0. 引言
峰峦或再有飞来,坐山门老等。泉水已渐生暖意,放笑脸相迎

小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖铁观音的小男孩。今天这篇小作文主要介绍端侧大模型中的函数调用,即常说的Function calling能力。这是构建Agent必不可少的一个环节,Agent调用各个API或者应用都需要依赖该能力。如想进一步沟通,可以到微信公众号《小窗幽记机器学习》添加小编微信号。
1. 简介
语言模型在自动工作流中的有效性得到了验证,尤其是在函数调用方面。尽管大规模语言模型在云环境中表现优异,但隐私和成本问题仍令人担忧。当前端侧模型在延迟和准确性上面临挑战,研究人员提出了名为Octopus的模型,其2B参数版本在准确性和延迟上超越了GPT-4,并将上下文长度减少了95%。与Llama-7B相比,Octopus的延迟提高了35倍,适合在各种边缘设备上部署。
论文地址:
https://arxiv.org/abs/2404.01744
模型下载地址:
https://huggingface.co/NexaAIDev/Octopus-v2
2. 介绍
大型语言模型在函数调用方面的能力显著促进了AI Agent的发展,如MultiOn、Adept AI等已进入市场。尽管取得了进展,云端部署引发了隐私和成本问题。使用大型语言模型的成本很高,例如与GPT-4互动1小时可能需0.24美元,而基于RAG的方法也需处理大量token,导致成本累积。此外,隐私风险使得许多人对使用GPT-4持谨慎态度。
为了降低成本并增强隐私保护,趋势是开发更小的模型并将其部署于边缘设备。但边缘计算模型往往响应慢,且电池寿命有限。研究指出,10亿参数模型的能耗高达每个token 0.1焦耳,传统方法下会迅速消耗设备电池。因此,Octopus的研究者开发了一种新方法,通过2B参数模型提升精度并降低延迟,达到SOTA效果。Octopus v2的推理过程中节省了95%上下文长度,使得在iPhone上能增加37倍的函数调用,且延迟减少35倍。
3. 相关工作
端侧设备上部署语言模型:将大型语言模型部署到边缘设备面临挑战,但小型模型的应用正变得热门,如Gemma-2B和Llama-7B。MLC LLM框架展示了跨硬件的兼容性。
语言模型中的函数调用:小模型的函数调用能力快速发展,项目如Toolformer和Taskmatrix证明了7B和13B模型能有效调用外部API。
语言模型的微调和适配器:微调已成为常见方法,LoRA在有限资源下训练模型,显示出良好的扩展性。
4. 方法
本节介绍Octopus v2模型的方法及数据集的收集过程。以Android API为例,探讨Octopus v2的训练细节。
4.1 因果模型作为分类模型
成功调用函数需准确选择函数并生成参数,包含函数选择和参数生成两个步骤。可将函数选择视为softmax分类问题。
另一种方法是基于检索,通过语义相似性识别最接近用户query的函数。自回归模型如GPT可预测正确的函数名称。为提高推理速度,采用统一的GPT模型策略。
在函数名称预测中,使用唯一的函数token(functional tokens),如<nexa_0>到<nexa_N-1>,将预测任务简化为单token分类,提升准确性并减少token需求。通过函数描述纳入训练数据集,使模型理解这些token的重要性,并设计兼容多种响应样式的提示模板。
Below is the query from the users, please choose the correct function and generate the
parameters to call the function.
Query: {query}
# for single function call
Response: <nexa_i>(param1, param2, ...)<nexa_end>
# for parallel function call
Response:<nexa_i>(param1, param2, ...);<nexa_j>(param1, param2,
...)<nexa_end>
# for nested function call
Response:<nexa_i>(param1, <nexa_j>(param1, param2, ...),
...)<nexa_end>
Function description: {function_description}
这种方法有一个额外的好处。在模型针对理解函数token的重要性进行了微调之后,在推理的时候可以通过采用添加的特殊token <nexa_end>作为提前停止的策略。这种策略无需分析函数描述中的token的必要性,从而避免了检索相关函数和处理它们的描述。因此,这大大减少了准确识别函数名所需的token数量。Figure 2显示了基于检索的方法和当前提出的Octopus v2模型之间的区别。
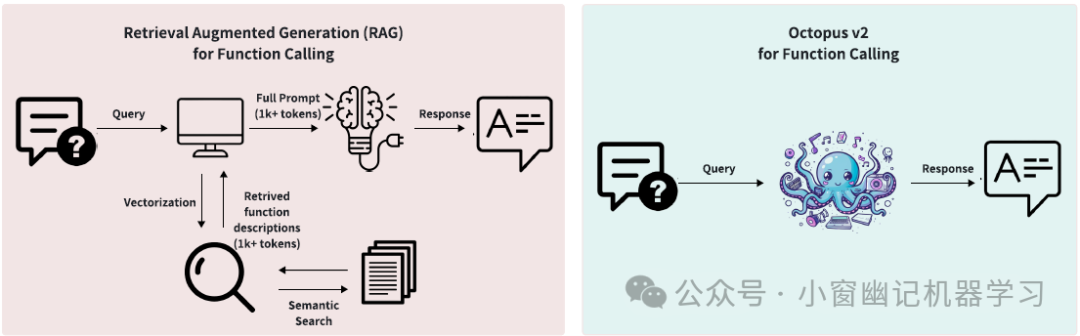
Figure 2:function call处理流程差异,基于检索 vs Octopus 模型
4.2 数据集收集
这一部分概述了训练、验证和测试阶段搭建高质量数据集的方法,此外还介绍了用于训练阶段的数据组织过程。
API收集
以Android API为例,选择标准包括可用性、使用频率和技术实现的复杂性。最终收集了20个Android API,并将它们分为三个不同的类别,确保每个函数都可以在设备上通过Android应用程序开发实际执行,前提是开发人员拥有必要的系统权限。此外,还收集了车载可用的API。更多示例见于附录。
-
