Lab1: Xv6 and Unix utilities
文章目录
- Lab1: Xv6 and Unix utilities
- 实验任务
- 1.启动XV6(easy)
- 2.Sleep(easy)-练手的,就是熟悉一下怎么在xv6项目中加.c文件,生成可执行程序并进行测试的
- 1.解析rm.c
- 2.argc 如何被赋值
- 3.Sleep代码
- 4.makefile编辑
- 5.通过make qemu生成sleep并执行
- 6.测试sleep
- 3. pingpong(难度:Easy)
- 1.注意
- 2.代码
- 3.make qemu
- 4.pingpong命令执行
- 5. 测试该命令 ./grade-lab-util pingpong
- 4.Primes(素数,难度:Moderate/Hard)
- 1.思路
- 难点:
- 注意:
- 2.代码
- 3.make qemu
- 4.primes执行
- 5.测试该命令 ./grade-lab-util primes
- 5.find(难度:Moderate)
- 1.ls.c解析
- 2.代码
- 难点讲解
- 0.问题:p++后不应该去到了无效地址吗?为什么de.name还可以赋值给p?p[strlen(de.name)] = 0;这句话是在干什么?
- 1. buf 数组的定义
- 2. 计算指针 p
- 3. 插入路径分隔符
- 4. 内存管理
- 5. 再次拼接 de.name
- 结论
- 3.make qemu
- 4.find执行
- 5.测试该命令 ./grade-lab-util find
- 6.xargs(难度:Moderate)
- 1.思路
- 2.代码
- 3.make qemu
- 4.xargs执行
- 5.测试该命令 ./grade-lab-util xargs
- image-20241122194130827
实验任务
1.启动XV6(easy)
安装xv6和qemu部分请看环境搭建部分Mit6.S081-实验环境搭建_mit 6.s081-CSDN博客
启动qemu
执行ls命令

2.Sleep(easy)-练手的,就是熟悉一下怎么在xv6项目中加.c文件,生成可执行程序并进行测试的
实现xv6的UNIX程序sleep:您的sleep应该暂停到用户指定的计时数。一个滴答(tick)是由xv6内核定义的时间概念,即来自定时器芯片的两个中断之间的时间。您的解决方案应该在文件user/sleep.c中
提示:
- 在你开始编码之前,请阅读《book-riscv-rev1》的第一章
- 看看其他的一些程序(如**/user/echo.c, /user/grep.c, /user/rm.c**)查看如何获取传递给程序的命令行参数
- 如果用户忘记传递参数,
sleep应该打印一条错误信息 - 命令行参数作为字符串传递; 您可以使用
atoi将其转换为数字(详见**/user/ulib.c**) - 使用系统调用
sleep - 请参阅kernel/sysproc.c以获取实现
sleep系统调用的xv6内核代码(查找sys_sleep),user/user.h提供了sleep的声明以便其他程序调用,用汇编程序编写的user/usys.S可以帮助sleep从用户区跳转到内核区。 - 确保
main函数调用exit()以退出程序。 - 将你的
sleep程序添加到Makefile中的UPROGS中;完成之后,make qemu将编译您的程序,并且您可以从xv6的shell运行它。 - 看看Kernighan和Ritchie编著的《C程序设计语言》(第二版)来了解C语言。
1.解析rm.c
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
- 这三行代码引入了必要的头文件。其中:
- kernel/types.h 包含了基本数据类型的定义。
- kernel/stat.h 包含了文件状态的信息。
- user/user.h 包含了用户级别的函数和常量,包括输出和进程控制的相关功能。
int main(int argc, char *argv[]){
- 这里定义了main函数,argc表示命令行参数的数量,argv是一个字符串数组,用来保存每个参数的值。
int i; if(argc < 2){ fprintf(2, "Usage: rm files...\n"); exit(1); }
- 定义了一个整数变量i用于循环。
- 接下来检查命令行参数的数量。如果传入的参数数量少于2(即程序名加上至少一个文件名),则打印出用法提示信息到标准错误输出,并以状态码1退出程序。
for(i = 1; i < argc; i++){ if(unlink(argv[i]) < 0){ fprintf(2, "rm: %s failed to delete\n", argv[i]); break; } }
- 这个循环从1开始遍历传入的文件名参数(argv[0]是程序名,argv[1]是第一个要删除的文件名)。
- unlink系统调用用于删除指定的文件名。如果unlink返回的结果小于0,表示删除文件失败,则在标准错误输出中打印出相应的错误信息,并跳出循环。
exit(0);}
- 最后,调用exit(0)正常退出程序,状态码0表示程序执行成功。
总结
这段代码实现了一个基本的文件删除功能,类似于Unix/Linux系统中的rm命令。它首先检查输入参数的有效性,然后尝试逐个删除指定的文件。如果某个文件的删除操作失败,会输出错误信息并结束程序。
2.argc 如何被赋值
argc 的值是由操作系统的 shell(命令行解释器)给赋值的。
具体过程如下:
argc 如何被赋值
- 用户输入命令:当你在命令行中输入一个命令(例如 ./rm file1.txt file2.txt file3.txt)并按下回车,shell 开始处理你输入的命令。
- 解析命令:shell 解析你输入的字符串,将其分解成程序名和参数。它将程序名(./rm)和所有后续的参数(file1.txt、file2.txt、file3.txt)提取出来。
- 构建参数列表:
- argc 被设置为参数的总数,包括程序名。
- argv被构建为一个指针数组,其中每个元素指向相应的字符串:
- argv[0]: ./rm
- argv[1]: file1.txt
- argv[2]: file2.txt
- argv[3]: file3.txt
- 创建进程:shell 使用系统调用(通常是 exec 系列的函数)来创建一个新的进程,并将 argc 和 argv 参数传递给它。这些参数传递给程序的入口点(即 main 函数)。
- 程序开始执行:当新的进程启动后,它的 main 函数会使用 argc 和 argv 来访问命令行传递的参数。
示例
例如,你在终端中输入的完整命令:
./rm file1.txt file2.txt file3.txt
操作系统中的处理流程可以描述为:
- argc 被设置为 4(因为有 4 个参数:./rm、file1.txt、file2.txt、file3.txt)。
- argv被设置为一个数组,有 4 个元素:
- argv[0] = ./rm
- argv[1] = file1.txt
- argv[2] = file2.txt
- argv[3] = file3.txt
3.Sleep代码
根据提示写就行,注意要把sleep.c放到user目录下
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"int main(int argc,char *argv[])
{if(argc!=2){//在标准输出,输出错误信息fprintf(2,"sleep命令缺少参数\n");exit(1);}int sec=atoi(argv[1]);sleep(sec);exit(0);
}
4.makefile编辑
152行处加上$U/_sleep\
作用是通过make qemu生成可执行文件sleep的
5.通过make qemu生成sleep并执行
执行

