现有的大模型已经能够创作令人惊叹画作,那鉴赏艺术画作岂不是信手拈来?
但同济大学的研究团队却发现——并非如此。
他们发现这些大模型虽然对熟知的知名画作分析得头头是道,但一遇到较为冷门的画作就容易产生“视觉幻觉”,造成诸如张冠李戴的错误。
比如给大模型看梵高的《向日葵》,它能从画面布局、色彩搭配到笔触技巧等各个方面给出详尽的分析,相当准确:


然而,一换到那些不太出名的画作前,即便是像Gemini和GPT-4V这样强大的模型也会犯迷糊。(图中红色表示错误分析)

作者认为现有的大模型在分析画作时,往往倾向于首先识别给定的画作,然后相应地进行分析。简单来说,他们是先认出了这副画,然后再从记忆中调取关于这幅画的知识。这仅限于照本宣科,还不是真正意义上的具备鉴赏能力。
这种“识别再分析”的过程高度依赖于识别的准确性,一旦遇到不认识的画作,就容易出错,产生“视觉上的错觉”。
而作者更希望赋予大模型formal analysis(形式分析) 的能力,主要关注作品的形式元素,如线条、色彩、构图等,以及它们在作品中的组合和表现方式。
因此作者首先构建一个包含近19K画作和50K形式分析的大型数据集 “PaintingForm”,并进一步微调一个优越的多模态大模型——GalleryGPT,这个新模型不再只是简单地识别画作名称后复述知识,而是能够深入解析画作的视觉元素,大大提升了其艺术鉴赏能力。
论文标题:
GalleryGPT: Analyzing Paintings with Large Multimodal Models
论文链接:
https://arxiv.org/pdf/2408.00491
github链接:
https://github.com/steven640pixel/GalleryGPT

数据集构建
画源与数据过滤
本文在GPT-4 和Gemini等强大的LMM帮助下,使用1st Art Gallery中的著名画作作为来源,构建了一个名为PaintingForm的绘画数据集,包含绘画作品及每幅绘画的相关形式分析标注。整个流程如下图所示:

