从 Llama 1 到 3.1:Llama 模型架构演进详解
原创
编者按:面对 Llama 模型家族的持续更新,您是否想要了解它们之间的关键区别和实际性能表现?本文将探讨 Llama 系列模型的架构演变,梳理了 Llama 模型从 1.0 到 3.1 的完整演进历程,深入剖析了每个版本的技术创新,还通过实际实验对比了 Llama 2 和 Llama 3 在推理速度、答案长度和相对答案质量(RAQ)等关键指标上的表现差异。
根据本文, Llama 模型的架构演变主要经历了以下三个阶段:
- Llama 1:基于原始 Transformer 架构,引入了预归一化、RMSNorm、SwiGLU 激活函数和旋转式位置编码等改进,提升了模型的训练稳定性和性能。
- Llama 2:在 Llama 1 的基础上,将上下文长度扩展至 4096,并引入了分组查询注意力 (GQA) 机制,有效降低了推理过程中的内存需求,提升了推理速度。
- Llama 3:进一步将 GQA 应用于小型模型,并采用更高效的分词器 TikToken,扩大了词汇表的数量,同时将上下文长度翻倍,并大幅增加了训练数据量。
目录
01 Introduction
02 Llama: A Family of Open LLMs
2.1 Llama 1:该系列首个模型问世
2.2 Llama 2:Llama 1 的升级版
2.3 Llama 3: Size and Tokenization
2.4 Llama 3.1
03 Llama 2 与 Llama 3:模型比较
04 Conclusions
References

01
Introduction
Meta 公司推出了其大语言模型 Llama 的三个主要版本。Llama 在 2023 年初的首度亮相,为开源自然语言处理(NLP)社区带来了重大突破。Meta 一直通过分享最新的模型版本,为这一社区贡献力量。
**在这里,我们需要区分“开放型(open) LLM”与“开源(open-source) LLM”。**传统上,开源软件会在特定的公共许可证下公开源代码,允许用户使用和修改。在 LLM 领域,开放型 LLM 会公开模型权重和初始代码,而开源 LLM 则会更进一步,在宽松的许可下共享整个训练过程,包括训练数据。目前,包括 Meta 的 Llama 在内的多数模型,都属于开放型 LLM,因为它们并未公开用于训练的数据集。
**Llama 经历了三次重要的架构更新。