6.测试sleep
在xv6目录下执行命令
./grade-lab-util sleep

如果出现

把grade-lab-util第一行的python改成python3即可
#!/usr/bin/env python3
3. pingpong(难度:Easy)
1.注意
1.在父子进程中要关闭两个管道不用的一端
2.父子进程都要把两个管道全部关闭
3.打印的信息冒号后面有个空格,不打会报错
2.代码
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"int main(int argc,char *argv[])
{int p1[2];//父到子方向int p2[2];//子到父方向pipe(p1);pipe(p2);char *buffer="buffer";if(argc!=1){printf("pingpong命令有多余的参数");}if(fork()==0){close(p1[1]);close(p2[0]);if(read(p1[0],&buffer,sizeof(char))!=1){printf("子进程读错误\n");exit(0);}if(write(p2[1],&buffer,sizeof(char))!=1){printf("子进程写错误\n");exit(0);}else{printf("%d: received ping\n",getpid());exit(0);}close(p1[0]);close(p2[1]);}else{close(p1[0]);close(p2[1]);if(write(p1[1],&buffer,sizeof(char))!=1){printf("父写进程写错误\n");exit(0);}if(read(p2[0],&buffer,sizeof(char))!=1){printf("父进程读错误\n");exit(0);}else{printf("%d: received pong\n",getpid());exit(0);}close(p1[1]);close(p2[0]);}exit(0);
}3.make qemu
4.pingpong命令执行

