观看B站软件工艺师杨旭的rust教程学习记录,有删减有补充
自动化测试
测试:验证非测试代码功能是否和预期一致
测试函数体(3A操作)
- 准备数据/状态(Arrange)
- 运行被测代码(Act)
- 断言结果(Asstert)
- 在函数上加
#[test]即可将函数变为测试函数 cargo testRust会构建一个Runner可执行文件,自动运行标注了#[test]的测试函数
new一个名为hello的library项目
cargo new hello --lib
lib.rs内容
pub fn add(left: usize, right: usize) -> usize {left + right
}
#[cfg(test)]
mod tests {use super::*;#[test]fn it_works() {let result = add(2, 2);assert_eq!(result, 4);//判断两者是否相等}
}
- 每个测试运行在一个新线程
panic!宏会导致测试失败
Assert!宏
- 状态为true:测试通过
- 状态为false:调用panic!宏,测试失败
assert!:里面可以指定错误信息
assert_eq!: ==
assert_ne!: !=
断言失败自动打印两个参数的值
fn add_two(a: i32, b: i32) -> i32 {a + b
}#[cfg(test)]
mod tests {use super::*;#[test]fn it_adds_teo() {let result = add_two(2, 3);assert!(result.eq(&6), "不等于6!"); //断言结果不等于6,并指定错误信息assert_eq!(result, 5); // 断言结果等于 5,如果不等于则会导致程序出错assert_ne!(result, 0); // 断言结果不等于 0,如果等于则会导致程序出错}
}
- 使用
debug格式打印参数 - 要求实现了PartialEq和Debug Trait(所有基本类型和大部分标准库类型都已实现)
debug_assert!宏
仅debug模式下运行
debug_assert!:指定错误信息
debug_assert_eq!:==
debug_assert_ne!:!=
should_panic
- 函数panic:测试通过
- 函数没有panic:测试失败
#[cfg(test)]
mod tests {#[test]#[should_panic(expected = "index out of bounds")]//只有信息中包含指定信息的panic才会测试通过fn test_vector_index() {let v = vec![1, 2, 3];let _ = v[10];//超出索引,这个测试发生了panic所以测试通过}
}
Result<(),T>
不会发生panic,失败返回Err,不要添加#[should_panic]
#[cfg(test)]
mod tests {#[test]fn it_work() -> Result<(), String> {if 2 + 2 == 4 {Ok(())} else {Err(String::from("结果不相等"))}}
}
控制测试
默认行为
- 并行运行
- 所有测试
- 捕获所有输出
参数控制
- cargo test 参数
- –help:帮助信息
- – – help:可以跟在cargo test --后面的参数
- 如
cargo test --no-run:编译测试函数但不执行
- 可执行测试文件 参数
- 如
cargo test -- --show-output:显示成功测试的输出
- 如
并行运行测试
-
运行多个测试默认使用多线程测试
-
需要确保测试之间不会相互依赖
-
不依赖与共享状态(环境、工作目录、环境变量等)
-
使用
cargo test -- --test=threads=1指定线程数量
指定函数名测试
cargo test 函数名:仅执行指定的测试函数
- 如
cargo test add_two_two
cargo test 模块名:仅执行指定模块的测试
- 如
cargo test work
cargo test add:仅执行开头包含add的测试函数
cargo test -- --ignored:仅执行被忽略的测试函数,通过在测试函数上添加#[ignore]忽略测试函数(比较耗时的函数可以忽略单独执行)
pub fn add_two(a: i32) -> i32 {a + 2
}#[cfg(test)]//指定单元测试
