我自己的原文哦~ https://blog.51cto.com/whaosoft/12304427
# 智能驾驶仿真测试的『虚幻』与『真实』
先给大家讲个故事:某主机厂计划构建一套智能驾驶仿真环境,但需同时满足“对外展示”和“项目使用”两方面需求,与供应商商讨一个月后,最终方案是构建两套环境,一套“真实酷炫”给参观者体验;一套“标准实用”为研发测试所用。眼见不一定为实,尤其在看了不少仿真软文、做了很多仿真项目之后,总能想起“理想很丰满、现实很骨感”这句话。本文想把智能驾驶仿真测试的“虚幻”与“真实”做个对照,让兴致勃勃想进入仿真测试的人、让曾经在仿真中饱受挫折的人、让重振旗鼓重燃仿真希望的人,好好地看清楚她的过往。
有位主机厂的朋友说过:对于仿真从业人员来讲,软硬件的技术是次要的,重要的是思考本身。本文围绕“虚幻”与“真实”来展开,并非针对智驾产品仿真测试的技术细节,而是讲解业务形态自身的“虚幻”与“真实”。首先从认知进入智驾仿真测试的主题;之后介绍智驾仿真测试“虚幻”的开始、“虚幻”的模样、以及“虚幻”下主机厂和服务商的追捧;再通过“真实”写照,对比目标的达成、主机厂及服务商的“真实”现状;然后总结这个过程的“成败”,以及产生这些偏差的“原因”分析;最后站在2024年,重新看智驾仿真测试未来的“虚幻”与“真实”。旨在从现实的剖析中引入思考,向智驾仿真测试从业者呈现其真实面貌。
二、仿真测试的认知
仿真与仿真测试:仿真是一种手段,通过这种手段可以去做设计、做开发,当然也可以做测试及验证。很多人一听到仿真就来找测试团队,或者把仿真等同于仿真测试,这都是不准确的。
汽车中的仿真测试:汽车中的仿真及仿真测试,由来已久,如汽车结构的仿真设计、动力系统的仿真测试等。并非是有了智能驾驶产品才有了仿真及仿真测试,只不过是伴随汽车智能化的迅速发展,让仿真测试被很多人知晓。
仿真测试的基本做法:仿真测试的落脚点还是“测试”,利用MIL\SIL\HIL等不同的仿真手段,有针对性的开展测试任务。同样包括测试分析、用例设计、环境构建、测试执行、分析评价等过程,与常规测试基本一致。
三、为什么智能驾驶领域,仿真测试被捧在手心?
以前也没觉得仿真测试那么吃香,为什么在智能驾驶领域这么受欢迎呢,主要有三点:
1.资本驱动:近年来,太多公司跨界造车,传统主机厂也在迅速转型,智能化作为汽车下半场,让智能驾驶首当其冲成为投资焦点,从而带动了智驾仿真测试的需求。
2.技术驱动:与传统汽车零部件的仿真测试不同,智驾中仿真测试的被测对象为人工智能技术的产物,而AI在面对无穷尽的复杂场景时无法确保百分比准确,让仿真测试成为了救命稻草。
3.应用驱动:L2到L3的应用跨越,智驾产品势必会逐步代替驾驶者的感知和决策,其中首要确保安全底线,在公道测试常规操作下,仿真测试承担了一层“保险”。
四、仿真测试,起初承载了智能驾驶研发的诸多“虚幻”
智能驾驶研发对仿真测试有五方面的“虚幻”期望,既包括眼前的“多 快 好 省”、也包括将来的“创新”需求:
虚幻1:90%的测试验证可通过仿真测试完成——多。经常看到此类言论,如“90%仿真测试+9%场地测试+1%公道测试”,或者“之前只能在实车上开展的测试任务,现在有仿真测试解决方案了!”让仿真测试无所不能,万物尽可仿真一般。很容易联想到AEB实车测试中的各种困难,如摄像头的短路/断路/遮挡等,实车无法测试或者难度大的测试,仿真可以得心应手。
虚幻2:仿真测试可尽早发现问题、可日行千万里——快。快有两个维度,一个是介入早,仿佛仿真测试成了“测试左移”(shift-left)和“测试驱动”(TDD)的必选项,软件与产品同步、测试与研发同步。另外一个是效率高,都在幻想一台电脑的仿真测试可提升实车测试的十倍效率;上到云端的并行仿真可提升实车测试的百倍、千倍效率。
虚幻3:仿真测试可轻易覆盖真实中少见的特殊场景——好。既然现实中大多智驾产品引发的交通事故是因特殊场景导致,那么仿真测试对边缘场景的轻松构建,就是对质量最好的保障。幻想着仿真测试可以通过构建无限有价值的场景,对智驾产品提供全方位的测试验证(这个期望在国内尤其心切)。
虚幻4:充分利用数字化,降低设备及人力成本——省。省也有两个维度,一个是人力成本,仿真测试既然那么快,加上数字化、自动化的手段,以及对实车及场地人员的释放,幻想着团队的精简;另外一个是设备成本,XIL设备的一次性投入,幻想着可带来24小时不间断的使用效果,从长期考虑节省了大量开支。
虚幻5:数据驱动仿真测试,支撑算法迭代和创新——创新。幻想着智驾产品终有一天会走向数据驱动,汽车的控制决策也马上会由人工智能代替规则,那么仿真测试就是前提条件。在仿真测试的基础上,先打通控制决策的数据闭环、之后打通感知融合的数据闭环,最终打通端到端的大模型数据闭环,无限的创新场景,先要从仿真测试出发。
五、在“虚幻”的趋势下,主机厂的几步“让人兴奋”的操作
智驾仿真测试环境的构建:首先,要有达成“虚幻”必备的环境。常规做法有几种,一种是继承,在原有仿真环境的集成方案下,加入智能驾驶模块,如原先是整车或通信测试的仿真环境,再加入一些设备升级改造即可;另外就是重建,为某个平台或者某个产品申请预算,通过设备采购或集成商委托构建面向智驾的仿真测试环境;且大多侧重在零部件级仿真。高阶操作也有几种,一种是对现有仿真设备及软件的二次开发,如匹配自身需求的动力学模块改造、传感器模型适配等;另外一种就是对仿真设备及软件的重新开发,如基于开源架构的场景软件研发等;且大多希望构建整车级仿真环境。
有了环境,剩余的五步操作,就是对前期五个“虚幻”的实际响应:
1. 智驾产品的仿真测试实施(对应虚幻1):为大量开展仿真测试实施,常规做法有两种,一种是项目委外或人力onsite,通过供应商的设备及人力快速助力产品迭代;另外一种是主机厂构建自身仿真测试团队,大力开展仿真测试实施。高阶操作从数据回灌到虚拟仿真、从MIL\SIL到HIL\VIL\DIL、从功能逻辑到性能及可靠性测试,全面铺开。
2. 测试驱动模式与并行仿真(对应虚幻2):为缩短仿真测试周期、加快仿真测试速度,常规做法采用测试驱动研发、测试左移的思想,想尽一切手段与研发并行,为测试实施争取时间。高阶操作是借助云架构、云算力的支撑,通过并行仿真等手段解决环境对于执行效率的影响,从而进一步提升速度。
3. 健全仿真场景库的内容及理论(对应虚幻3):为提升智驾仿真测试的质量,常规做法通过购买第三方仿真测试场景库或者自建仿真数据库,尽力通过数据的丰富程度来满足自身需求。高阶操作是自研仿真测试方法论并参与智能驾驶场景相关的标准起草等。
4. 构建高效的仿真测试相关工具(对应虚幻4):通过数字化、自动化降低仿真测试成本,常规做法如购买场景泛化工具、数字孪生工具、测试自动化工具等来降低人工接入。高阶做法是基于自身需求,研发定制化工具,通过自研或委外研发等来实现。尤其是数字孪生概念,一想到数据中心里被灰尘覆盖的大量原始数据被得以重生,并在仿真测试中委以重任,就会让人无比激动;倘若真实的地图数据和实车路测数据都能够自动化的转换为仿真数据,并在仿真测试环境中被有效利用,也是莫大的期盼。
5. 数据驱动下的仿真测试闭环(对应虚幻5):为满足仿真测试对于数据驱动的创新支撑,常规做法是通过离线的数据回灌、场景还原、云仿真等构建仿真测试闭环,在研发阶段确保仿真测试的全面性。高阶操作通过实时的数据上传、场景转换、仿真训练及评价等,构建端到端智驾数据闭环,在量产阶段也能确保智驾产品的自我进化。
六、为助力主机厂“虚幻”达成,智驾仿真测试服务生态的“躁动”
智驾仿真测试服务生态中有五类服务商,分别看看他们的现有基础及面向主机厂“虚幻”目标所引发的“躁动”:
1. 集成商:现有基础是对各类仿真设备及软件的代理,以及丰富的集成经验。引发的躁动是针对自身集成能力向两头延伸,一是仿真产品的研发或基于代理产品的二次研发,提高自身IP含量;二是大力开展服务,如仿真测试服务、定制化服务等。
2. 产品商:现有基础是有仿真产品雏形、或者有同类型产品的案例经验。引发的躁动是针对智驾仿真测试所需的产品进行研发并尝试商业化,如场景仿真软件、动力学软件、场景构建软件等,投入大量研发打磨相关产品。
3. 云厂商:现有基础是有云存储及计算资源,并且在其他领域商业化成熟,且具备龙头效应。引发的躁动是以各类优惠服务大量涌入智驾业务,宣扬云的高效能、低成本助推仿真测试的实施,如云仿真。
4. 数据商:现有基础是具备标准制定能力、行业号召及影响力、或历史相关数据积累,但还未过多涉及仿真测试领域。引发的躁动是凭借标准导向和产业号召,构建全面的仿真测试场景库及权威的方法论,并向产业提供数据要素及标准。
5. 服务商:现有基础是有丰富的汽车整车及零部件的软硬件测试能力,或许有仿真测试经验,但对智驾产品涉及不够。引发的躁动是加大智驾仿真设备投入、增多仿真人员招聘及培养、加强仿真测试技术研究等,并联动各方资源构建智驾仿真测试整体解决方案。
七、六年间,“虚幻”是否成为“真实”?
对照当初的五个“虚幻”,目前看来的“真实”情况如何:
真实1:少部分的测试验证采用仿真,侧重功能逻辑等(对应虚幻1):零部件厂商的仿真测试占比或许多一些,但从主机厂的维度看,智驾仿真测试占比并不多。更多聚焦在功能逻辑、特定需求的验证等,仅在项目的部分阶段中起到主要作用。
真实2:依然在产品研发完毕后应用、大多以SIL\HIL为主(对应虚幻2):仿真测试并未起到测试驱动、测试先行的效果。一方面是部分企业的智驾产品未完成研发前,无法给出仿真测试环境所需的依赖,导致必须等到产品基本成型;另一方面,产品研发人员支撑不足、仿真集成环境问题百出,也是造成仿真测试延后的原因。曾经有个项目,仿真测试居然在公道测试之后,违背了起初的设想。另外,由于仿真测试投入有限,大多并未采取上云模式,且对执行人员依赖较高,并未对测试效率提升太大。
真实3:以法规、式样、泛化场景为主(对应虚幻3):这几年,国内外的相关组织和结构、以及行业联盟实施的国家级项目,都在尝试和普及智驾场景的方法论,但并未真正在产业中应用推广,加上L2到L3过渡周期的放缓,更多针对式样、法规及泛化场景的测试为主,未过多关注特殊场景的覆盖全面性。
真实4:大量工具未发挥作用,依然依靠经验人员(对应虚幻4):这几年工具研发了不少,尤其是场景生成、孪生还原的工具,但应用中各类定制化、调整、信息补充依然耗时耗力;且仿真人才引入门槛更高,测试执行中更需要经验人员的介入;若遇到产品技术平台的变动,前期很多投入都将打水漂。所以在成本节省方面并未取得良好效果。
真实5:目前还未融入数据驱动概念(对应虚幻5):第一阶段的研发环境实车数据都没有在仿真测试中应用起来,主要原因是各类误差的堆叠导致仿真测试效果较差、人工介入的调整太多;第二阶段的量产数据驱动更是由于控制决策算法的不支持而未全面展开。
八、大力推进仿真测试下,主机厂 “真实”写照中的六道坎
1道坎-没研发/构建出来:由于技术门槛高、人才投入大,开展的自研仿真工具并未成功上线或并未助力到现行项目;计划投资构建的智驾仿真环境,一直处于论证、延期状态,迟迟无法落地。
2道坎-有了,但没跑起来:好不容易投入大量资金构建了仿真设备和软件,但由于应用场景不满足或人才缺失等问题,环境处于未启用、闲置状态;或由于软硬件的各方面调试联动的复杂性,造成长时间处于集成商的集成实现中。
3道坎-跑起来了,但不适用:好不容易仿真环境集成完毕,但由于自身产品的变化、升级等,导致无法匹配现行产品,且各种不稳定、异常情况被暴露,测试执行层面需依赖产品研发人员及集成商,造成工作无法开展。
4道坎-适用了,但产出有限:好不容易仿真环境与产品匹配好了,但之前设计的用例场景仍需更多调整、开发的自动化测试工具也需手工过多接入,问题的定位依然依赖经验人员,造成产出较低的情况。
5道坎-有产出了,但不可信:好不容易有测试结果产出了,但因环境和工具的误差,仿真与真实的误差,造成应该测试出来问题没有被测出、而正常的表现却被认定为BUG,最终导致结果不可信。
6道坎-有效果了,但失败了:好不容易通过技术攻关解决了可信性问题,再看一下项目工期,已经延迟、甚至落后于实车验证;再看一下项目投入,已经远大于产出,甚至没有公道测试来的实惠,最终造成仿真测试的失败。
九、残酷的“真实”下,主机厂的应变现状
能用就行、不管多少:一方面,把仿真测试作为实车测试的补充,多应用于SOP之后的功能逻辑、故障验证等;另一方面,充分挖掘现有仿真环境价值,在HIL有强依赖的情况下,尽量通过SIL来解决。
好用就行、不管大小:不再追求大而全的一体化大仿真台架,反而更注重投益效果,如采用较多小而美的台架测试针对性的特定问题,更受欢迎。
有效就行、不管前后:不盲目追求前期颠覆性的创新,反而注重基于现有环境的后期优化,如开发一些数据分析工具或者自动化脚本来提升局部环节的效率。
十、智驾仿真测试服务商“躁动”后的“真实”情况如何?
分别剖析五类服务商的“真实”情况:
1. 集成商:一方面大量服务商及产品商都延伸到集成业务,在市场有限的情况下,竞争相对激烈;另一方面,因每家主机厂的智驾方案各有不同,造成集成中存在较多技术难度大的适配工作,投入研发的成本大、但技术再利用的市场有限。
2. 产品商:国内大多产品商把仿真类产品研发想象的过于简单,在投入大量研发后发现产品无法与国际竞品媲美,市场不买账,无法商业落地,最终走向消亡;即使有应用场景,但产品局限性、定制性较强,最后仅能自我使用,价值体现弱。
3. 云厂商:互联网思维运营汽车云,通过各类优惠政策获取客户,并投入大量人力物力开展云仿真环境构建,或自研云仿真平台,但除了AI感知训练服务外,在控制决策的仿真测试方面,真实用户较少,较多处于依赖企业其他板块救济状态。
4. 数据商:花费了大力气去积累、生产仿真测试数据,却由于场景不匹配、质量不满足、太贵用不上等各类原因销售惨淡;并且行业并未形成公认的智驾仿真测试标准,导致各类方法论不统一,数据相互不认可,流转不通畅,卷来卷去没出路。
5. 服务商:智驾仿真测试服务,较高的设备门槛、人才门槛、经验门槛,导致服务商前期投入较大,人才的稳定性也不高;另一方面,服务对象的仿真环境和需求迥异,导致项目的中标、项目的实施、有利润的开展都遇到很大困难,真正赚钱的也不多。
十一、在这个过程中看到的“成效”,哪些是“虚幻”的、哪些是“真实”的?
“虚幻”的“成效”
1.从无到有、从旧到新,具备了自己的仿真实验室,时常对外展示,提升品牌;
2.或多或少积累了智驾仿真技术和产品,综合能力有所提升,助力了宣传;
3.新增了一个仿真测试业务方向,虽发展缓慢,但“聊胜于无”,撑撑场面;
4.或许参与了一些政府、科研类项目,得到了一些经费补贴和荣誉,些许慰藉。
“真实”的“成效”
在“虚幻”中看清本质,不被“躁动”所影响的组织,才能真正得到“成效”。如某些零部件企业,起初就看准了仿真测试的边界和效果,较小的设备投入在某些功能方面取得较好的效果;再比如国际化的仿真设备商、软件商,聚焦在自身领域做专做深,当别人都在挖矿的时候,把铁锹做好就是最好的生意。
十二、“虚幻”与“真实”差异较大的原因
这些年来智驾仿真测试为什么没有达到预期效果?从三个层面来思考:
表面原因:
1.仿真太费钱:觉得客户/领导跟不上“潮流”,明明有好的仿真产品、好的解决方案,就是不采用、或者舍不得花钱;就算是POC走通了、客户也始终在犹豫要不要上,不够果断。
2.仿真太复杂:都觉得仿真测试关联方众多,联动不畅,尤其是智驾仿真测试,感知虚拟化、场景孪生、动力学适配、域控软件联调等等,高门槛导致推行受阻。
3.仿真不准确:这点最重要,仿真如果做不到较高的逼真度,势必与真实情况存在偏差。而智驾的误差因素有很多,环境模拟、传感器感知、动力控制等误差的叠加最终会导致结果的不可信,从而使得Sim2Real方案遭到质疑。
4.仿真不规范:实时机、场景软件、动力学软件、传感器仿真的国内外厂商琳琅满目,并且在各种组合后形成数十种方案。再加上被测智驾产品的方案不同、对仿真数据库的要求不同,最终就形成了各类定制化。造成的后果就是相互不兼容、重复性的技术投入大,导致问题多、周期长、不可持续。
深层原因:
1.环境不支撑:一方面虽中国汽车产销破3000万辆,但今后也不会有大幅上涨,叠加产业内卷造成的单车利润下降,势必会影响研发方面的投入;另一方面,智能化虽号称作为汽车的下半场,但消费端依然视作加分项,在较多主机厂依旧以“辅助驾驶”产品为主的情况下,大规模仿真测试的需求并不强烈。
2.管理不匹配:智驾研发在组织结构上比其他产品研发更为复杂。甚至国内某些知名主机厂成立单独的科技公司、软件公司进行匹配。原因是涉及车辆工程、芯片域控、软件研发、人工智能、工程服务、数据挖掘等众多类型,需组织各部门间、组织与组织间构建网状的协同模式,而往往在仿真测试项目中依然采用过往的测试+研发模式,急需探索新的管理方法。
3.方法不统筹:从大的方面看,目前的强制法规依然集中在L1\L2阶段,并且是最为初级的门槛,L3又会涉及这样那样的问题,导致大多产品在L2+徘徊、并且没有成熟的测试标准规范依赖。在混沌状态下、市场默认产品的差异化,从而造成没有权威的方法去衡量产品,仿真测试也是如此,导致了规范性不强。
4.技术不成熟:不成熟的表现有三点,一是短平快思想主导(无法坚持长期主义),尤其是受到市场波动压力、考核周期较短、内部组织调整等,无法长期规划技术路线、坚持技术投入;二是畏惧新技术心理(缺乏勇闯无人区的勇气),尤其在仿真工业软件领域,都愿意在简单的技术上雕花、而不愿意在卡脖子的技术上投入;三是万事靠自己的思想(不习惯用生态资源),崇尚全栈自研、遍地布局,就算明面上与伙伴共赢、实则白嫖的心理,尤其在智驾领域行不通,靠自身无法促成仿真技术的突破。
根本原因:
归根结底是智驾技术并未有本质性的突破,智驾产品并未在本质上获得用户的认可。绝大多数采用模块化思想实现智驾功能、绝大多数在控制决策中采用软件1.0的规则思想来实现规划控制。这就导致智驾产品的渗透率和使用率不高,从而反应到投入上,影响了智驾仿真的环境、管理、方法及技术的发展。
十三、用现在的视角再看智能驾驶
相比其他领域,智能驾驶日新月异,站在2024年重新从政策、市场、技术等方面看智能驾驶的积极面和消极面:
积极的:
政策面:一方面,我国提出“新质生产力”,智能驾驶是其在汽车产业应用的重要体现。另一方面,我国新能源汽车产销连续9年位居全球第一,成为“新三样”之一;且两会报告中也提到加强“人工智能+”行动,深化大数据、人工智能研究。在政策引导下,各级政府对智能网联汽车尤其重视,也带动了智能驾驶的发展。
市场面:汽车智能化作为汽车发展的下半场,已经被主机厂和消费群体认可。小米、问界等新车型的发布也少不了智驾表现的大力宣传,市场培养了对智能驾驶的迫切需求。
技术面:一年来,端到端、数据驱动、多模态、大模型等创新性的技术和模式涌现,为智能驾驶产品成熟重新点燃了希望;另外,三维重建、AR\VR、SORA等技术的进步,也为仿真技术革新提供了新途径。
若积极看待技术变革,在政策引导和市场推动下,智能驾驶将加速发展。
消极的:
政策面:分析今年两会的汽车相关提案可以看出,智能驾驶相关的提案较少,更多侧重在绿色低碳、出口及促消费等方面,且信息安全及人身安全依然是政策第一位,一定程度上约束了智驾发展。
市场面:汽车市场继续内卷状态,且面向智驾的资本注入遇冷,在降本的策略下不会通过提升传感器配置来为市场加分,在辅助驾驶阶段会继续维持一段时间。
技术面:苹果等高端玩家的撤出,也为智驾技术的发展蒙上了阴影,大模型对算力的依赖、端到端对算法的依赖都可能成为技术难以逾越的门槛,挑战依然严峻。
若消极看待技术变革,目前的L2++仍会保持较长时间的存在。
十四、今后,智能驾驶仿真测试的“虚幻”与“真实”又是什么?
通过重新审视智能驾驶的发展,来分析其仿真测试的“虚幻”与“真实”:
虚幻:
利用世界物理模型等新技术,构建新一代的仿真测试环境,让Sim2Real真正助力智驾研发。结合游戏引擎、利用SORA类同的技术,在无限量的公道数据基础上,形成集感知、融合、控制、决策、执行于一体端到端仿真平台,并结合数据挖掘、实时上传、自动处理、无限泛化、高效训练等来提升智驾水平。
真实:
吸取前期的经验教训,认清自身的边界,或聚焦于自身平台/产品研发所需来开展仿真测试的研发及应用;或聚焦于自身擅长的领域,把仿真测试做专、做深来赢得市场。另外,一定要重视生态,若是甲方就应该积极寻求乙方的技术资源加快实现;若是乙方就必须融入到甲方的朋友圈共同进步。只有这样,才能在未来诸多“虚幻”与“真实”的分叉路口一直走对方向。
十五、写在最后
作为行业一员、在智驾仿真测试中走过六年,遇到太多人、经历过太多事,回首过往点点滴滴,想以此篇来记录对智能驾驶仿真测试的审视。没有讲仿真测试技术,更多是对过去和将来的思考,希望对大家有所启发。
也借助平台,分享我写文章的十条原则及方针,共勉:
1. 原创输出:不做网络信息的复制者,追求独立见解
2. 真实客观:不捏造事实、不道听途说,确保真实性
3. 拒绝软文:不做技术或产品的大肆宣传,拒绝广告
4. 实践导向:结合多年工作及实际案例,来源于实践
5. 深度聚焦:不求广度求深度,聚焦某个方面讲透彻
6. 紧贴动态:尤其是结合行业和技术的最新动态来谈
7. 本质思考:挖掘现象背后的逻辑,思考现象的本质
8. 朴素生动:朴素易懂、鲜活生动,拉进听众的距离
9. 逻辑清晰:结构鲜明有逻辑、思路清晰并突出重点
10.合规底线:所在企业和关联客户及伙伴的信息保护
# 效率狂增16倍!VRSO
纯视觉静态物体3D标注,打通数据闭环!
标注之殇
静态物体检测(Static object detection,SOD),包括交通信号灯、导向牌和交通锥,大多数算法是数据驱动深度神经网络,需要大量的训练数据。现在的做法通常是对大量的训练样本在 LIDAR 扫描的点云数据上进行手动标注,以修复长尾案例。
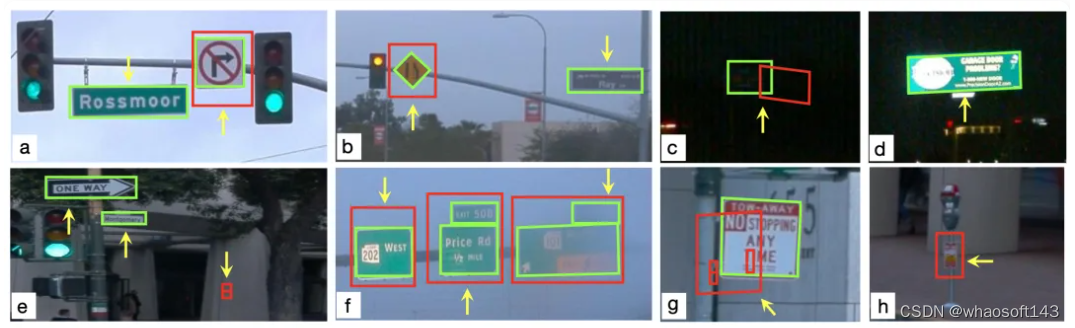
手动标注难以捕捉真实场景的变异性和复杂性,通常无法考虑遮挡、不同的光照条件和多样的视角(如图1中的黄色箭头)。整个过程链路长、极其耗时、容易出错、成本颇高(如图2)。所以目前公司都寻求自动标注方案,特别是基于纯视觉,毕竟不是每辆车都有激光雷达。