5. 测试该命令 ./grade-lab-util pingpong

4.Primes(素数,难度:Moderate/Hard)
1.思路
考虑所有小于1000的素数的生成。Eratosthenes的筛选法可以通过执行以下伪代码的进程管线来模拟:
p = get a number from left neighbor
print p
loop:n = get a number from left neighborif (p does not divide n)send n to right neighbor
p = 从左邻居中获取一个数
print p
loop:n = 从左邻居中获取一个数if (n不能被p整除)将n发送给右邻居
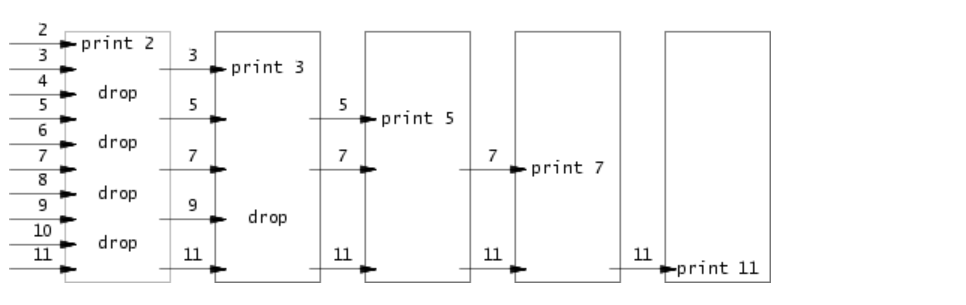
文档中的这个资料很重要,需要好好理解
在这里就是用一个递归函数去实现它的loop循环操作
每一层递归函数就是一个子进程,即就把图上的方框当做一层递归函数或者一个子进程
每一个子进程做的事情就是把自己进程的管道内的数字进行筛选,用第一个数筛选剩下的其他数字
比如在第一个子进程就是用2筛选2-11,只要是2的倍数就给剔除,所以在子进程的子进程就只剩下了3,5,7,9,11
再用3筛选剩下的四个数字就好
难点:
1.我如何存储2,3,4,5,6,…35这些数字?
用管道存储,管道可以看做一个文件,在linux系统中最大可以放65536字节,存几个数字还是轻轻松松的
2.对不用的管道的读端或者写端要关闭,在什么时候关闭
这个看下面代码部分
3.那我递归函数的终止条件又是什么呢?
管道里面没有数字了,那这个进程就结束了,因为我们不需要再次创建子进程进行筛选了
注意:
递归函数所有代码执行完了要在结尾加上exit(0)作为子进程的结束
2.代码
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"//无限递归报错时添加
__attribute__((noreturn))
void dfs(int p[2])
{close(p[1]);int num;//读第一个数//读到数字才会继续往下执行,否则不执行 if(read(p[0],&num,sizeof(int))==sizeof(int)){printf("prime %d\n",num);}else{exit(0);}int son_fork_p[2];pipe(son_fork_p);int res;//用第一个数字筛选其他的数字,满足条件才会写进子进程的管道while(read(p[0],&res,sizeof(int))==sizeof(int)){if(res%num!=0){write(son_fork_p[1],&res,sizeof(int));}}close(son_fork_p[1]);close(p[0]);//给子进程传入筛选后的管道if(fork()==0){dfs(son_fork_p);}else{close(son_fork_p[0]);wait(0);}//不要忘记这个,我们需要结束子进程exit(0);
}int main(int argc,int argv[])
{if(argc!=1){printf("不必要的参数,参数过多\n");exit(0);}int p[2];pipe(p);int i;for(i=2;i<=35;i++){write(p[1],&i,sizeof(int));}//调用递归函数if(fork()==0){dfs(p);}else{close(p[1]);close(p[0]);wait(0);}exit(0);
}3.make qemu
如果碰到无限递归的错误,那就在dfs前加个
_attribute_((noreturn)) 就行
4.primes执行

