最近我在进行一些前端小开发,遇到了一个小需求:我想要将数据导出到 Excel 文件,并希望能够封装成一个函数来实现。这个函数需要接收一个二维数组作为参数,数组的第一行是表头。在导出的过程中,要能够确保避免出现中文乱码的情况。另外,考虑到数组中可能包含回车、逗号、换行符等特殊字符,咱们该如何处理这些情况呢?
解决方案
1、导出CSV文件
将一个二维数组导出为CSV文件,这种操作比较简单,这里咱们不直接依赖外部库,使用纯JavaScript在浏览器中导出CSV文件,具体的操作步骤可以如下所示:
- 将二维数组中的每一行数据转换为CSV格式,但是要确保特殊字符(如回车、逗号、emoji等)被正确处理
- 添加UTF-8 BOM(Byte Order Mark)以确保生成的CSV文件在处理中文时不会出现乱码。
- 创建一个Blob对象,将CSV数据转换为一个包含MIME类型为
text/csv;charset=utf-8;的Blob。 - 创建一个不可见的
<a>标签,设置href为Blob对象的URL,并设置download属性为导出的文件名。 - 模拟点击该链接以触发下载,然后移除该链接。
示例代码:
/*** 将二维数组导出为CSV文件并下载* @param {Array<Array<string>>} data - 要导出的二维数组* @param {string} filename - 导出的CSV文件名*/
const exportToCSV = (data, filename) => {// 转换数组中的每一行数据为CSV格式const csvContent = data.map(row => row.map(item => {// 处理包含逗号、回车或双引号的内容if (item.includes(',') || item.includes('\n') || item.includes('"')) {// 将双引号替换为两个双引号,并包裹在双引号内item = `"${item.replace(/"/g, '""')}"`;}return item;}).join(',')).join('\n');// 确保使用UTF-8 BOM防止中文乱码const bom = '\uFEFF';const csvData = bom + csvContent;// 创建一个Blob对象并指定MIME类型为text/csvconst blob = new Blob([csvData], { type: 'text/csv;charset=utf-8;' });// 创建一个下载链接const link = document.createElement('a');if (link.download !== undefined) {// 设置下载文件名link.href = URL.createObjectURL(blob);link.download = filename;link.style.visibility = 'hidden';// 触发下载document.body.appendChild(link);link.click();document.body.removeChild(link);}
};// 导出函数以便其他文件使用
module.exports = exportToCSV;
使用示例:
const exportToCSV = require('./exportToCSV');const data = [['姓名', '年龄', '地址'],['张三', '25', '北京\n中国'],['李四', '30', '上海,中国'],['王五', '35', '广州"中国"']
];exportToCSV(data, 'output.csv');
拓展知识:在
data:text/csv;charset=utf-8,\uFEFF中,\uFEFF是一个特殊的Unicode字符,称为“零宽度无间断空格”(Zero Width No-Break Space,ZWNBSP)。在CSV文件的开头放置\uFEFF字符,主要是为了标记文件的字节顺序(Byte Order Mark, BOM),指示其采用UTF-8编码,帮助某些文字处理器或应用程序正确识别文件的编码方式,尤其是那些可能不默认使用UTF-8编码的程序。
这里面会有一些弊端,比如我要导出的内容包含回车等字符,这就导致用excel打开的时候,内容会把行高撑得很高,在屏幕上显示不了两行内容,但在纯CSV文件中,无法直接设置行高或格式化样式,因为CSV文件是一种纯文本格式,不支持这些样式属性。这时候就要考虑另一种导出方式了。
2、导出Excel文件
首先咱们要在项目中引入SheetJS库。我这项目是webpack打包的,所以我通过npm安装
npm install xlsx
纯网页应用可以通过CDN引入
<script src="https://cdnjs.cloudflare.com/ajax/libs/xlsx/0.16.2/xlsx.full.min.js"></script>
接下来就是根据需求写代码,我这里不仅添加了行高的设置,还对每一列做了宽度的设置,如果没有这个参数,默认列宽为30个字符,
示例代码:
import XLSX from 'xlsx'/*** 将二维数组导出为Excel文件并下载* @param {Array<Array<string>>} data - 要导出的二维数组* @param {string} filename - 导出的Excel文件名* @param {Array<number>} [colWidths] - 每列的宽度(以字符数为单位)*/