VRSO 是一种以视觉为主、面向静态对象标注的标注系统,主要利用了 SFM、2D 物体检测和实例分割结果的信息,整体效果:
- 标注的平均投影误差仅为2.6像素,约为Waymo标注的四分之一(10.6像素)
- 与人工标注相比,速度提高了约16倍
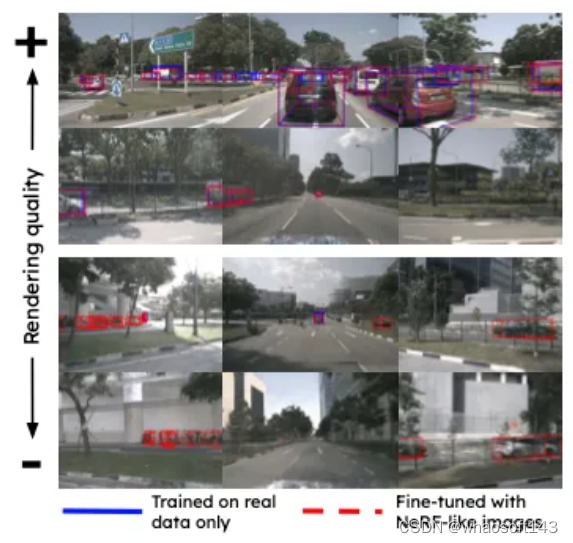
对于静态物体,VRSO通过实例分割和轮廓提取关键点,解决了从不同视角集成和去重静态对象的挑战,以及由于遮挡问题而导致观察不足的困难,从而提高了标注的准确性。从图1上看,与Waymo Open数据集的手动标注结果相比,VRSO展示了更高的鲁棒性和几何精度。
(都看到这里了,不如大拇指往上滑,点击最上方的卡片关注我,整个操作只会花你 1.328 秒,然后带走未来所有干货,万一有用呢~)
破局之法
VRSO系统主要分为两部分:场景重建和静态对象标注。
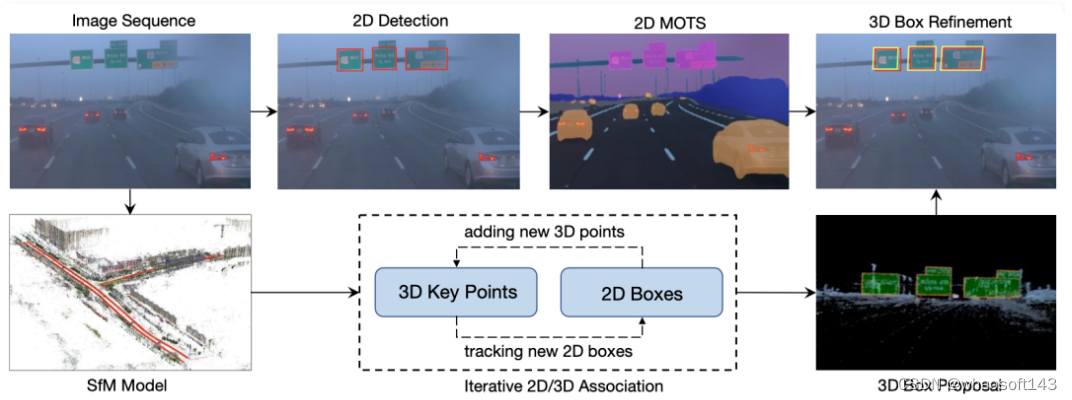
重建部分不是重点,就是基于 SFM 算法来恢复图像 pose 和稀疏的 3D 关键点。
静态对象标注算法,配合伪代码,大致流程是(以下会分步骤详细展开):
- 采用现成的2D物体检测和分割算法生成候选
- 利用 SFM 模型中的 3D-2D 关键点对应关系来跟踪跨帧的 2D 实例
- 引入重投影一致性来优化静态对象的3D注释参数
1.跟踪关联
- step 1:根据 SFM 模型的关键点提取 3D 边界框内的 3D 点。
- step 2:根据 2D-3D 匹配关系计算每个 3D 点在 2D 地图上的坐标。
- step 3:基于 2D 地图坐标和实例分割角点确定当前 2D 地图上 3D 点的对应实例。
- step 4:确定每个 2D 图像的 2D 观察与 3D 边界框之间的对应关系。
2.proposal 生成
对静态物体的 3D 框参数(位置、方向、大小)进行整个视频剪辑的初始化。SFM 的每个关键点都有准确的3D位置和对应的 2D 图像。对于每个 2D 实例,提取 2D 实例掩码内的特征点。然后,一组对应 3D 关键点可以被视为 3D 边界框的候选。
路牌被表示为在空间中具有方向的矩形,它有6个自由度,包括平移(、、)、方向(θ)和大小(宽度和高度)。考虑到其深度,交通信号灯具有7个自由度。交通锥的表示方式与交通信号灯类似。
3.proposal refine
- step 1:从 2D 实例分割中提取每个静态物体的轮廓。
- step 2:为轮廓轮廓拟合最小定向边界框(OBB)。
- step 3:提取最小边界框的顶点。
- step 4:根据顶点和中心点计算方向,并确定顶点顺序。
- step 5:基于2D检测和实例分割结果进行了分割和合并过程。
- step 6:检测并拒绝包含遮挡的观察。从2D实例分割蒙版中提取顶点要求每个标牌的四个角都可见。如果有遮挡,从实例分割中提取轴对齐边界框(AABB),并计算AABB与2D检测框之间的面积比。如果没有遮挡,这两种面积计算方法应该是接近的。
4.三角化
通过三角化在3D条件下获取静态物体的初始顶点值。
通过检查在场景重建期间由 SFM 和实例分割获得的3D边界框中的关键点数量,只有关键点数量超过阈值的实例被认为是稳定且有效的观测。对于这些实例,相应的 2D 边界框被视为有效的观测。通过多幅图像的 2D 观测,将 2D边界框顶点进行三角化,以获取边界框的坐标。
对于没有在掩模上区分“左下、左上、右上、右上和右下”顶点的圆形标牌,需要识别这些圆形标牌。使用 2D 检测结果作为圆形物体的观测结果,使用 2D 实例分割掩模进行轮廓提取。通过最小二乘拟合算法计算出中心点和半径。圆形标牌的参数包括中心点(、、)、方向(θ)和半径()。
5.tracking refine
跟踪基于 SFM 的特征点匹配。根据 3D 边界框顶点的欧式距离和 2D 边界框投影 IoU 来确定是否合并这些分开的实例。一旦合并完成,实例内的 3D 特征点可以聚集以关联更多的2D特征点。进行迭代2D-3D关联,直到无法添加任何2D特征点为止。
6.最终参数优化

- 将六个自由度转换为四个 3D 点,并计算旋转矩阵。
- 将转换后的四个 3D 点投影到2D图像上。
- 计算投影结果与实例分割得到的角点结果之间的残差。
- 使用 Huber 进行优化更新边界框参数
标注效果

也有一些具有挑战性的长尾案例,例如极低的分辨率和照明不足。

总结一下
VRSO 框架实现了静态物体高精度和一致的3D标注,紧密集成了检测、分割和 SFM 算法,消除了智能驾驶标注中的人工干预,提供了与基于LiDAR的手动标注相媲美的结果。和被广泛认可的Waymo Open Dataset进行了定性和定量评估:与人工标注相比,速度提高了约16倍,同时保持了最佳的一致性和准确性。
# 强化学习真的很适用于自动驾驶吗
对于L4+级别的自动驾驶,RL是一种能够提高决策上限的技术路线。没错,仅仅是一种技术探索选择。
理想是:RL打上限 + 规则托底下限 + 海量场景库 + 全量特征输入 +……
现实是:规则 + 传统控制,已经cover 99%场景,RL在这些场景下无法保证有传统的控制决策水平。所以对于1%长尾场景,才是RL被期待的重点,但是这个东西又需要大量仿真和场景触发来学习对比,这又顶到了RL“样本类型少而无法学好”的问题……
不过,目前头部车企应该都是有RL方案探索的(注意这里RL应用层次和深浅都不一样,为避免误解,修改成“头部车企”和“RL方案探索”),和学术界搞端到端或者直接决策不同。
一方面,RL主要优化策略搜索的问题来提高效率,比如用MCTS来搜索航点(Tesla),比如用输出预测未来一段时间的位置(百度apollo),比如用来在规划时做不同决策路径的价值评估(车前有自行车是跟随还是远离还是变道等)。
另一方面,RL主要在仿真下做smart agent,其实就是模仿出现实世界的人和物的决策行为,和自动驾驶车辆做博弈,主动创造符合真实场景的人车运动,来提高或验证传统算法。
-----> 分割线
做RL的更多还是在游戏领域,因为env可控、稳定、任务明确。不过现在RL很多新领域研究确实比较香,破游戏圈的趋势也很明显,插一句,自动驾驶类的游戏ai已经是可以做得很好了,当然这和实际自动驾驶可能不是同一类问题。
现在imtaion和offline的RL研究成果尤其多,而且在游戏的工业界也有成功应用,这对降低成本和加速实验迭代是很大利好。
但需要注意,不同公司的RL人才储备和技术水平也差别很大,由于业务需求、组织发展等原因导致RL人才的技术差别巨大。而真正能商业化落地和实际表现出众,是需要大量工程实践经验和扎实项目背景做依靠的。从做出demo到实际落地并成熟商业化,不单纯是个技术问题,但RL技术路线非常值得探索,所以个人还是比较看好RL在自动驾驶落地,并且能够表现惊人,拭目以待吧。
------> 二次分割
部分资料:
- 特斯拉2021人工智能日AI Day完整视频(中英双字)_哔哩哔哩_bilibili
2.百度apollo pnc rl

