K-means算法是经典的基于划分的聚类方法
基本思想是以空间中的k个点为中心进行聚类,对最靠近它们的对象归类,类别数为k。不断迭代,逐次更新各聚类中心的值,直至得到最好的聚类结果。
各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。该算法的最大优势在于简洁和快速,算法的关键在于预测可能分类的数量以及初始中心和距离公式的选择。
图像分割即把图像分割成若干不相交的区域,实质是像素的聚类过程,是图像处理的一种方法。这里利用opencv2实现k-means
cv2.kmeans(data, K, bestLabels, criteria, attempts, flags)
首先先进行导入所需的库和包,cv2中包含了我们需要调用的api

对灰度图像进行分割
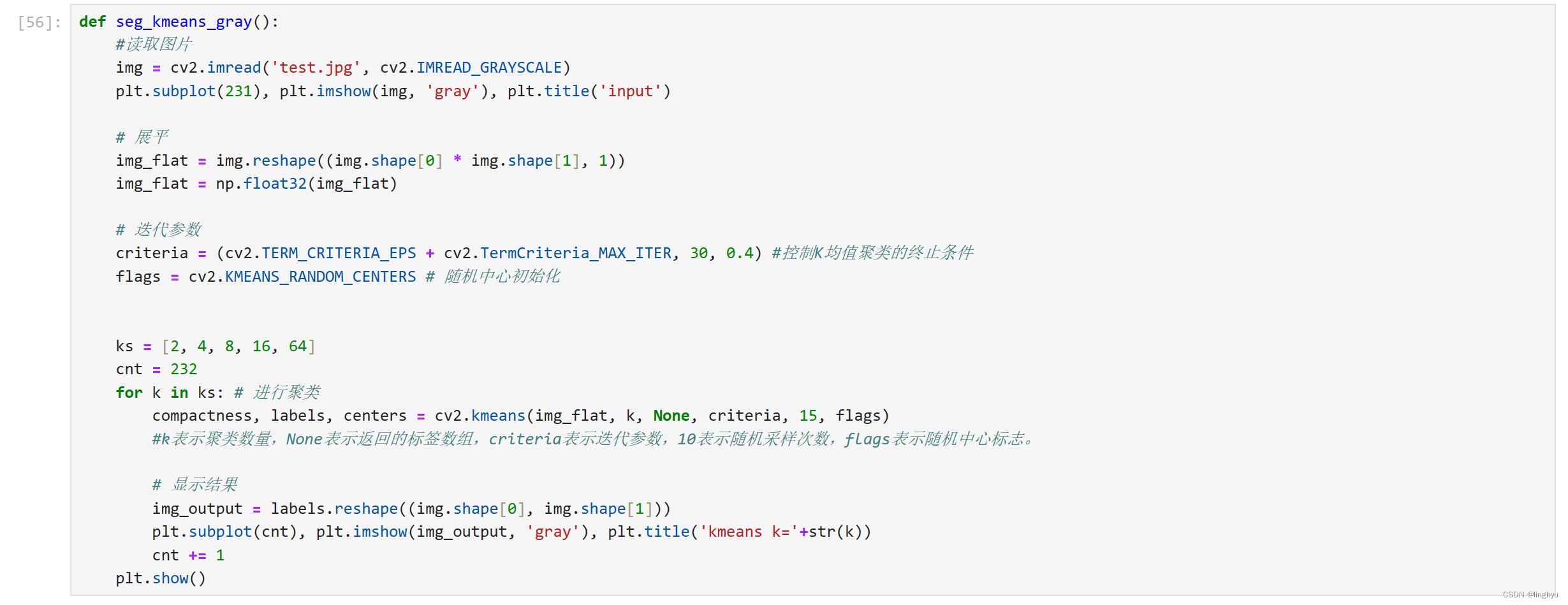
定义一个名为seg_kmeans_gray的函数,用于实现K均值聚类图像分割。
图片读取:
img = cv2.imread('test.jpg', cv2.IMREAD_GRAYSCALE) plt.subplot(231), plt.imshow(img, 'gray'), plt.title('input')使用cv2.imread函数读取图片,并将其转换为灰度图像。cv2.IMREAD_GRAYSCALE表示以灰度模式读取图片。plt.subplot和plt.imshow函数用于显示原始图像。
图像展平:
img_flat = img.reshape((img.shape[0] * img.shape[1], 1))img_flat = np.float32(img_flat)使用img.reshape函数将图像展平为一维数组,以便进行聚类。img.shape[0] * img.shape[1]表示图像的像素总数,1表示将图像转换为一维数组。np.float32将数组转换为浮点数类型,以便进行K均值聚类。
迭代参数及初始化:
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TermCriteria_MAX_ITER, 30, 0.4)flags = cv2.KMEANS_RANDOM_CENTERS定义一个迭代参数criteria,用于控制K均值聚类的终止条件。cv2.TERM_CRITERIA_EPS + cv2.TermCriteria_MAX_ITER表示当聚类中心的变化小于0.6时停止迭代。30表示最大迭代次数。0.6表示聚类中心的变化阈值。
定义一个随机中心标志flags,用于指定K均值聚类的初始化方法。cv2.KMEANS_RANDOM_CENTERS表示随机选择聚类中心。
进行聚类:
compactness, labels, centers = cv2.kmeans(img_flat, k, None, criteria, 15, flags)使用cv2.kmeans函数对图像进行K均值聚类。img_flat表示展平后的图像一维数组,k表示聚类数量,None表示返回的标签数组,criteria表示迭代参数,15表示随机采样次数,flags表示随机中心标志。
以下是完整代码截图:
代码执行结果:

对彩色图像进行聚类
同样的导入图片:
img = cv2.imread('test.png', cv2.IMREAD_COLOR)plt.subplot(231), plt.imshow(img), plt.title('input')变换图像通道bgr->rgb:
b, g, r = cv2.split(img)
img = cv2.merge([r, g, b])使用cv2.imread函数读取图片,并将其转换为灰度图像。cv2.IMREAD_COLOR表示以彩色模式读取图片。plt.subplot和plt.imshow函数用于显示原始图像。
3个通道展平:
img_flat = img.reshape((img.shape[0] * img.shape[1], 3))
img_flat = np.float32(img_flat)将图像的BGR通道转换为RGB通道。cv2.split函数将图像拆分为三个通道,然后使用cv2.merge函数将它们重新组合为RGB图像。将图像展平为一维数组,img.reshape函数将图像展平为一维数组,img.shape[0] * img.shape[1]表示图像的像素总数,3表示将图像转换为一维数组。np.float32将数组转换为浮点数类型,以便进行K均值聚类。
迭代参数及初始化:
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TermCriteria_MAX_ITER, 30, 0.6)定义一个迭代参数criteria,用于控制K均值聚类的终止条件。cv2.TERM_CRITERIA_EPS + cv2.TermCriteria_MAX_ITER表示当聚类中心的变化小于0.6时停止迭代。30表示最大迭代次数。0.6表示聚类中心的变化阈值。
进行聚类:
compactness, labels, centers = cv2.kmeans(img_flat, k, None, criteria, 15, flags)img_flat表示展平后的图像一维数组,k表示聚类数量,None表示返回的标签数组,criteria表示迭代参数,15表示随机采样次数,flags表示随机中心标志。
以下是完整代码截图:

函数代码执行结果:
