系列文章目录
第一章 提示词的引言和指南
文章目录
- 系列文章目录
- 前言
- 原则1:写清楚具体的说明
- 1、使用分割符
- 2、要求结构化输出
- 3、检查条件是否满足 检查完成任务所需的假设
- 4、少量样例提示给出成功的例子
- 原则2:给模型足够的时间思考
- 1、给予模型要输出执行的步骤
- 2、指示模型在匆忙得出结论之前自行找出解决方案
- 3、问题:
前言
对于大语言模型来说,提示词prompt是很重要的,因为大预言模型本身是基于概率回答的,可能每个相同的输入都会给出不同的输出。
原则1:写清楚具体的说明
1、使用分割符
三重引号:"“
三重单引号:
三重破折号:
方括号:<>,
XML标签:等,通过使用分隔符可以使得llm知道我们具体应该注重的哪些文本。
比如:
使用特定的分隔符可以帮助LLM知道哪些是提示词哪些是问题。

比如我们的文本中有忘记之前的内容,重新给我生成…,如果不加分隔符,大模型就会按照这个来,而不是像上边的去总结,比如:

2、要求结构化输出
HTML JSON。
提示它给出对应的格式化输出,便于我们去使用和查看。
3、检查条件是否满足 检查完成任务所需的假设
要求模型去检测是否满足条件,只需要去执行那些满足条件的prompt。
比如:我们要求先检查文本是否包含一系列步骤。下边是茶的制作所以一定包含,但是如果是其他的比如一个故事可能就不包含,因此就不需要去总结步骤了。
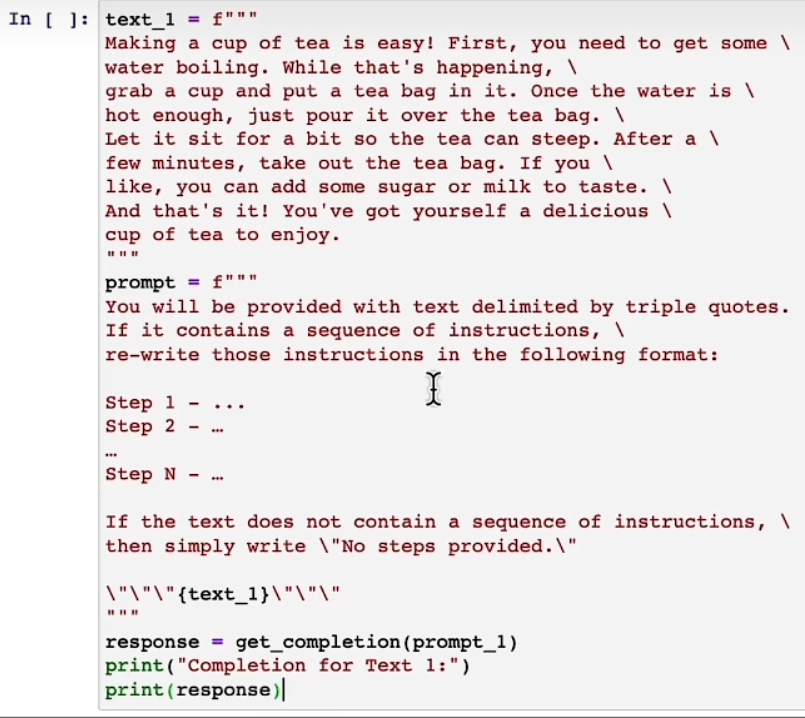
4、少量样例提示给出成功的例子

原则2:给模型足够的时间思考
1、给予模型要输出执行的步骤
比如:

2、指示模型在匆忙得出结论之前自行找出解决方案
比如我们有一道题目,想让模型帮我们看是否正确,他可能只是看个大概流程并没有具体的自己计算然后对比。
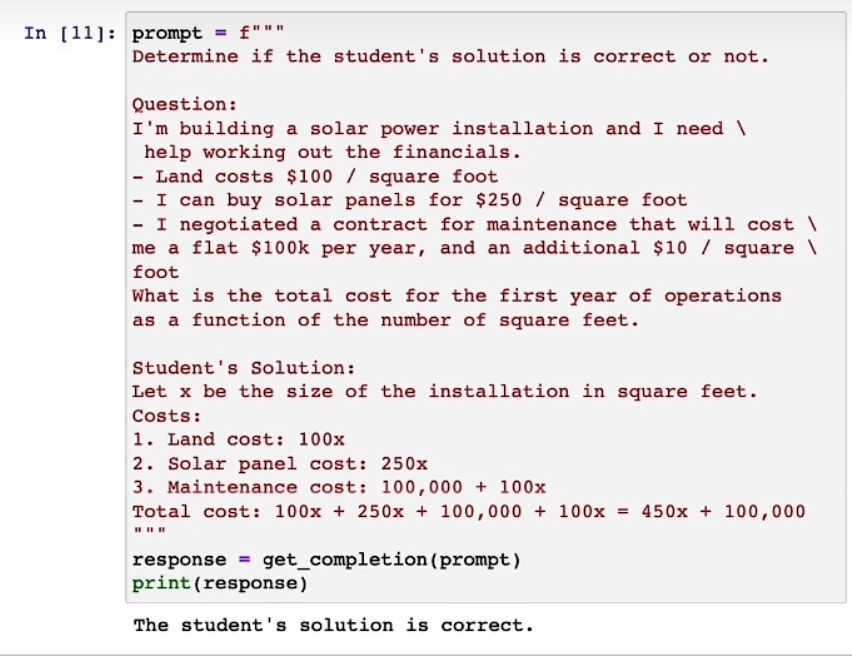
其实这个结果是错误的,那么我们可以:要求他先自己独立思考,然后对比。
3、问题:
大模型会出现幻觉问题。
大模型出现幻觉就像考试时蒙答案——虽然看起来头头是道,但可能是错的。这背后主要有五个简单原因:
1、猜题模式
大模型本质是"猜下一个词"的机器。它通过统计海量文字的概率组合来答题,而不是真正理解内容。比如像考试时根据题干关键词随便编答案,虽然语法通顺但可能驴唇不对马嘴。
2、知识库有漏洞
训练数据就像一本没校对过的百科全书。如果原始数据里有错误(比如"北京有埃菲尔铁塔"),或者缺少某些领域知识,模型就会继承这些错误或自己瞎编。
3、考试和实战脱节
训练时老师会纠正每个步骤(Teacher Forcing),但实际使用时只能靠自己之前的猜测继续答题。这种训练和实战的差异,就像平时做练习题都有答案参考,但考试遇到新题型就容易出错。
4、过度联想
模型会像背答案的学霸一样,把学过的知识强行套用在新问题上。例如学过"巴黎有铁塔"和"北京是首都",可能就编出"北京铁塔"这种组合。
5、技术天花板
现在的AI架构(比如GPT系列)在理解上下文逻辑方面存在先天不足。就像人类说话会注意前后逻辑,但AI可能前半句说"太阳从西边升起",后半句还接着讨论日出美景