# 自动驾驶与轨迹预测
轨迹预测在自动驾驶中承担着重要的角色,自动驾驶轨迹预测是指通过分析车辆行驶过程中的各种数据,预测车辆未来的行驶轨迹。作为自动驾驶的核心模块,轨迹预测的质量对于下游的规划控制至关重要。轨迹预测任务技术栈丰富,需要熟悉自动驾驶动/静态感知、高精地图、车道线、神经网络架构(CNN&GNN&Transformer)技能等,入门难度很大!
入门相关知识
1.预习的论文有没有切入顺序?
A:先看survey,problem formulation, deep learning-based methods里的sequential network,graph neural network和Evaluation。
2.行为预测是轨迹预测吗
A:是耦合的,但不一样。行为一般指目标车未来会采取什么动作,变道停车超车加速左右转直行等等。轨迹的话就是具体的具有时间信息的未来可能的位置点
3.请问Argoverse数据集里提到的数据组成中,labels and targets指的是什么呢?labels是指要预测时间段内的ground truth吗
A:我猜这里想说的是右边表格里的OBJECT_TYPE那一列。AV代表自动驾驶车自己,然后数据集往往会给每个场景指定一个或多个待预测的障碍物,一般会叫这些待预测的目标为target或者focal agent。某些数据集还会给出每个障碍物的语义标签,比如是车辆、行人还是自行车等。
Q2:车辆和行人的数据形式是一样的吗?我的意思是说,比如一个点云点代表行人,几十个点代表车辆?
A:这种轨迹数据集里面其实给的都是物体中心点的xyz坐标,行人和车辆都是
Q3:argo1和argo2的数据集都是只指定了一个被预测的障碍物吧?那在做multi-agent prediction的时候 这两个数据集是怎么用的
A:argo1是只指定了一个,argo2其实指定了多个,最多可能有二十来个的样子。但是只指定一个并不妨碍你自己的模型预测多个障碍物。
4.路径规划一般考虑低速和静态障碍物 轨迹预测结合的作用是??关键snapshot?
A:”预测“自车轨迹当成自车规划轨迹,可以参考uniad
5.轨迹预测对于车辆动力学模型的要求高吗?就是需要数学和汽车理论等来建立一个精准的车辆动力学模型么?
A:nn网络基本不需要哈,rule based的需要懂一些
6. 模模糊糊的新手小白,应该从哪里在着手拓宽一下知识面(还不会代码撰写)
A:先看综述,把思维导图整理出来,例如《Machine Learning for Autonomous Vehicle's Trajectory Prediction: A comprehensive survey, Challenges, and Future Research Directions》这篇综述去看看英文原文
7.预测和决策啥关系捏,为啥我觉得好像预测没那么重要?
A1(stu): 默认预测属于感知吧,或者决策中隐含预测,反正没有预测不行。
A2(stu): 决策该规控做,有行为规划,高级一点的就是做交互和博弈,有的公司会有单独的交互博弈组8.目前头部公司,一般预测是属于感知大模块还是规控大模块?
A:预测是出他车轨迹,规控是出自车轨迹,这俩轨迹还互相影响,所以预测一般放规控。
Q: 一些公开的资料,比如小鹏的感知xnet会同时出预测轨迹,这时候又感觉预测的工作是放在感知大模块下,还是说两个模块都有自己的预测模块,目标不一样?
A:是会相互影响,所以有的地方预测和决策就是一个组。比如自车规划的轨迹意图去挤别的车,他车一般情况是会让道的。所以有些工作会把自车的规划当成他车模型输入的一部分。可以参考下M2I(M2I: From Factored Marginal Trajectory Prediction to Interactive Prediction). 这篇思路差不多,可以了解 PiP: Planning-informed Trajectory Prediction for Autonomous Driving
9.argoverse的这种车道中线地图,在路口里面没有车道线的地方是怎么得到的呀?
A: 人工标注的
10.用轨迹预测写论文的话,哪篇论文的代码可以做baseline?
A: hivt可以做baseline,蛮多人用的
11.现在轨迹预测基本都依赖地图,如果换一个新的地图环境,原模型是否就不适用了,要重新训练吗?
A: 有一定的泛化能力,不需要重新训练效果也还行
12.对多模态输出而言,选择最佳轨迹的时候是根据概率值最大的选吗
A(stu): 选择结果最好的Q2:结果最好是根据什么来判定呢?是根据概率值大小还是根据和gt的距离A: 实际在没有ground truth的情况下,你要取“最好”的轨迹,那只能选择相信预测概率值最大的那条轨迹了Q3: 那有gt的情况下,选择最好轨迹的时候,根据和gt之间的end point或者average都可以是吗A: 嗯嗯,看指标咋定义轨迹预测基础模块
1.Argoverse数据集里HD-Map怎么用,能结合motion forecast作为输入,构建驾驶场景图吗,异构图又怎么理解?
A:这个课程里都有讲的,可以参照第二章,后续的第四章也会讲. 异构图和同构图的区别:同构图中,node的种类只有一种,一个node和另一个node的连接关系只有一种,例如在社交网络中,可以想象node只有‘人’这一个种类,edge只有‘认识’这一种连接。而人和人要么认识,要么不认识。但是也可能细分有人,点赞,推文。则人和人可能通过认识连接,人和推文可能通过点赞连接,人和人也可能通过点赞同一篇推文连接(meta path)。这里节点、节点之间关系的多样性表达就需要引入异构图了。异构图中,有很多种node。node之间也有很多种连接关系(edge),这些连接关系的组合则种类更多(meta-path), 而这些node之间的关系有轻重之分,不同连接关系也有轻重之分。
2.A-A交互考虑的是哪些车辆与被预测车辆的交互呢?
A:可以选择一定半径范围内的车,也可以考虑K近邻的车,你甚至可以自己提出更高级的启发式邻居筛选策略,甚至有可能可以让模型自己学出来两个车是否是邻居
Q2:还是考虑一定范围内的吧,那半径大小有什么选取的原则吗?另外,选取的这些车辆是在哪个时间步下的呢
A:半径的选择很难有标准答案,这本质上就是在问模型做预测的时候到底需要多远程的信息,有点像在选择卷积核的大小对于第二个问题,我个人的准则是,想要建模哪个时刻下物体之间的交互,就根据哪个时刻下的物体相对位置来选取邻居
Q3:这样的话对于历史时域都要建模吗?不同时间步下在一定范围内的周边车辆也会变化吧,还是说只考虑在当前时刻的周边车辆信息
A:都行啊,看你模型怎么设计
3.老师uniad端到端模型中预测部分存在什么缺陷啊?
A:只看它motion former的操作比较常规,你在很多论文里都会看到类似的SA和CA。现在sota的模型很多都比较重,比如decoder会有循环的refine
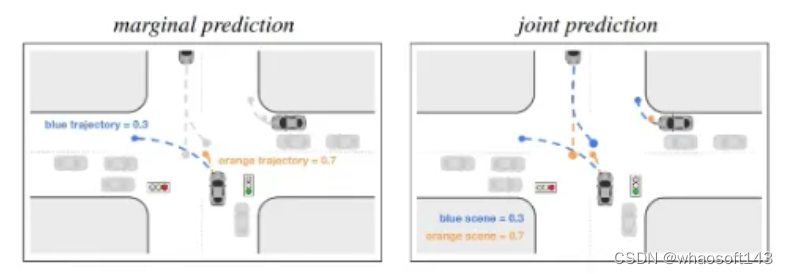
A2:做的是marginal prediction不是joint prediction;2. prediction和planning是分开来做的,没有显式考虑ego和周围agent的交互博弈;3.用的是scene-centric representation,没有考虑对称性,效果必拉
Q2:啥是marginal prediction啊
A:具体可以参考scene transformer
Q3:关于第三点,scene centric没有考虑对称性,怎么理解呢
A:建议看HiVT, QCNet, MTR++.当然对于端到端模型来说对称性的设计也不好做就是了
A2:可以理解成输入的是scene的数据,但在网络里会建模成以每个目标为中心视角去看它周边的scene,这样你就在forward里得到了每个目标以它自己为中心的编码,后续可以再考虑这些编码间的交互
4. 什么是以agent为中心?
A:每个agent有自己的local region,local region是以这个agent为中心
5.轨迹预测里yaw和heading是混用的吗
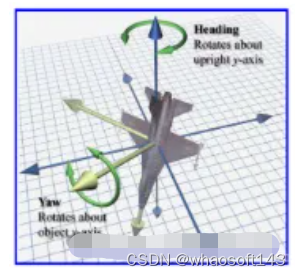
A:可以理解为车头朝向
6.argoverse地图中的has_traffic_control这个属性具体代表什么意思?
A:其实我也不知道我理解的对不对,我猜是指某个lane是否被红绿灯/stop sign/限速标志等所影响
7. 请问Laplace loss和huber loss 对于轨迹预测而言所存在的优劣势在哪里呢?如果我只预测一条车道线的话
A:两个都试一下,哪个效果好哪个就有优势。Laplace loss要效果好还是有些细节要注意的
Q2:是指参数要调的好吗
A:Laplace loss相比L1 loss其实就是多预测了一个scale参数
Q3:对的 但似乎这个我不知道有啥用 如果只预测一个轨迹的话。感觉像是多余的。我把它理解为不确定性 不知道是否正确
A:如果你从零推导过最小二乘法就会知道,MSE其实是假设了方差为常数的高斯分布的NLL。同理,L1 loss也是假设了方差为常数的Laplace分布的NLL。所以说LaplaceNLL也可以理解为方差非定值的L1 loss。这个方差是模型自己预测出来的。为了使loss更低,模型会给那些拟合得不太好的样本一个比较大的方差,而给拟合得好的样本比较小的方差
Q4:那是不是可以理解为对于非常随机的数据集【轨迹数据存在缺帧 抖动】 就不太适合Laplace 因为模型需要去拟合这个方差?需要数据集质量比较高
A:这个说法我觉得不一定成立。从效果上来看,会鼓励模型优先学习比较容易拟合的样本,再去学习难学习的样本
Q5:还想请问下这句话(Laplace loss要效果好还是有些细节要注意的)如何理解 A:主要是预测scale那里。在模型上,预测location的分支和预测scale的分支要尽量解耦,不要让他们相互干扰。预测scale的分支要保证输出结果>0,一般人会用exp作为激活函数保证非负,但是我发现用ELU +1会更好。然后其实scale的下界最好不要是0,最好让scale>0.01或者>0.1啥的。以上都是个人看法。其实我开源的代码(周梓康大佬的github开源代码)里都有这些细节,不过可能大家不一定注意到。
给出链接:https://github.com/ZikangZhou/QCNet
https://github.com/ZikangZhou/HiVT
8. 有拿VAE做轨迹预测的吗,给个链接!
https://github.com/L1aoXingyu/pytorch-beginner/tree/master/08-AutoEncoder
9. 请问大伙一个问题,就是Polyline到底是啥?另外说polyline由向量Vector组成,这些Vector是相当于节点吗?
A:Polyline就是折线,折线就是一段一段的,每一段都可以看成是一段向量Q2:请问这个折线段和图神经网络的节点之间的边有关系吗?或者说Polyline这个折现向量相当于是图神经网络当中的节点还是边呀?A:一根折线可以理解为一个节点。轨迹预测里面没有明确定义的边,边如何定义取决于你怎么理解这个问题。Q3: VectorNet里面有很多个子图,每个子图下面有很多个Polyline,把Polyline当做向量的话,就相当于把Polyline这个节点变成了向量,相当于将节点进行特征向量化对吗?然后Polyline里面有多个Vector向量,就是相当于是构成这个节点的特征矩阵么?A: 一个地图里有很多条polyline;一个Polyline就是一个子图;一个polyline由很多段比较短的向量组成,每一段向量都是子图上的一个节点10. 有的论文,像multipath++对于地图两个点就作为一个单元,有的像vectornet是一条线作为一个单元,这两种有什么区别吗?
A: 节点的粒度不同,要说效果的话那得看具体实现;速度的话,显然粒度越粗效率越高Q2:从效果角度看,什么时候选用哪种有没有什么原则?A: 没有原则,都可以尝试11.有什么可以判断score的平滑性吗? 如果一定要做的话
A: 这个需要你输入是流动的输入比如0-19和1-20帧然后比较两帧之间的对应轨迹的score的差的平方,统计下就可以了
Q2: Thomas老师有哪些指标推荐呢,我目前用一阶导数和二阶导数。但好像不是很明显,绝大多数一阶导和二阶导都集中在0附近。
A: 我感觉连续帧的对应轨迹的score的差值平方就可以了呀,比如你有连续n个输入,求和再除以n。但是scene是实时变化的,发生交互或者从非路口到路口的时候score就应该是突变的
12.hivt里的轨迹没有进行缩放吗,就比如×0.01+10这种。分布尽可能在0附近。我看有的方法就就用了,有的方法就没有。取舍该如何界定?
A:就是把数据标准化归一化呗。可能有点用 但应该不多
13.HiVT里地图的类别属性经过embedding之后为什么和数值属性是相加的,而不是concat?
A:相加和concat区别不大,而对于类别embedding和数值embedding融合来说,实际上完全等价
Q2: 完全等价应该怎么理解?
A: 两者Concat之后再过一层线性层,实际上等价于把数值embedding过一层线性层以及把类别embedding过一层线性层后,两者再相加起来.把类别embedding过一层线性层其实没啥意义,理论上这一层线性层可以跟nn.Embeddding里面的参数融合起来
14.作为用户可能更关心的是,HiVT如果要实际部署的话,最小的硬件要求是多少?
A:我不知道,但根据我了解到的信息,不知道是NV还是哪家车厂是拿HiVT来预测行人的,所以实际部署肯定是可行的
15. 基于occupancy network的预测有什么特别吗?有没有论文推荐?
A:目前基于occupancy的未来预测的方案里面最有前途的应该是这个:https://arxiv.org/abs/2308.01471
16.考虑规划轨迹的预测有什么论文推荐吗?就是预测其他障碍物的时候,考虑自车的规划轨迹?
A:这个可能公开的数据集比较困难,一般不会提供自车的规划轨迹。上古时期有一篇叫做PiP的,港科Haoran Song。我感觉那种做conditional prediction的文章都可以算是你想要的,比如M2I
17.有没有适合预测算法进行性能测试的仿真项目可以学习参考的呢
A(stu):这个论文有讨论:Choose Your Simulator Wisely A Review on Open-source Simulators for Autonomous Driving
18.请问如何估计GPU显存需要多大,如果使用Argoverse数据集的话,怎么算
A:和怎么用有关系,之前跑hivt我1070都可以,现在一般电脑应该都可以
# 巧用NeRF生成的自动驾驶仿真数据
神经辐射场(NeRF)已成为推进自动驾驶(AD)重新搜索的有前途的工具,提供可扩展的闭环模拟和数据增强功能。然而,为了信任模拟中获得的结果,需要确保AD系统以相同的方式感知真实数据和渲染数据。尽管渲染方法的性能正在提高,但许多场景在忠实重建方面仍然具有固有的挑战性。为此,我们提出了一种新的视角来解决真实数据与模拟数据之间的差距。我们不只是专注于提高渲染保真度,而是探索简单而有效的方法,在不影响真实数据性能的情况下,增强感知模型对NeRF伪影的鲁棒性。此外,我们使用最先进的神经渲染技术,首次对AD设置中的真实到模拟数据间隙进行了大规模调查。具体来说,我们在真实和模拟数据上评估了对象检测器和在线映射模型,并研究了不同预训练策略的效果。我们的结果显示,模型对模拟数据的稳健性显著提高,甚至在某些情况下提高了真实世界的性能。最后,我们深入研究了真实到模拟间隙与图像重建指标之间的相关性,将FID和LPIPS确定为强指标。
在本文中,我们提出了一种新的视角来缩小智驾系统不同感知模块的真实数据和模拟数据之间的差距。我们的目标不是提高渲染质量,而是在不降低真实数据性能的情况下,使感知模型对NeRF伪影更具鲁棒性。我们认为,这一方向是对提高NeRF性能的补充,也是实现可扩展虚拟AV测试的潜在关键。作为朝着这个方向迈出的第一步,我们表明,即使是简单的数据增强技术也会对模型对NeRF伪影的鲁棒性产生很大影响。
此外,我们对大规模AD数据集进行了首次广泛的real2sim gap研究,并评估了多个目标检测器以及在线建图模型对真实数据和最先进(SOTA)神经渲染方法数据的性能。我们的研究包括训练过程中不同数据增强技术的影响,以及推理过程中NeRF渲染的保真度。我们发现,在模型微调过程中集成这些数据显著增强了它们对模拟数据的鲁棒性,在某些情况下,甚至提高了对真实数据的性能。最后,我们研究了real2sim间隙和常见图像重建指标之间的相关性,以深入了解将NeRFs用作AD数据模拟器的重要意义。我们发现LPIPS和FID是real2sim差距的有力指标,并进一步证实了我们提出的增强降低了对较差视图合成的敏感性。
方法详解
NeRF驱动的模拟引擎可以大大加速AD功能的测试和验证,因为它们可以使用已经收集的数据探索新的虚拟场景。然而,为了使此类模拟结果可信,AD系统在暴露于渲染数据和真实数据时必须以相同的方式运行。以前,这已经通过渲染更真实的传感器数据来改进模拟来解决。在这项工作中,我们提出了一种替代和补充的方法,即我们调整AD系统,使其对真实数据和模拟数据之间的差异不那么敏感。
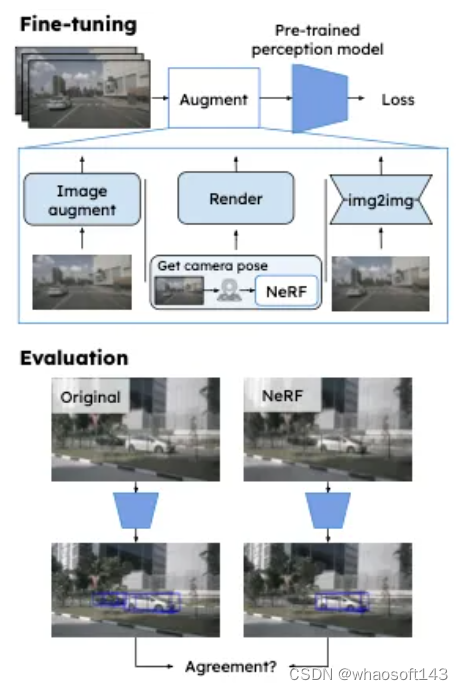
作为朝着这个方向迈出的第一步,我们探索了不同的微调策略如何使感知模型对渲染数据中的伪影更具鲁棒性。具体来说,在给定已经训练好的模型的情况下,我们使用图像来微调感知模型,这些图像旨在提高渲染图像的性能,同时保持真实数据的性能,见图2。除了减少real2sim差距外,这还可能降低对传感器真实性的要求,为神经渲染方法的更广泛应用开辟道路,并减少对所述方法的训练和评估的计算需求。请注意,当我们专注于感知模型时,我们的方法也可以很容易地扩展到端到端模型。
最后,我们可以想象多种方法来实现使模型更健壮的目标,例如从领域自适应和多任务学习文献中汲取灵感。然而,微调需要最小的模型特定调整,使我们能够轻松地研究一系列模型。
Image augmentations
获得对伪影增强鲁棒性的经典策略是使用图像增强。在这里,我们选择增强来表示渲染图像中存在的各种失真。更具体地说,我们添加随机高斯噪声,将图像与高斯模糊核卷积,应用类似于SimCLR中发现的光度失真,最后对图像进行下采样和上采样。增广是按顺序应用的,每个增广都有一定的概率。
Fine-tuning with mixed-in rendered images

Image-to-image translation
如前所述,渲染NeRF数据是一种昂贵的数据增强技术。此外,除了感知任务所需的数据外,它还需要顺序数据和潜在的额外标记。也就是说,为了获得可扩展的方法,我们理想地想要一种有效的策略来获得单个图像的NeRF数据。为此,我们建议使用图像对图像的方法来学习生成类NeRF图像。给定真实图像,该模型将图像转换到NeRF域,有效地引入了NeRF的典型伪影。这使我们能够在有限的计算成本下,在微调过程中大幅增加类NeRF图像的数量。我们使用渲染图像Dnerf及其相应的真实图像来训练图像到图像模型。不同增强策略的可视化示例见图3。

