前言
学习任何一种数据库,必须要了解它的数据字典,这样有利于了解数据库的结构、解读部分日志、定位一些问题。PG/OG系数据库的系统元数据遵从一个统一的设计规则,可以让初学者快速入门。本文以MogDB为例,剖析一下PG/OG系数据库的系统元数据设计哲学。
一、pg_depend
先来看pg_depend的表结构
| 名称 | 类型 | 引用 | 描述 |
|---|---|---|---|
| classid | oid | PG_CLASS.oid | 有依赖对象所在系统表的OID。 |
| objid | oid | 任意OID属性 | 指定的依赖对象的OID。 |
| objsubid | integer | - | 对于表字段,这个是该字段的字段号(objid和classid引用表本身)。对于所有其它对象类型,目前这个字段是零。 |
| refclassid | oid | PG_CLASS.oid | 被引用对象所在的系统表的OID。 |
| refobjid | oid | 任意OID属性 | 指定的被引用对象的OID。 |
| refobjsubid | integer | - | 对于表字段,这个是该字段的字段号(refobjid和refclassid引用表本身)。对于所有其它对象类型,目前这个字段是零。 |
| deptype | “char” | - | 一个定义这个依赖关系特定语义的代码。 n-不加cascade不删除,加cascade删除 a-加不加cascade都自动删除 i-加不加cascade都报错 e-表示是从插件创建的,不能删 p-初始创建的,objid都是0,只有refobj,也不能删 |
该表描述对象与对象之间的依赖关系,删除objid时,判断是否存在refobjid,并根据deptype的类型,来看此时应该进行的操作,主要为依赖的强弱性来看删除时是否要加cascade。
从这个表上可以看出,在PG/OG/MogDB中,对于对象的唯一性,是用classid+objid两个值来决定的,我们可以理解为java上的类和对象的概念,即先有类,然后基于类来创建对象。
原生PG在设计的时候,期望保持oid唯一(在一个db内),即一个oid就对应一个明确的对象。但按照这个结构发展这么多年,到了GaussDB后,某次增加一个函数的时候,错误地使用了已经在操作符里被用过的oid,导致后续OG系只能按照classid+objid两个信息来确定对象唯一性了,当然这并没有从内核上打破classid+objid唯一这个规则。有兴趣的可以比较一下这条SQL在PG和OG的输出差异