首先为了确保 LLMs 知道这些画作,询问模型是否知道该画作的标题和艺术家姓名并过滤掉一些没有特定标题的画作,最终获得 18,526 幅画作。其中选择了5000 幅知名度不高的画作进行测试,并保留 13,526 幅用于训练。画作与艺术家的分布如下图所示:
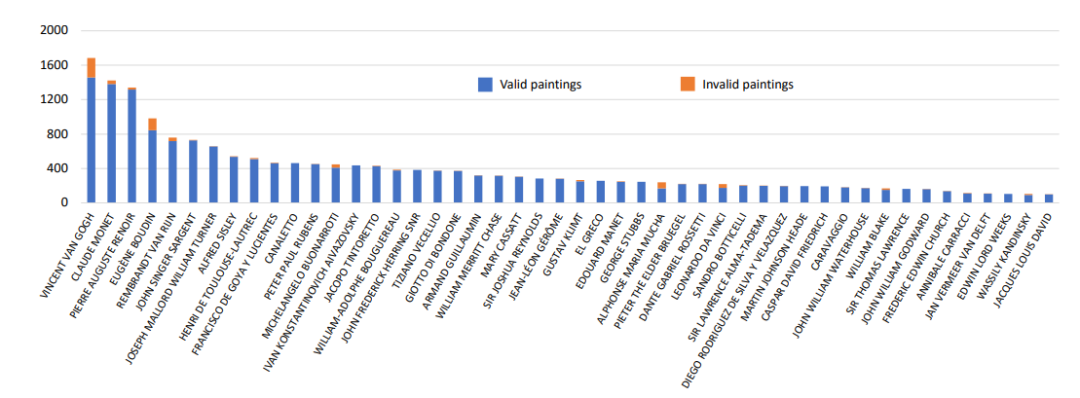
在数据集中梵高的画作是最多的,高达1458副。
形式分析数据标注
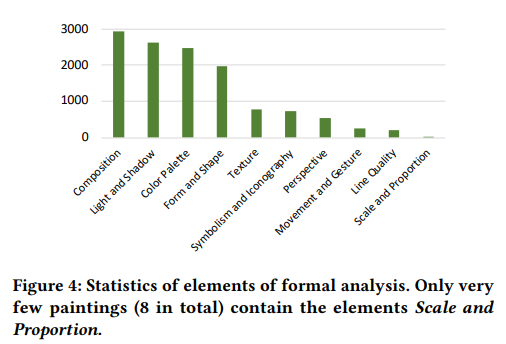
在使用LLMs标注时,仅向LLMs提供画作的标题和艺术家姓名,而不输入任何视觉信息。要求LLMs检索与特定画作的标题和艺术家姓名相关的学习知识,并生成一段仅关注视觉特征的分析,包括:1)整体正式分析,以及2)从特定角度的正式分析,例如颜色、构图和形式,下图展示了LLMs提供的主要分析角度。在生成的分析过程中要求LLM不提及标题和艺术家姓名。
艺术鉴赏模型GalleryGPT
随后,作者基于ShareGPT4V-7B在构建的PaintingForm数据集基础上进行监督微调,以使LLMs能够分析绘画,重点关注视觉元素。并与现有流行且强大的开源LMM进行比较。在实验过程中都使用相同的提示:“请撰写一段连贯的形式分析,重点关注视觉特征。”实验结果如下表所示:
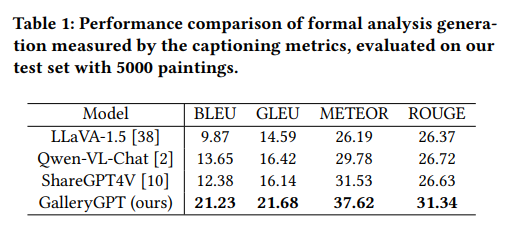
GalleryGPT在各项指标中显著超越了其他模型,这证明PaintingForm数据集的有效性。
推广到其他艺术分析任务
为了GalleryGPT 的泛化能力,作者还在几个现有数据集上进行视觉问答和绘画风格分类评估:
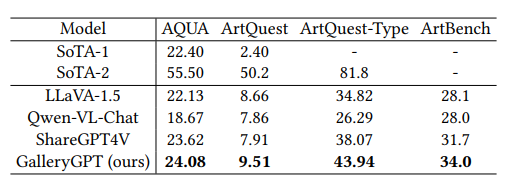
GalleryGPT显著优于所有基线LMM,并展现出强大的下游艺术分析任务泛化能力。另外,将GalleryGPT与近期的SOTA相比,SoTA-1表示未使用预训练语言模型(PLM)的模型,如BERT;SoTA-2表示利用PLM特征或基于PLM进行微调的模型。
可以看到当前LMM在AQUA上的表现接近SoTA-1模型,但均远不及利用PLM的SoTA-2模型,表明LMM在艺术分析上的泛化能力仍有待提升。作者认为,艺术鉴赏中的高级抽象概念需要更精细的感知,这将是未来研究的重要方向。
多模态模型基准测试
由于GalleryGPT是基于ShareGPT4V-7B实现的,它本质上仍然是一个LMM。因此,作者还在几个LLM基准上进行实验,并将其与基线LLM进行比较以评估其多模态理解能力。
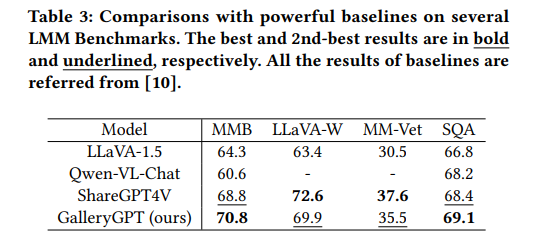
从结果上来看,GalleryGPT在性能上与ShareGPT4V相当。也就是说,经过精心收集的绘画分析数据微调后的GalleryGPT不仅在绘画分析性能上取得了更好的表现,包括形式分析生成和其他下游任务,而且还保留了其优越的多模态理解能力。
样例展示
作者展示了GalleryGPT与其他LMM(LLaVA-1.5、ShareGPT4V-7B、GPT-4V)在面对不知名的画作进行鉴赏时的输出,如下图:

LLaVA侧重描述事实,缺乏艺术批评视角;ShareGPT4V-7B同样注重内容描述,虽有艺术分析能力但有限;GPT-4V在形式分析上表现出色,但忽略微妙艺术元素。相比之下,GalleryGPT不仅简述画作内容,还深入分析色彩、光影、深度等艺术元素,全面展现艺术品分析能力,验证其优越性。
作者还评估了GalleryGPT的对话能力,下图显示它能准确理解用户意图并提供精炼分析。此外,即便未进行多语种监督训练,GalleryGPT也能用中文生成高质量回答,展现其多语种潜力

结语
本文提出了一个精心构建的从视觉特征方面赏析画作的数据集PaintingForm,显著提高了LLMs进行形式分析的能力。随着大模型的艺术鉴赏能力的提升,希望未来可以帮助更多人欣赏或学习欣赏艺术作品。
