AI数据管道(Data Pipeline)是指在AI项目中,数据从原始状态到最终可用模型的整个处理流程,包括数据采集、清洗、转换、分析、训练模型、验证模型直至部署和监控等多个环节。

-
在AI训练和推理过程中,多个管道可能同时读取大量数据用于训练或写入处理后的数据,这会显著增加存储系统的I/O(输入/输出)负载,可能导致存储性能瓶颈。
-
随着AI模型和数据集的规模不断扩大,存储容量需求急剧增长,尤其是考虑到模型版本管理、历史数据保留和备份需求。
-
模型训练和推理需要快速访问数据以保持计算资源(如GPU)的高效利用,低效的存储访问会导致GPU空闲等待,影响整体处理速度。
-
分布式存储和数据并行处理策略要求存储系统能够高效地跨多个节点分配和同步数据,这对存储的网络带宽和一致性协议提出更高要求。
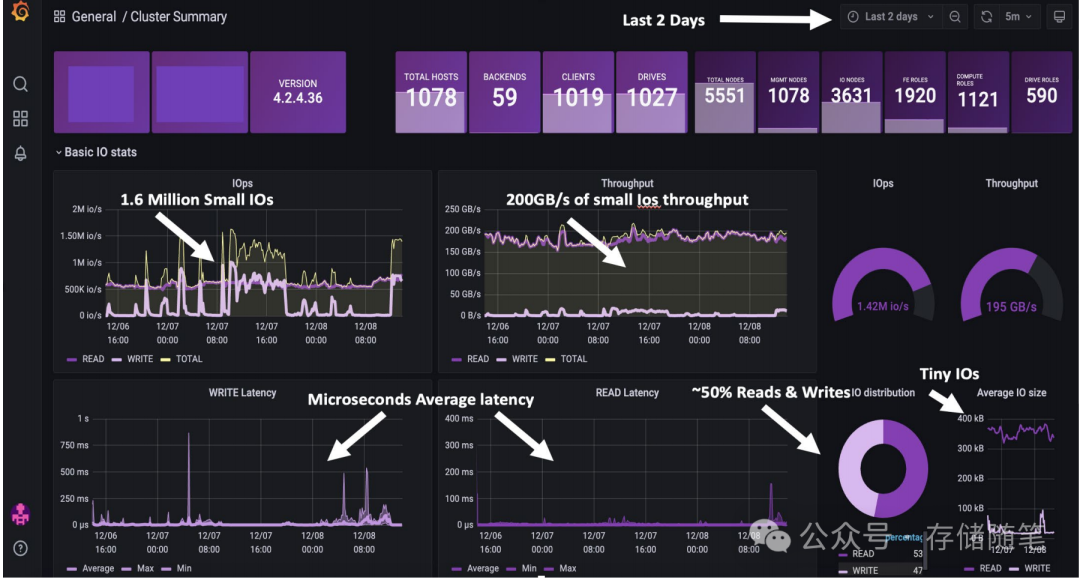
AI应用程序在处理大规模数据集和复杂模型训练时,往往展现出独特的IO模型,特别是当提到"数百万个小IO读写操作"时,AI工作负载,尤其是在深度学习训练阶段,经常涉及对大量小块数据的频繁读取和写入操作。这些小I/O操作可能是由于以下几个原因:
-
模型参数更新:在训练过程中,模型的权重和偏置等参数需要不断微调,每次调整可能只涉及到模型参数的一小部分,导致频繁的小数据块写入。
-
数据预处理:AI应用通常需要对原始数据进行预处理,如图像裁剪、标准化等,这个过程可能产生大量的小I/O操作。
-
批次处理:为了高效利用计算资源,AI训练通常采用批次处理,每个批次可能只包含少量样本,导致对数据集的连续小批量读取。
小IO请求相比大块连续读写更容易造成存储设备的随机访问压力,降低IOPS和吞吐量。AI训练对数据访问延迟非常敏感,频繁的小I/O可能会累积延迟,影响训练效率和模型收敛速度。大量并发的小I/O请求可能导致存储资源过度碎片化,影响存储空间的有效利用率。