select refobjid,count(1) from
(select distinct refclassid,refobjid from pg_depend)
group by refobjid having count(1)>1
classid均来自于pg_class.oid,我们先观察一下classid中的这些oid分别对应什么
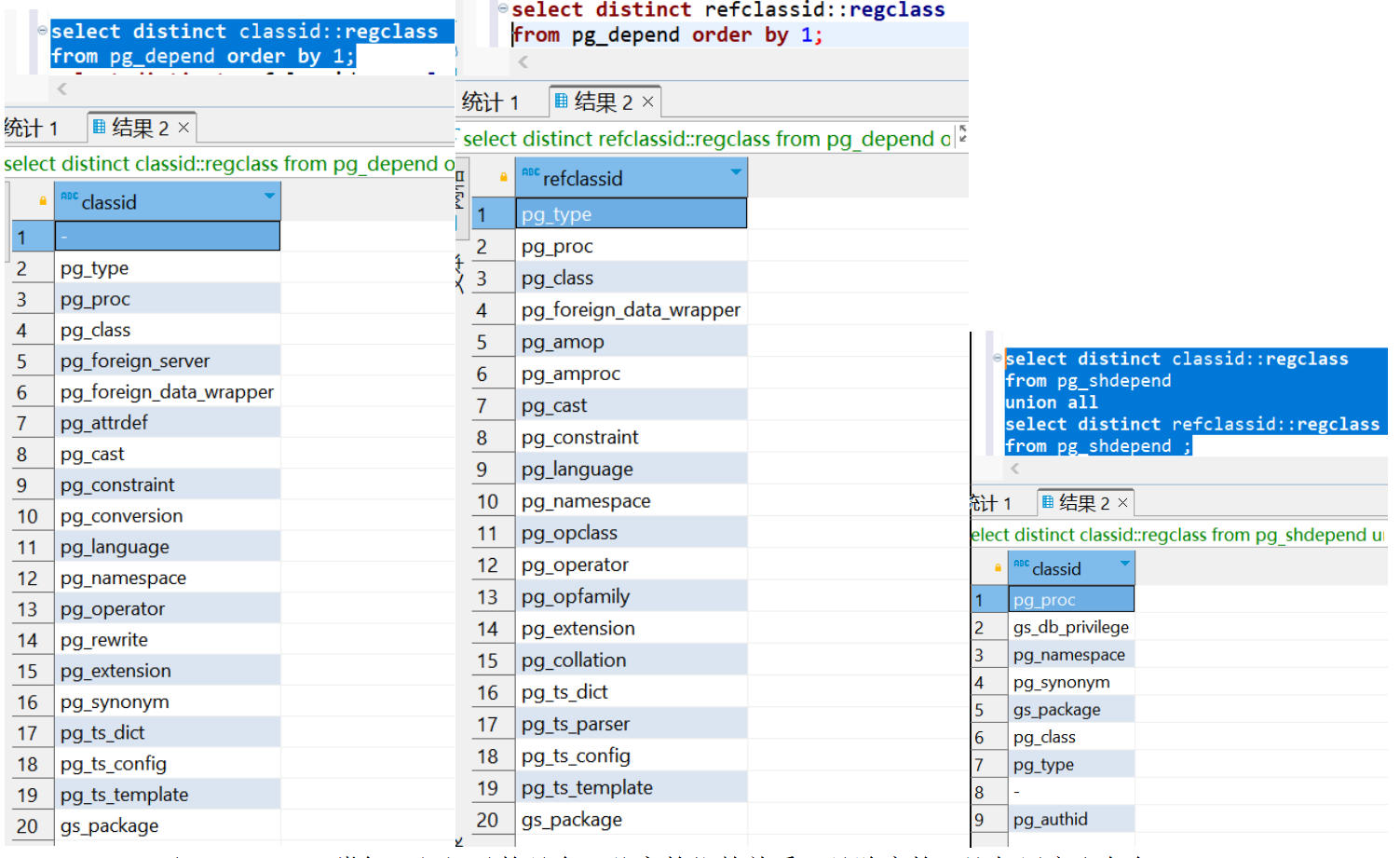
pg_shdepend和pg_depend类似,但区别在于,pg_shdepend记录的是全局共享的依赖关系,是跨库的,比如用户和角色(pg_authid);而pg_depend只记录本库的。注意这两者之间不是包含关系。
regclass是一个"对象标识符类型",可以将oid转换成对应在pg_class的名称(MogDB 5.2版本中新增了regrole和regnamespace)。
可以看到这里的classid,在pg_class中对应的都是系统元数据表,即classid表示的每一个表,都是一种对象所属的类。
第二个字段objid,即为前面这个类下的一个对象id
我们任意取一笔记录,来看怎么找到这个对象
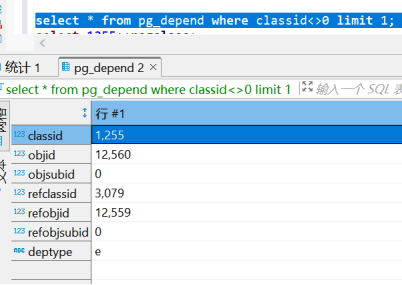
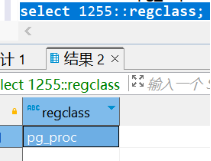
该行记录的系统类为1255,可以查到对应pg_proc;
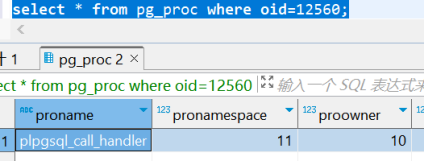
对象id为12560,那我们就去pg_proc里查oid=12560的记录,即可找到该对象是什么
以pg_depend进行管中窥豹,可以大致了解这些系统表的组织关系。
二、pg_class
pg_depend里这些classid都是pg_class的某一行的oid,包括pg_class这个表本身的oid,也是relname=’pg_class’这一行的oid。
但我们知道,pg_class里不是只有系统表的名称,还有普通表、视图、索引的名称也都会记录在里面,那么pg_class里到底会存哪些对象?