**版本 1 对原始的 Transformer 架构进行了多项改进。版本 2 在大模型中引入了分组查询注意力(GQA)机制。版本 3 将这一机制扩展到了小模型,同时引入了更高效的分词器,还扩大了词汇量。版本 3.1 并未对核心架构做出调整,主要的变化在于训练数据的清洗、上下文长度的增加以及对更多语言的支持。
本文探讨了 Llama 的架构演变,着重介绍其主要进步及其对 LLM 未来发展的影响。文章最后通过一个实验对 Llama 2 和 Llama 3 进行了比较,使用了推理速度、答案长度和相对答案质量(RAQ,Relative Answer Quality)框架[1]等指标进行评估。RAQ 框架提供了一个客观的评分系统,用于检验 LLM 的回答准确度,对于评估特定应用场景尤为有用。

Figure 1: Llama family (image by author with DALL-E)
02
Llama: A Family of Open LLMs
2.1 Llama 1:该系列首个模型问世
Llama 系列的第一个模型,Llama 1 [2],是建立在 Vaswani 等人在 2017 年提出的编码器-解码器 Transformer 架构之上的[3]。该架构曾是 NLP 领域的重大创新,并且至今仍是 LLM 模型的基础架构。
Llama 1 在其核心设计中采纳了这一架构,并在此基础上进行了多项优化,包括:
预归一化技术
借鉴了 GPT3 [4]架构中提高训练稳定性的方法,Llama 1 也采用了对每个 Transformer 子层的输入进行归一化的策略,而不仅仅是对输出进行归一化处理,具体细节如图 2 所示。
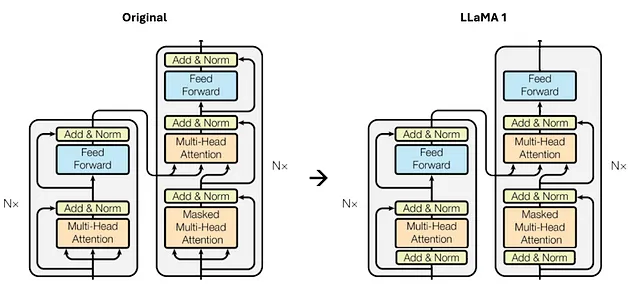
图 2:原始 Transformer 架构与 Llama 1 架构的不同之处,特别是在 Transformer 子层中,对每个输入都进行了归一化处理(图片由作者提供)
此外,Llama 1 还采用了 RMSNorm [5] 来替代传统的 LayerNorm 函数,这一改变在保持训练稳定性和提升模型收敛速度的同时,大幅提高了计算效率。