此外,训练数据存储的读取带宽需求存在巨大差异,这一现象主要取决于两个关键因素:模型的计算约束程度(compute boundness)和输入数据的大小。
1. 模型的计算约束程度(Compute Boundness)
-
定义与影响:计算约束指的是模型在运行过程中,其计算能力(CPU或GPU等处理器的算力)相对于数据读取速度的限制程度。如果一个模型的计算密集度非常高,意味着它的大部分执行时间都花在了复杂的数学运算上,而不是等待数据从存储中读取出来。反之,如果模型较为依赖数据输入,且计算相对简单,则可能更多受限于数据读取速度。
-
读带宽需求:对于计算密集型的模型,即使数据读取速度稍慢,对整体训练速度的影响也可能相对较小,因此对存储读取带宽的需求较低。相反,如果模型不是特别计算密集,而是频繁等待数据输入,那么就需要高速的存储读取能力,以减少I/O等待时间,进而提高训练效率。因此,计算约束程度低的模型对存储读带宽的要求通常更高。
2. 输入数据的大小
-
影响因素:输入数据的大小直接影响了模型训练过程中每次迭代需要从存储中读取的数据量。大型模型或者处理高分辨率图像、长序列文本等复杂数据的任务,往往需要处理更大体积的数据集,这自然就要求存储系统能提供更高的读取带宽。
-
读带宽需求:随着输入数据大小的增加,为了保证数据能够及时供给计算单元,避免计算资源空闲等待,对存储系统读取带宽的需求也随之上升。例如,在处理高分辨率图像分类或大规模语言模型训练时,由于每次迭代需要从存储中加载大量数据,因此对读带宽的需求远高于处理小规模或低维度数据的模型。
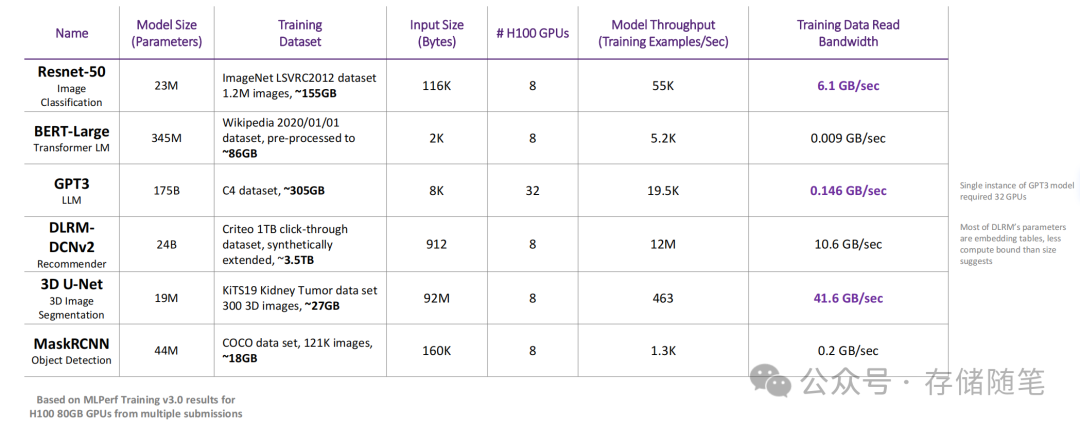
鉴于上述因素,为了优化训练效率,实践中可能采取以下策略:
-
分层存储:采用多层次存储方案,将频繁访问的数据或活跃数据缓存在高速存储(如SSD)中,而较少访问的数据则存储在低成本但容量大的存储(如HDD)中。(扩展阅读:深度剖析-大容量QLC SSD为何遭疯抢?)
