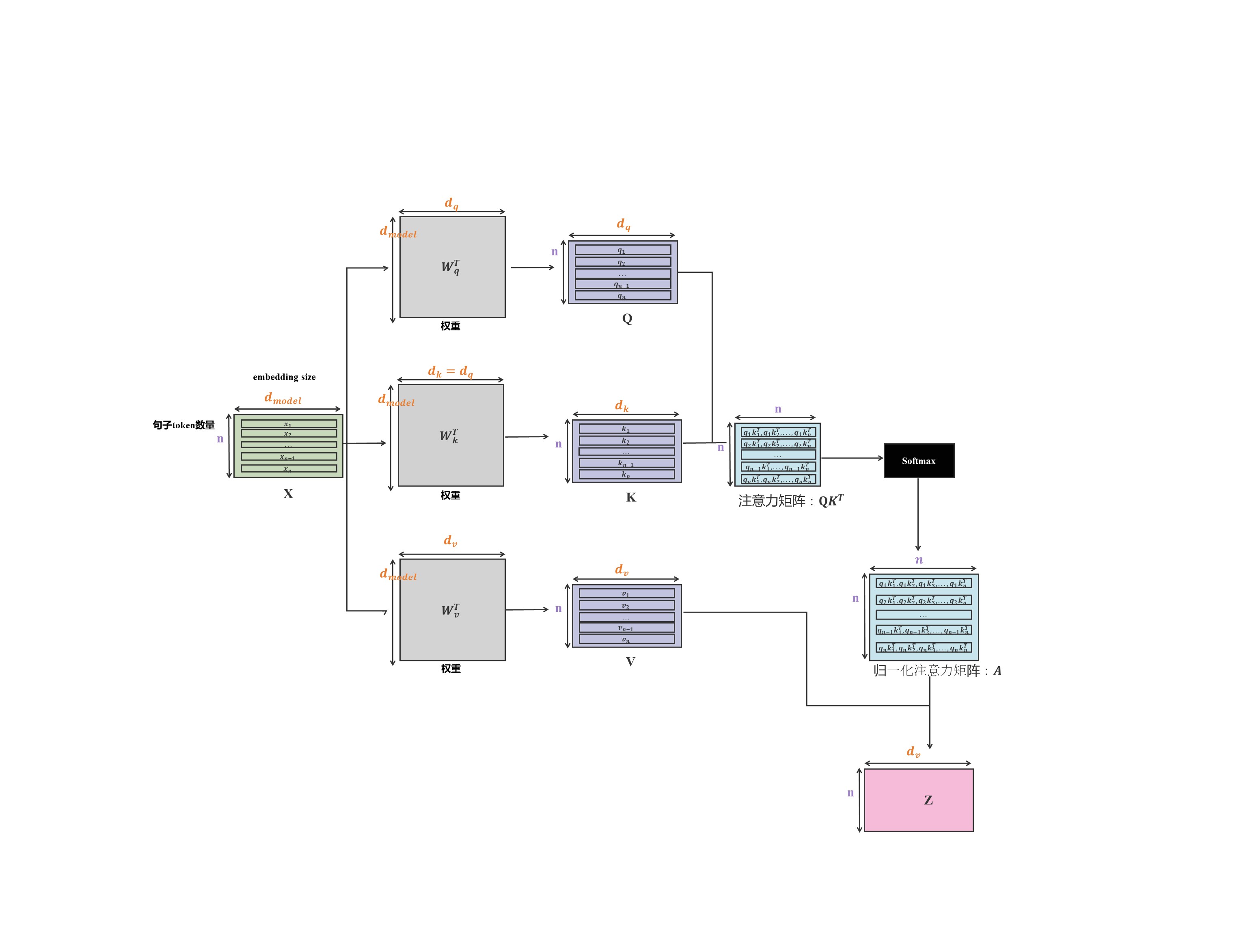
大家都知道大模型是通过语言序列预测下一个词的概率。假定{ x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3,…, x n − 1 x_{n-1} xn−1}为已知序列,其中 x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3,…, x n − 1 x_{n-1} xn−1均为维度是 d m o d e l d_{model} dmodel的向量, q n q_{n} qn、 k n k_{n} kn、 v n v_{n} vn同为向量。当输入 x n x_n xn时,需要预测 x n + 1 x_{n+1} xn+1的概率分布。
KV Cache干了什么?
