背景需求
【教学类65-01】20240622秘密花园涂色书01(通义万相)(A4横版2张,一大3小 38张纸76份)-CSDN博客文章浏览阅读118次。【教学类65-01】20240622秘密花园涂色书01(通义万相)(A4横版2张,一大3小 38张纸76份)https://blog.csdn.net/reasonsummer/article/details/139899797
以上链接于小图片中的人物图片只有76张,所以花园图片也只能最多76张,
但我希望把下载花园图片136张都做成涂色卡。
素材准备
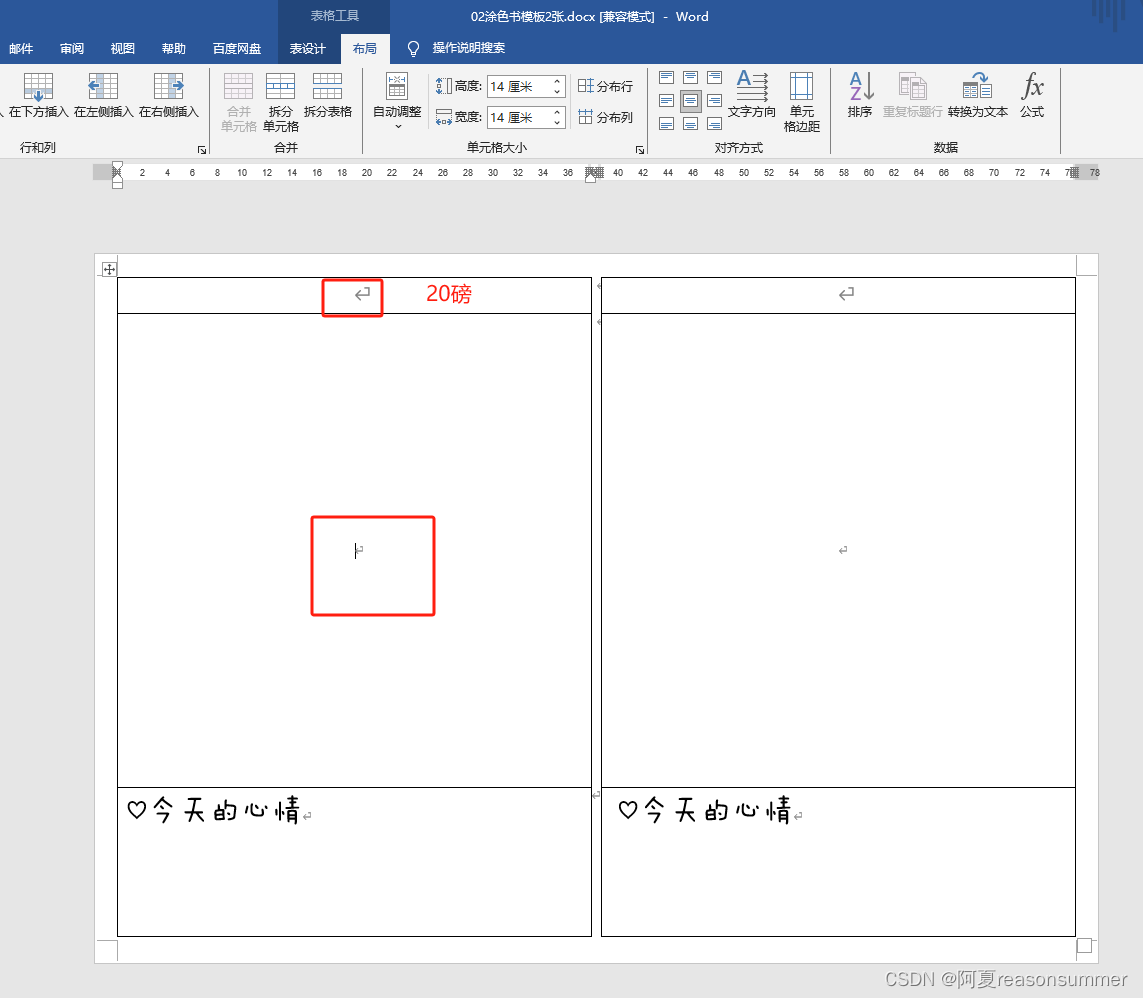
图片准备:
代码展示
'''
秘密花园涂色书(通义,模板2图)
作者:AI对话大师,阿夏
2024年6月22日'''import docx
import os
import time
import random
from docx import Document
from docx.shared import Pt, Inches, Cm, RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.enum.text import WD_ALIGN_PARAGRAPH
# from docx.enum.text import WD_VERTICAL_ALIGNMENT
# from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convertprint('----------第1步:提取所有的幼儿照片的路径------------')
# 文件信息
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\秘密花园涂色书'
image_folder=path+r'\01jpg'
# 新建文佳佳
ten_folder = path+r'\零时Word'
os.makedirs(ten_folder , exist_ok=True)# 6个文件夹
image_files = [os.path.join(image_folder, file) for file in os.listdir(image_folder) if file.endswith('.png')]
grouped_files = [image_files[i:i+2] for i in range(0, len(image_files), 2)]
print(grouped_files)
# # 55pic=['10','12']
long=['14','14']
wide=['14','14']
# 每4个图片一组进行处理s=1
for nn in range(0,int(len(grouped_files))): # 读取图片的全路径 的数量 31张doc = Document(path+r'\01涂色书模板2张.docx')table = doc.tables[0] # 4567(8)行# 假设字体名称为"Your Font Name"font_name = r"C:\Windows\Fonts\FZMWFont.ttf"for t in [0, 2]:# 设置单元格内容cell_0_0 = table.cell(0, t)cell_0_0.text = f"秘密花园涂色书——{s:03d}"cell_0_0.paragraphs[0].alignment = docx.enum.text.WD_ALIGN_PARAGRAPH.CENTERcell_0_0.paragraphs[0].runs[0].font.size = Pt(20) # 设置字体大小cell_0_0.paragraphs[0].runs[0].font.name = font_name # 设置字体名称cell_0_0.paragraphs[0].runs[0].font.bold = True # 设置字体加粗s += 1for l in range(len(long)):# 单元格坐标a=int(pic[l][0])b=int(pic[l][1])figures=grouped_files[nn][l] # 图片的全路径的第一张
## 写入1张大图run=doc.tables[0].cell(a,b).paragraphs[0].add_run() # # 图片位置 第一个表格的0 3 插入照片run.add_picture(r'{}'.format(figures),width=Cm(float(long[l])),height=Cm(float(wide[l])))table.cell(a,b).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中 doc.save(ten_folder+r'\{}.docx'.format('%02d'%nn)) from docx2pdf import convert# docx 文件另存为PDF文件inputFile = ten_folder+fr'\{nn:02d}.docx' # 要转换的文件:已存在outputFile = ten_folder+fr'\{nn:02d}.pdf' # 要生成的文件:不存在# 先创建 不存在的 文件f1 = open(outputFile, 'w')f1.close()# 再转换往PDF中写入内容convert(inputFile, outputFile)print('----------第4步:把都有PDF合并为一个打印用PDF------------')# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = ten_folder
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:print(pdf)file_merger.append(pdf)
file_merger.write(path+fr"\02涂色书2图标题({len(image_files)}人共{int(len(image_files)/2)}份).pdf")
file_merger.close()
# doc.Close()# print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree(ten_folder) #递归删除文件夹,即:删除非空文件夹结果展示