结果
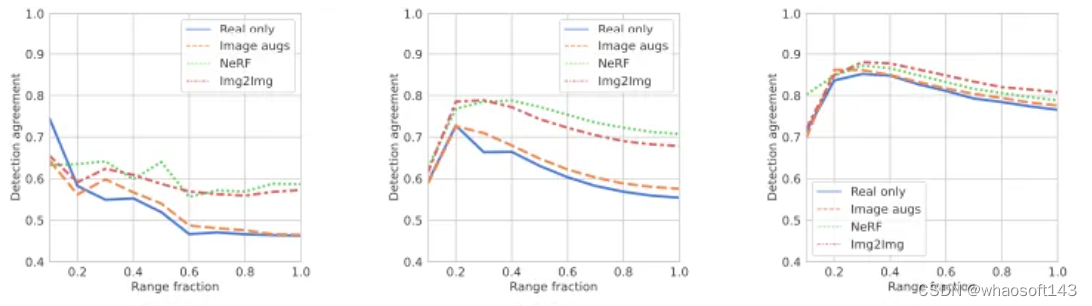

结论
神经辐射场(NeRF)已成为模拟自动驾驶(AD)数据的一种很有前途的途径。然而,为了实用,必须了解AD系统在模拟数据上执行的行为是如何转换为真实数据的。我们的大规模调查揭示了暴露于模拟图像和真实图像的感知模型之间的性能差距。
与早期专注于提高渲染质量的方法不同,本文研究了如何改变感知模型,使其对NeRF模拟数据更具鲁棒性。我们表明,使用NeRF或类似NeRF的数据进行微调,在不牺牲真实数据性能的情况下,大大减少了对象检测和在线映射方法的real2sim间隙。此外,我们还表明,在现有的列车分布之外生成新的场景,例如模拟车道偏离,可以提高实际数据的性能。对NeRF社区内常用图像指标的研究表明,LPIPS和FID分数与感知性能表现出最强的相关性。这表明,与单纯的重建质量相比,感知相似性对感知模型具有更大的意义。
总之,我们认为NeRF模拟数据对AD有价值,尤其是当使用我们提出的方法来增强感知模型的稳健性时。此外,NeRF数据不仅有助于在模拟数据上测试AD系统,而且有助于提高感知模型在真实数据上的性能。
# 3D视觉绕不开的点云配准
作为点集合的点云有望在3D重建、工业检测和机器人操作中,在获取和生成物体的三维(3D)表面信息方面带来一场改变。最具挑战性但必不可少的过程是点云配准,即获得一个空间变换,该变换将在两个不同坐标中获取的两个点云对齐并匹配。这篇综述介绍了点云配准的概述和基本原理,对各种方法进行了系统的分类和比较,并解决了点云配准中存在的技术问题,试图为该领域以外的学术研究人员和工程师提供指导,并促进对点云配准统一愿景的讨论。
点云获取的一般方式
分为主动和被动方式,由传感器主动获取的点云为主动方式,后期通过重建的方式为被动。
从SFM到MVS的密集重建。(a) SFM。(b) SfM生成的点云示例。(c) PMVS算法流程图,一种基于patch的多视角立体算法。(d) PMVS生成的密集点云示例。
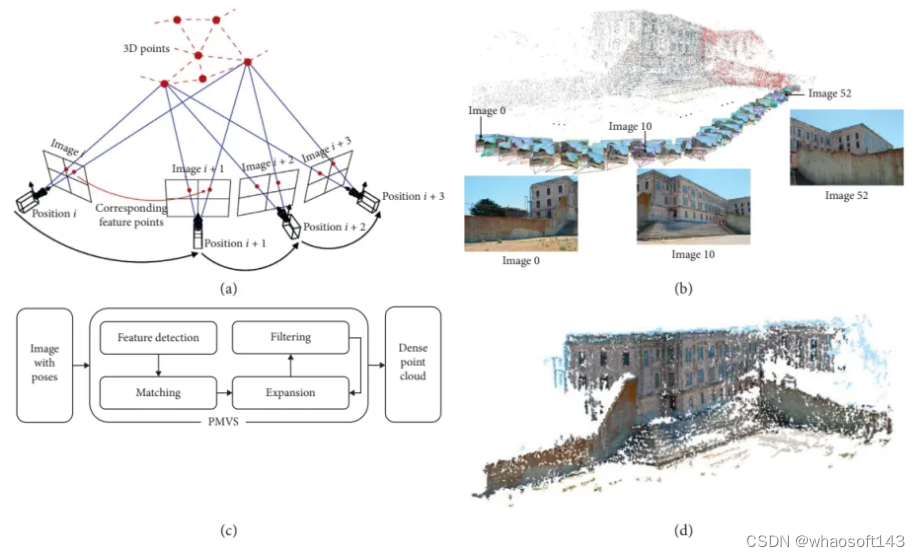
结构光重建方法:
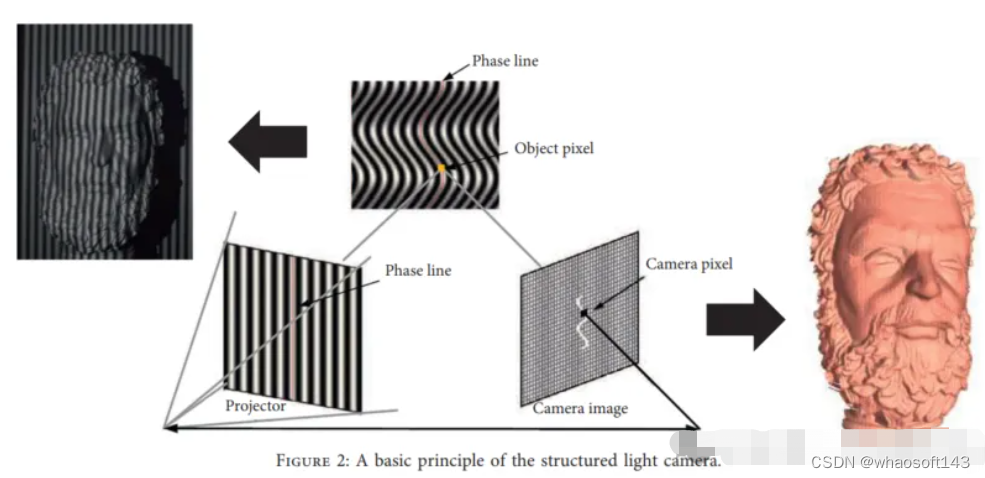
刚性配准和非刚性配准
刚性配准假设在一个环境中,变换可以分解为旋转和平移,从而在适当的刚性变换后,一个点云被映射到另一点云,同时保持相同的形状和大小。
在非刚性配准中,建立非刚性变换以将扫描数据wrap到目标点云。非刚性变换包含反射、旋转、缩放和平移,而不是刚性配准中仅包含平移和旋转。非刚性配准的使用主要有两个原因:(1) 数据采集的非线性和校准误差会导致刚性物体扫描的低频扭曲;(2) 对随着时间改变其形状的和移动场景或目标执行配准。
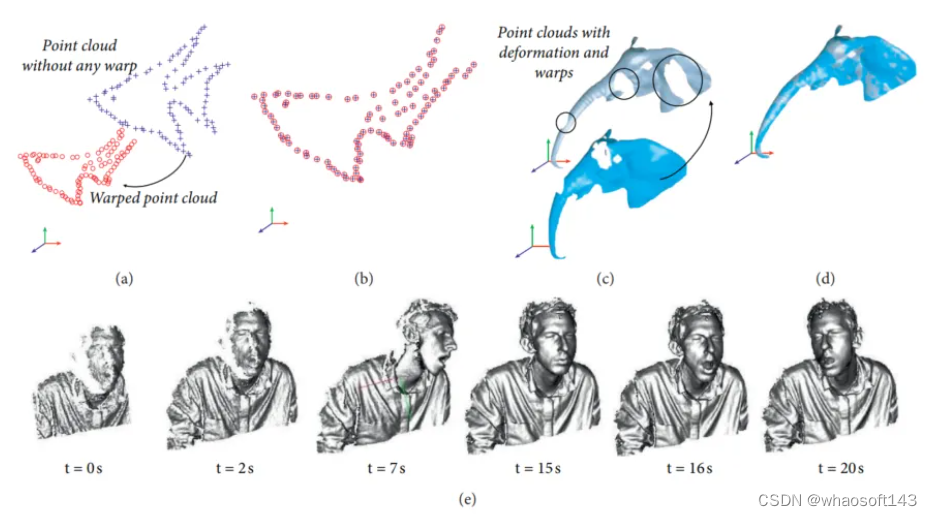
刚性配准的示例:(a)两个点云:读取点云(绿色)和参考点云(红色);在不使用(b)和使用(c)刚性配准算法的情况下,点云融合到公共坐标系中。

然而,点云配准的性能被Variant Overlap、噪声和异常值、高计算成本、配准成功的各种指标受限。
配准的方法有哪些?
在过去的几十年里,人们提出了越来越多的点云配准方法,从经典的ICP算法到与深度学习技术相结合的解决方案。
1)ICP方案
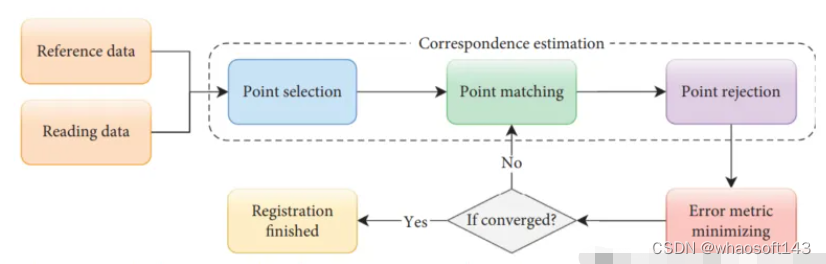
ICP算法是一种迭代算法,可以在理想条件下确保配准的准确性、收敛速度和稳定性。从某种意义上说,ICP可以被视为期望最大化(EM)问题,因此它基于对应关系计算和更新新的变换,然后应用于读取数据,直到误差度量收敛。然而,这不能保证ICP达到全局最优,ICP算法可以大致分为四个步骤:如下图所示,点选择、点匹配、点拒绝和误差度量最小化。
2)基于特征的方法
正如我们在基于ICP的算法中所看到的,在变换估计之前,建立对应关系是至关重要的。如果我们获得描述两个点云之间正确关系的适当对应关系,则可以保证最终结果。因此,我们可以在扫描目标上粘贴地标,或者在后处理中手动拾取等效点对,以计算感兴趣点(拾取点)的变换,这种变换最终可以应用于读取点云。如图12(c)所示,点云加载在同一坐标系中,并绘制成不同的颜色。图12(a)和12(b)显示了在不同视点捕获的两个点云,分别从参考数据和读取数据中选择点对,配准结果如图12(d)所示。然而,这些方法对不能附着地标的测量对象既不友好,也不能应用于需要自动配准的应用。同时,为了最小化对应关系的搜索空间,并避免在基于ICP的算法中假设初始变换,引入了基于特征的配准,其中提取了研究人员设计的关键点。通常,关键点检测和对应关系建立是该方法的主要步骤。
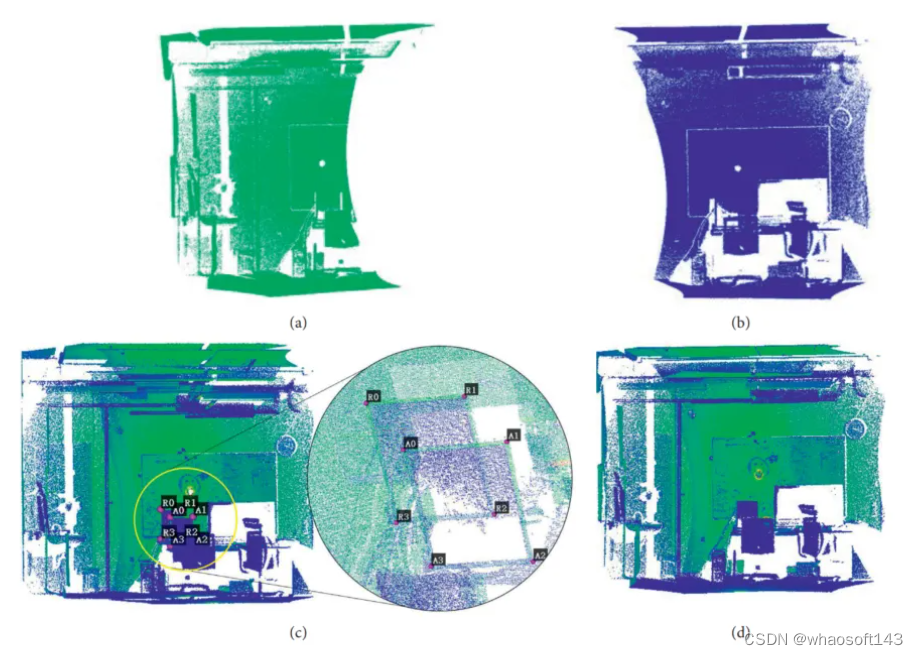
关键点提取的常用方法包括PFH、SHOT等,设计一种算法来去除异常值和有效地基于inliers的估计变换同样很重要。
3)基于学习的方法
在使用点云作为输入的应用程序中,估计特征描述符的传统策略在很大程度上依赖于点云中目标的独特几何特性。然而,现实世界的数据往往因目标而异,可能包含平面、异常值和噪声。此外,去除的失配通常包含有用的信息,可以用于学习。基于学习的技术可以适用于对语义信息进行编码,并且可以在特定任务中推广。大多数与机器学习技术集成的配准策略比经典方法更快、更稳健,并灵活地扩展到其他任务,如物体姿态估计和物体分类。同样,基于学习的点云配准的一个关键挑战是如何提取对点云的空间变化不变、对噪声和异常值更具鲁棒性的特征。
基于学习的方法代表作为:PointNet 、PointNet++ 、PCRNet 、Deep Global Registration 、Deep Closest Point、Partial Registration Network 、Robust Point Matching 、PointNetLK 、3DRegNet。
4)具有概率密度函数的方法
基于概率密度函数(PDF)的点云配准,使得使用统计模型进行配准是一个研究得很好的问题,该方法的关键思想是用特定的概率密度函数表示数据,如高斯混合模型(GMM)和正态分布(ND)。配准任务被重新表述为对齐两个相应分布的问题,然后是测量和最小化它们之间的统计差异的目标函数。同时,由于PDF的表示,点云可以被视为一个分布,而不是许多单独的点,因此它避免了对对应关系的估计,并具有良好的抗噪声性能,但通常比基于ICP的方法慢。
5)其它方法
Fast Global Registration 。快速全局配准(FGR)为点云配准提供了一种无需初始化的快速策略。具体来说,FGR对覆盖的表面的候选匹配进行操作并且不执行对应关系更新或最近点查询,该方法的特殊之处在于,可以直接通过在表面上密集定义的鲁棒目标的单个优化来产生联合配准。然而,现有的解决点云配准的方法通常在两个点云之间产生候选或多个对应关系,然后计算和更新全局结果。此外,在快速全局配准中,在优化中会立即建立对应关系,并且不会在以下步骤中再次进行估计。因此,避免了昂贵的最近邻查找,以保持低的计算成本。结果,迭代步骤中用于每个对应关系的线性处理和用于姿态估计的线性系统是有效的。FGR在多个数据集上进行评估,如UWA基准和Stanford Bunny,与点对点和点顶线的ICP以及Go ICP等ICP变体进行比较。实验表明FGR在存在噪声的情况下表现出色!
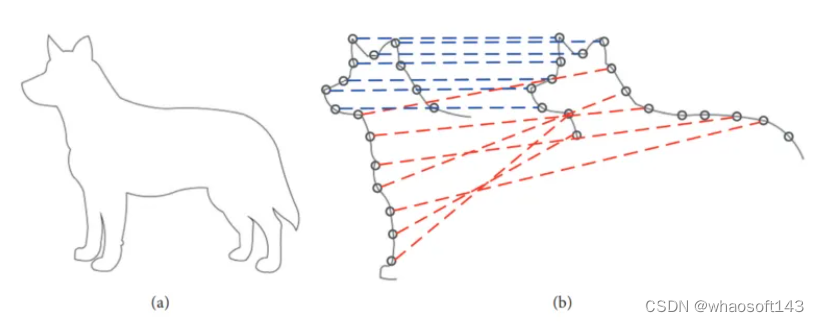
四点一致集算法:4点全等集(4PCS)提供了用于读取数据的初始变换,而不需要起始位置假设。通常,两点云之间的刚性配准变换可以由一对三元组唯一定义,其中一个来自参考数据,另一个来自读取数据。然而,在这种方法中,它通过在小的潜在集合中搜索来寻找特殊的 4-points bases,即每个点云中的4共面全等点,如图27所示。在最大公共点集(LCP)问题中求解最佳刚性变换。当成对点云的重叠率较低并且存在异常值时,该算法实现了接近的性能。为了适应不同的应用,许多研究人员介绍了与经典4PCS解决方案相关的更重要的工作。
# 开源驾驶仿真平台大汇总
本文的详细版本敬请期待 Choose Your Simulator Wisely: A Review on Open-source Simulators for Autonomous Driving。这篇论文中:
- 回顾了驾驶仿真器至今为止发展历史,预测了之后可能的发展趋势;
- 调研了截止2023年为止具有一定影响力的开源驾驶仿真器的维护状态、功能、性能、适用场景,基于用途,对现有驾驶仿真器进行了分类和推荐;
- 论证了目前开源驾驶仿真器中存在的关键问题,主要划分为真实性和仿真性能两大方面,讨论了这些关键问题的重要性,并调研了可能的解决方案。
论文目前处于Early Access状态,完整版估计要下个月才会上线。
动机
博士生涯之初,因为对CV不是那么感兴趣,我强转去研究驾驶决策算法,并一度沉迷强化学习。然而,在验证算法性能之前,找到合适的实验平台和benchmark是非常重要的。而调研过程中,我发现开源驾驶仿真器充斥着各式各样的问题,导致基于仿真验证的驾驶决策算法在投稿时容易因为不具有实用性遭到质疑。近年来,开源的驾驶仿真平台层出不穷,但是由于性能、维护状态等问题,它们不一定有让研究者能更轻松地在这个领域起步,反而是多了一个个需要亲自趟过的坑。
这种情况下,我们有必要对适用于自动驾驶相关任务的仿真器进行较为全面的调研,检查目前仍然值得使用的开源驾驶仿真器还有哪些,并讨论现有开源仿真器中存在的局限,从而有意识地避免由于相关方面的算法验证实验不够充分导致的质疑。另一方面,本文也可以视为对开源驾驶仿真器的开发者的建议,从用户的角度列举许愿了目前呼声较高的待解决的关键问题,有利于开发者们更有针对性地优化自己的仿真器。
历史
驾驶仿真器的发展历史与本篇博客的关联性不大,在此略过。
总览
筛选标准
在回顾仿真器历史和分类仿真器的过程中,由于商业仿真器在某些任务上具有开源仿真器不可比拟的优势——有些领域中甚至是商业仿真器独大的,因此我们必须将它们纳入调研范围。但是在推荐工具和讨论现有不足的环节,考虑本文主要面对的是广大资源体量较小的学术实验室和个人研究者(而且我也没有拿到那么多授权),所以会回退到仅讨论开源仿真器的状态。
因为近年来发布的仿真器数量较多,而我们人手有限,所以在调研过程开始前,设置了几条较为简单粗暴的基准来筛选候选仿真器,若有遗漏还请多多包涵:
- 商业仿真器的调研主要基于工业界合作方和专家推荐,需要该仿真器有可访问的官方网站;
- 开源仿真器的论文在google scholar上已有大于等于100的引用量;
- 开源仿真器的仓库有大于100的star;
考虑到手头资源的局限性,我们没有实际测试各个仿真器的硬件在环测试(Hardware-in-the-loop testing)能力,而是总结了软件所有者在网站/论文中自我声明的支持水平。
目前不同类型的仿真器大致情况如表所示。我们判定维护状态的方式是检查该软件在一年的时间内是否有进行过任何类型的更新,若没有则视为不再积极维护,若最近更新恰好是在一年左右,则标注为问号,一年以内有更新则视为正常维护状态。完整表格请见正式发表的论文。
分类
本节对于上表中的仿真器类别定义进行简单的说明,并基于相关任务推荐开源仿真器(在正式论文中有更详细的表格列举不同类型仿真器的具体功能)。
交通流仿真器
这类仿真器主要用于模拟大规模的车流在交通系统中的运行状态,它们的特征一般包括可以编辑的路网结构、微观交通流,并通常采用模式较为单一的驾驶行为模型操纵车辆。自动驾驶中研究车路协同、车队、联网智能车(Connected and Autonomous Vehicle, CAV) 相关的任务可以用到这类仿真器。这类仿真器中,目前还处于积极维护状态的热门开源仿真器只有SUMO。
传感数据仿真器
这类仿真器的目的是弥补真实数据中缺少极端天气样本,增强感知模型的泛化性。它们追求的是在各类不同光照、能见度、反光率等状态下,通过渲染或学习类方法生成高真实性的光学类感知数据(RGB图像、语义分割、实例分割、甚至是激光雷达)。因为这类仿真器的开发成本高、难度大,而实际收益较低,相关的开源仿真器已经基本停止维护。如果有利用仿真器生成训练/测试感知数据的需求,目前较为合适的选项是综合型仿真器CARLA。
驾驶决策仿真器
驾驶决策仿真器是指用途仅为验证驾驶决策算法的仿真器,它们与综合型仿真器的主要区别在于,为了节约开发成本,这些仿真器往往省略或简化了车辆动力学模型的建模,也无法生成真实的原始感知数据。大部分驾驶决策仿真器只提供了鸟瞰视角的语义分割数据,不过,相应地,在多智能体并行仿真、交通参与物行为模式模拟方面,它们往往有更好的表现。对于模仿学习算法的研究者来说,只要保证环境能够提供理想的环境感知结果,决策模型的运行基本可以脱离环境,所以选择仿真器时会有更大的自由度。除了VDrift,其他积极维护中的仿真环境基本都提供了原生的RL训练支持,所以也可以基于需求选择。MetaDrive作为一款轻量级的、有3D图像界面、可以无限生成交通场景的仿真器,在训练端对端的驾驶决策模型时较为推荐。
车辆动力学仿真器
这类仿真器主要模拟的是车辆的物理运动表现,早早在车辆设计工程中有所应用,因此历史悠久。在自动驾驶相关的任务中,车辆控制通常需要在高真实性的车辆动力学仿真器上验证。这类仿真器需要收集大量实车在各类极限状态下的行为数据,这意味着,如果没有与车辆制造商的紧密合作,想凭空建模一个准确的车辆物理模型是几乎不可能的。这类仿真器的开发也不出意外地被一些老牌商业软件所垄断。开源软件中,机器人学中常用的Gazebo是为数不多可用的选项,而基于Matlab的车辆动力学在学界的实践中也较为常见(工业界的请不要来得瑟了,卑微.jpg)。
综合型仿真器
综合型仿真器是能为多个自动驾驶相关任务提供仿真验证的软件。在Nvidia Drive Sim可能的开源之前,开源软件中,能够独占鳌头的工作,毫无悬念地是CARLA。
说起来也挺好笑的,前几年调研时看好的LGSVL和AirSim都转成Archive模式了,只能说仿真本身是真的难做 ಥ_ಥ
关键问题
目前开源仿真器普遍面临真实性、仿真效率方面的问题。这里提供对关键问题的简单描述,对于可能改进方法的调研请见论文。
真实性-感知数据
感知模块面临一大挑战是算法的泛化性。即使是物体检测这类基础任务,在极端天气时,感知模型的性能也会大幅度下降。通过收集真实数据确实可以解决这个问题,但是极端天气在现实中的出现往往非常随机,想创造相关的大规模数据集对时间和成本要求都很高。有必要充分发挥仿真器的优势,去生成更真实的不同模态的原始感知数据。
其实,在游戏开发领域,已经积累了大量渲染相关的技术基础,如果能在仿真器中应用这些技术自然是最好的。但考虑到游戏的图像渲染未必能在真实性上达到要求,另外一种思路是仿真器提供原生接口,允许接入基于学习的图像生成/风格处理类型的算法,访问三维建模,并直接对其进行处理。
真实性-交通场景
交通场景中主要可以分成几个部分:静态的地图和交通标志、随时间规律变化的交通规则(指红绿灯等)、和随机性强的交通参与物。地图和交通规则主要是在自动构建方面存在瓶颈,影响了仿真器的发展,这个之后会说明。而影响交通场景真实性的主要因素是交通参与物的行为模型。前几年,大部分仿真器中要么提供基于统一规则的行为模型,仅在参数上有一定多样性;要么直接规避掉这个问题,只提供记录回放功能。近年来,InterSim,TBSim的出现反应了相关问题在逐渐得到重视,但仍然需要进一步的研究。
真实性-车辆模型
车辆模型的真实性一直是阻碍基于仿真器验证的自动驾驶系统直接上实车的拦路虎。正如前文提到的,独立的研究者们想要分头解决这个问题是不现实的,理想主义的情况下,要么等待车辆制造商良心发现,公布他们的核心机密,或者大家可以基于手头的实车,共享一些实体个例实验车辆的运行记录,创建符合某种社区规范的公共数据集。事实上,在现实中这两种模式都基本是幻想,这边也就做做梦。
仿真效率-数据准备-格式不一致性
现在很多开源仿真器对于公开轨迹数据集、地图格式的支持还有所不足,导致研究者们反复造轮子,或者为了使用特定的数据集/地图格式而在某几个仿真器之间跳来跳去。这极大地拖慢了仿真数据的准备过程。
仿真效率-数据准备-手动地图标注
目前的地图标注过程中仍有大量手工劳动的成分,OpenDRIVE地图如此,三维高精地图更是如此。这对于批量创造多样化的交通场景来说是一个瓶颈。近年来,快速自动构建地图的算法在大力发展,NeRF基本可以说是无人不晓,但是NeRF在数据格式和粒度方面显然都还无法达到工程要求,需要进一步发展。
仿真效率-运行速度
因为开源仿真器的开发者大部分是在为爱发电,势单力薄,在仿真软件的性能、远程/分布式部署、并行运算等方面显然难以做到尽善尽美。甚至有一部分开源仿真器不一定能够实时运行,想要以现实的多倍速加速训练和测试过程更是相当困难,但这往往是用户需求最强烈的问题,所以有必要进行优化。
仿真效率-迁移-HIL测试
开源仿真器与商业软件的一大差距也在于对HIL测试的支持。从表格中可以看出,有这一功能的开源仿真器寥寥无几。不过这主要是一个工程问题,搭建和维护HIL测试的接口都需要大量人力物力,只能说,用户在进行仿真测试的时候,需要注意被测算法往往距离上实车存在差距,并在描述实验设计时需要注意防范可能的漏洞。
# 3D-BBS:全局定位强势加速50倍
遥想当年Google大名鼎鼎的 Cartographer一经问世,掀起了激光SLAM的血雨腥风,其回环方法—— 2D 分支定界算法(Real-time loop closure in 2d LIDAR SLAM)把整个解空间用一棵树来表示,其根节点代表整个搜索窗口。树中的每一个节点的孩子节点都是对该节点所代表的搜索空间的一个划分,每个叶子节点都对应着一个解。整个搜索过程的基本思想可以总结为“缩小搜索空间”:先分支:不断地分割搜索空间;后定界:为每次分支之后的子节点确定一个上界。
然而,这些性能在 3D 地图中很难实现,因为内存消耗和处理成本急剧增加。
本文提出了一种准确快速的 3D 全局定位方法 3D-BBS,它扩展了现有的基于分支定界的 2D 扫描匹配算法。该方法平均只需要 878 ms 即可执行全局定位,并且在准确性和处理速度方面优于最先进的全局配准方法。为了优化整个算法在 3D 情况下的表现,主要贡献为:
- 本文提出的批处理 BnB 算法,可以在 GPU 上一次性快速进行大量分数计算
- 采用最佳优先搜索和旋转平移分支的组合:仅仅需要略微的近似,可以显著减少处理时间
- 利用通过稀疏哈希表创建的 3D 体素图,可以节省 3D 多分辨率体素图所需的内存
通过在模拟和真实环境中进行的实验,本文证明了3D-BBS只需在重力方向上粗略对齐的3D LiDAR点云和3D预建地图即可实现精确的全局定位。
原文链接:https://arxiv.org/pdf/2310.10023.pdf
代码链接:https://github.com/KOKIAOKI/3d_bbs
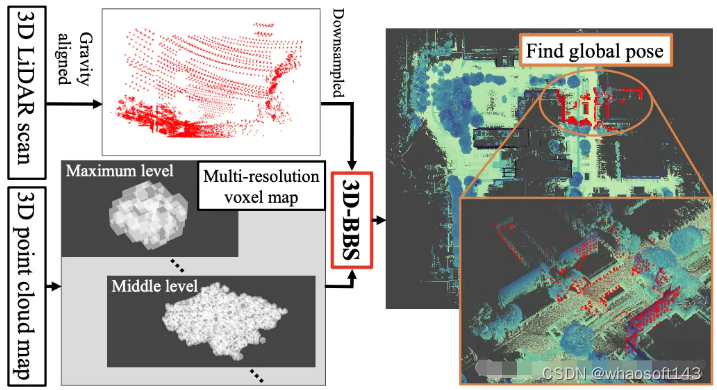
主要方法
问题定义
3D全局定位的已知条件有:
- 3D点云地图
- 待全局定位的当前帧点云
- 假设已知重力方向(e.g 由 IMU 测量获取)
待求解:6 自由度 pose: [x, y ,z, roll, pitch, yaw]
分支定界算法
使用层次树搜索来快速找到与全搜索结果等效的解决方案。树结构和叶节点分别表示搜索空间和问题的可行解。上层的节点表示一组子节点(即分支)。在每个非叶节点,计算其子节点分数的上限估计。如果计算出的上限低于临时最佳分数,我们可以用子节点修剪该节点,而无需近似(即修剪)。如果较早找到较高的临时最佳分数,BnB算法可以修剪许多节点,从而大大降低计算成本。因此,搜索顺序对于最大化 BnB 算法的性能(即搜索策略)非常重要。
用于 2D 全局定位的分支定界算法求的是 3 自由度 pose [x, y, yaw]