RMSNorm 之所以能更高效,是因为其创造者发现 LayerNorm 的优势在于 rescaling invariance(译者注:指的是归一化过程能够适应输入数据的缩放,使得网络对这种缩放不敏感。),而非 recentering invariance(译者注:如果输入数据的均值发生了变化,但数据的分布形状和范围保持不变,那么具有 recentering invariance 的算法或函数的输出应该不受影响。)。基于这一发现,他们省略了归一化过程中的均值计算,使得算法更加简洁,而效果不减,且运算效率显著提升。
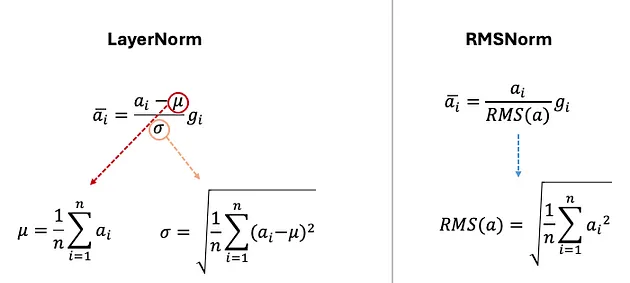
图 3:层归一化(LayerNorm)与均方根归一化(RMSNorm)之间的方程差异(图片由作者提供)
SwiGLU 激活函数
在激活函数的选择上,研究者们采用了 SwiGLU [6] 函数来替代传统的 ReLU 函数,这一改变旨在提升模型的性能。两者的核心差异在于:
- ReLU 函数会将所有负数输入直接归零,而正数输入则保持不变。
- 相比之下,**SwiGLU 函数含有一个可学习的参数 β,能够调节函数的插值程度。**随着 β 值的增大,SwiGLU 的行为将逐渐接近 ReLU,这一点如图 4 所示。
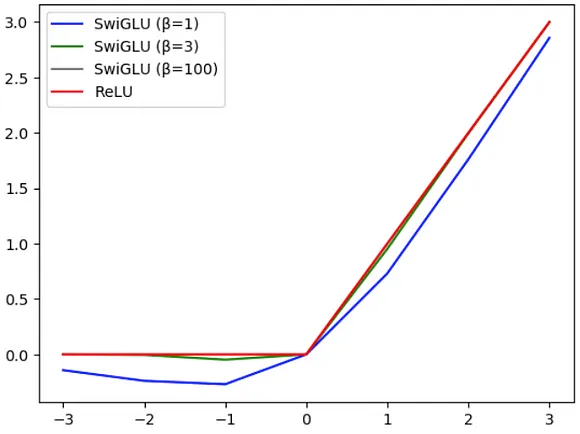
图 4:ReLU 与 SwiGLU 在不同 β 值下的行为对比,可以看到当 β 达到 100 时,两者的曲线趋于一致。
旋转式位置编码(Rotary Positional Embeddings)
在大语言模型(LLMs)中,位置编码起到了至关重要的作用,这是因为 Transformer 架构本身不区分单词的顺序。也就是说,**如果没有位置编码的辅助,Transformer 会将单词顺序不同但单词相同的两个句子视为相同的句子。**例如,如果没有位置编码,下面两个句子的含义 Transformer 将无法区分:
Sentence 1: Llama 2 is better than Llama 1 Sentence 2: Llama 1 is better than Llama 2
句子1:Llama 2的性能优于Llama 1。句子2:Llama 1的性能优于Llama 2。
在论文[3]中,提出了一种通过正弦和余弦函数实现的绝对位置编码(Absolute Positional Embeddings)。序列中的每个位置都有其独特的编码(positional embedding),它们与词向量相加,从而确保即使单词相同,不同顺序的句子也能表达不同的意思。
