ctr/cvr预估之Wide&Deep模型
在探索点击率(CTR)和转化率(CVR)预估的领域中,我们始终追求的是一种既能捕获数据中的线性关系,又能发现复杂模式的模型。因子分解机(Factorization Machines, FM)模型以其在处理稀疏特征和特征交互方面的优势,赢得了广泛的关注和应用。然而,随着业务需求的不断深化和数据复杂性的增加,FM模型在某些场景下可能难以充分挖掘数据的非线性特性。
在这样的背景下,Wide & Deep 模型应运而生,它是一种创新的机器学习架构,旨在结合线性模型的可解释性和深度神经网络的自动特征学习能力。Wide部分,即广义线性模型(Wide Part),负责学习数据中的一阶特征和线性关系;而Deep部分,即深度神经网络(Deep Part),负责捕捉高阶特征交互和非线性模式。
文章目录
- ctr/cvr预估之Wide&Deep模型
- 一、什么是Wide&Deep模型
- 二、Wide&Deep模型提出背景
- 三、Wide&Deep模型原理
- Wide侧
- Deep侧
- 联合训练(joint training)
- 四、Wide&Deep模型注意事项
- 五、Wide&Deep模型的核心参数以及实现代码
一、什么是Wide&Deep模型
Wide & Deep模型是一种结合了线性模型和深度神经网络的机器学习架构,专为处理推荐系统和广告点击率预估等任务中的高维稀疏数据而设计。该模型包含两个主要部分:Wide部分和Deep部分。
Wide部分基于广义线性模型,能够捕获数据中的一阶特征和线性关系,它通过大量的稀疏特征和特征组合来学习模型的线性信号,这使得模型能够解释和利用已有的领域知识(增强记忆[memorization]能力)。
Deep部分则是一个深度神经网络,能够自动学习数据中的高阶特征交互和非线性模式。通过非线性变换,Deep部分能够捕捉复杂的特征关系,发现数据中的隐含结构(增强泛化[generalization]能力)。
Wide & Deep模型的优势在于它结合了线性模型的可解释性和深度学习的自动特征学习能力,这使得它在处理大规模稀疏数据集时,能够提供更准确的预测和更好的泛化能力。
二、Wide&Deep模型提出背景
在前DeepLearning时代,以Logistic Regression(LR)为代表的广义线性模型在CTR,CVR中得到了广泛的应用,主要原因包括:(1)模型足够简单,相当于不包括隐含层的神经网络;(2)可扩展性强;(3)可解释性强,因为是线性的模型,可以很方便的显现出特征对最终结果的强弱。
虽然线性模型有如上的优点,但同时也存在很多的不足,其中最重要的是无法处理特征的交叉,泛化能力较差。在以CTR为代表的Ranking问题中,需要同时获得记忆(memorization)和泛化(generalization)的能力。记忆可以理解为从历史数据中学习到item或者特征之间的共现关系,泛化则是对上述共现关系的传递,能够对未出现的关系对之间的共现关系进行判定。