多分辨率体素地图

分支算法
分支规则

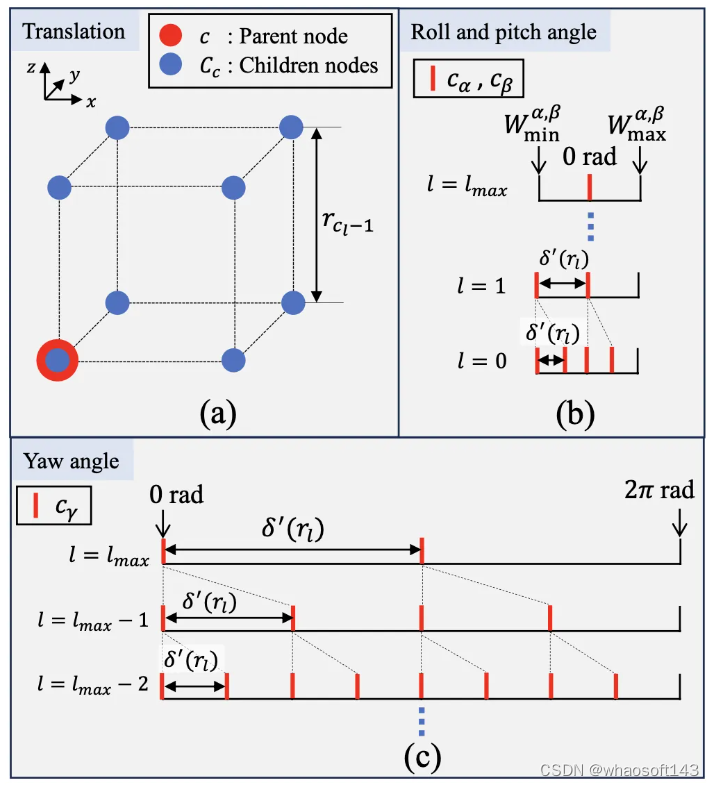

值得注意的是,通过引入以上角度分支,方程 12 中的上限估计变得不是严格精确。然而,如实验所示,我们凭经验证实它仅在所有情况下低估了上限 0.001%。
搜索策略
尽管从初始集合中删除估计上限小于分数阈值的节点,但队列中仍保留大量节点。这会导致寻找 DFS 最佳解决方案的延迟并增加处理时间。因此,本文采用 BFS 并按分数降序对 C 进行排序。由于 BFS 选择具有最佳上限分数的节点,因此当全局最佳分数接近最大分数时(即,当 LiDAR 扫描与地图有较大重叠时),它往往比 DFS 更快地找到解决方案。然而,在中间级别,BFS 需要分支大量高分节点,因为大多数输入点与膨胀的体素重叠。为了加速分支过程,我们为分数计算实现了 GPU 并行批处理。
GPU 加速的批量分支定界

实验
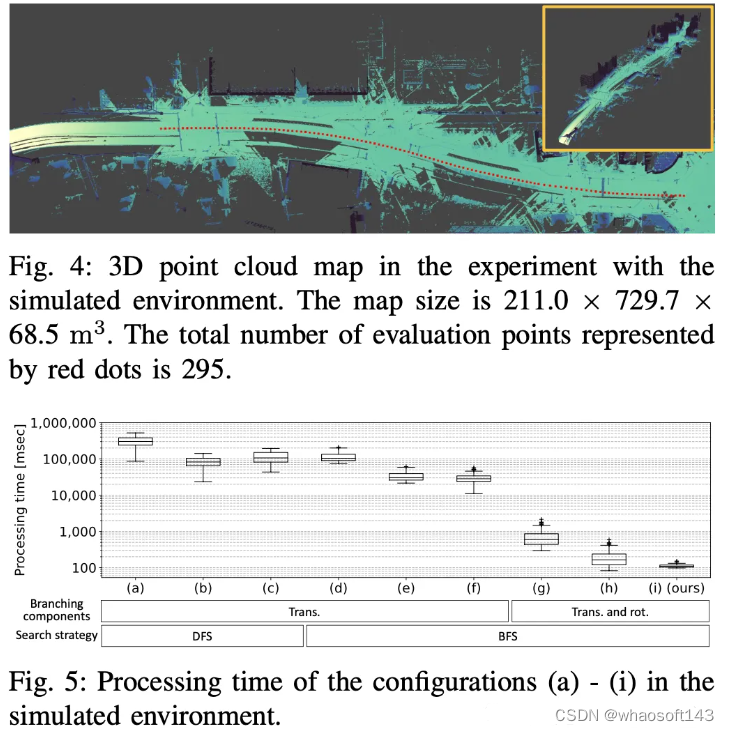
虚拟环境
实验设计了 9 种算法组合:处理类型(CPU 单线程、CPU 多线程(4 线程)和 GPU)、分支组件(仅平移、平移+旋转)、搜索策略的所有组合( DFS 和 BFS)

配置 (a) - (i) 成功估计了传感器位姿,其平移和旋转误差小于所有评估点的标准阈值。旋转分支仅在 0.001% 的情况下显示出错误的上限估计,相对于真实上限的平均误差约为 1.5%。这些结果表明旋转分支仅引入了一个小的近似值。

使用 BFS 的配置 (d) - (f) 比使用 DFS 的配置 (a) - (c) 稍快。由于BFS首先对临时得分最高的节点进行分支,因此当扫描点与地图有较大重叠(即解的得分接近最大得分)时,它可以更快地找到全局解。然而,需要计算大量的各个级别的节点。在配置 (g) - (i) 中,旋转分支和 BFS 的组合有助于显着减少处理时间。采用批处理的配置 (i) 与采用 CPU 单线程的配置 (g) 相比,处理时间减少了 50% 以上。采用 CPU 处理的配置 (g) 和 (h) 也展示了不到 1 秒的快速处理,因为模拟环境中的最高分数允许更快的修剪。
真实环境
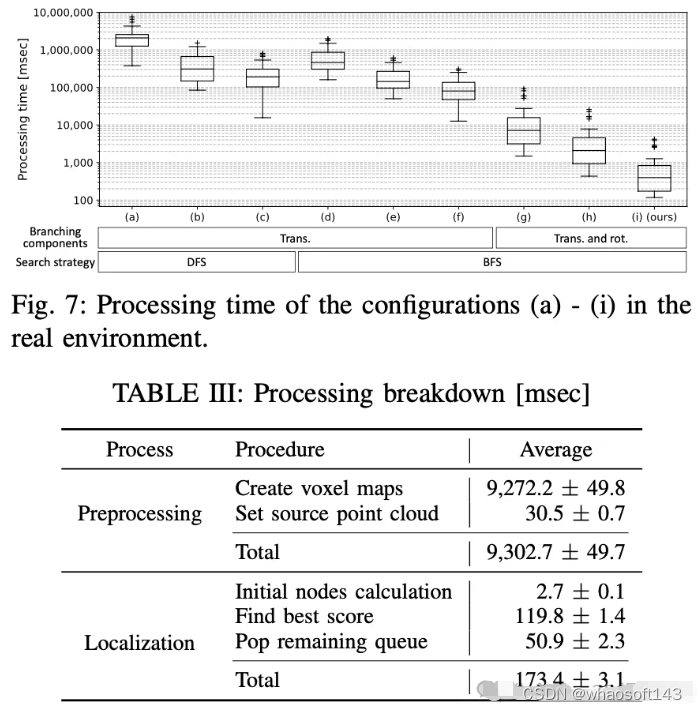
在真实数据上,与其他 SOTA 算法进行了对比:

结论
本文提出了一种基于BnB算法的3D全局定位方法,主要idea为:
- 使用稀疏哈希表来克服分层 3D 体素图的内存增加问题
- 提出了旋转平移分支和批量处理来减少处理时间
实验结果表明,3D-BBS准确估计了全局位姿,并在1秒内完成了定位过程。后续可扩展所提出的方法来处理极端情况(例如,退化区域或激光雷达扫描遮挡)。
# 相机与激光雷达是怎么标定的?行业所有主流的标定工具
相机与激光雷达的标定是很多任务的基础工作,标定精度决定了下游方案融合的上限,因为许多自动驾驶与机器人公司投入了较大的人力物力不断提升,今天也为大家盘点下常见的Camera-Lidar标定工具箱,建议收藏!
(1)Libcbdetect
一次拍摄多棋盘格检测:https://www.cvlibs.net/software/libcbdetect/
MATLAB代码实现,该算法自动提取角到亚像素精度,并将它们组合成(矩形)棋盘状图案。它可以处理各种图像(针孔相机、鱼眼相机、全向相机)。

(2)Autoware 标定包
Autoware 框架的激光雷达-相机标定工具包。
链接:https://github.com/autowarefoundation/autoware_ai_utilities/tree/master/autoware_camera_lidar_calibrator
(3)基于3D-3D匹配的靶标标定
基于3D-3D点对应关系的激光雷达相机标定,ROS包,出自论文《LiDAR-Camera Calibration using 3D-3D Point correspondences》!
链接:https://github.com/ankitdhall/lidar_camera_calibration
(4)上海 AI Lab OpenCalib
上海人工智能实验室出品,OpenCalib提供了一个传感器标定工具箱。工具箱可用于标定IMU、激光雷达、相机和Radar等传感器。
链接:https://github.com/PJLab-ADG/SensorsCalibration
(5)Apollo 标定工具
Apollo标定工具箱,链接:https://github.com/ApolloAuto/apollo/tree/master/modules/calibration
(6)Livox-camera标定工具
本方案提供了一个手动校准Livox雷达和相机之间外参的方法,已经在Mid-40,Horizon和Tele-15上进行了验证。其中包含了计算相机内参,获得标定数据,优化计算外参和雷达相机融合应用相关的代码。本方案中使用了标定板角点作为标定目标物,由于Livox雷达非重复性扫描的特点,点云的密度较大,比较易于找到雷达点云中角点的准确位置。相机雷达的标定和融合也可以得到不错的结果。
链接:https://github.com/Livox-SDK/livox_camera_lidar_calibration
中文文档:https://github.com/Livox-SDK/livox_camera_lidar_calibration/blob/master/doc_resources/README_cn.md

(7)CalibrationTools
CalibrationTools为激光雷达-激光雷达、激光雷达相机等传感器对提供标定工具。除此之外,还提供了:
1)定位-偏差估计工具估计用于航位推算(IMU和里程计)的传感器的参数,以获得更好的定位性能!
2)Autoware控制输出的可视化和分析工具;
3)用于修复车辆指令延迟的校准工具;
链接:https://github.com/tier4/CalibrationTools

(8)Matlab
Matlab自带的工具箱,支持激光雷达和相机的标定,链接:https://ww2.mathworks.cn/help/lidar/ug/lidar-and-camera-calibration.html
(9)ROS 标定工具
ROS Camera LIDAR Calibration Package,链接:https://github.com/heethesh/lidar_camera_calibration

(10)Direct visual lidar calibration
该软件包提供了一个用于激光雷达相机标定的工具箱:可通用:它可以处理各种激光雷达和相机投影模型,包括旋转和非重复扫描激光雷达,以及针孔、鱼眼和全向投影相机。无目标:它不需要标定目标,而是使用环境结构和纹理进行标定。单次拍摄:标定至少只需要一对激光雷达点云和相机图像。可选地,可以使用多个激光雷达相机数据对来提高精度。自动:标定过程是自动的,不需要初始猜测。准确和稳健:它采用了像素级直接激光雷达相机配准算法,与基于边缘的间接激光雷达相机配准相比,该算法更稳健和准确。
链接:https://github.com/koide3/direct_visual_lidar_calibration
(11)2D lidar-camera工具箱