mod work {use super::*;#[test]fn add_two_and_two() {assert_eq!(4, add_two(2), "2+2");}#[test]fn add_three_and_two() {assert_eq!(5, add_two(3), "3+2");}#[test]#[ignore = "reason"]//指定忽略原因fn one_hundred() {assert_eq!(102, add_two(100), "102+100");}
}
测试分类(仅libary crate,binary crate也就是main.rs可独立运行不测试)
-
单元测试:
#[cfg(test)]标注- 一次对一个模块进行隔离测试
- 可测试private函数(没有使用pub的函数默认是private的)
-
集成测试:创建
tests目录,tests目录下每个测试文件都是一个单独的crate- 在库外部测试
- 只能测试public函数
- 可以在测试中使用多个模块
tests文件夹下新建任意名字的测试文件use hello; #[test] fn it_adds_two() {assert_eq!(34,hello::add_two(32)); }
在tests目录下新建子目录common可以创建公共测试函数,通过use导入,但不会被集成测试
程序关注点分离指导性原则
- 将程序拆分为
main.rs和lib.rs将业务逻辑放入lib.rs - 纵向分离:界面层(
UI Layer),业务逻辑层(Business Layer)和数据持久化层(Data Access Layer) - 横向分离:将软件拆分成模块(
module)或子系统(crate),每个子系统都有明确定义的接口和职责 - 切面分离:像日志在多个层都需要,通过配置日志过滤器和输出格式来控制日志的行为
- 依赖分离:使用依赖注入(DI)或依赖倒置(DI)原则,将组件的依赖关系从具体实现中解耦。可以使用 Rust 的依赖注入框架(如
di)或手动实现依赖注入 - 关注数据分离:用数据结构和类型来表示和操作数据,确保数据的独立性和可重用性,如
struct、enum、泛型等 - 关注行为分离:使用 Rust 的特质(trait)来定义抽象行为和接口,然后为不同的类型实现这些特质,这样可以将行为从具体类型中分离出来,增加了代码的灵活性和可重用性
- 扩展分离:使用模块和
trait来支持可插拔的扩展功能 - 委托分离:将某个对象的功能委托给其他对象来实现
- 反转分离:使用依赖反转原则(DIP)或控制反转(IOC)容器来实现
main.rs
use std::{env, process};
use minigrep::{run, Config};
fn main() {let args: Vec<String> = env::args().collect();println!("{:?}", args);let config = Config::new(&args).unwrap_or_else(|err| {println!("解析参数出错:{}", err);process::exit(1); //状态码推出});println!("查找:{}", config.query);println!("文件:{}", config.filename);if let Err(e) = run(config) {println!("程序出错!:{}", e);process::exit(1);}
}
lib.rs
use std::error::Error;
use std::fs;
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.filename)?;println!("{}", contents);Ok(())
}
pub struct Config {pub query: String,pub filename: String,
}
impl Config {pub fn new(args: &[String]) -> Result<Config, &'static str> {//错误处理if args.len() < 3 {return Err("参数不够!");}let query = &args[1].clone();let filename = &args[2].clone();Ok(Config {query: query.to_string(),filename: filename.to_string(),})}
}
test.txt
Rust:
hello world
so easy
TDD(Test-Driven Development)