简单来说,我们可以假设句子中的单词是用一维向量而不是多维向量来编码的。如图 5 所示,在词向量中,“1”和“2”的表示值是相同的。但是,在加入了位置编码之后,它们的表示值就变得不同了(分别从0.88变为1.04,以及从0.26变为0.1)。
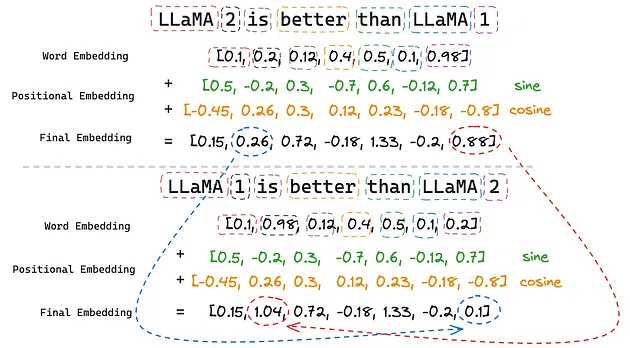
图 5:绝对位置编码(Absolute Positional Embeddings)(图片由作者提供)
**尽管绝对位置编码已经解决了 Transformer 不区分顺序的问题,但它生成的位置编码是相互独立的,没有考虑到序列中单词之间的相对位置关系。**这意味着在模型看来,位置 1 和位置 2 之间的相关性与位置 1 和位置 500 之间的相关性并无差异。然而,我们知道实际情况并非如此,因为在位置上更接近的单词,其相关性理论上应该更高。
旋转式位置编码[7](RoPE)能够解决上述问题,**它通过将序列中的每个位置转换成词嵌入的旋转变量来模拟单词间的相对位置关系。**以前文的 “Llama 2 is better than Llama 1” 为例,假设词嵌入现在是二维的。那么,“better ”一词将由基于其位置 m (4) 和常数 θ 的原始二维向量的二维旋转向量来表示。
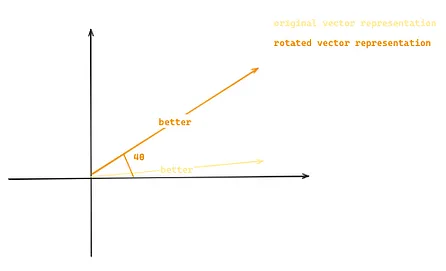
图 6:展示了如何通过旋转式位置编码(Rotary Positional Embedding)将原始向量转换为新的向量。这一转换是基于向量在序列中的位置(例如,m=4)和常数θ来进行的(图片由作者提供)
采用这种方式,即便在原句中增加更多词汇,单词之间的相对距离也能得到保持。比如,在句子 “The LLM Llama 2 is better than Llama 1” 中添加两个单词,尽管“better”和“than”的位置从(4和5)变为(6和7),但由于旋转量保持一致,两个向量之间的相似性(即左图中向量的点积与右图中的点积相同)依旧不变。
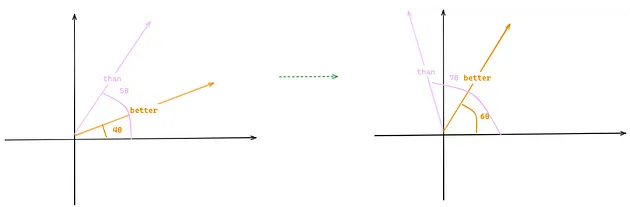
图 7:旋转式位置编码维持 tokens 间相对距离的能力(图片由作者提供)
2.2 Llama 2:Llama 1 的升级版
Llama 2 [8] 保留了 Llama 1 对原始 Transformer 架构所做的所有改动。在此基础上,还将处理上下文的长度扩展至 4096,相较于之前的 2048,翻了一番。同时,对于 34B 和 70B 这样的大型模型,Llama 2 使用 Grouped-Query Attention (GQA) [10] 取代了传统的 Multi-Head Attention (MHA) [9]。