逻辑回归(LR)模型具备良好的记忆能力,而深度神经网络(DNN)模型则展现出卓越的泛化能力。因此,结合这两种能力的Wide&Deep模型应运而生,旨在更高效解决Ranking问题。在Wide&Deep模型中,LR模型构建了模型的Wide侧,DNN模型则形成了Deep侧。
三、Wide&Deep模型原理
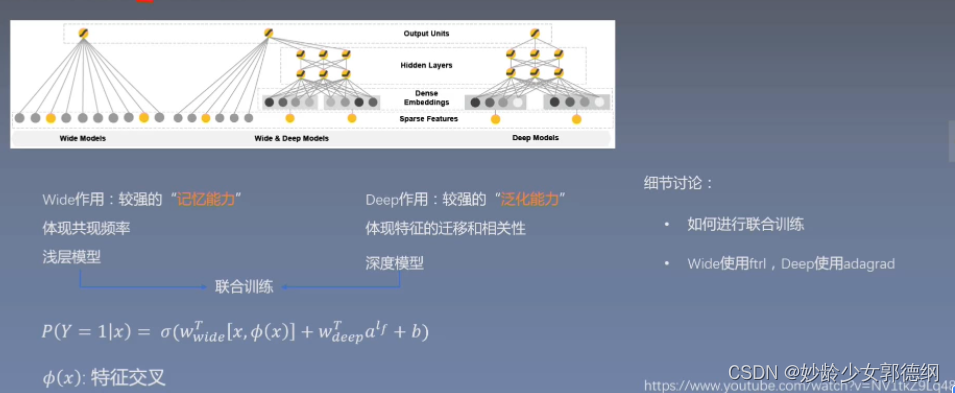
在Wide&Deep模型中包括两个部分,分别为Wide部分和Deep部分。
Wide侧
Wide侧本质是一个广义的线性回归模型
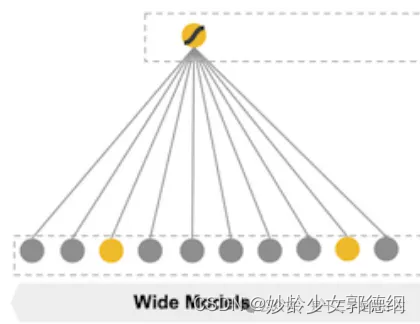
其中不仅包含了原始的特征,还包括了一些衍生的交叉特征。
Deep侧
Deep侧则是一个典型的DNN模型
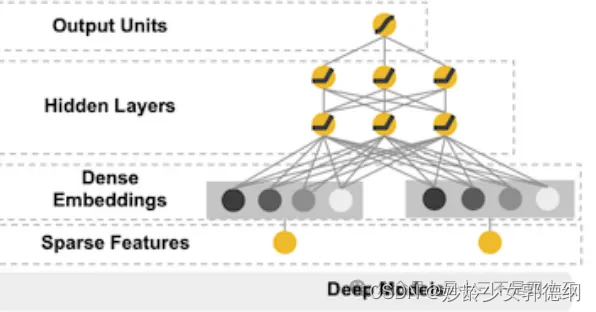
在DNN模型中,通常将离散的稀疏特征通过Embedding层转换成连续的稠密特征,代入模型训练。
联合训练(joint training)
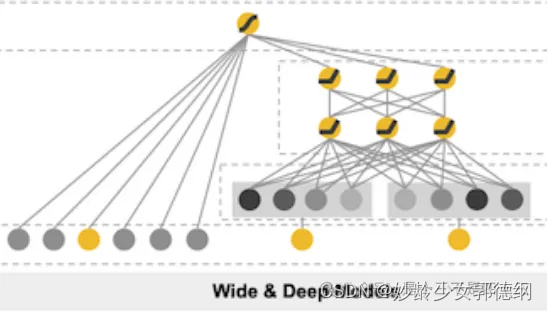
同时训练Wide侧模型和Deep侧模型,将两个模型的结果的加权和作为最终的预测结果。
四、Wide&Deep模型注意事项
- 特征选择:Wide部分通常需要手工选择具有业务意义的特征,如ID交叉特征,以利用其记忆能力对特定规则进行建模。Deep部分则可以利用嵌入向量自动学习特征表示,因此需要选择适合深度学习的原始特征。Wide部分通常使用一些高基数的离散特征和它们的交叉特征,以增强模型的记忆能力;而Deep部分则使用连续特征和低基数的离散特征,以提高模型的泛化能力。
- 模型结构设计:在设计模型结构时,应确保Wide部分足够简单,通常是一个单层的线性模型,直接连接输入和输出。Deep部分则可以是一个多层感知机(MLP),用于学习特征间的复杂交互。Deep部分的网络结构设计对模型的效果有重要影响。需要合理设置层数、神经元数目以及激活函数等,以确保模型可以学到有效的非线性特征。
- 正则化和优化:为了避免过拟合,特别是在Deep部分,需要合理使用正则化技术,如L1、L2正则化。同时,选择合适的优化器和学习率也是模型训练的关键。
- 特征交叉:在Wide部分,特征交叉可以显著提升模型性能,但也需要避免过多的特征交叉导致模型复杂度过高。
- 数据预处理:对输入数据进行适当的预处理,如归一化(尤其对于连续型特征)、独热编码等,以提高模型的稳定性和性能。
五、Wide&Deep模型的核心参数以及实现代码
Wide&Deep模型核心参数以及实现代码