TDD:开发功能代码之前,先编写单元测试用例代码
TDD包含以下三个方面,一般指的是UTDD
UTDD(Unit Test Driven Development,单元测试驱动开发)
ATDD(Acceptance Test Driven Development,验收测试驱动开发)
BDD(Behavior Driven Development,行为驱动测试开发)
TDD周期
测试先行->迭代开发->持续重构
- 写一个会失败的测试,运行测试确保它按照预期的原因失败(
Test Fails红) - 编写或修改刚好足够的代码,让测试通过(
Test Passes绿) - 重构优化设计,确保测试始终通过(
Refactor重构),重复该过程
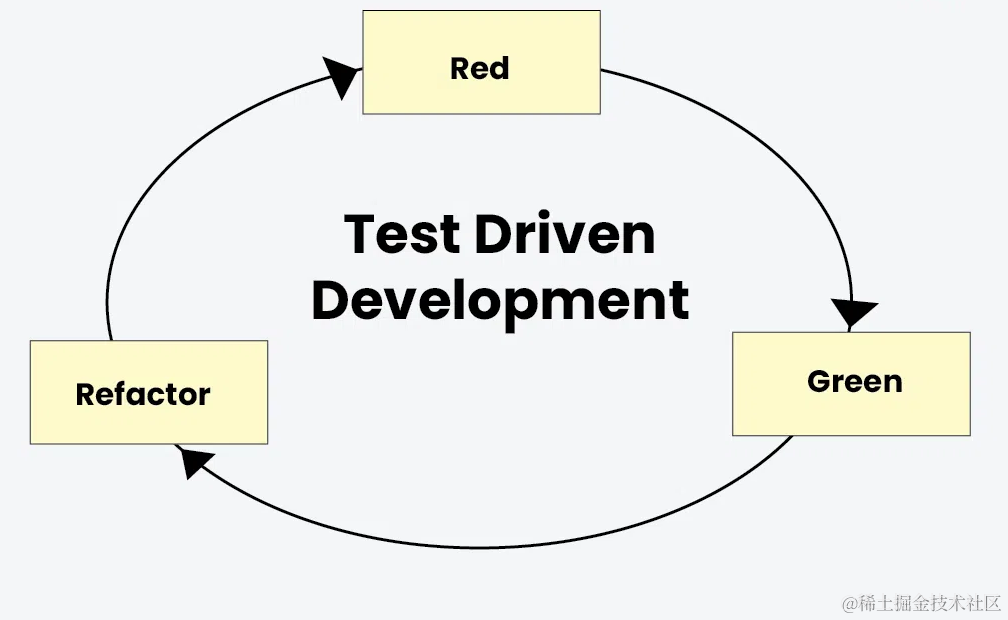
TDD原则
- 除非是为了一个失败的用例通过,否则不允许编写任何代码
- 在一个单元测试中,只允许编写刚好能导致失败的内容
- 只允许编写刚好能够使一个失败用例通过的代码
1、先写一个测试
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {//为了让一个失败的用例通过vec![]
}
//TDD
#[cfg(test)]
mod tests {use super::*;#[test]fn one_result() {let query = "hello";let contents = "
Rust
hello world";assert_eq!(vec!["hello world"], search(query, contents))}
}
执行cargo test出现FAILED(红)
2、编写或修改刚好通过测试的代码
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {//为了让一个失败的用例通过let mut results = Vec::new();for line in contents.lines() {//将每一行遍历if line.contains(query) {results.push(line); //包含查询结果则存入results}}results
}
执行cargo test出现ok(绿)
3、重构优化设计,确保测试始终通过(修改lib.rs中的run方法)
use std::error::Error;
use std::fs;
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.filename)?;for line in search(&config.query, &contents) {//重构方法println!("{}", line);}Ok(())
}
pub struct Config {pub query: String,pub filename: String,
}
impl Config {pub fn new(args: &[String]) -> Result<Config, &'static str> {//错误处理if args.len() < 3 {return Err("参数不够!");}let query = &args[1].clone();let filename = &args[2].clone();Ok(Config {query: query.to_string(),filename: filename.to_string(),})}
}
执行cargo run hello test.txt确保测试通过
closures 闭包
可以捕获其所在环境的匿名函数
fn apply_operation<F>(a: i32, b: i32, operation: F) -> i32
whereF: Fn(i32, i32) -> i32,
{operation(a, b)
}
fn main() {let add = |a, b| a + b;let result = apply_operation(2, 3, add); //将闭包函数作为参数使用println!("Result: {}", result); //Result: 5
}
闭包获得函数的三种方式
- 取得所有权:
FnOnce - 可变借用:
FnMut - 不可变借用:
Fn
FnOnce 取得所有权(move)
fn main() {let name = String::from("Alice");let greet = move || {println!("Hello, {}", name);};greet();// 下面这行代码将无法编译,因为闭包已经获取了 `name` 的所有权// println!("Name: {}", name);
