 3
随机并移除
- spop rands 3
交集
并集
- Hash:hash的key不能重复,如果重复就覆盖
存
- hset person name 'jack'
- hset person age 40
取
- hget person name
- hget person age
存多个
- hmset person name 'rose' age 12
大小
- hlen person
判断k是否存在
- hexists person age
- Zset:有序,不可重复,通过score来进行排序,score必须是数字
通过score进行排序
zadd hot 300 '华为met10' 10 '苹果10' 19 '小米'
zrange hot 0 -1
zrevrange hot 0 -1#分数范围过滤
zrangebyscore hot 11 100
zrangebyscore hot 10 100 limit 0 1
#删除
zrem hot '小米'
zcard hot #查看集合的元素个数
3、redis事物
✅ 原子性(Atomicity):事务中的所有命令会按顺序执行,但Redis 事务并不支持回滚。
✅ 单线程执行:事务中的所有命令在执行期间不会被其他命令打断。
❌ 不支持回滚:如果事务中某个命令执行失败,不会影响已执行的命令。
4、redis为什么不支持事物回滚
redis 只会因为语法错误而失败,如果这些错误不会在入队的时候发现,说明时程序错误造成的
不需要对回滚进行支持,所以redis才非常的快
5、持久化

7、内存淘汰
实际上Redis定义了几种策略用来处理这种情况:
-
noeviction(默认策略):对于写请求不再提供服务,直接返回错误(DEL请求和部分特殊请求除外)
-
allkeys-lru:从所有key中使用LRU算法进行淘汰,LRU(Least Recently Used)
-