export const exportToExcel = (data, filename = 'download.xlsx', colWidths = []) => {// 创建一个新的工作簿const wb = utils.book_new();// 将二维数组数据转换为工作表const ws = utils.aoa_to_sheet(data);// 获取工作表的范围(包括所有单元格)const range = utils.decode_range(ws['!ref']);// 遍历所有单元格,设置单元格样式for (let R = range.s.r; R <= range.e.r; ++R) {for (let C = range.s.c; C <= range.e.c; ++C) {const cellAddress = { c: C, r: R }; // 单元格地址const cellRef = utils.encode_cell(cellAddress); // 单元格引用if (!ws[cellRef]) continue; // 如果单元格不存在,跳过// 设置单元格样式ws[cellRef].s = {alignment: {wrapText: true, // 自动换行vertical: 'center', // 垂直居中horizontal: 'center' // 水平居中}};}}// 设置行高ws['!rows'] = []; // 初始化行高数组for (let R = range.s.r; R <= range.e.r; ++R) {ws['!rows'][R] = { hpx: 24 }; // 设置每行高度为24像素}// 设置列宽const defaultColWidth = 30; // 默认列宽const numberOfColumns = range.e.c - range.s.c + 1; // 计算总列数// 如果提供了列宽数组,使用提供的宽度,否则使用默认宽度ws['!cols'] = colWidths.length > 0 ? colWidths.map((width) => ({ wch: width })) : Array(numberOfColumns).fill({ wch: defaultColWidth });// 将工作表添加到工作簿中utils.book_append_sheet(wb, ws, 'Sheet1');// 生成Excel文件并触发下载writeFile(wb, filename);
};export default exportToExcel;
问题
在使用webpack打包的时候,尽管在Webpack配置中使用了webpack.ProvidePlugin来提供process模块,但仍然出现Module not found: Error: Can't resolve 'process/browser' 错误,SheetJS尝试引用process模块,但是在浏览器环境中默认情况下没有提供这个模块。
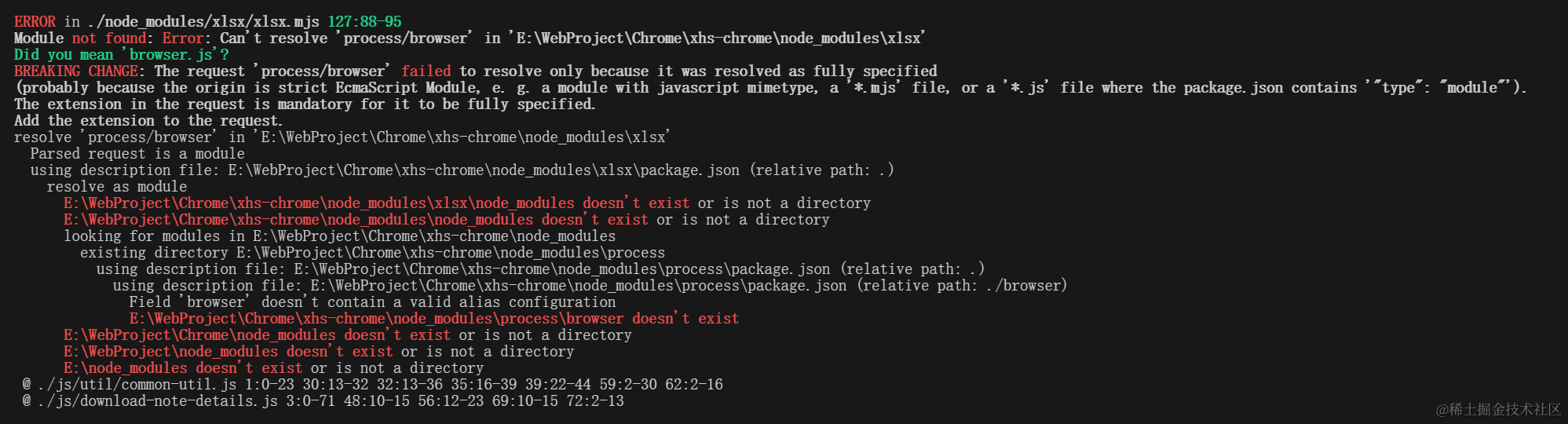
这该怎么办呢?
1、安装需要的所有依赖,确保SheetJS需要的依赖都存在
npm install process stream-browserify crypto-browserify path-browserify os-browserify buffer
2、修改webpack的配置
module.exports = {module: {rules: [{test: /\.mjs$/,resolve: {// 在解析模块路径时,允许导入不带扩展名的模块。// 在严格的 ES 模块规范中,导入时必须提供完整的路径和扩展名。设置 `fullySpecified: false` 可以放宽这个限制,允许省略扩展名。fullySpecified: false },include: /node_modules/,// Webpack 中的 `javascript/auto` 类型允许文件使用混合的 CommonJS 和 ES 模块语法。// 这样可以更好地兼容一些使用 `.mjs` 扩展名但并不完全符合 ES 模块规范的第三方库。type: 'javascript/auto'}]},resolve: {fallback: {"process": require.resolve('process/browser'),"stream": require.resolve("stream-browserify"),"crypto": require.resolve("crypto-browserify"),"path": require.resolve("path-browserify"),"os": require.resolve("os-browserify/browser"),"fs": false}},plugins: [new webpack.ProvidePlugin({process: 'process/browser',Buffer: ['buffer', 'Buffer']})]
}
上面的规则块的目的是为了处理
node_modules中的.mjs文件,使其能在 Webpack 中正确解析和打包。这对一些使用 ES 模块的第三方库(如xlsx)特别重要,因为这些库有时会使用.mjs扩展名但并不完全符合严格的 ES 模块规范。
最后我添加了这个规则才解决了问题,我太难了。