Attention机制的目标是输入 x n x_n xn,输出 z n z_n zn。在具体实现过程中,输入 x n x_n xn,生成 q n q_n qn、 k n k_n kn和 v n v_n vn,并在实际计算中不再需要重复计算 k 1 k_1 k1, k 2 k_2 k2,…, k n − 1 k_{n-1} kn−1和 v 1 v_1 v1, v 2 v_2 v2,…, v n − 1 v_{n-1} vn−1,直接从缓存中取即可。
具体Attention机制计算流程如下图所示。
观察注意力矩阵最下面一行(放大图我放下面了)。新输入的 x n x_n xn通过矩阵 W q W_q Wq生成 q n q_n qn,其中 q n q_n qn与 k 1 k_1 k1, k 2 k_2 k2,…, k n k_n kn均有运算关系。所以可以通过缓存 k 1 k_1 k1, k 2 k_2 k2,…, k n − 1 k_{n-1} kn−1向量加速推理。这是K矩阵需要缓存的原因。
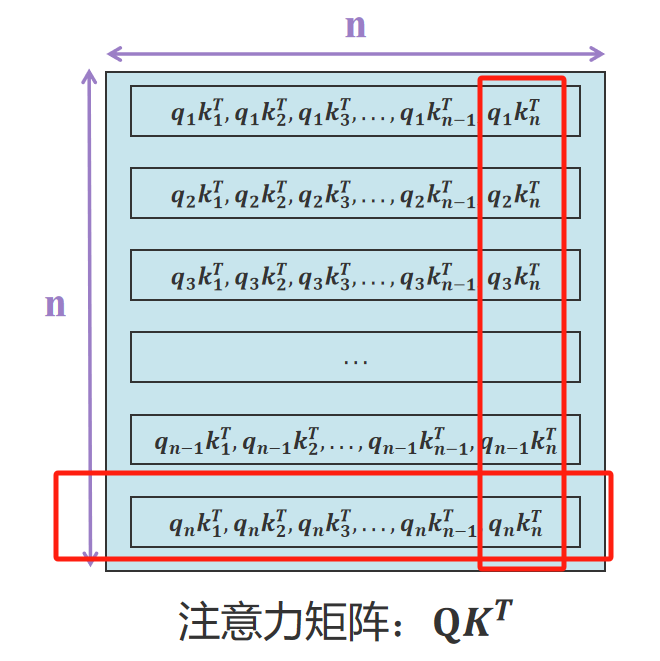
不过很意外的发现最右边一列 q 1 q_1 q1, q 2 q_2 q2,…, q n − 1 q_{n-1} qn−1与 k n k_{n} kn之间存在计算。
不是说好的只有KV缓存,没有Q矩阵缓存?如果推导成立,新输入 x n x_{n} xn是否会改变 x 1 x_1 x1, x 2 x_2 x2,…, x n − 1 x_{n-1} xn−1的注意力分布?
