一、研究背景介绍
糖尿病是美国最普遍的慢性病之一,每年影响数百万美国人,并对经济造成重大的经济负担。糖尿病是一种严重的慢性疾病,其中个体失去有效调节血液中葡萄糖水平的能力,并可能导致生活质量和预期寿命下降。。。。糖尿病也给经济带来了巨大的负担,诊断出的糖尿病成本约为88亿美元,未诊断的糖尿病和糖尿病前期的总成本每年接近1亿美元。本案例分析针对糖尿病数据集进行探索和分析:
二、实证分析
首先,导入需要的基础包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号
import seaborn as sns
读取数据文件,展示数据前15行
数据和代码
df=pd.read_csv('diabetes_data.csv')
df.head(15)
查看数据类型和形状
df.shape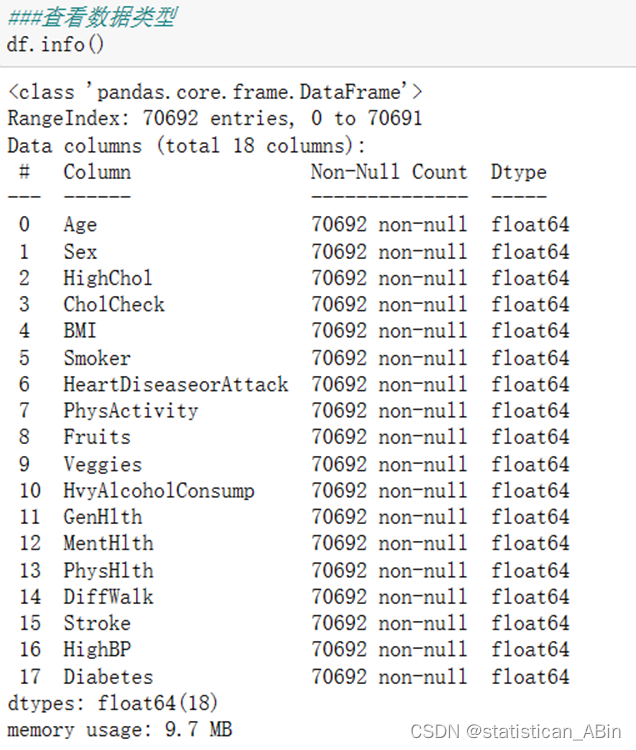
###发现数据量为七万多行,17个特征,各项特征介绍如下:
###各项特征名称
年龄:13级年龄组(_AGEG5YR见密码本)
1 = 18-24 / 2 = 25-29 / 3 = 30-34 / 4 = 35-39 / 5 = 40-44 / 6 = 45-49 / 7 = 50-54 / 8 = 55-59 / 9 = 60-64 / 10 = 65-69 / 11 = 70-74 / 12 = 75-79 / 13 = 80 岁或以上
Sex:患者性别(1:男;0:女)
HighChol:0 = 无高胆固醇 1 = 高胆固醇
CholCheck:0 = 5 年内未进行胆固醇检查 1 = 5 年内进行了胆固醇检查
BMI:身体质量指数
吸烟者:您一生中至少吸过 100 支香烟吗? [注:5 包 = 100 支香烟] 0 = 否 1 = 是
心脏病或发作:冠心病 (CHD) 或心肌梗塞 (MI) 0 = 否 1 = 是
PhysActivity:过去 30 天的身体活动 - 不包括工作 0 = 否 1 = 是
水果:每天吃水果 1 次或更多次 0 = 否 1 = 是
蔬菜:每天吃蔬菜 1 次或更多次 0 = 否 1 = 是
HvyAlcoholConsump:(成年男性每周 >=14 杯,成年女性每周 >=7 杯)0 = 否 1 = 是
GenHlth:总体而言,您的健康状况是: 等级 1-5 1 = 极好 2 = 非常好 3 = 好 4 = 一般 5 = 差
MentHlth:心理健康状况不佳的天数 1-30 天
PhysHlth:过去 30 天的身体疾病或受伤天数 1-30
DiffWalk:你走路或爬楼梯有严重困难吗? 0 = 否 1 = 是
中风:您曾经中风。 0 = 否,1 = 是
HighBP:0 = 不高,BP 1 = 高 BP
糖尿病:0 = 无糖尿病,1 = 糖尿病
进行基本的统计性描述分析
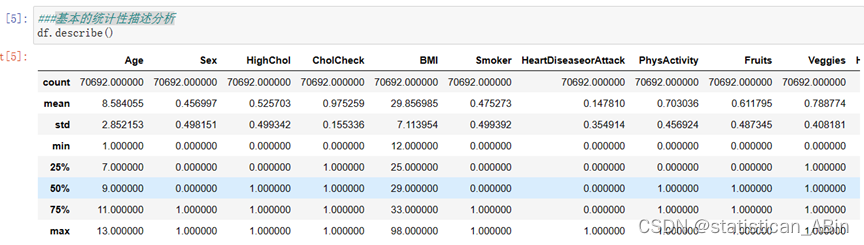
从上面结果可以看出,从描述中,我们观察到BMI,PhysHlth,MentHlth的标准差高于1,
最大值和最小值之间的差异相对较高,因此我们将使用max-min归一化来规范化它们。接下来查看缺失值