由于需要大量内存来加载所有的注意力头的 queries、keys 和 values ,MHA 成为了 Transformer 的性能瓶颈。针对这一问题,有两种解决方案:
- Multi-Query Attention [9](MQA)通过在注意力层使用单一的键和值头(key and value),配合多个查询头(query heads)来大幅降低内存需求。但这种做法可能会降低模型的质量,并导致训练过程不稳定,因此像 T5 这样的其他开源大语言模型并未采用此方法。
- GQA 则采用了一种折中方案,它将查询值(query values)分为 G 组(GQA-G),每组共享一个键和值头(key and value head)。如果 GQA 的组数为 1(GQA-1),则相当于 MQA,所有查询(queries)都集中在一组;而如果组数等于头数(GQA-H),则与 MHA 相当,每个查询(query)自成一组。这种方法减少了每个查询(query)组中的键和值头(keys and values)数量,从而缩小了键值缓存的大小,减少了需要加载的数据量。与 MQA 相比,这种更为温和的缩减方式在提升推理速度的同时,也降低了解码过程中的内存需求,且模型质量更接近 MHA,速度几乎与 MQA 持平。
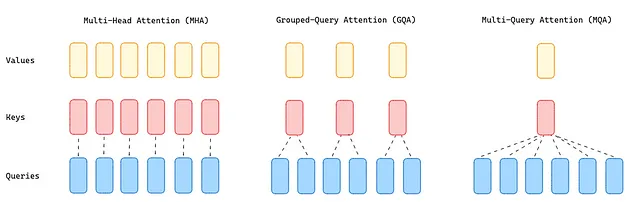
图 8:MHA、GQA 和 MQA 方法概览(图片由作者提供)
2.3 Llama 3: Size and Tokenization
Llama 3 [11] 将处理上下文的长度从 4096 扩展至 8192,并将 GQA 使用到了较小规模的模型(8B)。同时,研究者们还将分词工具从 Sentence Piece [12] 更换为 OpenAI 模型所采用的 TikToken [13]。因为新的词汇表容量增加到了 128k 个 tokens,较之前的 32k 有了大幅提升,这一变更显著提升了模型的性能。
**这两种分词工具的主要差异在于,在输入的 tokens 已经存在于词汇表中时,TikToken 会跳过字节对编码(BPE)****[14]****的合并规则。**例如,如果“generating”这个词已经在词汇表中了,那么它将作为一个完整的 token 返回,而不是将其拆分为“generating”和“ing”这两个最小单元的 tokens 。
2.4 Llama 3.1