推导没有错,也没有Q矩阵缓存。因为在推理阶段,Attention机制有一个非常重要的细节:mask掩码
注意力矩阵在训练推理过程中,为了模拟真实推理场景,当前位置token是看不到下一位置的,且只能看到上一位置以及前面序列的信息,所以在训练推理的时候加了attention mask。具体实现如下图所示:
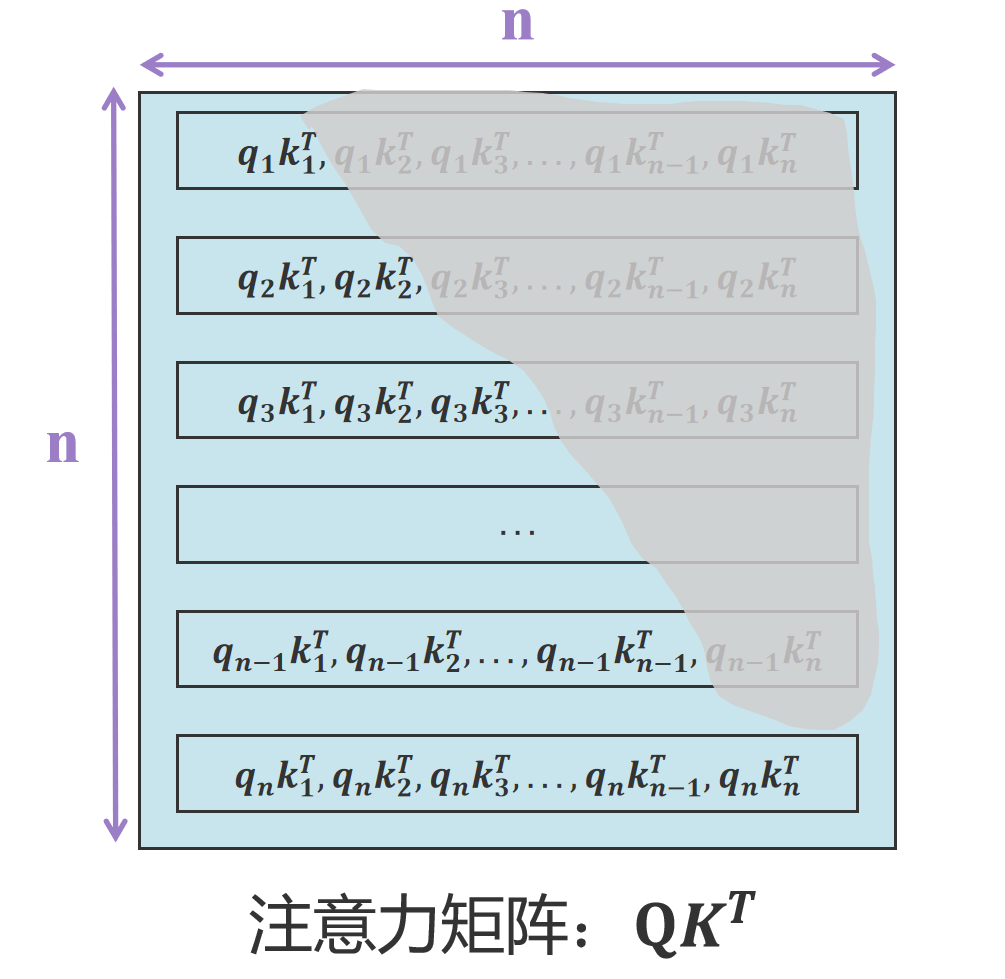
将上图灰色区域全部重置为-inf(负无穷大) ,这样方便softmax的时候置为0。当新输入 x n x_n xn,注意力的计算(见注意力矩阵最下面一行)与 q 1 q_1 q1, q 2 q_2 q2,…, q n − 1 q_{n-1} qn−1无关,因此无需缓存Q矩阵
另外,还有个V矩阵,参照图1就干了一件事。
z n = a 1 ∗ v 1 + a 2 ∗ v 2 + . . . + a n ∗ v n z_n = a1*v_1+a2*v_2+...+a_n*v_n zn=a1∗v1+a2∗v2+...+an∗vn
我可以提前缓存 v 1 v_1 v1, v 2 v_2 v2,…, v n − 1 v_{n-1} vn−1,计算的时候从缓存中取即可,这是V矩阵需要缓存的原因。