目录
分组数据回归
分组数据回归
并非所有数据点都是一样的。 如果我们再次查看我们的 ENEM 数据集,相比小规模学校的分数,我们更相信规模较大的学校的分数。 这并不是说大型学校更好或什么, 而只是因为它们的较大规模意味着更小的方差。
import warnings
warnings.filterwarnings('ignore')import pandas as pd
import numpy as np
from scipy import stats
from matplotlib import style
import seaborn as sns
from matplotlib import pyplot as plt
import statsmodels.formula.api as smfstyle.use("fivethirtyeight")np.random.seed(876)
enem = pd.read_csv("./data/enem_scores.csv").sample(200)
plt.figure(figsize=(8,4))
sns.scatterplot(y="avg_score", x="number_of_students", data=enem)
sns.scatterplot(y="avg_score", x="number_of_students", s=100, label="Trustworthy",data=enem.query(f"number_of_students=={enem.number_of_students.max()}"))
sns.scatterplot(y="avg_score", x="number_of_students", s=100, label="Not so Much",data=enem.query(f"avg_score=={enem.avg_score.max()}"))
plt.title("ENEM Score by Number of Students in the School");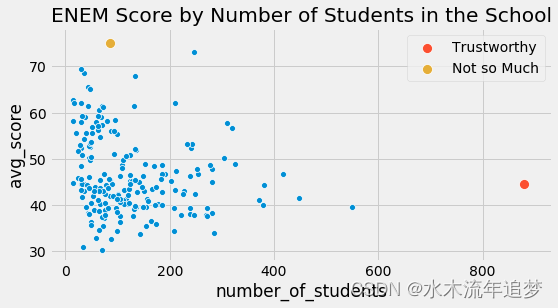
在上面的数据中,直观上,左边的点对我的模型的影响应该比右边的点小。本质上,右边的点实际上是许多其他数据点组合成一个。如果我们可以拆分它们并对未分组的数据进行线性回归,那么它们对模型估计的贡献确实比左侧的未捆绑点要大得多。
这种同时具有一个低方差区域和另一个高方差区域的现象称为异方差。简而言之,异方差是指因变量的方差在各个特征变量的值域内方差不是恒定的。在上面的例子中,我们可以看到因变量方差随着特征样本大小的增加而减少。再举一个我们有异方差的例子,如果你按年龄绘制工资,你会发现老年人的工资差异大于年轻人的工资差异。但是,到目前为止,方差不同的最常见原因是分组数据。
像上面这样的分组数据在数据分析中非常常见。原因之一是保密。政府和公司不能泄露个人数据,因为这会违反他们必须遵守的数据隐私要求。如果他们需要将数据导出给外部研究人员,他们只能通过对数据进行分组的方式来完成。这样,个人集合在一起,不再是唯一可识别的。
对我们来说幸运的是,回归可以很好地处理这些类型的数据。要了解如何做,让我们首先采用一些未分组的数据,例如我们在工资和教育方面的数据。在这些数据集中,每个工人对应一行数据,所以我们知道这个数据集中每个人的工资以及他或她有多少年的教育。
wage = pd.read_csv("./data/wage.csv")[["wage", "lhwage", "educ", "IQ"]]wage.head()
如果我们运行一个回归模型来找出教育与对数小时工资的关系,我们会得到以下结果。
model_1 = smf.ols('lhwage ~ educ', data=wage).fit()
model_1.summary().tables[1]
现在,让我们暂时假设这些数据有某种保密限制, 它的提供者无法提供个性化数据。 因此,我们请他将每个人按受教育年限分组,并只给我们平均对数小时工资和每个组中的人数。 这让我们只剩下 10 个数据点。