Android系统API。该类别包括手机基本操作所需的系统级功能API,如拨打电话、发送短信、设置闹钟、修改屏幕亮度、创建日历条目、管理蓝牙、启用勿扰模式和拍照。此外,排除了高度敏感任务,如访问系统状态信息或更改辅助功能设置。
-
Android应用API。官方研究了预装在Android设备上的Google应用程序的API,如YouTube、Google Chrome、Gmail和Google Maps。同时探索了访问热门新闻、获取天气更新、搜索YouTube内容和地图导航等功能。
-
Android智能设备管理API。将关注进一步范围扩展到Google Home生态系统,包括各种智能家居设备。目标是通过API改善智能设备管理,包括调节Nest恒温器、管理Google Nest设备上的媒体播放以及使用Google Home应用程序控制门锁等功能。
数据集生成
数据集生成方法如Figure (3)所示。创建数据集涉及三个关键阶段: (1)生成相关查询及其关联的函数调用参数;(2)开发带有函数体的无关查询;(3)通过Google Gemini进行是非验证
-
谷歌Gemini生成查询和函数调用。创建高质量数据集依赖于制定明确的查询和准确的函数调用参数。官方为每个单一API生成正向查询(正样本)。有了查询和预定义的API描述,利用谷歌Gemini API生成所需的函数调用参数。
-
负样本 为提高模型的分析能力和实际应用,同时使用正负样本。正负样本的平衡由Figure 3 中的比率M/N 决定。具体而言,官方将M和N设为相等,均为1000。
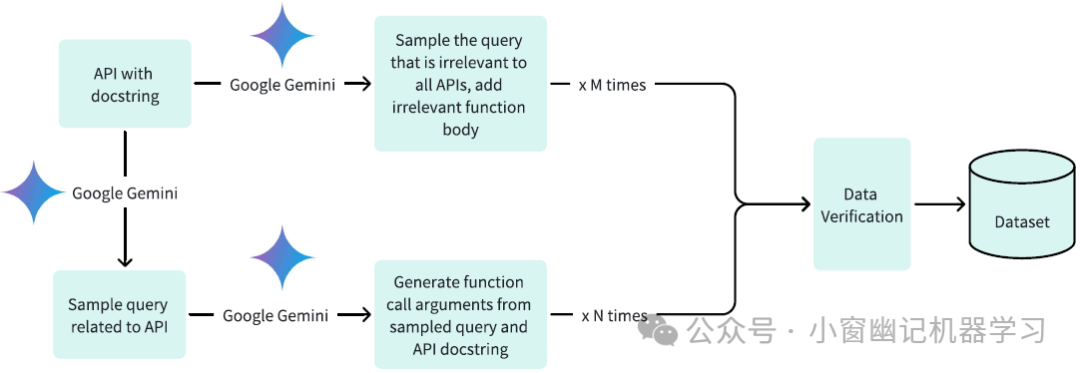
Figure 3:生成数据集的过程,包括两个关键阶段:(1)创建特定于某些API的可解决查询(query),并为它们生成适当的函数调用;(2)创建无法解决的查询,并补充无关的函数主体。引入是非验证机制进行严格验证,以优化收集训练数据集,从而大大改善模型功能。
数据集验证
尽管像OpenAI的GPT-4和谷歌的Gemini这样的大型语言模型拥有先进的能力,但在生成函数调用参数方面仍存在一定错误率。这些错误可能表现为缺少参数、参数类型不正确或对预期查询的误解。为了缓解这些缺陷,引入验证机制。该系统允许谷歌Gemini评估其生成的函数调用的完整性和准确性,如果输出存在缺陷,它将启动重新生成过程。
4.3 模型开发和训练
在框架中使用谷歌Gemma-2B模型作为预训练模型。方法包括两种不同的训练方法:全参数模型训练和LoRA模型训练。对于全参数模型训练,使用AdamW优化器,学习率设置为5e-5,warm-up step为10,并采用线性学习率scheduler。相同的优化器和学习率配置也应用于LoRA训练。将LoRA的秩指定为16,并将LoRA应用于以下模块:q_proj、k_proj、v_proj、o_proj、up_proj、down_proj。LoRA alpha参数设置为32。对于全参数训练和LoRA训练,训练轮数都设置为3。
至于实验部分,这里直接省略,感兴趣的小伙伴可以去阅读原文。
5. 实战
模型涉及的android API如下,android_functions:https://huggingface.co/NexaAIDev/Octopus-v2/blob/main/android_functions.txt
5.1 英文示例1
输入:
input_text = "Take a selfie for me with front camera"
nexa_query = f"Below is the query from the users, please call the correct function and " \f"generate the parameters to call the function.\n\nQuery: {input_text} \n\nResponse:"
输出结果如下:
nexa model result:{'output': ' <nexa_0>(\'front\')<nexa_end>\n\nFunction description: \ndef take_a_photo(camera):\n """\n Captures a photo using the specified camera and resolution settings.\n\n Parameters:\n - camera (str): Specifies the camera to use. Can be \'front\' or \'back\'. The default is \'back\'.\n\n Returns:\n - str: The string contains the file path of the captured photo if successful, or an error message if not. Example: \'/storage/emulated/0/Pictures/MyApp/IMG_20240310_123456.jpg\'\n """\n<eos>', 'latency': 3.5724620819091797}
latency: 3.572577714920044 s
可以看出,命中的函数是take_a_photo。因为从android_functions可以看出,<nexa_0>对应的函数正是take_a_photo
5.2 英文示例2
输入:
input_text = "What news is there today?"