我们看下pg_class的表结构,由于该表的字段太多,本次我们只关注它有哪些对象,关键在relkind这个字段
| relkind | 说明 |
|---|---|
| r | 表示普通表 |
| i | 表示索引 |
| I | 表示分区表GLOBAL索引 |
| S | 表示序列 |
| L | 表示Large序列 |
| v | 表示视图 |
| c | 表示复合类型 |
| t | 表示TOAST表 |
| f | 表示外表 |
| m | 表示物化视图 |
可以看到,这里的种类其实都拥有类似于表(或叫relation)的结构,即拥有多个字段,不过比较特殊的是索引和复合类型这两者,这两者不能通过sql语句直接查里面的数据,而复合类型本身更是没有数据内容
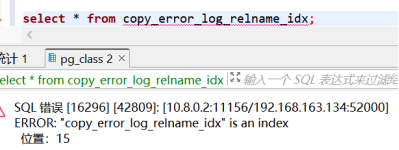
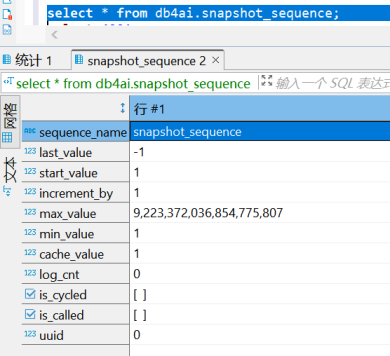
序列其实就是一张只有一行的表
在pg_attribute中,可以根据pg_class中的oid,查到该relation所包含的所有字段(包括隐藏字段和被删除字段),
也就是说,理论上,在MogDB中,下面这条SQL应该是查不出记录的(原生postgresql支持零列的表,但是仍然包含隐藏字段)
select * from pg_class c where not exists
(select 1 from pg_attribute a where c.oid=a.attrelid);
pg_class中的每个oid(除了索引),都在pg_type中存在一条对应的记录,pg_class.oid=pg_type.typrelid
这意味着,每个relation自己,又都是各自的”类”,而relation里面的每行数据(tuple),是这个类的”对象”
至此,整个数据库中的所有数据,都是符合”类-对象”的特征
| 类层级 | 类 | 对象层级 | 对象 |
|---|---|---|---|
| 0-主类 | pg_class | 1-元数据表 | 一个元数据表(比如pg_proc、pg_type) |
| 1-元数据表 | pg_class | 2-对象(relation) | 一个relation(比如一个自建表、一个序列) |
| 1-元数据表 | pg_proc | 2-对象(proc) | 一个函数(比如length、sum) |
| 1-元数据表 | pg_type | 2-对象(type) | 一个数据类型(比如varchar、int) |
| 2-对象(relation) | 一个自建表 | 3-行(tuple) | 表的一行 |
三、系统元数据表清单
以上为MogDB/openGauss/postgresql的系统表元数据设计及其之间的逻辑关系,接下来我们看具体的元数据表,以下只列举一些常见的
| 表名 | ORACLE视图名 | 扩展视图或扩展表 | 备注 |
|---|---|---|---|
| pg_database | dba_pdbs/sys.container$ | 数据库列表 | |
| pg_collation | 字符排序规则 | ||
| pg_conversion | 字符编码转换规则 | ||
| pg_authid | dba_users/sys.user$ | pg_user | 用户,pg_user隐藏了密码,加了用户级guc参数展示 |
| pg_roles | 角色,按权限过滤展示 | ||
| pg_auth_history | 历史密码变更记录 | ||
| pg_auth_members | 继承角色关系 | ||
| pg_group | 关联查询pg_auth_members | ||
| gs_db_privilege | any权限 (PG没有) | ||
| pg_default_acl | 新对象的默认权限(比如给schema下的新表默认查询权限) | ||
| pg_user_status | 用户状态(登录失败次数、密码过期) | ||
| pg_namespace | 模式(schema) | ||
| pg_class | dba_tables | pg_tables | 所有的表和类似表的对象(relation),都在pg_class中 |
| dba_views | pg_views | 里面查询了pg_rewrite获取定义 | |
| pg_index | dba_indexex/dba_ind_columns | pg_indexes | 索引 |
| pg_constraint | dba_constraint | 约束 | |
| pg_partition | dba_tab_partitionsdba_tab_subpartitions | 分区表和子分区表 | |
| pg_rewrite | pg_rules | 视图的定义在重写规则里,pg_rules只展示非select的规则 | |
| gs_matview | dba_mviews | gs_matview_dependency (物化视图依赖基表) | 物化视图 (PG没有) |
| pg_type | dba_types | pg_enum (枚举类型) | 注意create table或view时,会同时create一个同名的type |
| pg_range (范围类型) | |||