链接:https://github.com/MegviiRobot/CamLaserCalibraTool
#基于相关滤波的目标跟踪算法
1. 相关滤波跟踪原理
相关滤波跟踪的基本思想就是,设计一个滤波模板,利用该模板与目标候选区域做相关运算,最大输出响应的位置即为当前帧的目标位置。

2. 2010 开篇
MOOSE
MOSSE (Minimum Output Sum of Squared Error filter)算法是相关滤波跟踪的开篇之作。
Bolme D S, Beveridge J R, Draper B A, et al. Visual object tracking using adaptive correlation filters [C]// CVPR, 2010.
为提高滤波器模板的鲁棒性,MOSSE利用目标的多个样本作为训练样本,以生成更优的滤波器。MOSSE 以最小化平方和误差为目标函数,用m个样本求最小二乘解,

3. 2012 循环移位
3.1 CSK
CSK针对MOSSE算法中采用稀疏采样造成样本冗余的问题,扩展了岭回归、基于循环移位的近似密集采样方法、以及核方法。
Henriques J F, Caseiro R, Martins P, et al. Exploiting the circulant structure of tracking-by-detection with kernels [C]// ECCV, 2012
- 岭回归
CSK为求解滤波模板的目标函数增加了正则项,

增加正则项的目的是为了防止过拟合,可以使求得的滤波器在下一帧图像中的泛化能力更强。
- 循环移位
CSK的训练样本是通过循环移位产生的。密集采样得到的样本与循环移位产生的样本很像,可以用循环移位来近似。循环矩阵原理如图,第一行是实际采集的目标特征,其他行周期性地把最后的矢量依次往前移产生的虚拟目标特征。

线性回归系数w就可以通过向量的傅里叶变换和对位点乘计算得到,

这样,滤波模板就可以通过向量的傅里叶变换和矩阵的点乘计算得到。
循环移位的样本集是隐性的,并没有真正产生过,只是在推导过程中用到,所以也不需要真正的内存空间去存储这些样本。
循环移位生成的近似样本集结合FFT极大地减少了计算量,但这种近似引入边界效应。边界效应的处理方法在后续章节中讨论。
- 核方法

- CSK算法流程
论文中给出了算法实现的Matlab参考代码。不使用核方法的实现更为简单直观。

4. 2014 多通道特征
MOSSE与CSK处理的都是单通道灰度图像。引入多通道特征扩展只需要对频域通道响应求和即可,后续章节会介绍其他的处理方法。HoG+CN在近年来的跟踪算法中常用的特征搭配,HoG是梯度特征,而CN(color names)是颜色特征,两者可以互补。
4.1 CN
CN其实是一种颜色命名方式,与RGB、HSV同属一类。CN在CSK的基础上扩展了多通道颜色。将RGB的3通道图像投影到11个颜色通道,分别对应英语中常用的语言颜色分类,分别是black, blue, brown, grey, green, orange, pink, purple, red, white, yellow,并归一化得到10通道颜色特征。也可以利用PCA方法,将CN降维到2维。
Danelljan M, Shahbaz Khan F, Felsberg M, et al. Adaptive color attributes for real-time visual tracking [C]// CVPR, 2014.
4.2 KCF/ DCF
KCF可以说是对CSK的完善。论文中对岭回归、循环矩阵、核技巧、快速检测等做了完整的数学推导。KCF在CSK的基础上扩展了多通道特征。KCF采用的HoG特征,核函数有三种高斯核、线性核和多项式核,高斯核的精确度最高,线性核略低于高斯核,但速度上远快于高斯核。
Henriques J F, Rui C, Martins P, et al. High-Speed Tracking with Kernelized Correlation Filters [J]. IEEE TPAMI, 2015.
5. 2014 多尺度跟踪
尺度变化是跟踪中比较基础和常见的问题,前面介绍的KCF/DCF和CN都没有尺度更新。如果目标缩小,滤波器就会学习到大量背景信息,如果目标扩大,滤波器可能会跟踪到目标局部纹理。这两种情况都可能出现非预期的结果,导致跟踪漂移和失败。
5.1 SAMF
SAMF基于KCF,特征是HoG+CN。SAMF实现多尺度目标跟踪的方法比较直接,类似检测算法里的多尺度检测方法。由平移滤波器在多尺度缩放的图像块上进行目标检测,取响应最大的那个平移位置及所在尺度。因此这种方法可以同时检测目标中心变化和尺度变化。
Li Y, Zhu J. A scale adaptive kernel correlation filter tracker with feature integration [C]// ECCV, 2014.
5.2 DSST
DSST将目标跟踪看成目标中心平移和目标尺度变化两个独立问题。首先用HoG特征的DCF训练平移相关滤波,负责检测目标中心平移。然后用HoG特征的MOSSE(这里与DCF的区别是不加padding)训练另一个尺度相关滤波,负责检测目标尺度变化。2017年发表的文章又提出了加速版本fDSST。
Danelljan M, Häger G, Khan F, et al. Accurate scale estimation for robust visual tracking [C]// BMVC, 2014.
Danelljan M, Hager G, Khan F S, et al. Discriminative Scale Space Tracking [J]. // IEEE TPAMI, 2017.
尺度滤波器仅需要检测出最佳匹配尺度而无须关心平移情况,其计算原理如图。DSST将尺度检测图像块全部缩小到同一个尺寸计算特征(CN+HoG),再将特征表示成一维(没有循环移位),尺度检测的响应图也是一维的高斯函数。

6. 2015 边界效应与更大的搜索区域
CSK引入了循环移位和快速傅里叶变换,极大地提高了算法的计算效率。但是离散傅里叶变换也带来了一个副作用:边界效应。
针对边界效应,有2个典型处理方法:在图像上叠加余弦窗调制;增加搜索区域的面积。
CSK采用了加余弦窗的方法,使搜索区域边界的像素值接近0,消除边界的不连续性。余弦窗的引入也带来了缺陷: 减小了有效搜索区域。例如在检测阶段,如果目标不在搜索区域中心,部分目标像素会被过滤掉。如果目标的一部分已经移出了这个区域,很可能就过滤掉仅存的目标像素。其作用表现为算法难以跟踪快速运动的目标。
扩大搜索区域能缓解边界效应,并提高跟踪快速移动目标的能力。但缺陷是会引入更多的背景信息,可能造成跟踪漂移。
SRDCF与CFLB的思路都是扩大搜索区域,同时约束滤波模板的有效作用域。
6.1 SRDCF
SRDCF(Spatially Regularized Correlation Filters)的思路是,给滤波模板增加一个约束,对接近边界的区域惩罚更大,或者说让边界附近滤波模板系数接近0。
Danelljan M, Hager G, Shahbaz Khan F, et al. Learning spatially regularized correlation filters for visual tracking [C]// ICCV. 2015.
SRDCF基于DCF,同时加入空域正则化,惩罚边界区域的滤波器系数,

正则项的引入破坏了DCF的闭合解。所以SRDCF采用高斯-塞德尔方法迭代优化,这也导致SRDCF速度比较慢。SRDCF与DCF得到的滤波模板对比如图。

6.2 CFLB/BACF
CFLB和BACF的思路是使搜索区域内,目标区域以外的像素为0。
Kiani Galoogahi H, Sim T, Lucey S. Correlation filters with limited boundaries [C]// CVPR, 2015.
Kiani Galoogahi H, Fagg A, Lucey S. Learning Background-Aware Correlation Filters for Visual Tracking [C]// ICCV, 2017.
CFLB给循环移位样本左乘一个由0和1组成的二值掩膜矩阵P。掩膜矩阵其实就是从大图像块的循环移位样本中裁切小图像块

CFLB仅使用单通道灰度特征,最新BACF将特征扩展为多通道HOG特征。CFLB和BACF采用Alternating Direction Method of Multipliers(ADMM)快速求解。
7. 2016 颜色特征与深度特征
7.1 DAT
DAT(Distractor-Aware Tracker)不是一种相关滤波方法,而是一种基于颜色统计特征方法。
Possegger H, Mauthner T, Bischof H. In defense of color-based model-free tracking [C]// CVPR, 2015.

DAT统计前景目标和背景区域的颜色直方图,这就是前景和背景的颜色概率模型,检测阶段,利用贝叶斯方法判别每个像素属于前景的概率,得到像素级颜色概率图,如上图(a)。
DAT在跟踪过程中预先探测出与目标相似的干扰区域,图(b),与正确的目标区域结合表示(加权均值),图(c)。这样的做法能够有效降低传统颜色特征方法常出现的“漂移”现象。
7.2 STAPLE
STAPLE结合了模板特征方法DSST和颜色统计特征方法DAT。
Bertinetto L, Valmadre J, Golodetz S, et al. Staple: Complementary Learners for Real-Time Tracking [C]// CVPR, 2016.
相关滤波模板类特征(HOG)对快速变形和快速运动效果不好,但对运动模糊光照变化等情况比较好;而颜色统计特征(DAT)对变形不敏感,而且不属于相关滤波框架没有边界效应,但对光照变化和背景相似颜色不好。因此,这两类方法可以互补。
DSST把跟踪划分为两个问题,即平移检测和尺度检测。DAT就加在平移检测部分。相关滤波有一个响应图,DAT得到的像素级前景概率也有一个响应图,两个响应图线性加权得到最终响应图。
7.3 C-COT
图像特征的表达能力在目标跟踪中起着至关重要的作用。以HoG+CN为代表的图像特征,性能优秀而且速度优势非常突出,但也成为性能进一步提升的瓶颈。以卷积神经网络(CNN)为代表的深度特征,具有更强大特征表达能力、泛化能力和迁移能力。将深度特征引入相关滤波也就水到渠成。
Danelljan M, Hager G, Shahbaz Khan F, et al. Convolutional features for correlation filter based visual tracking [C]// ICCVW, 2015.
Ma C, Huang J B, Yang X, et al. Hierarchical convolutional features for visual tracking [C]// ICCV, 2015.
C-COT综合了SRDCF的空域正则化和SRDCFdecon的自适应样本权重方法,并采用了多层深度特征(VGG第1和5层)。为了应对不同卷积层分辨率不同的问题,C-COT提出了连续空间域插值方法,在训练之前通过频域隐式插值将特征图插值到连续空域,方便集成多分辨率特征图,并且保持定位的高精度。目标函数通过共轭梯度下降方法迭代优化。
Danelljan M, Robinson A, Khan F S, et al. Beyond correlation filters: Learning continuous convolution operators for visual tracking [C]// ECCV, 2016.
SRDCFdecon的主要贡献是提出了一种样本权重更新方法,解决样本污染问题。其核心思想在后续的ECO算法中一并介绍。
Danelljan M, Hager G, Shahbaz Khan F, et al. Adaptive decontamination of the training set: A unified formulation for discriminative visual tracking [C]// CVPR, 2016.
8. 2017 灵活地组合应用
8.1 LMCF
LMCF提出了两个方法,多峰目标检测和高置信度更新。
Wang M, Liu Y, Huang Z. Large Margin Object Tracking with Circulant Feature Maps [C]// CVPR, 2017.
多峰目标检测对平移检测的响应图做多峰检测,如果其他峰峰值与主峰峰值的比例大于某个阈值,说明响应图是多峰模式,以这些多峰为中心重新检测,并取这些响应图的最大值作为最终目标位置。
高置信度更新:只有在跟踪置信度比较高的时候才更新跟踪模型,避免目标模型被污染。一个置信度指标是最大响应。另一个置信度指标是平均峰值相关能量(average peak-to correlation energy, APCE),反应响应图的波动程度和检测目标的置信水平,
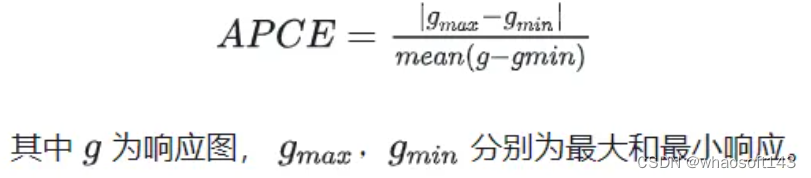
8.2 CSR-DCF
CSR-DCF,提出了空域可靠性和通道可靠性方法。
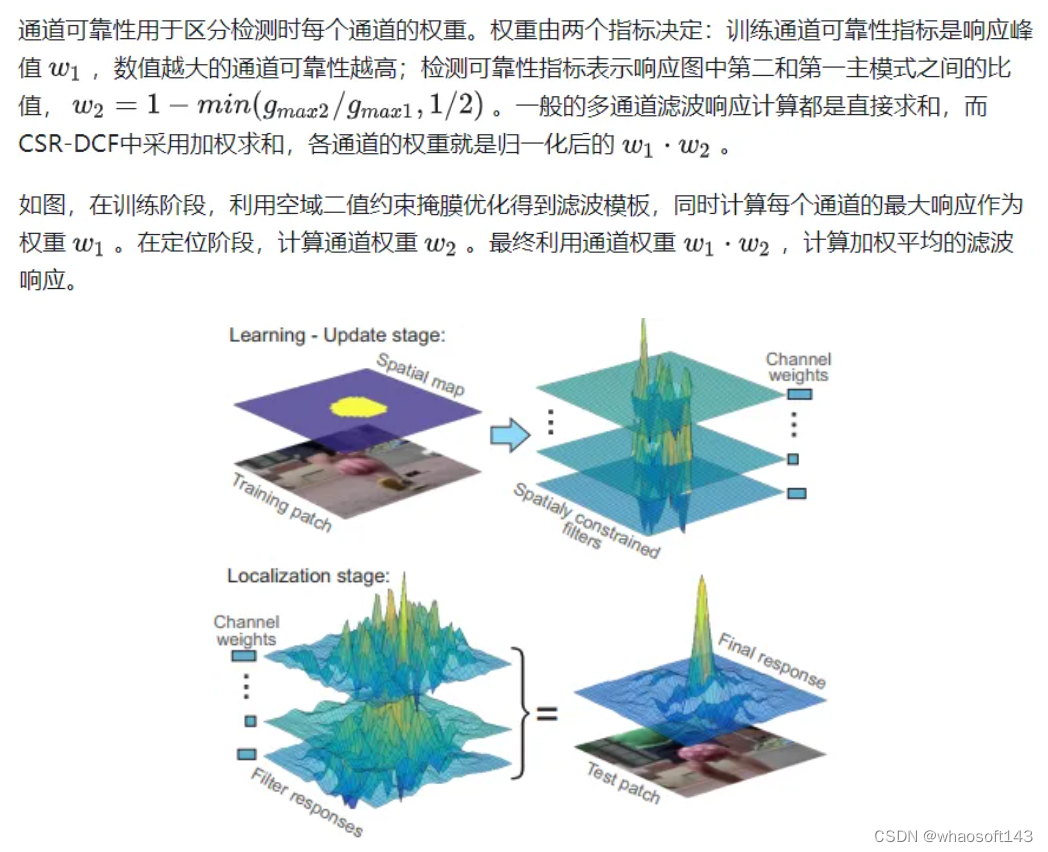
Lukežič A, Vojíř T, Čehovin L, et al. Discriminative Correlation Filter with Channel and Spatial Reliability [C]// CVPR, 2017.
空域可靠性利用图像分割方法,通过前背景颜色直方图概率和中心先验计算空域二值约束掩膜。这里的二值掩膜就类似于CFLB中的掩膜矩阵P。CSR-DCF利用图像分割方法更准确地选择有效的跟踪目标区域。
由于引入了二值约束掩膜,采用ADMM迭代优化。
8.3 ECO
ECO可以看做是C-COT的升级加速版,从模型大小、样本集大小和更新策略三个方面加速。
Danelljan M, Bhat G, Khan F S, et al. ECO: Efficient Convolution Operators for Tracking [C]// CVPR, 2017
- 模型降维
ECO采用分解卷积方法(factorized convolution operator)在特征提取上做了简化。定义一个矩阵P,将原有的D维特征降低到C维。利用最优化方法同时训练得到滤波模板和矩阵P。在实际计算中可以在第一帧图像将P计算出来,后续帧都直接使用这个矩阵P,减少计算量。当然,此方法也可用于其他高维特征,例如HoG。
- 样本集更新和生成模型
ECO借鉴了SRDCFdecon的训练样本权重更新方法,以应对训练样本受污染问题。
因为目标跟踪过程中的训练样本并不是手工标定而是由跟踪算法得到的,难免出现样本受损的情况,例如
-- 错误的跟踪预测。由于旋转、形变而导致的跟踪失败。
-- 局部或者全遮挡造成的正样本受损。
-- 扰动。运动模糊可能导致目标的误识。
自MOSSE,一般的相关滤波都是固定学习率的线性加权更新模型,不需要显式保存训练样本,每帧样本训练的模型与已有目标模型,以固定权值加权来更新目标模型,这样以往的样本信息都会逐渐失效,而最近几帧的样本信息占模型的比重很大。如果出现目标定位不准确、遮挡、背景扰动等情况,固定学习率方式会平等对待这些“有问题”的样本,目标模型就会被污染导致跟踪失败。
另一种比较常见的方式也是固定学习率,如果当前帧在目标检测阶段置信度比较低,则说明这个样本不可靠,选择丢弃这个样本不更新或仅在置信度比较高的时候更新,LMCF就采用了这种做法。但这种做法依然不够灵活,可能会排除少量遮挡或背景扰动的样本,但这些样本中也有非常重要的目标信息。
SRDCFdecon提出的方式是同时优化模型参数和样本权重,得到连续的样本权重值。这样可以降低污染样本的影响而增加正确样本的影响。此外,SRDCFdecon可以在线地在每一帧中重新决定样本的权重,进而纠正错误。
SRDCFdecon有三个优势,
-- 连续权重值。连续权重值更准确地描述的样本的重要性。比如对轻微遮挡或者轻微扰动的样本,依然可以获取有价值的信息。
-- 权重重新评估。可以在线地在每一帧时,利用历史帧图像,重新决定样本的权重,纠正之前的错误权重。
-- 动态先验权重。引入了样本的先验权重以结合样本的先验知识。
图中示例了权重结算的结果。蓝色曲线表示优化得到的权重,红色曲线表示时间相关的先验权重。

ECO在SRDCFdecon的基础上提出了紧凑生成模型(compact generative model),以减少样本数量。如图,ECO采用高斯混合模型(Gaussian Mixture Model)合并相似样本,分成不同的样本分组,每一个样本分组内样本一致性较高,不同分组之间差异性较大,这样就使得训练样本集同时具有了多样性和代表性。