在 2024 年 7 月发布的 Llama 3.1,实现了上下文长度(128K tokens)的显著提升,并新增了对 8 种语言的支持。此次发布版本的一个重要亮点是更大的 Llama 3.1 405B 模型。在此之前,开放式的 LLMs(大语言模型)通常模型规模都低于 100 B。
最后,我们可以从下表中总结一下 Llama 模型的演变情况:
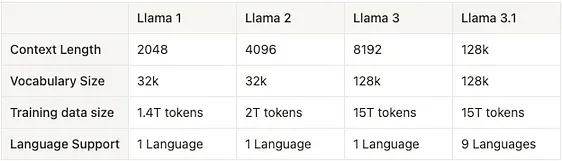
表 1:比较 Llama 模型在上下文长度、词汇表大小、训练数据集大小以及支持语言数量方面的演变。
03
Llama 2 与 Llama 3:模型比较
在本节中,我们将 Llama2 和 Llama 3 模型在 SQuAD 数据集上进行测试。SQuAD 是一个采用 CC BY-SA 4.0 许可协议的问答数据集(https://huggingface.co/datasets/rajpurkar/squad)。该阅读理解数据集(reading comprehension dataset)由一系列维基百科文章的问题组成。模型需要根据上下文,检索出问题的正确答案。对于本次模型比较,数据集中有三个较为重要的字段:
- 问题(question)——模型需要回答的问题。
- 上下文(context)——模型需要从中提取答案的背景信息。
- 答案(answers)——问题的文本答案。
评估过程将包括三个量化指标:**第一个是评估推理速度,第二个是确定答案长度,第三个是评估准确性。**对于准确性的评估,我们使用 RAQ [1]。RAQ 通过一个独立的 LLM 对 Llama 2 和 Llama 3 的答案进行排序,排序的依据是它们与真实答案的接近程度。
我们首先下载这两个模型的 .gguf 格式文件,以便能够在 CPU 上运行它们,并将它们放置在 model/ 文件夹下。
我们使用了每个模型的 instruct 版本,并进行了 4-bit 量化:
- nous-hermes-Llama-2-7b.Q4_K_M.gguf,来自 https://huggingface.co/TheBloke/Nous-Hermes-Llama-2-7B-GGUF