volatile-lru:从设置了过期时间的key中使用LRU算法进行淘汰,LRU(Least Recently Used)
-
allkeys-random:从所有key中随机淘汰数据
-
volatile-random:从设置了过期时间的key中随机淘汰
-
volatile-ttl:在设置了过期时间的key中,根据key的过期时间进行淘汰,越早过期的越优先被淘汰
12、缓存击穿
某一个热点key,在失效的一瞬间,
13、缓存穿透
- 非法访问
17、缓存降级
- Redis服务不可用,或者网络抖动,导致服务不稳定
解决
- 使用熔断降级策略进行服务熔断降级
19、布隆过滤器
hash碰撞怎么办
用不同的hash算法取模落在不同位置
存在不一定存在,不存在一定不存在
21、redis底层
底层
通过hashtable
hash表:一维数组加二维码链表。(hash,set)
压缩列表:把链表的指针去掉了,用偏移找到位置,类似于数组(zset,hash,list)
整数数组:查询很快,操作很慢(set)
双向链表:(list)
跳表:底层是链表,从左到右依次排序,有点像二分查找。从下往上看 (zset)
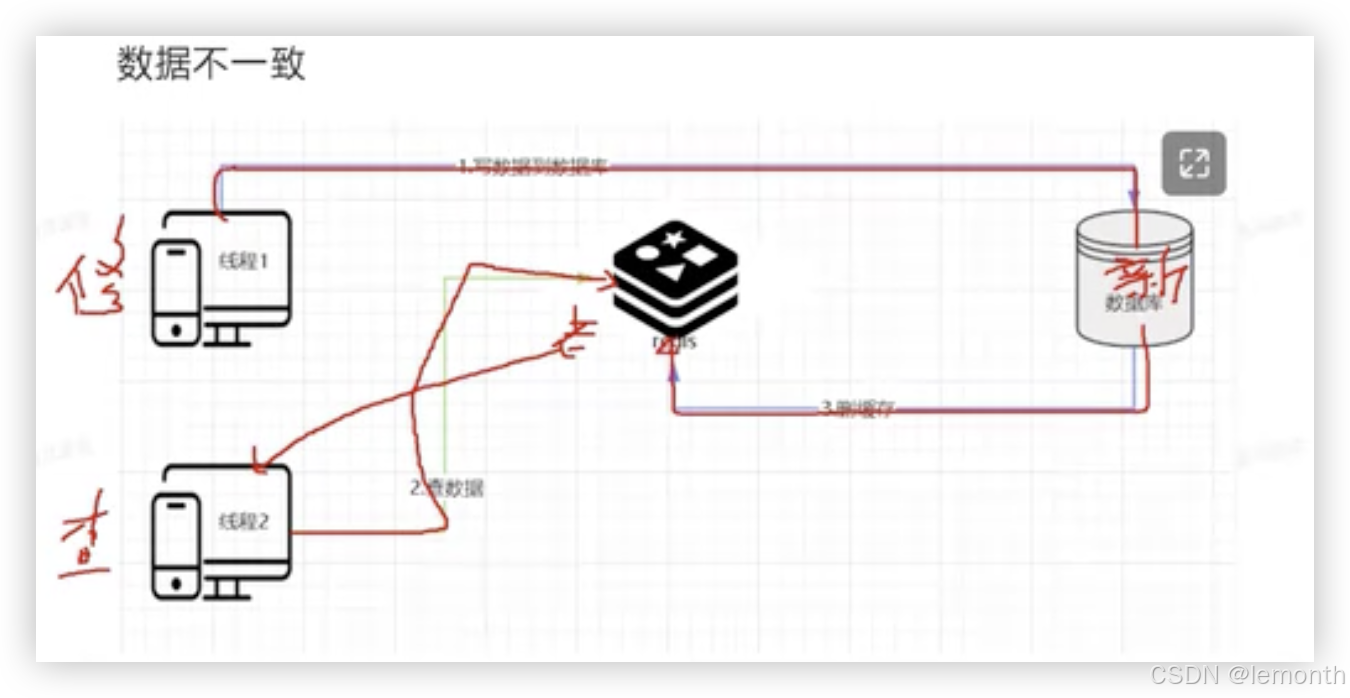
22、redis同步mysql先同步redis还是先同步sql
先操作redis
1、如果先修改同步redis 在同步mysql时出现网络原因,其他数据访问redis是新数据,而mysql存储是老数据(问题:数据不一致)
2、如果先删除redis,在同步mysql,在删除redis(要用延迟,是为了避免另一个线程进来删除后同步老数据)(问题:并发时会有一次数据不一致:解决用锁,限制速度不能使用)
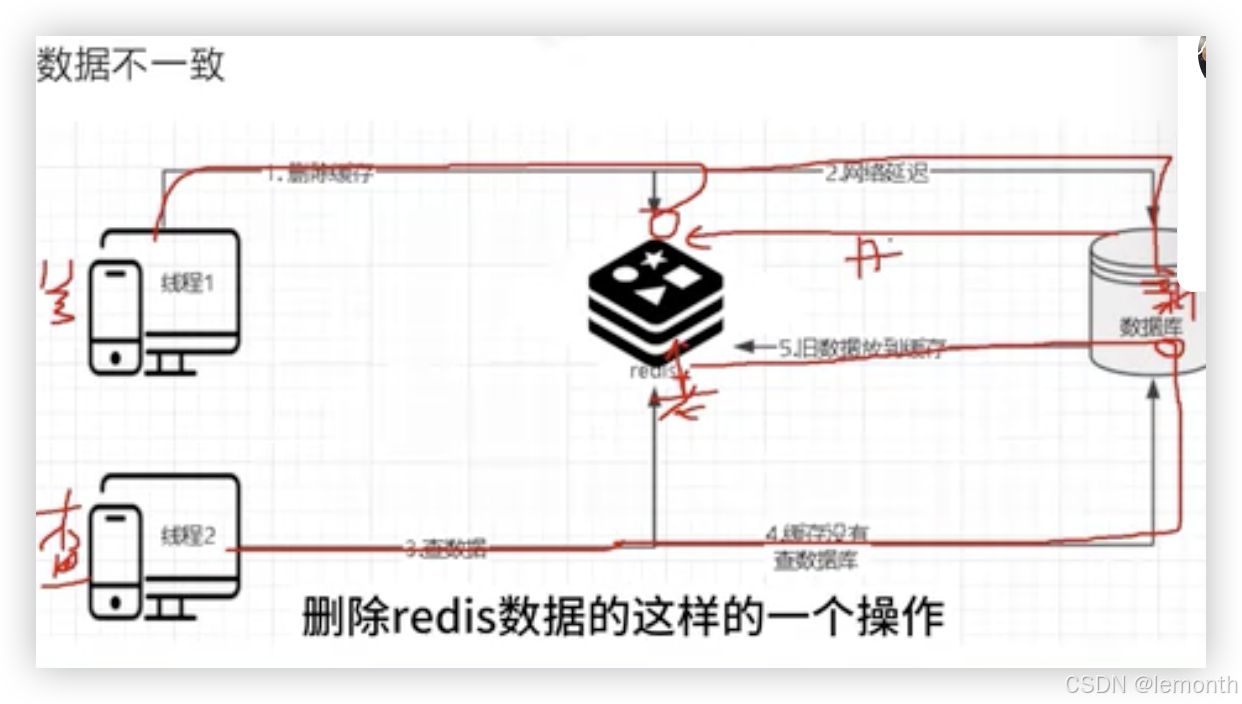
先操作mysql
只会出现一次老数据
问题:如果删除失败,可以用重试消息通知