-
数据预处理:在训练前进行数据预处理,如数据压缩、数据增强等,减少实际需要从存储中读取的数据量。
-
I/O优化:利用软件层面的优化,如异步I/O、数据预读取策略,减少I/O等待时间,提高数据读取效率。
-
分布式训练:采用分布式训练策略,将数据集分割到多个计算节点上,每个节点独立处理一部分数据,这样可以分散对单一存储系统的读取压力,同时利用多个存储设备的总带宽。
-
分布式存储:采用分布式文件系统或对象存储解决方案,通过并行处理小I/O请求来分散负载,提高整体系统吞吐量。
-
数据预加载和预处理:提前将数据加载到内存或更快的存储层,并进行必要的预处理,减少实时I/O需求。
针对AI场景的存储方案,我们来举几个案例:
1.服务器厂商Supermicro提出的优化的存储解决方案:分层存储
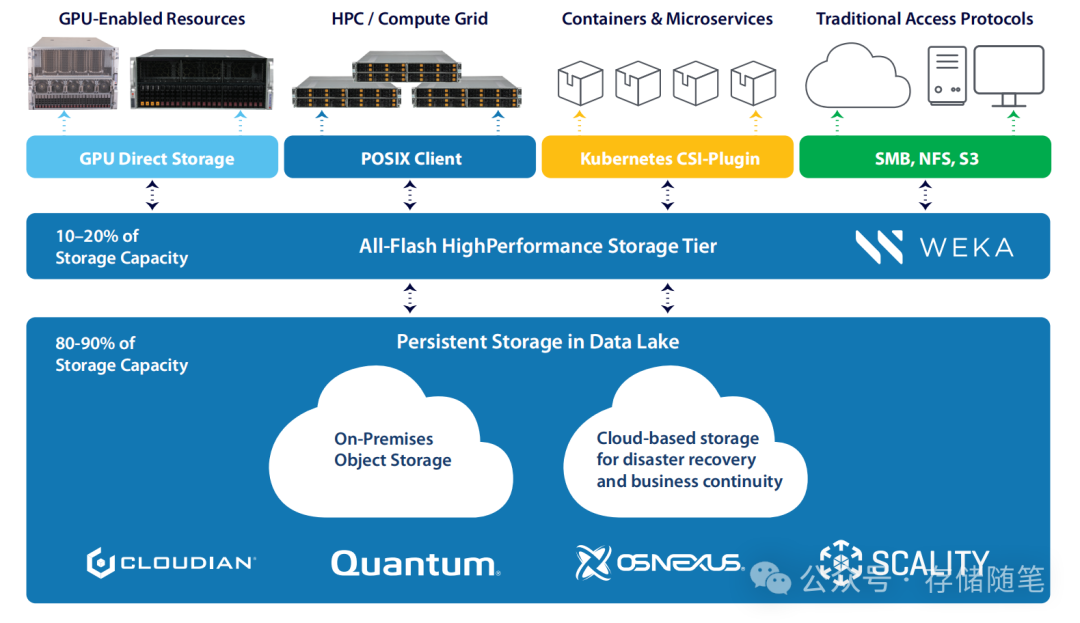
提供由10-20%的闪存和80-90%的数据湖组成的存储方案,平衡了性能与成本。提到的解决方案已在一家跨国高科技制造企业的环境中成功部署,支持了25PB的存储需求,证明了其在实际应用中的可行性和效率。
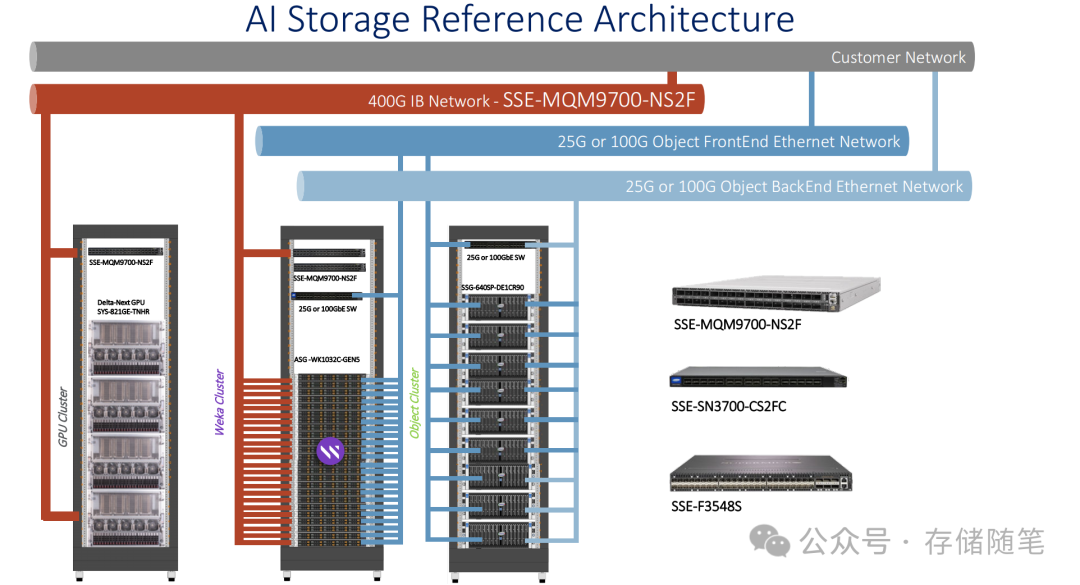
2.云厂商-全栈AI解决方案
(1)阿里云
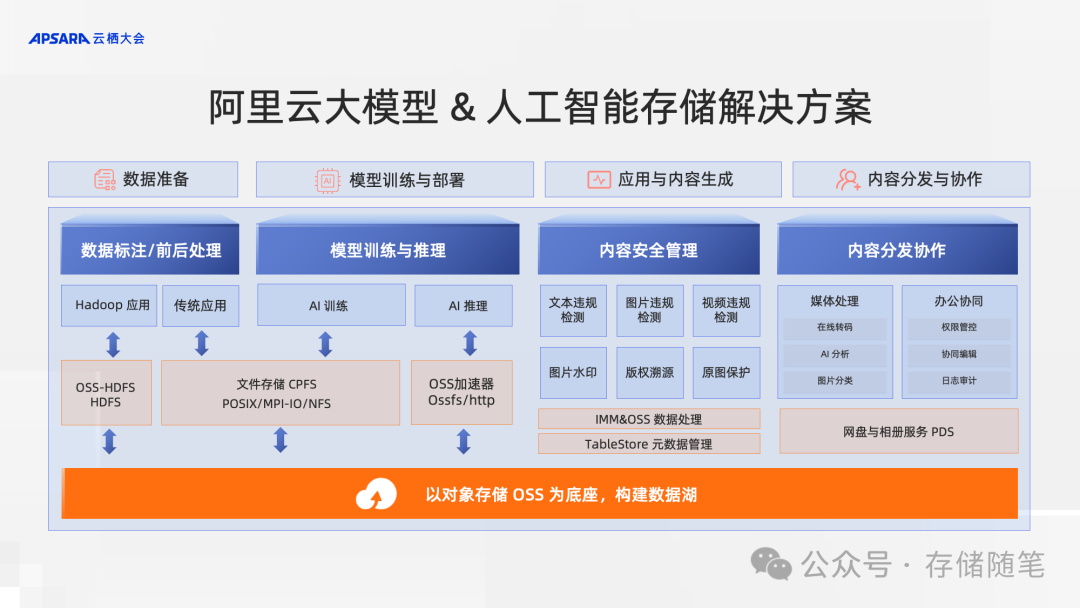
在实际生产过程中,AI 场景分为训练和推理两个流程。其中训练环节需要消耗大量的算力,为了提升算力资源的生产效率,对于数据集和 checkpoint 的读写加速至关重要。阿里云文件存储 CPFS 采用全并行 IO 架构,数据和元数据分片存储在所有节点上,单文件读写可以利用所有节点带宽,同时 CPFS 的弹性文件客户端可以利用近计算端缓存,进一步加速数据集和 checkpoint 读写。产品性能指标最高提供 20TB/s 吞吐和 3 亿 IOPS,在超大规模训练场景下,也能快速完成 checkpoint 读写,加速 AI 训练。