- Meta-Llama-3-8B-Instruct-Q4_K_M.gguf,来自 https://huggingface.co/NousResearch/Meta-Llama-3-8B-Instruct-GGUF
在完成上述操作之后,接下来我们会导入所有需要的库,以及我们自定义的一个生成器。这个生成器是一个函数或者类,它能够接受我们想要使用的模型作为输入参数。
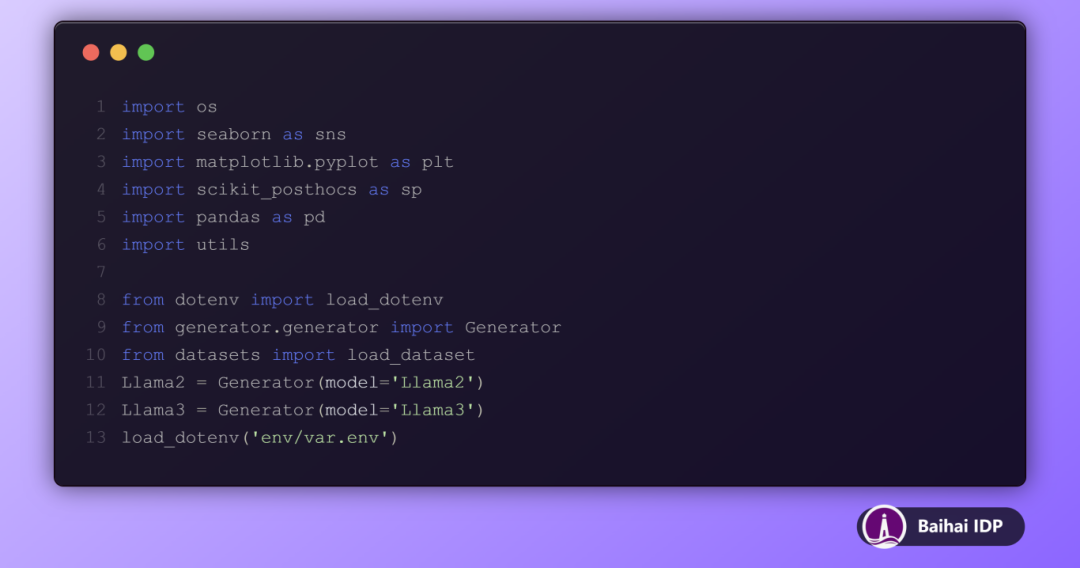
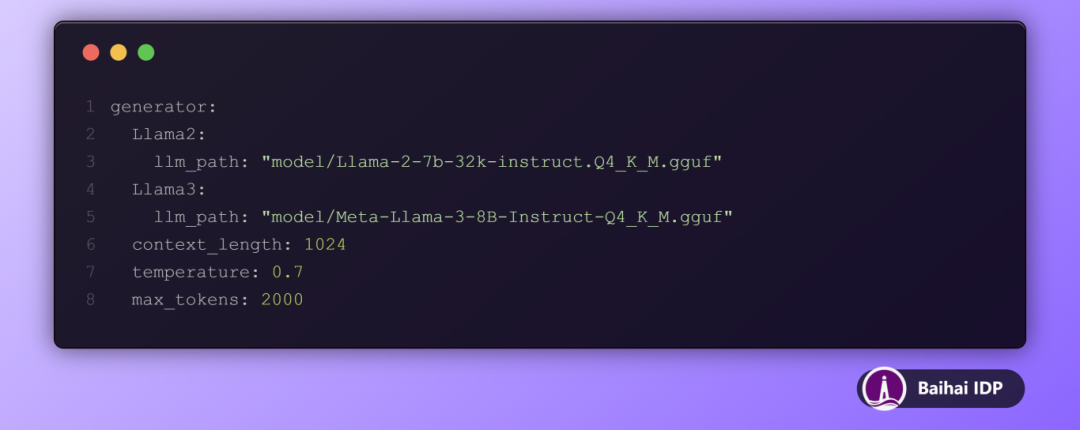
这个类的作用是从 config.yaml 配置文件中载入模型参数,这些参数的具体设置包括:设定上下文长度为 1024,调节模型运行的“temperature ”为 0.7,以及限制输出的最大 tokens 数为2000。
此外,系统还构建了一个基于 LangChain 的提示词模板。这个模板的作用是在将问题和相关上下文提交给大语言模型之前,对它们进行格式化处理,以便获得更准确的响应。
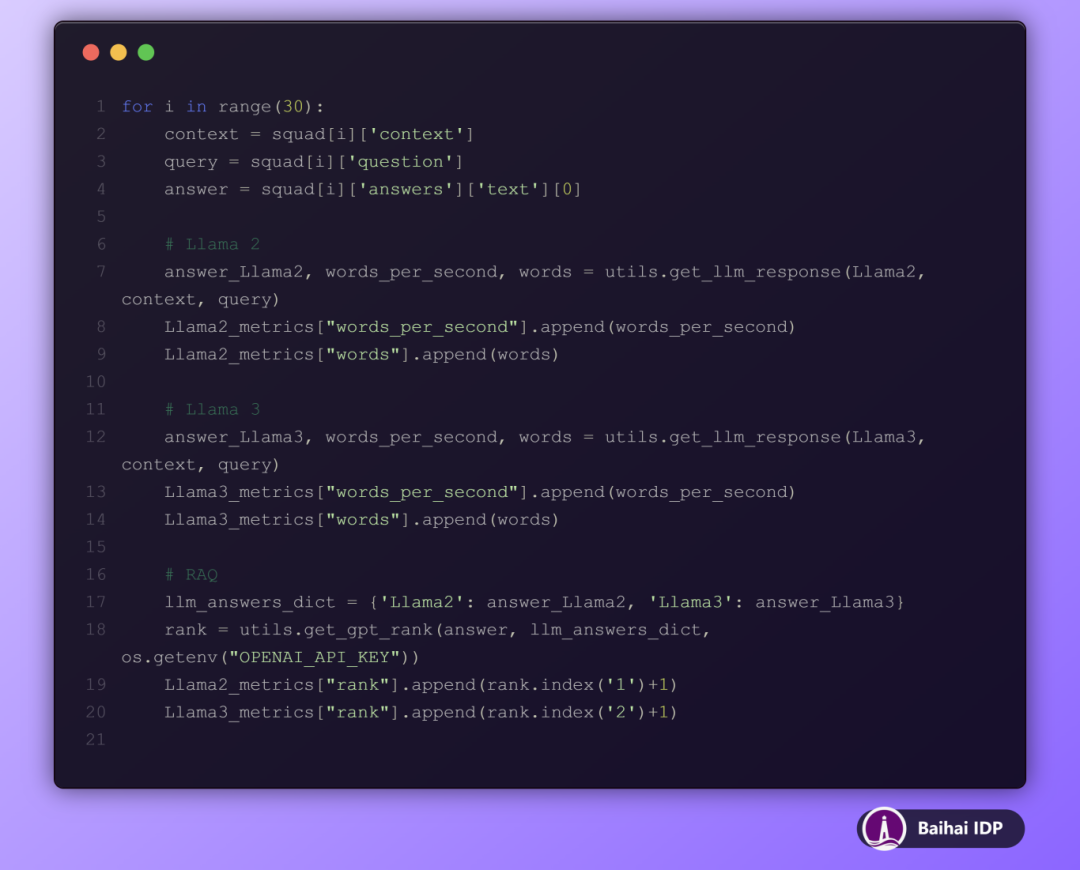
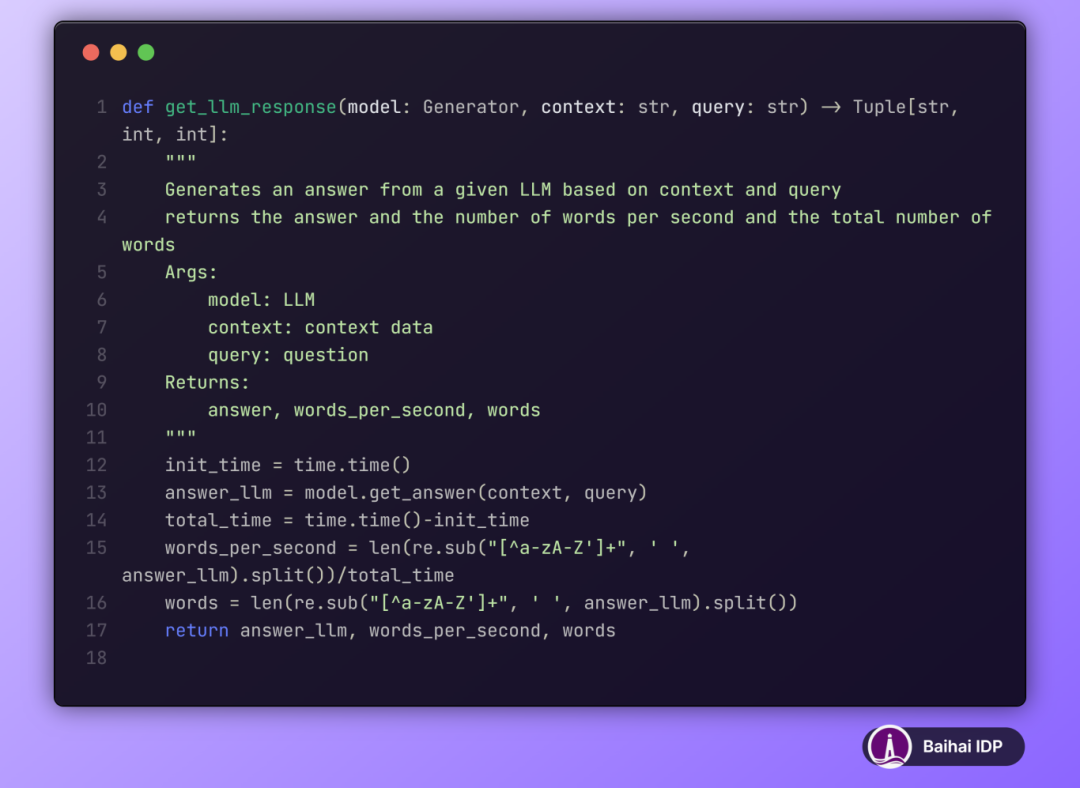
函数 get_llm_response 负责接收已加载的大语言模型、相关上下文以及问题,并输出模型的回答以及一系列量化评估指标。
评估结束后,我们将各项指标进行了可视化展示,并发现 Llama 3 的速度比 Llama 2 快,其平均生成速度达到每秒 1.1 个单词,而 Llama 2 的生成速度仅为每秒 0.25 个单词。在答案长度方面,Llama 3 输出的答案较长,平均为 70 个单词,相比之下,Llama 2 7B 的答案平均长度只有 15 个单词。根据相对答案质量(RAQ,Relative Answer Quality)评估框架,Llama 3 在平均排名上拔得头筹,约为 1.25,而 Llama 2 的表现则稍逊一筹,其平均排名大约为 1.8。
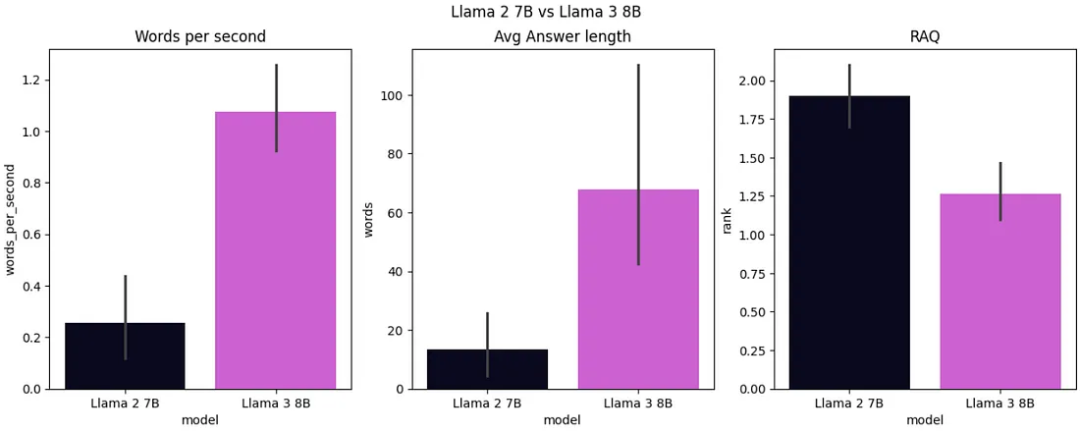
图 9:Llama 2 7B vs Llama 3 8B(图片由作者提供)
表 2 展示了不同语言模型性能的 Dunn 事后检验(Dunn post-hoc test)结果。每个单元格显示了两种模型之间的性能差异是否在 5 %的显著性水平(significance level)上具有统计意义。“Significant” 意味着存在统计上的显著差异(p值不超过0.05),而 “Not Significant” 则意味着模型之间的性能差异不具备统计显著性(p值超过0.05)。根据检验结果,Llama 3 与 Llama 2 在性能上的差异是显著的。