}
FnMut 可变借用
fn main() {let mut count = 0;let mut increment = || {count += 1;println!("Count: {}", count);};increment();increment();
}
Fn 不可变借用
fn main() {let name = "Bob";let greet = || {println!("Hello, {}", name);};greet();greet();
}
iterators 迭代器
检查容器内元素并遍历元素
Rust的迭代器是惰性的,只有调用时才能显示
fn main() {let v = vec![1, 2, 3, 4];let v = v.iter();for val in v {println!("迭代数据:{}", val);}
}
其他用法
fn main() {let shoe_sizes = vec![8, 9, 10, 9, 8, 7, 8, 9];// 使用迭代器的 next 方法遍历元素let mut sizes_iterator = shoe_sizes.iter();while let Some(size) = sizes_iterator.next() {println!("size: {}", size);}// 使用迭代器的消费方法进行求和let sum: i32 = shoe_sizes.iter().sum();println!("求和sizes: {}", sum);//求和sizes: 68// 使用迭代器适配器进行筛选,filter返回true则将元素包含在filter产生的迭代器中let small_sizes: Vec<&i32> = shoe_sizes.iter().filter(|&size| size < &8).collect();println!("最小的sizes: {:?}", small_sizes);//最小的sizes: [7]// 使用捕获 shoe_size 的闭包进行筛选let shoe_size = 9;let matching_sizes: Vec<&i32> = shoe_sizes.iter().filter(|&size| size == &shoe_size).collect();println!("匹配的sizes: {:?}", matching_sizes);//匹配的sizes: [9, 9, 9]
}
零成本抽象
不用的东西,你不需要为之付出代价,用到的东西,你也不可能做得更好
能带来感官上高层次的抽象又不会带来运行时的性能损失
fn main() {let numbers = vec![1, 2, 3, 4, 5];// 使用闭包迭代器计算所有奇数的平方和let odd_square_sum: i32 = numbers.iter().filter(|&num| num % 2 != 0).map(|&num| num * num).sum();println!("Sum of squares of odd numbers: {}", odd_square_sum);
}文档注释
用于生成文档
- 生成HTML文档
- 显式公共API的文档注释
- 支持Markdown
执行命令cargo doc生成文档,找到生成的地址打开,在target/doc下
/// 使用闭包迭代器计算所有奇数的平方和
///示例章节
/// # Example
/// ```rust
/// fn main(){
/// println!("支持md语法");
/// }
/// ```
fn main() {let numbers = vec![1, 2, 3, 4, 5];let odd_square_sum: i32 = numbers.iter().filter(|&num| num % 2 != 0).map(|&num| num * num).sum();println!("Sum of squares of odd numbers: {}", odd_square_sum);
}
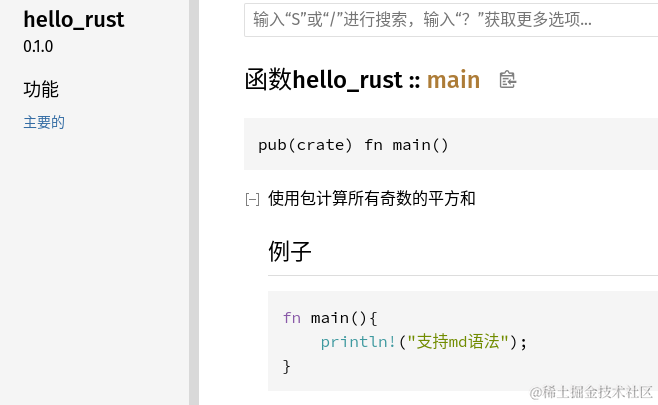
其他章节
- Panics
- Errors
发布库
在Cargo.toml添加元数据
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2021"
description = "A fun game where you guess what number the computer has chosen."