import missingno as msno
msno.matrix(df)
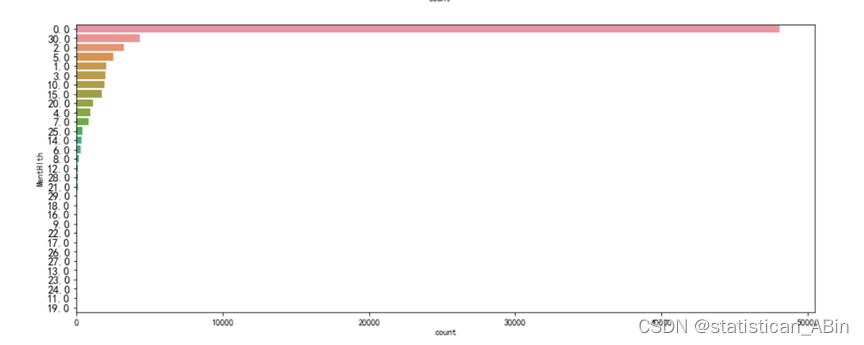
对特征分别进行可视化一下 比如各个特征的占比情况等等
import seaborn as sb
for i in df.columns:fig, ax = plt.subplots(1,1, figsize=(15, 6))sb.countplot(y = df[i],data=df, order=df[i].value_counts().index)plt.ylabel(i)plt.yticks(fontsize=13)plt.show() 


# 接下来使用groupby函数对响应变量可视化
grouped['BMI'].plot(kind='bar')
plt.title('Average BMI by Gender')
plt.xlabel('Gender')
plt.ylabel('Average BMI')
plt.show()
接下来使用热力图看一下特征之间的相关系数
plt.figure(figsize=(15,10))
sb.heatmap(df.corr(), annot=True)
plt.show()
从上面热力图可以看出,最大相关性在0.38左右
再画出具体特征的分布

分别画出响应变量糖尿病与其他特征的关系
fig, ax = plt.subplots(5, 4, figsize=(15,15))
k = 0
for i in range(5):for j in range(4):if k >= len(df.keys()):continuecol = data.keys()[k]if col=='BMI' or col=='MentHlth' or col=='PhysHlth':sb.kdeplot(data=df, x=col, hue='Diabetes', ax=ax[i,j])else:sb.histplot(data=df, x=col, hue='Diabetes', ax=ax[i,j])k += 1
plt.tight_layout()
plt.show() 
我们将尝试使用一些不同的模型来对两个目标类之间的数据进行分类。最后,我们将选择更好的模型。
我们希望在两个目标类别中都尽可能获得更好的结果。
在这个健康问题中,减少真正糖尿病患者的数量非常重要,但被归类为健康。
# 接下来进行标准化
df1 = df
cols = ['BMI', 'PhysHlth']
for i in cols:df1[i] = (df1[i] - df1[i].min()) / (df1[i].max() - df1[i].min())####划分训练集和验证集
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
print('Non normalized dataset')
x_train, x_test, y_train, y_test= train_test_split(x,y,test_size=0.25,random_state=101)
print('Training: ', x_train.shape[0])
print('Test: ', x_test.shape[0])
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)print('Normalized dataset')
x_train1, x_test1, y_train1, y_test1 = train_test_split(x1,y1,test_size=0.25,random_state=101)
print('Training: ', x_train1.shape[0])
print('Test: ', x_test1.shape[0])KNN模型预测
knn.fit(x_train1, y_train1)y_pred = knn.predict(x_test1)
exec1.append(time.time() - st)
cm = confusion_matrix(y_test1, y_pred)
print(cm)
print('\n')
print(classification_report(y_test1,y_pred))
print(accuracy_score(y_test1, y_pred))
accuracy1.append(accuracy_score(y_test1, y_pred))
使用其他模型试一下


从以上结果可以看出,自适应提升Adaboost模型的效果还可以,达到了0.7486.其次是极端梯度提升,KNN以及最后的决策树。
三、小结
在这个项目中,我运用了机器学习的模型来预测一个人是否患有糖尿病,使用的模型包括自适应提升(AdaBoost)、K最近邻(KNN)和决策树(Decision Tree)等。通过对不同算法的比较和分析,最终发现自适应提升最优的算法来进行预测,并根据预测结果来制定相应的医疗干预措施,以帮助预防和治疗糖尿病。