一、什么是进程?什么是线程?
二、并发和并行
三、多线程使用场景
四、python实现多线程
五、GIL问题
一、什么是进程?什么是线程?

一个进程中可以同时处理很多事情【浏览器中可以在多个选项卡中打开多个页面,有的页面播放音乐,有的页面播放视频,可以同时运行,互补不干扰】
为什么能同时做到这麽多任务呢?
-----任务对应着线程的执行。
进程是线程的集合,进程是由一个或者多个线程构成的;
线程是操作系统进行线性调度的最小单位,是进程中一个最小运行单元。
多线程就是一个进程中同时执行多个线程。
二、并发和并行

三、多线程使用场景
在一个程序进程中,有些操作比较耗时或者需要等待,如:等待数据库的查询结果的返回;等待网页结果的返回



如果任务不全是计算密集型任务,可以使用多线程来提高程序整体的执行效率,尤其对于网络爬虫这种 10 密集型任务来说,使用多线程会大大提高程序整体的爬取效率
四、python实现多线程
在python中实现多线程的模块叫做threading是python自带的模块
import threading
import time
def target(second):print(f"线程{threading.currentThread().name} 正在运行")print(f"线程{threading.currentThread().name} sleep {second}s")time.sleep(second)print(f"线程{threading.currentThread().name} 运行结束啦")print(f"主线程{threading.currentThread().name} 正在运行")
th1=threading.Thread(target=target,args=[2])
th1.start()
#th1.join()
th2=threading.Thread(target=target,args=[5])th2.start()
#th2.join()
print(f"\n线程{threading.currentThread().name} 运行结束啦")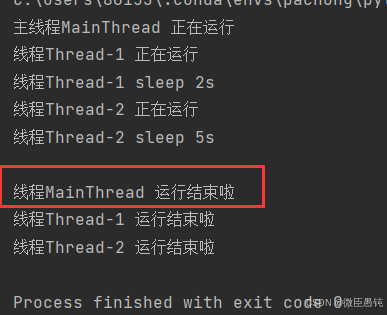
给每个子线程后添上join方法,就可以实现主线程等待所有子线程运行结束后才结束
import threading
import time
def target(second):print(f"线程{threading.currentThread().name} 正在运行")print(f"线程{threading.currentThread().name} sleep {second}s")time.sleep(second)print(f"线程{threading.currentThread().name} 运行结束啦")print(f"主线程{threading.currentThread().name} 正在运行")
th1=threading.Thread(target=target,args=[2])
th1.start()
th1.join()
th2=threading.Thread(target=target,args=[5])th2.start()
th2.join()
print(f"\n线程{threading.currentThread().name} 运行结束啦")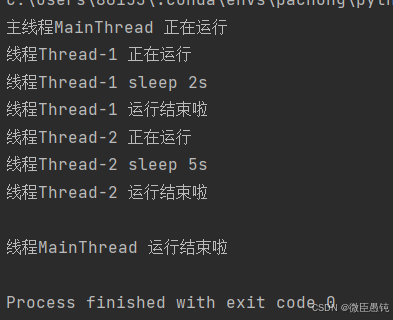
守护线程:将一个线程设置成守护线程说明这个线程不重要【如果主线程结束了守护线程还没运行完,那么这个守护线程也要被强制结束运行】,可以通过setDaemon方法设置守护线程
将线程-2设置为守护线程
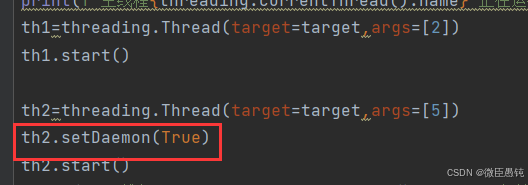
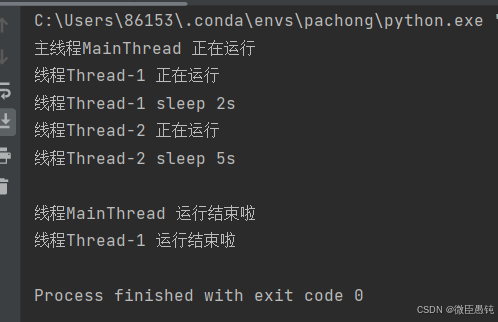
【可以看到咩有看到thread-2运行结束的消息】
为什么没有join方法了呢?因为只要有join方法,主线程都会等待子线程运行结束,无论其是否为守护线程!!!
互斥锁:
'''
互斥锁
'''
count =0 # 在一个进程中,有一个全局变量count 进行计数
class MyThread(threading.Thread):def __init__(self):threading.Thread.__init__(self)def run(self):global counttemp=count+1time.sleep(0.001) # 声明多个线程,每个线程都给count +1count = temp
threads=[]
for _ in range(1000): # 1000个线程 thread = MyThread()thread.start()threads.append(thread)
for thread in threads :thread.join()
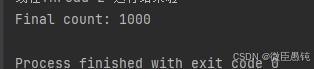
print(f'Final count: {count}') 按常理来说count的值应该是 1000,可是
![]()
为什么呢?
这是因为count这个值共享,在多线程环境中,线程的执行顺序是不可预测的,尤其是当多个线程同时访问和修改同一个共享变量时。在你的代码中,
count是一个全局变量,所有线程都会对其进行读取和修改。由于竞争条件的存在,多个线程对count的更新操作可能会相互覆盖。每次线程覆盖其他线程的结果时,count的值就会丢失一次加1的操作。
如何解决?
对多个线程进行同步,即需要对要操作的数据进行加锁保护【某个线程在对数据进行操作前,需要先加锁,这样其他的线程发现被加锁了之后,就无法继续向下执行,会一直等待锁被释放
只有加锁的线程把锁释放了,其他的线程才能继续加锁并对数据做修改,修改完了再释放锁
这样可以确保同一时间只有一个线程操作数据,多个线程不会再同时读取和修改同一个数据
最后的运行结果就是对的了】
count =0 # 在一个进程中,有一个全局变量count 进行计数
class MyThread(threading.Thread):def __init__(self):threading.Thread.__init__(self)def run(self):global countlock.acquire() # 进行加锁temp=count+1time.sleep(0.001) # 声明多个线程,每个线程都给count +1count = templock.release()
threads=[]
lock = threading.Lock()
for _ in range(1000): # 1000个线程thread = MyThread()thread.start()threads.append(thread)
for thread in threads :thread.join()
print(f'Final count: {count}')此时,运行结果count为 1000
五、GIL问题
GIL全称为 GlobalInterpreter Lock,译为全局解释器锁,GIL 是 Python 解释器(CPython)的一个机制,用于确保同一时刻只有一个线程可以执行 Python 字节码。它的主要目的是保护 Python 的内存管理和其他内部数据结构的线程安全。

GIL 的存在意味着即使在多线程环境中,同一时刻也只有一个线程可以执行 Python 代码。因此,对于 CPU 密集型任务,多线程并不能带来性能提升,因为 GIL 限制了多个线程同时执行代码。然而,对于 I/O 密集型任务【如爬虫】,GIL 的影响较小。