license = "MIT OR Apache-2.0"
1、官网注册账号、添加邮件并创建API token
2、执行cargo login token
3、执行cargo publish发布
发布是 永久性的,对应版本不可能被覆盖,其代码也不可能被删除
cargo yank --vers 1.0.1可以撤回某个版本
cargo yank --vers 1.0.1 --undo回退撤回操作
工作空间
共享同一个的 Cargo.lock 和输出目录的包
1、新建一个目录
2、在这个目录里新建``Cargo.toml`配置子项目
3、cargo new projectname创建项目,也会自动添加[workspace]配置
4、指定运行某个crate,执行cargo run -p add_two,-p是``–package,也可以cargo test -p add_one指定运行某个crate`的测试函数
5、如果要依赖同级项目的函数,在需要依赖的项目Cargo.toml添加
[dependencies]
add_one = { path = "../add_one" }
然后use add_one;导入
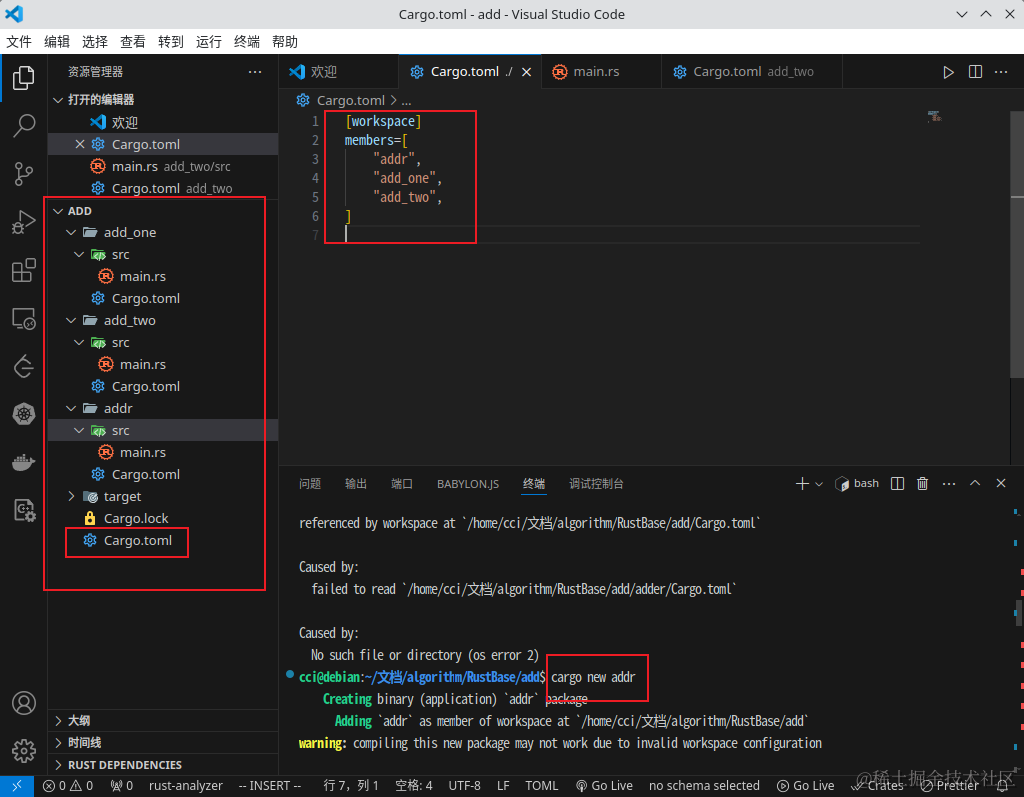
在worksapce里添加的依赖是公共依赖,相当于父子项目?(干过为服务的应该知道)
cargo install:安装可执行文件,可以把别人写好的工具下载下来运行使用(需要在环境变量里);和添加依赖库不一样,库只能调用里面的方法使用,如cargo tree -p 就是执行官方写的用于显示当前包目录结构的可执行文件