5.测试该命令 ./grade-lab-util primes

5.find(难度:Moderate)
1.ls.c解析
struct dirent {ushort inum;//索引,可以通过这个找到具体的文件信息char name[DIRSIZ];//文件名
};
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"//这个 fmtname 函数的主要功能是将给定的路径字符串格式化成一个指定长度的名称(这里的DIRSIZ是14),具体是将路径中最后一个斜杠后的部分提取出来并进行处理
char*
fmtname(char *path)
{static char buf[DIRSIZ+1];char *p;// p从path末尾从后往前遍历,将p移动到碰到的第一个'/'的位置for(p=path+strlen(path); p >= path && *p != '/'; p--);//移动到最后的文件名的开头的部分 后面就是具体的文件名了p++;// 如果文件名大小比DIRSIZ大的话那就直接用p就行,如果大小比DIRSIZ小的话,那缺少的部分就用空格补齐,下面的代码就干这个事情if(strlen(p) >= DIRSIZ)return p;memmove(buf, p, strlen(p));memset(buf+strlen(p), ' ', DIRSIZ-strlen(p));return buf;
}//ls的具体功能实现 大体是先看是不是文件,是文件就输出详细信息,是目录就遍历它所有的子目录显示具体的信息
void
ls(char *path)
{char buf[512], *p;int fd;//存储目录项struct dirent de; //存储文件信息的结构体struct stat st;//打开pathif((fd = open(path, 0)) < 0){fprintf(2, "ls: cannot open %s\n", path);return;}//把fd所指文件的信息(大小,名称,类型之类的)存储到st结构体中if(fstat(fd, &st) < 0){fprintf(2, "ls: cannot stat %s\n", path);close(fd);return;}switch(st.type){//普通文件case T_FILE:printf("%s %d %d %l\n", fmtname(path), st.type, st.ino, st.size);break;//目录case T_DIR:if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){printf("ls: path too long\n");break;}//移动p到buf的末尾,方便后续拼接路径,通俗的说就是往输入路径后面加了个/strcpy(buf, path);p = buf+strlen(buf);*p++ = '/';//如果是目录(T_DIR),则使用 read 函数读取目录中的每个目录项,利用 struct dirent 读取信息,并进行处理。while(read(fd, &de, sizeof(de)) == sizeof(de)){if(de.inum == 0)continue;//将目录项名称复制到 buf 中,这样可以构建文件路径memmove(p, de.name, DIRSIZ);p[DIRSIZ] = 0;//对每个目录项,使用 stat 获取状态信息,如文件类型、inode 和大小。if(stat(buf, &st) < 0){printf("ls: cannot stat %s\n", buf);continue;}printf("%s %d %d %d\n", fmtname(buf), st.type, st.ino, st.size);}break;}close(fd);
}int
main(int argc, char *argv[])
{int i;//默认是当前目录if(argc < 2){ls(".");exit(0);}//可以一条命令查询多个文件或者目录的状态for(i=1; i<argc; i++)ls(argv[i]);exit(0);
}
感觉这个最多可以搞abcd/abd.c这种目录的,ab/abcd/abd.c估计就不太行了,因为没有递归。
2.代码
大多数都是ls.c里面的代码,功能一样的就不说了,其他的主要看注释把
#include "kernel/types.h"
#include "kernel/fcntl.h"
#include "kernel/stat.h"
#include "kernel/fs.h"
#include "user/user.h"/*将路径格式化为文件名,就是提取路径中的文件名
*/
char* fmt_name(char *path){static char buf[DIRSIZ+1];char *p;// Find first character after last slash.for(p=path+strlen(path); p >= path && *p != '/'; p--);p++;memmove(buf, p, strlen(p)+1);return buf;
}
/*系统文件名与要查找的文件名,若一致,打印系统文件完整路径
*/
void eq_print(char *fileName, char *findName){if(strcmp(fmt_name(fileName), findName) == 0){printf("%s\n", fileName);}
}
/*在某路径中查找某文件
*/
void find(char *path, char *findName){int fd;struct stat st; if((fd = open(path, O_RDONLY)) < 0){fprintf(2, "find: cannot open %s\n", path);return;}if(fstat(fd, &st) < 0){fprintf(2, "find: cannot stat %s\n", path);close(fd);return;}char buf[512], *p; struct dirent de;switch(st.type){ case T_FILE:eq_print(path, findName); break;case T_DIR:if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){printf("find: path too long\n");break;}strcpy(buf, path);p = buf+strlen(buf);*p++ = '/';while(read(fd, &de, sizeof(de)) == sizeof(de)){if(de.inum == 0 ||strcmp(de.name, ".")==0 || strcmp(de.name, "..")==0)continue;//把新得到的子目录拼接到buf后面//比如我们的find . b,就是在./后面拼接了a,然后在递归中传入的是./amemmove(p, de.name, strlen(de.name));p[strlen(de.name)] = 0;find(buf, findName);}break;}close(fd);
}int main(int argc, char *argv[]){if(argc < 3){printf("find: find <path> <fileName>\n");exit(0);}find(argv[1], argv[2]);exit(0);
}难点讲解
0.问题:p++后不应该去到了无效地址吗?为什么de.name还可以赋值给p?p[strlen(de.name)] = 0;这句话是在干什么?
char buf[512], *p;
...
strcpy(buf, path);
p = buf + strlen(buf);
*p++ = '/';
1. buf 数组的定义
- char buf[512]; 定义了一个字符数组 buf,大小为 512 字节。
- 该数组用于存储路径名。
2. 计算指针 p
- strcpy(buf, path); 将路径 path 复制到 buf 中。
- p = buf + strlen(buf); 设置指针 p 指向 buf 的末尾(即原始字符串的末尾)。
3. 插入路径分隔符
- *p++ = ‘/’; 在 buf 的末尾添加了一个斜杠 /,并将指针 p 移动到下一个位置。此时,p 指向了 buf 中新添加的 / 的下一个位置。
4. 内存管理
此时,buf 中的内容如下(假设 path 是 “.”):
- buf 的内容为 “./”,即字符串结束后有一个斜杠 /。
5. 再次拼接 de.name
memmove(p, de.name, strlen(de.name));
p[strlen(de.name)] = 0;
- memmove(p, de.name, strlen(de.name)); 将目录项的名称 de.name 复制到 p 指向的内存地址。这是有效的,因为 p 在这里指向 buf 的末尾,即 ‘/’ 之后的位置,足够容纳 de.name 的字符串。
- 复制后,紧接着通过 p[strlen(de.name)] = 0; 在 p 后面添加一个空字符 ‘\0’,以正确地终止这个拼接后的字符串,使其成为一个有效的 C 字符串。
结论
- 在这段代码中没有出现内存访问错误,因为 buf 数组是充分分配的(大小为 512 字节),并且 p 最初被设置为指向数组 buf 的有效内存区域的末尾。
- 通过指针管理,程序能够在原有路径后面正确拼接额外的目录名 de.name。
3.make qemu
注:qemu会保留上次的结果,更改find.c以后最好make clean一下再make qemu,不然有可能一直报错
4.find执行