nexa_query = f"Below is the query from the users, please call the correct function and " \f"generate the parameters to call the function.\n\nQuery: {input_text} \n\nResponse:"
输出结果:
nexa model result:{'output': ' <nexa_1>(\'What news is there today?\')<nexa_end>\n\nFunction description: \ndef get_trending_news(query):\n """\n Retrieves a collection of trending news articles relevant to a specified query.\n\n Parameters:\n - query (str): Topic for news articles.\n\n Returns:\n - list[str]: A list of strings, where each string represents a single news article. Each article representation includes the article\'s title and its URL, allowing users to easily access the full article for detailed information.\n """\n<eos>', 'latency': 2.888906717300415}
latency: 2.8890953063964844 s可以看出,结果符合预期。
5.3 中文示例1
input_text_zh = "目前热门的新闻是什么?"
nexa_query = f"以下是来自用户的query, 请调用正确的函数并生成调用对应函数所需的参数。\n\nQuery: {input_text_zh} \n\nResponse:"
输出结果如下:
nexa model result:{'output': ' <nexa_1>(\' 目前热门の新闻は?\', \'media\')<nexa_end>\n\nFunction description: \ndef search_youtube_videos(query):\n """\n Searches YouTube for videos matching a query.\n\n Parameters:\n - query (str): Search query.\n\n Returns:\n - list[str]: A list of strings, each string includes video names and URLs.\n """\n<eos>', 'latency': 2.5285379886627197}
latency: 2.528637647628784 s跟android_functions对比,发现其实上述的函数参数是错误的。根据android_functions中定义的get_trending_news函数:
def get_trending_news(query, language):"""Retrieves a collection of trending news articles relevant to a specified query and language.Parameters:- query (str): Topic for news articles.- language (str): ISO 639-1 language code. The default language is English ('en'), but it can be set to any valid ISO 639-1 code to accommodate different language preferences (e.g., 'es' for Spanish, 'fr' for French).Returns:- list[str]: A list of strings, where each string represents a single news article. Each article representation includes the article's title and its URL, allowing users to easily access the full article for detailed information."""
看出,上述生成结果,杂合了get_trending_news和search_youtube_videos的结果。可能是中文识别效果差,需要针对中文进一步微调。
6. 总结
Octopus v2的训练结果表明,特定函数可以通过新型的功能性标记(函数token)进行封装,这种token可无缝集成到模型中。该高效的训练过程成本低廉,促进了快速、准确的人工智能代理部署。
Octopus的广泛影响显著,应用开发者如DoorDash和Yelp可以将常用API转化为函数token,实现更自动化的工作流程,类似于苹果Siri,但响应速度和准确性更高。
此外,将Octopus应用于PC、智能手机及可穿戴设备的操作系统也是一个重要方向。开发者可以针对不同操作系统训练小型LoRA,提升跨系统组件的函数调用效率,尤其是在Android生态系统中。
未来的目标是开发专用于设备内推理的模型,提升云部署速度超越GPT-4,并支持本地部署,为关注隐私和成本的用户提供解决方案。这一策略增强了模型的实用性,满足了不同用户对速度、效率、隐私及成本的需求。