在大规模推理环节时,需要多台 GPU 协同处理,需要短时间内加载模型文件至所有 GPU 服务器的内存。阿里云对象存储 OSS 推出加速器 2.0 功能,以应对存储在对象存储 OSS 中大模型的加载需求。
在整个大模型的业务流程当中,存储数据量庞大,且面对不同流程阶段时,上层应用需要使用不同的数据格式,极为容易发生数据孤岛的情况。阿里云利用对象存储 OSS 的能力,构建统一的数据湖存储,利用对象存储 OSS 的海量扩展、低成本的存储能力,搭建 AI 场景数据存储底座。
(2)腾讯云
腾讯云宣布云存储解决方案面向AIGC场景全面升级,能够针对AI大模型数据采集清洗、训练、推理、数据治理全流程提供全面、高效的云存储支持。数据显示,采用腾讯云AIGC云存储解决方案,可将大模型的数据清洗和训练效率均提升一倍,需要的时间缩短一半。

据介绍,腾讯云AIGC云存储解决方案主要由对象存储COS、高性能并行文件存储CFS Turbo、数据加速器GooseFS和数据万象CI等产品组成。目前,已经有80%的头部大模型企业选择了腾讯云AIGC云存储解决方案,包括百川智能、智谱、元象等明星大模型企业。
参考文献:
-
CMSS24-Cardente-Storage-Requirements-for-AI
-
CMSS24-McLeod-Storage-Architectures-Optimized-for-AI-Workloads
-
white_paper_SMCI_AMD_Accelerating_AI_Data_Pipelines
-
https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
-
https://scoop.market.us/artificial-intelligence-market-news/
-
https://developer.nvidia.com/zh-cn/blog/tips-on-scaling-storage-for-ai-training-and-inferencing/
-