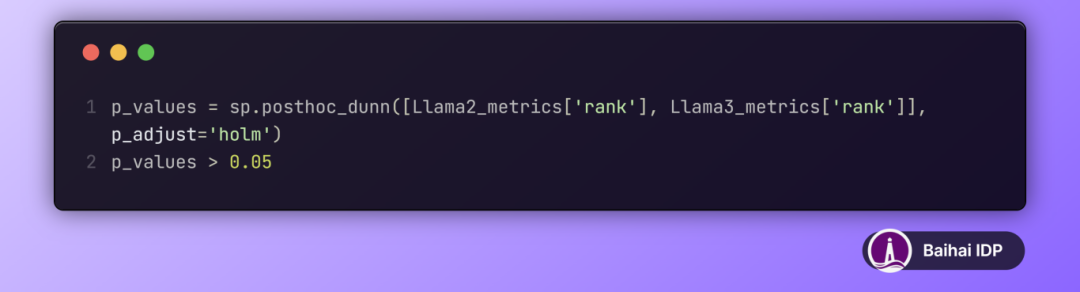

表 2:不同 LLM 模型性能排名差异的显著性分析
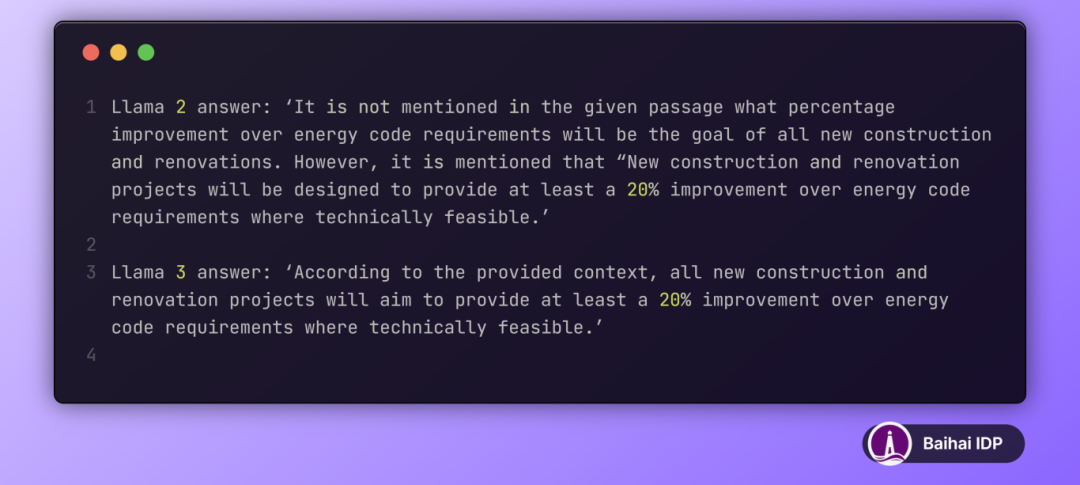
最后,从定性角度,我们分析了两种模型对某一特定问题的回答:“What percentage of improvement over energy code requirements will be the goal of all new construction and renovations?”。这一问题基于以下上下文信息得出答案,两者均正确地回答了问题。

然后,如下所示,Llama 2 在回答过程中先是表示答案不在给定上下文中,但最终却又引用了上下文中的内容来给出答案,显得前后矛盾。而 Llama 3 则能够准确地从上下文中找到答案,并简洁明了地作出了正确回应。
04
Conclusions
Llama 模型在发展过程中不断进行改进,使模型在处理语言任务时更加高效、表现更佳,并且能够适应更广泛的应用场景。从最初的 Llama 1 开始,引入了如 RMSNorm 输入归一化和更平滑的激活函数等基础性改变,后续的每个模型版本都是在此基础上进一步改进。
Llama 2 通过采用 GQA 提高推理效率,对这一方法进行了优化,为 Llama 3 的进一步提升铺平道路。Llama 3 在此基础上,将 GQA 应用于更小型的模型,采用了词汇表数量更大的高效分词器,将上下文长度翻倍,并大幅增加了训练数据量。
Llama 3.1 版本开启了新的篇章。它将上下文长度进一步扩展至 128K 个 token,增加了对更多语言的支持,并推出了迄今为止最大的开放式模型 —— 405B 模型。
Llama 模型的连续升级,使得它们在各种应用场景中都具有卓越的适应性。至今,Llama 模型已累计下载超过 3 亿次,而将其集成到利用私有 LLM 技术的数千种产品中,仅仅是一个开始。颇具讽刺意味的是,Llama 现在在推动开放式 AI 的发展道路上走在了前列,取代了曾经更为开放的 OpenAI 所占据的位置。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。