5.测试该命令 ./grade-lab-util find

6.xargs(难度:Moderate)
1.思路
笔者真是一点头绪也没有,这个是转载自这位大佬MIT 6.S081 Operating System - 知乎
第五个utility是xargs. 将标准输入里每一个以’\n’分割的行作为单独1个额外的参数, 传递并执行下一个命令. 这题主要感觉是考察fork + exec的使用. 但真正实现的时候, 麻烦点在于滑动窗口buffer的管理. 有以下这几个点需要思考的:
# 1. 什么时候知道不会有更多的行输入了?
当从file descriptor 0读的时候, 读到返回值为0# 2. 怎么能抓出每一个以'\n'分割的行?
我们不能方便地从file descriptor里读到空行符为止, xv6没有这样的库函数支持.
我们需要自己管理一个滑动窗口buffer, 如下:假设我们有1个长度为10的buffer, 以 . 代表为空
buf = [. . . . . . . . . .]
我们read(buf, 10)读进来6个bytes
buf = [a b \n c d \n . . . .]这时我们需要做的是,
1. 找到第一个'\n'的下标, 用xv6提供的strchr函数, 得到下标为2
2. 把下标0~1的byte转移到另一个buffer去作为额外参数
3. 执行fork+exec+wait组合拳去执行真正执行的程序, 使用我们parse出来的额外的参数
4. 修建我们的buffer, 把0~2的byte移除, 把3~9的byte移到队头
此时buffer变成:
buf = [c d \n . . . . . . .]# 3. 上述操作要一直循环直到
file descriptor 0 已经关闭了 && buffer里的所有读入的bytes都处理完了
2.代码
#include "kernel/param.h"
#include "kernel/types.h"
#include "user/user.h"#define buf_size 512int main(int argc, char *argv[]) {char buf[buf_size + 1] = {0};uint occupy = 0;char *xargv[MAXARG] = {0};int stdin_end = 0;for (int i = 1; i < argc; i++) {xargv[i - 1] = argv[i];}while (!(stdin_end && occupy == 0)) {// try read from left-hand programif (!stdin_end) {int remain_size = buf_size - occupy;int read_bytes = read(0, buf + occupy, remain_size);if (read_bytes < 0) {fprintf(2, "xargs: read returns -1 error\n");}if (read_bytes == 0) {close(0);stdin_end = 1;}occupy += read_bytes;}// process lines readchar *line_end = strchr(buf, '\n');while (line_end) {char xbuf[buf_size + 1] = {0};memcpy(xbuf, buf, line_end - buf);xargv[argc - 1] = xbuf;int ret = fork();if (ret == 0) {// i am childif (!stdin_end) {close(0);}if (exec(argv[1], xargv) < 0) {fprintf(2, "xargs: exec fails with -1\n");exit(1);}} else {// trim out line already processedmemmove(buf, line_end + 1, occupy - (line_end - buf) - 1);occupy -= line_end - buf + 1;memset(buf + occupy, 0, buf_size - occupy);// harvest zombieint pid;wait(&pid);line_end = strchr(buf, '\n');}}}exit(0);
}
3.make qemu

4.xargs执行

5.测试该命令 ./grade-lab-util xargs

最后,笔者比较菜,完成的时间大概在10h以上了。磨叽磨叽再加上中间有个javaweb考试,不知道隔了多久了才完成,有些.c程序也是真的没有头绪,所以还是得继续努力,大家加油。