https://developer.aliyun.com/article/1390479
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
-
浅析英伟达GPU NCCL P2P与共享内存
-
3D NAND原厂:哪家芯片存储效率更高?
-
大厂阿里、字节、腾讯都在关注这个事情!
-
磁带存储:“不老的传说”依然在继续
-
浅析3D NAND多层架构的可靠性问题
-
SSD模拟器MQSim简介与资料分享
-
孙凝晖院士万字长文|人工智能与智能计算的发展
-
探究NVMe SSD HMB应用场景与影响
-
深度剖析:大容量QLC SSD为何遭疯抢?
-
SSD突然掉电,是谁保护了用户数据?
-
漫谈HAMR硬盘的可靠性
-
万物皆可计算|下一个风口:近内存计算
-
SSD数据错误如何修复?
-
CXL与PCIe世界的尽头|你相信光吗?
-
全景剖析SSD SLC Cache缓存设计原理
-
存储革新:下一代低功耗PCM相变存储器
-
3D DRAM虽困难重重,最快明年到来
-
字节跳动入局存储内存SCM
-
PCIe 7.0|不要太卷,劝你先躺平
-
SSD LDPC软错误探测方案解读
-
关于SSD LDPC纠错能力的基础探究
-
存储系统如何规避数据静默错误?
-
PCIe P2P DMA全景解读
-
深度解读NVMe计算存储协议
-
对于超低延迟SSD,IO调度器已经过时了吗?
-
浅析CXL P2P DMA加速数据传输的原理
-
浅析LDPC软解码对SSD延迟的影响
-
为什么QLC NAND才是ZNS SSD最大的赢家?
-
SSD在AI发展中的关键作用:从高速缓存到数据湖
-
浅析不同NAND架构的差异与影响
-
SSD基础架构与NAND IO并发问题探讨
-
字节跳动ZNS SSD应用案例解析
-
CXL崛起:2024启航,2025年开启新时代
-
NVMe SSD:ZNS与FDP对决,你选谁?
-
浅析PCI配置空间
-
浅析PCIe系统性能
-
存储随笔《NVMe专题》大合集及PDF版正式发布!