- 稀疏更新策略
ECO每隔5帧做一次优化训练更新模型参数,不但提高了算法速度,而且提高了对突变,遮挡等情况的稳定性。但是ECO的样本集是每帧都更新的,稀疏更新并不会错过间隔期的样本变化信息。
# 特斯拉model3的硬件拆解
以下内容节选自《从拆解 Model3 看智能电动汽车发展趋势》报告中域控制器部分章节。这份报告是中信证券研究部TMT和汽车团队联手多家公司和机构耗时两个月对特斯拉Model3进行了完整的拆解,对E/E架构、三电、热管理、车身等进了深度解析。
域控制器 软件定义汽车,迭代决定智能
汽车的智能化的大方向已经成为了产业共识和市场共识。比如说 2008 年安卓 1.0 发布之初,使用体验是比较一般的,经过不断的数据收集、用户反馈和持续迭代,最终交互和用户体验越来越好,逐步向我们理想中的“智能终端”逼近。
显而易见,汽车如果要能像手机一样持续根据数据和用户反馈进行软件迭代,现有的E/E 架构势必然是要进行大的变革的。软件和硬件必须解耦,算力必须从分布走向集中,特斯拉的 Model3 率先由分布式架构转向了分域的集中式架构,这是其智能化水平遥遥领先于许多车厂的主要原因,我们接下来就对特斯拉的车身域、座舱域、驾驶域进行详细的解读。
车身域:按位置而非功能进行分区,彻底实现软件定义车身
同样是域控制器,特斯拉的域控制器思路始终是更为领先的。举例来说,作为传统汽车供应链中最核心的供应商之一,博世是最早提出域控制器概念的企业之一。但博世的思路仍然受到传统的模块化电子架构影响,其在 2016 年提出了按照功能分区的五域架构,将整车的 ECU 整合为驾驶辅助、安全、车辆运动、娱乐信息、车身电子 5 个域,不同域之间通过域控制器和网关进行连接。在当时看来,这一方案已经能够大大减少 ECU 数量,然而用今天的眼光来看,每个域内部仍然需要较为复杂的线束连接,整车线束复杂度仍然较高。
与博世形成对比,特斯拉 model 3 在 2016 年发布,2017 年量产上市,与博世的报告几乎处于同一时期。然而,model 3 的域控制器架构核心直接从功能变成了位置,3 个车身控制器就集中体现了特斯拉造车的新思路。按照特斯拉的思路,每个控制器应该负责控制其附近的元器件,而非整车中的所有同类元器件,这样才能最大化减少车身布线复杂度,充分发挥当今芯片的通用性和高性能,降低汽车开发和制造成本。所以特斯拉的三个车身域控制器分别分布在前车身、左前门和右前门前,实现就近控制。这样的好处是可以降低布线的复杂度,但是也要求三个车身域要实现彻底的软硬件解耦,对厂商的软件能力的要求大大提高。
以下分别介绍三个车身控制器的情况,车身域分为前车身域、左车身域、右车身域,其在 Model3 车身上的位置如下图所示

前车身域控制器的位置在前舱,这个位置理论上来说遇到的碰撞概率要更高,因此采用铝合金的保护外壳,而左右车身域控制器由于在乘用舱内,遇到外界碰撞的概率较低,保护外壳均采用塑料结构,如下图所示。