group_wage = (wage.assign(count=1).groupby("educ").agg({"lhwage":"mean", "count":"count"}).reset_index())group_wage
不要怕! 回归不需要大数据就可以工作! 我们可以做的是为我们的线性回归模型提供权重。 这样,相对样本量稍小的群体,模型会更多地考虑样本量更大的群体。 请注意我是如何用 smf.wls 替换 smf.ols 的,以获得加权最小二乘法。 新方法会让一切变得不同,虽然这点不容易被注意到。
model_2 = smf.wls('lhwage ~ educ', data=group_wage, weights=group_wage["count"]).fit()
model_2.summary().tables[1]
注意分组模型中 edu 的参数估计与未分组数据中的参数估计完全相同。 此外,即使只有 10 个数据点,我们也设法获得了具有统计意义的系数。 那是因为,虽然我们的点数较少,但分组也大大降低了方差。 还要注意参数估计的标准误差是变得大了一点,t 统计量也是如此。 那是因为丢失了一些关于方差的信息,所以我们必须更加保守。 一旦我们对数据进行分组,我们不知道每个组内的方差有多大。 将上面的结果与我们在下面的非加权模型中得到的结果进行比较。
model_3 = smf.ols('lhwage ~ educ', data=group_wage).fit()
model_3.summary().tables[1]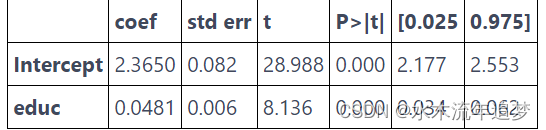
参数估计值相对较大。 这里发生的事情是回归对所有点施加了相等的权重。 如果我们沿着分组点绘制模型,我们会看到非加权模型对左下角小点的重视程度高于应有的重视程度。 因此,该模型的回归线具有更高的斜率。
sns.scatterplot(x="educ", y = "lhwage", size="count", legend=False, data=group_wage, sizes=(40, 400))
plt.plot(wage["educ"], model_2.predict(wage["educ"]), c="C1", label = "Weighted")
plt.plot(wage["educ"], model_3.predict(wage["educ"]), c="C2", label = "Non Weighted")
plt.xlabel("Years of Education")
plt.ylabel("Log Hourly Wage")
plt.legend();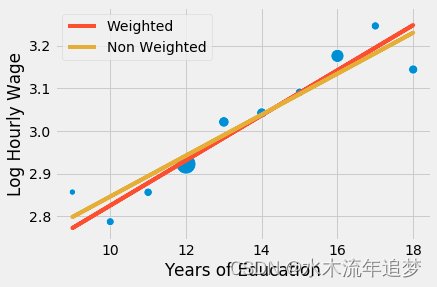
归根结底,回归就是这个奇妙的工具,可以处理单个数据或聚合数据,但在最后一种情况下您必须使用权重。 要使用加权回归,您需要平均统计量。 不是总和,不是标准差,不是中位数,而是平均值! 对于自变量和因变量都需要这么处理。 除了单一自变量回归的情况外,分组数据的加权回归结果与未分组数据的回归结果不会完全匹配,但会非常相似。
我将用在分组数据模型中使用附加自变量的最后一个例子来结束。
group_wage = (wage.assign(count=1).groupby("educ").agg({"lhwage":"mean", "IQ":"mean", "count":"count"}).reset_index())model_4 = smf.wls('lhwage ~ educ + IQ', data=group_wage, weights=group_wage["count"]).fit()
print("Number of observations:", model_4.nobs)
model_4.summary().tables[1]
Number of observations: 10.0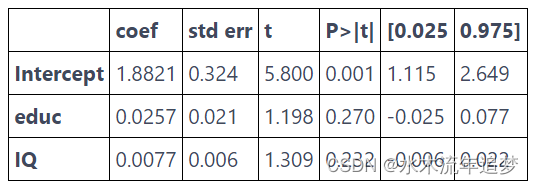
在此示例中,除了先前添加的教育年限之外,我们还包括 IQ 作为一个特征。运作机制几乎相同:获取均值并计数,回归均值并将计数用作权重。