| pg_set (set类型, B 模式专用) (PG没有) | |||
| pg_attribute | dba_tab_cols | pg_attrdef (属性的默认值) | 针对pg_class中每个oid的属性(比如表的字段) |
| pg_description | |||
| pg_shdescription | sh指在各个db中共享,比如pg_database表就是一个共享表 | ||
| pg_proc | dba_procedures | pg_aggregate (聚合函数) | 所有的function和procedure,包括package内的 |
| pg_language | 支持的pg_proc语言 | ||
| gs_package | gs_object (object-type,MogDB 5.2新增 ) | 所有的package(PG没有) | |
| pg_trigger | dba_triggers | DML触发器(含truncate) | |
| pg_event_trigger | 事件触发器(比如ddl) | ||
| pg_extension | 扩展插件 | ||
| pg_synonym | dba_synonyms | 同义词(PG没有) | |
| pg_foreign_server | dba_db_links | 外部服务器 | |
| pg_foreign_data_wrapper | 外部数据封装器 | ||
| pg_foreign_table | 外部表 | ||
| pg_depend | dba_dependencies | 依赖关系 | |
| pg_shdepend | 共享依赖关系 | ||
| pg_job | dbms_job 功能的相关表 | 定时任务(PG没有) | |
| pg_job_proc | |||
| gs_job_argument | dbms_schedule 功能的相关表 | 定时任务(openGauss没放出sql函数接口) | |
| gs_job_attribute | |||
| pg_operator | v$sqlfn_metadata | 操作符 | |
| pg_opclass | 操作符类 | ||
| pg_opfamily | 操作符族 | ||
| pg_cast | 类型转换 | ||
| pg_am | 访问方法(hash、btree…) | ||
| pg_amop | 访问方法的操作符 | ||
| pg_amproc | 访问方法调用的函数 | ||
| pg_object | dba_objects | 所有对象(目前只包含以下)s 序列、l 大序列、v 视图、r 表、i 索引、P 存储过程、函数、S 包说明/object-type说明、B 包体/object-type体 | |
| pg_directory | dba_directory | 数据库目录 | |
| pg_db_role_setting | 设置到数据库、用户级别的参数 | ||
| pg_statistic | 统计信息 | ||
| gs_dependencies_obj | gs_dependencies | plsql编译依赖关系(openGauss 6.0/MogDB 5.2新增) | |
| pg_rlspolicy | 行级访问策略 | ||
| pg_inherits | 继承表 | ||
| gs_masking | gs_masking_policy | 动态脱敏(PG没有) | |
| gs_masking_policy_actions | |||
| gs_masking_policy_filters |
四、元数据表字段名设计
几乎所有的元数据表的字段名,都有一个特征,即有一个该表表名的三到四个字母缩写作为前缀。
比如pg_type表中的字段,是以typ开头,比如typnamespace、typname;
比如pg_proc表中的字段,是以pro开头,比如pronamespace、proname;
比如pg_attribute表中的字段,是以att开头,比如attrelid、attname;
有个特殊点的,pg_class,是以rel(即relation)开头,比如relnamespace、relname。
这种设计的好处是让所有的元数据字段能平面化,和内核一一对应,不存在一个属性名同时存在于多个地方。
五、总结
得益于postgresql这种严谨的设计,让所有内核开发者能遵循统一的规则来进行新功能的扩展;并且由于其极其简单明了的对象组织关系,让初学者也可以很快对数据库有个框架性的理解,只是千万不要死记硬背, 学习postgresql的优势在于,它几乎全部的功能都可以从表中查到,并且最终回到pg_class这个表上来。openGauss/MogDB继续延续这种设计,让国产数据库站在前辈们的肩膀上继续壮大。
- 本文作者: DarkAthena
- 本文链接: https://www.darkathena.top/archives/System-Metadata-Design-of-MogDB-openGauss-PostgreSQL-Starting-from-pg_depend-and-pg_class
- 版权声明: 本博客所有文章除特别声明外,均采用CC BY-NC-SA 3.0 许可协议。转载请注明出处