前车身控制器:全车电子电气配电单元以及核心安全 ECU 连接
前车身控制器位于前舱中,主要负责的功能是前车体元件控制以及主要的配电工作。该控制器离蓄电池比较近,方便取电。其主要负责三类电子电气的配电和控制:
1、安全相关:i-booster、ESP 车身稳定系统、EPS 助力转向、前向毫米波雷达;
2、热管理相关:如冷却液泵、五通阀、换热器、冷媒温度压力传感器等;
3、前车身其它功能:车头灯、机油泵、雨刮等。除此之外,它还给左右车身控制器供电,这一功能十分重要,因为左右车身控制器随后还将用这两个接口中的能量来驱动各自控制的车身零部件。
将其拆开来看,具体功能实现方面,需要诸多芯片和电子元件来配合完成。核心的芯片主要完成控制和配电两方面的工作。
先说控制部分,主要由一颗意法半导体的 MCU 来执行(图中红框)。此外,由于涉及到冷却液泵、制动液液压阀等各类电机控制,所以板上搭载有安森美的直流电机驱动芯片(图中橙色框 M0、M1、M2),这类芯片通常搭配一定数量的大功率 MOSFET 即可驱动电机。
配电功能方面,一方面需要实时监测各部件中电流的大小,另一方面也需要根据监测的结果对电流通断和电流大小进行控制。电流监测方面,AMS 的双 ADC 数据采集芯片和电流传感器配套芯片(黄色框 AMS 中的芯片)可以起到重要作用。而要控制电流的状态,一方面是通过 MOSFET 的开关,另一方面也可以通过 HSD 芯片(High Side Driver,高边开关),这种芯片可以控制从电源正极流出的电流通断。
这一块控制器电路板共使用了 52个安森美的大功率 MOSFET,9个功率整流器芯片,以及 ST 和英飞凌的共计 21 个 HSD 芯片。在前车身控制器上我们可以看到,特斯拉已经在很大程度上用半导体元件取代了传统电气元件。
左车身域控制器:负责车身左侧电子电气调度
左车身控制器位于驾驶员小腿左前方位置,贴合车体纵向放置,采用塑料壳体封装,可以在一定程度上节约成本。左车身控制器负责管理驾驶舱及后部的左侧车身部件,充分体现了尽可能节约线束长度以控制成本的指导思想。
左车身控制器主要负责了几类电子电气的配电和控制:
1、左侧相关:包括仪表板、方向盘位置调节、照脚灯;
2、座椅和车门:,左前座椅、左后座椅、前门、后排车门、座椅、尾灯等。
左车身域控制的核心芯片主要也分为控制和配电。核心控制功能使用两颗 ST 的 32 位 MCU 以及一颗 TI 的 32 位单片机来实现。左车身的灯具和电机比较多,针对灯具类应用,特斯拉选用了一批 HSD 芯片来进行控制,主要采用英飞凌的 BTS 系列芯片。针对电机类应用,特斯拉则选用了 TI 的电机控制芯片和安森美的大功率 MOSFET。
右车身域控制器:负责车身右侧电子电气调度
右车身控制器与左车身基本对称,接口的布局大体相同,也有一些不同点。右车身域负责超声波雷达以及空调,同时右车身承担的尾部控制功能更多一些,包括后方的高位刹车灯和后机油泵都在此控制。
具体电路实现方面,由于功能较为相似,电路配置也与左车身较为相似。一个不同点在于右车身信号较多,所以将主控单片机从左车身的 ST 换成了瑞萨的高端单片机 RH850系列。此外由于右车身需要较多的空调控制功能,所以增加了三片英飞凌的半桥驱动器芯片。
特斯拉车身域的思路:彻底地软件定义汽车,用芯片替代保险丝和继电器车身域是特斯拉相比传统汽车变化最大的地方,传统汽车采用了大量 ECU,而特斯拉通过三个域实现了对整车的一个控制。虽然都是往域控制器方向走,但特斯拉没有采用博世的功能域做法,而是完全按区域来进行划分,将硬件尽量标准化,通过软件来定义汽车的思路体现得淋漓尽致。除此之外,特斯拉还将一些电气化的部件尽量芯片化,如车身域中采用了大量 HSD 芯片替代了继电器和保险丝,可靠性提高,而且可以编程,能更好实现软件定义汽车。
特斯拉控制器的未来走向:走向更高集成度,优化布置持续降本
从特斯拉车身控制器能够体现出的另一个发展趋势是器件的持续集成和持续降本。早期版本的 model S 和 model X 并无如此集中的车身控制器架构,但如今较新的 model 3 和 model Y 已经体现出集成度增加的趋势。左下图中我们可以看到,作为第三代车身域控制器产品,model Y 的车身控制器已经与第一代的 model 3 有所不同,直观上就是其元器件密度有所增加。比如图中的 MOSFET(黑色小方块),model Y 的间距明显要比 model 3更小。
因此,在同样的面积下,控制器就能容纳更多元件,融合更多功能。另外,与现有的 model 3 不同,model Y 控制器的背面也被利用起来,增加了一定数量的元器件,这使得控制器的集成度进一步提高。集成度提高的结果就是车身电子电气架构的进一步简化,汽车电子成本的进一步降低。
另外 2020 款 model Y 的 PCB 板也得到进一步节约。初代 PCB 板由于形状不规则,必然有一部分 PCB 材料被浪费,推高了成本。而第三代控制器的 PCB 形状能够紧密贴合,两个左右车身控制器可以合并成为一个矩形,因此 PCB 材料的利用率得到有效提升,也能够在一定程度上降低成本。
未来车身控制器会如何发展,是否会走向一台统一的控制器?至少目前来看,特斯拉用产品对此做出了否定的回答。我们可以看到,2021 年交付的 model S plaid,其第四代车身控制器仍旧使用了分离的两片左右车身控制器。
而且在第四代车身控制器设计中,前车身控制器也分成了两片,一片负责能量管理和配电,另一片负责车身管理、热管理以及少量配电工作。整体来看,第四代控制器的元件密度仍旧很高,体现出了集成降本的趋势。另外,第四代控制器的元件连接采用 Press-Fit技术取代了传统焊接,进一步提高了良率,也有利于实现更高的元器件密度。
整体来看,统一的中央计算机虽然集成度高,但不可避免地带来了控制器和受控器件的距离增加,从而增加线束长度,提高成本,而且元件集成密度也有一定的限制,我们无法在有限的空间内无限制集成,因此集中化也是有上限和最优解的,目前看来特斯拉正逐渐改善设计和工艺来逼近这个最优解。
硬件方面的持续集成也为软件的集成和发展创造了条件。传统汽车产业链当中不同功能独立性很高,各功能的 ECU 都来自不同厂商,难以协同工作。但特斯拉将大量 ECU 集成后,车身上只需保留负责各个功能的执行器,而主要的控制功能都统一在域控制器中,采用少量的 MCU,更多使用软件来完成功能控制。比如特斯拉 model 3 的左右车身域控制器中各有 3 个 MCU,数量大大减少,不同控制功能采用软件的形式进行交互,能够有更大的协同创新空间。比如特斯拉可以协同全车空调出风口来调节车内风场,或对副驾驶座位上的乘客进行体重检测,判断其是否属于儿童,从而灵活调整安全气囊策略,而不是像传统车企一样只能让儿童坐在后排。而且特斯拉可以从软件控制当中收集数据,并持续不断改善控制功能,改善用户体验。
特斯拉这种软硬件持续集成的方案在带来优势的同时也对软件开发能力提出了更高要求。只有统揽全局软硬件方案、熟悉各个部件特性的整车厂商才有能力开发如此庞大复杂的软件系统,传统车企一直以来扮演集成商的角色,ECU 软件开发更多依赖供应商,其人才队伍构成和供应链方面的利益关系导致其短时间内难以模仿特斯拉的方式,因而特斯拉的车身控制软件也成为其独特的竞争力。
驾驶域:FSD 芯片和算法构成主要壁垒,NPU 芯片效率更优
特斯拉的另一个重要特色就是其智能驾驶,这部分功能是通过其自动驾驶域控制器(AP)来执行的。本部分的核心在于特斯拉自主开发的 FSD 芯片,其余配置则与当前其他自动驾驶控制器方案没有本质区别。
在 model 3 所用的 HW3.0 版本的 AP 中,配备两颗 FSD 芯片,每颗配置 4 个三星 2GB内存颗粒,单 FSD总计 8GB,同时每颗 FSD配备一片东芝的 32GB闪存以及一颗 Spansion的 64MB NOR flash 用于启动。网络方面,AP 控制器内部包含 Marvell 的以太网交换机和物理层收发器,此外还有 TI 的高速 CAN 收发器。对于自动驾驶来说,定位也十分重要,因此配备了一个 Ublox 的 GPS 定位模块。
外围接口方面,model 3 整车的所有摄像头都直接连接到 AP 控制器,与这些相机配合的还有 TI 的视频串行器和解串器。此外还有供电接口、以太网接口和 CAN 接口使得 AP控制器能够正常运作。作为一款车载控制器,特斯拉的自动驾驶域控制器还考虑到了紧急情况,因此配备了紧急呼叫音频接口,为此搭配了 TI 的音频放大器和故障 CAN 收发器。
另外一点值得注意的是,为了保障驾驶安全,AP 控制器必须时刻稳定运行,因此特斯拉在 AP 控制器中加入了相当大量的被动元件,正面有 8 颗安森美的智能功率模块,并搭配大量的电感和电容。背面更为明显,在几乎没有太多控制芯片的情况下将被动元件铺满整个电路板,密度之高远超其他控制器,也明显高于生活中各种常见的智能终端。从这一点来看,随着智能汽车的发展,我国被动元器件企业也有望获益。
为了实现自动驾驶,特斯拉提出了一整套以视觉为基础,以 FSD 芯片为核心的解决方案,其外围传感器主要包含 12 个超声传感器(Valeo)、8 个摄像头(风挡玻璃顶 3 个前视,B 柱 2 个拍摄侧前方,前翼子板 2 个后视,车尾 1 个后视摄像头,以及 1 个 DMS 摄像头)、1 个毫米波雷达(大陆)。
其最核心的前视三目摄像头包含中间的主摄像头以及两侧的长焦镜头和广角镜头,形成不同视野范围的搭配,三个摄像头用的是相同的安森美图像传感器。
毫米波雷达放置于车头处车标附近,包含一块电路板和一块天线板。该毫米波雷达内部采用的是一颗 Freescale 控制芯片以及一颗 TI 的稳压电源管理芯片。
而整个 AP 控制器的真正核心其实就是 FSD 芯片,这也是特斯拉实现更高 AI 性能和更低成本的的一个重点。与当前较为主流的英伟达方案不同,特斯拉 FSD 芯片内部占据最大面积的并非CPU和GPU,而是NPU。虽然此类设计完全是为神经网络算法进行优化,通用性和灵活性相对不如英伟达的 GPU 方案,但在当前 AI 算法尚未出现根本性变化的情况下,NPU 的适用性并不会受到威胁。
NPU 单元能够对常见视觉算法中的卷积运算和矩阵乘法运算进行有效加速,因此特斯拉 FSD 芯片能够使用三星 14nm 工艺,达到 144TOPS 的 AI 算力,而面积只有约 260 平方毫米。相比而言,英伟达 Xavier 使用台积电 12nm 工艺,使用 350 平方毫米的芯片面积却只得到 30TOPS 的 AI 算力。这样的差距也是特斯拉从 HW2.5 版本的英伟达 Parker SoC 切换到 HW3.0 的自研 FSD 芯片的原因。因此,在算法不发生根本性变革的情况下,特斯拉 FSD 能取得成本和性能的双重优势,这也构成了特斯拉自动驾驶方案的竞争力。
AI 算法方面,根据特斯拉官网人工智能与自动驾驶页面的描述,AutoPilot 神经网络的完整构建涉及 48 个网络,每天依据其上百万辆车产生的数据进行训练,需要训练 70000 GPU 小时。基础代码层面,特斯拉具备可以 OTA 的引导程序,还有自定义的 Linux 内核(具有实时性补丁),也有大量内存高效的低层级代码。
未来自动驾驶域的创新仍然会集中在芯片端,另外传感器的创新如激光雷达、4D 毫米波雷达等也能够很大程度上推动智能驾驶。在可见的未来,专用 AI 芯片将能够成为与英伟达竞争的重要力量,我国 AI 芯片企业有望借助智能汽车的东风获得更好发展。
座舱域:特斯拉更多将座舱视为 PC 而非手机
座舱域是用户体验的重要组成部分,特斯拉的座舱控制平台也在不断进化中。本次拆解的特斯拉model 3 2020款采用的是第二代座舱域控制器(MCU2)。
MCU2 由两块电路板构成,一块是主板,另一块是固定在主板上的一块小型无线通信电路板(图中粉色框所示)。这一块通信电路板包含了 LTE 模组、以太网控制芯片、天线接口等,相当于传统汽车中用于对外无线通信的 T-box,此次将其集成在 MCU 中,能够节约空间和成本。我们本次拆解的 2020 款 model 3 采用了 Telit 的 LTE 模组,在 2021 款以后特斯拉将无线模组供应商切换成移远通信。
MCU2 的主板采用了双面 PCB 板,正面主要布局各种网络相关芯片,例如 Intel 和Marvell 的以太网芯片,Telit 的 LTE 模组,TI 的视频串行器等。正面的另一个重要作用是提供对外接口,如蓝牙/WiFi/LTE 的天线接口、摄像头输入输出接口、音频接口、USB 接口、以太网接口等。
而 MCU2 的背面更为重要,其核心是一颗 Intel Atom A3950 芯片,搭配总计 4GB 的Micron 内存和同样是 Micron 提供的 64GB eMMC 存储芯片。此外还有 LG Innotek 提供的WiFi/蓝牙模块等。
在座舱平台上,特斯拉基于开源免费的 Linux 操作系统开发了其自有的车机操作系统,由于 Linux 操作系统生态不如 Android 生态丰富,特斯拉需要自己进行一部分主流软件的开发或适配。
座舱域的重要作用就是信息娱乐,MCU2 在这一方面表现尚显不足。伴随 A3950 芯片低价的是其性能有限,据车东西测试称,在 MCU2 上启动腾讯视频或 bilibili 的时间都超过了 20 秒,且地图放大缩小经常卡顿。卡顿的原因是多方面的,一方面 A3950 本身算力有限,集成显卡 HD505 性能也比较弱,处理器测评网站 NotebookCheck 对英特尔 HD 505的评价是,截至 2016 年的游戏,即使是在最低画质设置下,也很少能流畅运行。
另一方面,速度较慢、寿命较短的eMMC(embedded MultiMedia Card)闪存也会拖累系统性能。eMMC 相对机械硬盘具备速度和抗震优势,但擦写寿命可能只有数百次,随着使用次数增多,坏块数量增加,eMMC 的性能将逐渐恶化,在使用周期较长的汽车上这一弊端可能会得到进一步放大,导致读写速度慢,使用卡顿,2021 年年初,特斯拉召回初代 MCU eMMC 可以佐证这一点。综合来看,特斯拉 MCU2 相比同时期采用高通 820A 的车机,属于偏弱的水平。
但特斯拉作为一家重视车辆智能水平的企业,并不会坐视落后的局面一直保持下去。2021 年发布的所有新款车型都换装 AMD CPU(zen+架构)和独立显卡(RDNA2 架构),GPU 算力提升超过 50 倍,存储也从 eMMC 换成了 SSD,读写性能和寿命都得到大幅改善。整体来看,相比 MCU2,MCU3 性能获得明显提升,提升幅度比第一代到第二代的跨度更大。
最新一代的特斯拉 MCU 配置已经与当前最新一代的主流游戏主机较为接近,尤其是GPU 算力方面不输索尼 PS5 和微软 Xbox Series X。
提升的配置也让使用体验得到大幅提升。根据车东西的测试,MCU3 加载 bilibili 的时间缩短到 9 秒,浏览器启动时间为 4 秒,地图也能够流畅操作,虽然相比手机加载速度仍然不够,但已经有明显改善。另外 MCU3 的庞大算力让其能够运行大型游戏,比如 2021年 6 月新款特斯拉 model S 交付仪式上,特斯拉工作人员就现场展示了用手柄和车机玩赛博朋克 2077。而且特斯拉官网上,汽车内部渲染图中,车机屏幕上显示的是巫师 3。这两个案例已经说明,MCU3 能够充分支持 3A 游戏,使用体验一定程度上已经可以与 PC 或游戏主机相比较。
从特斯拉车机与游戏的不断靠拢我们可以看到未来座舱域的发展第一个方向,即继续推进大算力与强生态。目前除特斯拉采用x86座舱芯片外,其他车企采用ARM体系较多,但同样呈现出算力快速增长的趋势,这一点从主流的高通 820A到8155,乃至下一代的8295都能够得到明显体现。高通下一代座舱芯片8295性能基本与笔记本电脑所用的8cx相同。可以看到无论是特斯拉用的 AMD芯片还是其他车企用的高通芯片,目前趋势都是从嵌入式的算力水平向 PC的算力水平靠拢,未来也有可能进一步超越PC算力。
而且高算力让座舱控制器能够利用现有的软件生态。特斯拉选用x86,基于Linux开发操作系统,利用现有的PC游戏平台,其他厂商更多利用现有的ARM-Android移动生态。这一方向发展到一定阶段后,可能会给车企带来商业模式的改变,汽车将成为流量入口,车企可以凭借车载的应用商店等渠道获得大量软件收入,并且大幅提高毛利率。
座舱域控制器的第二个发展方向则是可能与自动驾驶控制器的融合。首先,当前座舱控制器的算力普遍出现了过剩,剩余的算力完全可以用于满足一些驾驶类的应用,例如自动泊车辅助等。
其次,一些自动驾驶功能尤其是泊车相关功能需要较多人机交互,这正是座舱控制器的强项。而且,座舱控制器与自动驾驶控制器的融合还能够带来一定的资源复用和成本节约,停车期间可以将主要算力用于进行游戏娱乐,行驶期间则将算力用于保障自动驾驶功能,而且这种资源节约能够让汽车少一个域控制器,按照MCU3的价格,或许能够为每台车节约上百美元的成本。目前已经出现了相当多二者融合的迹象,比如博世、电装等主流供应商纷纷在座舱域控制器中集成ADAS功能,未来这一趋势有望普及。
电控域:IGBT宏图大展,SiC锋芒初露
IGBT:汽车电力系统中的“CPU”,广泛受益于电气化浪潮
IGBT相当于电力电子领域的“CPU”,属于功率器件门槛最高的赛道之一。功率半导体又称为电力电子器件,是电力电子装置实现电能转换、电路控制的核心器件,按集成度可分为功率 IC、功率模块和功率分立器件三大类,其中功率器件又包括二极管、晶闸管、MOSFET 和 IGBT 等。
应用场景的增量扩张使得汽车领域成为市场规模最大,增长速度最快的 IGBT 应用领域。根据集邦咨询数据,新能源汽车(含充电桩)是 IGBT 最主要的应用领域,其占比达31%。IGBT 在汽车中主要用于三个领域,分别是电机驱动的主逆变器、充电相关的车载充电器(OBC)与直流电压转换器(DC/DC)、完成辅助应用的模块。
1)主逆变器:主逆变器是电动车上最大的 IGBT 应用场景,其功能是将电池输出的大功率直流电流转换成交流电流,从而驱动电机的运行。除 IGBT 外,SiC MOSFET 也能完成主逆变器中的转换需求。
2)车载充电器(OBC)与直流电压转换器(DC/DC):车载充电器搭配外界的充电桩,共同完成车辆电池的充电工作,因此 OBC 内的功率器件需要完成交-直流转换和高低压变换工作。DC/DC 转换器则是将电池输出的高压电(400-500V)转换成多媒体、空调、车灯能够使用的低压电(12-48V),常用到的功率半导体为 IGBT 与 MOSFET。
3)辅助模块:汽车配备大量的辅助模块(如:车载空调、天窗驱动、车窗升降、油泵等),其同样需要功率半导体完成小功率的直流/交流逆变。这些模块工作电压不高,单价也相对较低,主要用到的功率半导体为 IGBT 与 IPM。
以逆变器为例,Model S 的动力总成有两种,分别为 Large Drive Unit(LDU)和 Small Drive Unit(SDU),前者装配在“单电机后驱版本”中的后驱、“双电机高性能四驱版本”中的后驱,后者装配在“双电机四驱版本”中的前后驱、“双电机高性能四驱版本”中的前驱。
LDU 尺寸较大,输出功率也较大,内部的逆变器包含 84 个 IGBT。LDU 的逆变器呈现三棱镜构造,每个半桥位于三棱镜的每个面上,每个半桥的 PCB 驱动板(三角形)位于三棱镜的顶部,电池流出的高压直流电由顶部输入,逆变后的高压交流电由底部输出。
Model S(单电机版本)全车共有 96个IGBT,其中有 84个IGBT 位于逆变器中,为其三相感应电机供电,84个IGBT 的型号为英飞凌的 IKW75N60T。若以每个 IGBT 5美元计算,Model S 逆变器所使用的 IGBT 价格约为 420 美元。
而 SDU 的形态更小,内部结构也更为紧凑,内部逆变器含 36 个 IGBT。根据01芯闻拆解,SDU 中的IGBT为单管IGBT,型号为英飞凌的 AUIRGPS4067D1,总用量为 36片。IGBT 单管的布局也有较大变化,IGBT 单管背靠背固定在散热器中,组成类似三明治的结构,充分利用内部空间。同时,SDU 内部 IGBT 的管脚也无需折弯,降低失效概率。相比 LDU,SDU 的出现体现出特斯拉对 IGBT 更高的关注度与要求,其机械、电学、成本、空间等指标均有明显提升。
SiC:Model 3 开创应用先河,与 IGBT 各有千秋
与 IGBT 类似,SiC 同样具有高电压额定值、高电流额定值以及低导通和开关损耗等特点,因此非常适合大功率应用。SiC 的工作频率可达 100kHz 以上,耐压可达 20kV,这些性能都优于传统的硅器件。其于上世纪 70 年代开始研发,2010 年 SiC MOSFET 开始商用,但目前并未大规模推广。
Model 3 为第一款采用全 SiC 功率模块电机控制器的纯电动汽车,开创 SiC 应用的先河。基于 IGBT 的诸多优势,在 Model 3 问世之前,世面上的新能源车均采用 IGBT 方案。而 Model 3 利用 SiC 模块替换 IGBT 模块,这一里程碑式的创新大大加速了 SiC 等宽禁带半导体在汽车领域的推广与应用。根据SystemPlus consulting 拆解报告,Model 3 的主逆变器上共有 24 个 SiC 模块,每个模块包含 2 颗 SiC 裸晶(Die),共 48 颗 SiC MOSFET。
Model 3 所用的 SiC 型号为意法半导体的 ST GK026。在相同功率等级下,这款 SiC模块采用激光焊接将 SiC MOSFET、输入母排和输出三相铜进行连接,封装尺寸也明显小于硅模块,并且开关损耗降低 75%。采用 SiC 模块替代 IGBT 模块,其系统效率可以提高5%左右,芯片数量及总面积也均有所减少。如果仍采用 Model X 的 IGBT,则需要 54-60颗 IGBT。
24 个模组每个半桥并联四个,利用水冷进行散热。24 个模块排列紧密,每相 8 个,单个开关并联 4 个。模组下方紧贴水冷散热器,并利用其进行散热。可以看到,模块所在位置的背面有多根棒状排列的散热器(扰流柱散热器),利用冷却水进行水冷。水通道由稍大的盖板覆盖和密封。
Model 3 形成“示范效应”后,多家车厂陆续跟进 SiC 方案。在 Model 3 成功量产并使用后,其他厂商开始逐渐认识到 SiC 在性能上的优越性,并积极跟进相关方案的落地。2019 年 9 月,科锐与德尔福科技宣布开展有关车用 SiC 器件的合作,科锐于 2020 年 12月成为大众 FAST 项目 SiC 独家合作伙伴;2020 年,比亚迪“汉”EV 车型下线,该车搭载了比亚迪自主研发的的 SiC MOSFET 模块,加速性能与续航显著提升;2021 年,比亚迪在其“唐”EV 车型中加入 SiC 电控系统;2021 年 4 月,蔚来推出的轿车 ET7 搭载具备 SiC 功率模块的第二代高效电驱平台;小鹏、理想、捷豹、路虎也在逐渐布局 SiC。
相比 IGBT,SiC 能够带动多个性能全面提升,优势显著。由于 Si-IGBT 和 Si-FRD组成的 IGBT 模块在追求低损耗的道路上走到极致,意法半导体、英飞凌等功率器件厂商纷纷开始研发 SiC 技术。与 Si 基材料相比,SiC 器件的优势集中体现在:
1)SiC 带隙宽,工作结温在 200℃以上,耐压可达 20kV;
2)SiC 器件体积可以减少至 IGBT 的 1/3~1/5,重量减少至 40%~60%;
3)功耗降低 60%~80%,效率提升 1%~3%,续航提升约 10%。在多项工况测试下,SiC MOSFET 相比 Si-IGBT 在功耗和效率上优势显著。
但 SiC 的高成本制约普及节奏,未来 SiC 与 Si-IGBT 可能同步发展,相互补充。与IGBT 相比,SiC 材料同样存在亟待提升之处。
1)目前 SiC 成品率低、成本高,是 IGBT的 4~8 倍;
2)SiC 和 SiO2 界面缺陷多,栅氧可靠性存在问题。受限于高成本,SiC 器件普及仍需时日,叠加部分应用场景更加看重稳定性,我们认为 SiC 在逐步渗透的过程中将与 Si-IGBT 一同成长,未来两者均有广阔的应用场景与增长空间。
由于应用落地较慢,目前整个 SiC 市场仍处于发展阶段,国外厂商占据主要份额。根据 Cree(现公司名为Wolfspeed)数据,2018 年全球 SiC 器件销售额为 4.2 亿美元,预计 2024 年销售额将达 50 亿美元。SiC 产业分链可分为衬底、外延、模组&器件、应用四大环节,意法半导体、英飞凌、Cree、Rohm 以及安森美等国外龙头主要以 IDM 模式经营,覆盖产业链所有环节,五家龙头占据的市场份额分别为 40%、22%、14%、10%、7%。
动力域:主从架构 BMS 为躯干,精细电池管理为核心
Model 3 作为电动车,电能和电池的管理十分重要,而负责管理电池组的 BMS 是一个高难度产品。BMS 最大的难点之一在于,锂电池安全高效运行的条件是十分苛刻的。当今的锂电池,无论正负极还是电解液都十分脆弱。正负极均为多孔材料,充放电时锂离子就在正极和负极的孔隙中移动,导致正负极材料膨胀或收缩,当锂电池电压过高或过低,就意味着锂离子过度集中在正负极其中之一,导致这一边的电极过度膨胀而破碎,还容易产生锂枝晶刺破电池结构,而另一边的电极由于缺乏锂离子支撑,会发生结构坍塌,如此正负极都会受到永久性损害。电解液和三元正极材料都对温度比较敏感,温度过高则容易发生分解和反应,乃至燃烧、爆炸。因此,使用锂电池的前提就是确保其能工作在合适的温度和电压窗口下。如果以电压为横轴,温度为纵轴绘制一张图,这就意味着锂电池必须运行在图中一个较小的区域内。
BMS 的第二大难点在于,不同的锂电池之间必然存在不一致性。这种不一致性就导致同一时间,在同一电池组内,不同的电池仍然工作在不同的温度、电压、电流下。如果继续用一张图来描述,就代表着不同电池处在图上的不同位置。而要保证电池组的安全高效运行,就意味着诸多电池所在的点位必须同时处于狭小的安全窗口内,这就导致电池数量越多,管理就越困难。
为了解决锂电池运行的这一难题,就必须有可靠的 BMS 系统来对电池组进行监控和管理,让不同电池的充放电速度和温度趋于均衡。
在诸多厂家的 BMS 中,特斯拉的 BMS 系统是复杂度和技术难度最高的之一,这主要是由于特斯拉独特的大量小圆柱电池成组设计。
为什么特斯拉选用难以控制的小圆柱电池?早在特斯拉成立的早期,日本厂商在18650 小圆柱电池上积累了丰富的经验,一年出货量达到几十亿节,因而这类电池一致性较好,有利于电池管理。因此特斯拉在model S 上选用了小圆柱电池。出于技术积累等方面的原因,特斯拉在 model 3 上使用了仅比 18650 略大的 2170 电池,并且至今还在使用圆柱形电池。
由于特斯拉一直采用数量庞大的小圆柱电池来构造电池组,导致其 BMS 系统的复杂度较高。在 model S 时代,特斯拉全车使用了 7104 节电池,BMS 对其进行控制是需要一定软件水平的。根据汽车电子工程师叶磊的表述,在 model S 当中,采用每 74 节电池并联检测一次电压,每 444 节电池设置 2 个温度探测点。从汽车电子工程师朱玉龙发布的model S 诊断界面图也可以看出,整个电池组共有 16*6=96 个电压采样点,以及 32 个温度采样点。可以看到采样的数据是很多的,需要管理的电池数量也为其增加了难度,最终BMS 将依据这些数据设置合理的控制策略。高复杂度的电池组也让特斯拉在 BMS 领域积累了相当强的实力。与之相对,其他厂商的 BMS 复杂度就远不如特斯拉高,例如大众 MEB平台的首款电动车 ID.3 采用最多 12 个电池组模块,其电池管理算法相对会比较简单。
未来特斯拉的 BMS 是否会维持这样的复杂度?从目前趋势来看,随着采用的电池越来越大,BMS 需要管理的电池数量是越来越少的,BMS 的难度也有所降低。比如从 model S 到 model 3,由于改用 2170 电池,电芯数量出现了较明显的下降,长续航版电芯数量缩减到 4416 颗,中续航版 3648 颗,标准续航版 2976 颗。本次拆解的标准续航版配置 96个电压采样点,数量与 model S 相同,平均每 31 节电池并联测量一个电压值。整车 4 个电池组,每个都由 24 串 31 并的电池组组成,对电流均衡等方面提出了较高的要求。未来,随着 4680 大圆柱电池的应用,单车电芯数量将进一步减少,有利于 BMS 更精确地进行控制,或许能够进一步强化特斯拉的 BMS 表现。
尽管面临着最高的 BMS 技术难度,但特斯拉仍旧在这一领域做到优秀水准,而且还有超越其他公司的独到之处。比如特斯拉在电池管理的思路方面显得更加大胆,热管理方面是一个典型体现。特斯拉会在充电期间启动热管理系统将电池加热到 55 度的理论最佳温度,并在此温度下进行持续充电,相比而言,其他厂商往往更在意电池是否会过热,不会采用此类策略,这更加显现出特斯拉在 BMS 方面的实力。
特斯拉在充电或电能利用方面的用户体验设计是其 BMS 系统的另一个独到之处。比如特斯拉会用车身电池来使其他重要控制器实现“永不下电”,提高启动速度,改善用户体验。充电时,特斯拉采取的策略也更加灵活,会在充电刚开始时将电流提高到极大的程度,迅速提升电池电量,随后再逐渐减小充电电流到一个可以长期持续的水平,比如 model Y 可以在 40 秒内达到 600A 的超大电流充电(如图中黄绿色线所示)。相比而言,一般的车企甚至消费电子厂商通常会用一个可以长期持续的电流进行恒流充电。考虑到车主有时需要在几分钟内迅速补充电池电量,特斯拉的这种策略无疑是更有优势的,这也体现出特斯拉比传统车企思路更灵活,更能产生创新。
而具体如何实现这样优秀的 BMS 功能?前文所说的种种 BMS 管理策略依赖于软件,软件的基础在于特斯拉的 BMS硬件设计。特斯拉 model 3 的硬件设计包括了核心主控板、采样板、能量转换系统(PCS,由 OBC 和 DCDC 两部分组成)以及位于充电口的充电控制单元。BMS 部分所有电路均覆盖有透明三防漆以保护电路,导致电路元件外观光滑且反光。
主控板负责管理所有 BMS 相关芯片,共设置 7 组对外接口,包含了对充电控制器(CP)、能量转换系统(PCS)的控制信号,以及到采样板(BMB)的信号,另外还包含专门的电流电压采集信号。电路板上包含高压隔离电源、采样电路等电路模块。元器件方面,有Freescale 和 TI 的单片机,以及运放、参考电压源、隔离器、数据采样芯片等。
在 BMS 的控制下,具体对电池组进行监测的是 BMB 电路板,对于特斯拉 model 3而言,共有 4 个电池组,每一组配备一个 BMB 电路板,并且 4 个电路板的电路布局各不相同,彼此之间可以很容易地利用电路板上的编号进行区别,并且按照顺序用菊花链连接在一起,在 1 号板和 4 号板引出菊花链连接到主控板的 P5 和 P6 接口。我们本次拆解的model 3 单电机标准续航版电池组较短,沿着每个电池组都布置了一条 FPC(柔性电路板),并且在其沿线设置了对电池进行采样的采样点,每个采样点都用蓝色聚氨酯进行覆盖保护,最后在 FPC 上方覆盖淡黄色胶带进行保护。需要注意的是,标准续航版尽管每个电池组仍有两条淡黄色胶带,但只有其中一条下面有 FPC,另一条仅起到对下方电池触点的保护作用。而对于长续航版本,由于电池较多,每个电池组都需要分成两条 FPC 进行采样。
具体到 BMB 电路方面,标准续航版和长续航版也有所不同,我们以元器件较多的 4号采样板为例进行说明。首先,在采样点数量方面就有所不同,标准续航版共设置 24 个采样点,因此 FPC 上有 24 个触点与 BMB 进行对应。长续航版的电池组顶格设置,4 个电池组当中,中间两组较长,左右各设置 25 个采样点,共 50 个,两边的电池组略短一些,共设置 47 个采样点,一侧 24 个,另一侧 23 个,因此长续航版的 BMB 需要在两侧都设置触点。
其次,电路布置和元器件数量也有较大不同。经过触点传来的信号需要由 AFE(模拟前端)芯片进行处理,这是整个 BMB 电路的核心。标准续航版每个 BMB 有两颗定制的AFE 芯片,其配置有些类似 Linear Technology(ADI)的 LTC6813 芯片但不完全相同,同时配置了 3 颗 XFMRS 的 BMS LAN 芯片用于与其他电路板的信号传输。长续航版 BMB由于两侧均有触点,信号数量较多,因此为每个 AFE 另外配置了两颗简化版的 AFE 芯片(图中橙色长方形),用来辅助信号处理。同时 BMS LAN 芯片的数量也增加了 1 颗。
BMS 体系的另一个重要组成部分是充电控制,特斯拉为此开发了充电控制器,位于左后翼子板充电口附近。该控制器有三个对外接口,负责控制充电口盖、充电枪连接状态与锁定、充电信号灯、快慢充控制及过热检测等。电路方面则包括了 Freescale 的 MCU 和ST 的 HSD 芯片等。
BMS 还有一个重要功能就是电能转换,包括将高压直流电转化成低压直流电来供给车内设备,或者将高压交流电转化为高压直流电用于充电等,这一部分是通过能量转换系统(PCS,也称高压配电盒)完成的。PCS 包括两个主要部分,分别是将交流电转化成直流电的 OBC(车载充电器,On Board Charger)和进行直流电压变换的 DCDC。这部分电路中主要是各种大电容和大电感,也包含了整车中十分罕见的保险丝。
从元器件层面来看BMS系统,最核心的主要就是AFE芯片和各类功率器件/被动元件。其中 AFE 芯片领域,国内最主流的是三家美国公司产品,Linear Technology(被 ADI 收购)、Maxim(被 ADI 收购)、TI,所以其实还是归结于全球最大的两家模拟芯片公司。此外 NXP/Freescale、Intersil 等大型厂商也有一定份额。随着国内产业发展,国产 AFE 芯片通道数和产品稳定性逐渐提高,也有望获得发展空间。功率器件方面,我国产业已经有一定市场地位,在汽车领域仍可以进一步突破。
从电路和系统层面来看,依据汽车电子工程师朱玉龙的说法,BMS 真正的核心价值,其实是在电池的测试,评价,建模和后续的算法。整个 EE 的软硬件架构,已经基本是红海,未来产业不需要大量的 BMS 公司,长久来看还是电池厂商和车厂能够在 BMS 领域获得较高的地位。随着汽车产业崛起,未来我国电动汽车厂商在 BMS 领域也有望获得更深厚的积累。