目录
一、什么是阻塞队列?特点是什么?
二、阻塞队列的两种创建方式:
1、使用 ArrayBlockingQueue<>( ) :
2、使用 LinkedBlockingQueue<>( ) :
三、阻塞队列方法的使用:
阻塞队列关键的两个方法:
使用实例:
四、阻塞队列的使用场景:
1、公司服务器
2.生产者消费者模型:
生产速度与消费速度一样:
生产速度比消费速度慢:
生产速度比消费速度快:
五、模拟实现生产者消费者模型:
实现代码:
一、什么是阻塞队列?特点是什么?
在JAVA里,阻塞队列是一种特殊的队列,阻塞队列在普通队列的基础上,增加了阻塞的特性,也就是说:
当队列满时,尝试向队列中插入元素的线程会被阻塞,直到队列有空间可用;当队列空时,尝试从队列中获取元素的线程会被阻塞,直到队列中有元素可用。
阻塞队列 是 java.util.concurrent 包下的,使用时需要导包:
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;并且,阻塞队列是线程安全的。
二、阻塞队列的两种创建方式:
1、使用 ArrayBlockingQueue<>( ) :
// 创建一个容量为 10 的 ArrayBlockingQueue
BlockingQueue<Integer> arrayQueue = new ArrayBlockingQueue<>(10);这种方法基于 数组 实现,创建 ArrayBlockingQueue<>( ) 时,需要指定阻塞队列的容量,这意味着它的底层数组容量大小是固定的,后续无法动态改变。
2、使用 LinkedBlockingQueue<>( ) :
// 创建一个有界的 LinkedBlockingQueue,容量为 20
BlockingQueue<Integer> boundedLinkedQueue = new LinkedBlockingQueue<>(20);// 创建一个无界的 LinkedBlockingQueue
BlockingQueue<Integer> unboundedLinkedQueue = new LinkedBlockingQueue<>();这些方法基于 链表 实现,第一种创建有界队列(上面的指定容量为 20,当队列满了之后再尝试放入元素,队列不会进行扩容);
也可以创建无界队列(默认情况下,其最大容量为 Integer.MAX_VALUE)。
所以,无界的LinkedBlockingQueue是不是可以无限放置元素?
从理论上来说,无界的 LinkedBlockingQueue 可以不断地放置元素,因为它的默认最大容量为Integer.MAX_VALUE,这是一个非常大的数,在实际应用中通常可以认为是无界的。
然而,在实际情况中,它并不能真正无限地放置元素。这是因为虽然队列本身没有严格的容量限制,但服务器的内存是有限的。随着元素不断添加,LinkedBlockingQueue 会不断占用内存空间,当内存被耗尽时,系统会抛出异常。
三、阻塞队列方法的使用:
阻塞队列关键的两个方法:
//往队列放元素,队列满时会阻塞,直到有空位
put();//把队列元素取出,队列为空时会阻塞,直到队列不为空
take();put 方法用于阻塞式的入队列,take 用于阻塞式的出队列。
BlockingQueue 也有 offer, poll, peek 等方法, 但是这些方法不带有阻塞特性。
使用实例:
public class Demo14 {public static void main(String[] args) throws InterruptedException {BlockingQueue<String> queue = new ArrayBlockingQueue<>(100);// 入队列queue.put("aaa");System.out.println("添加一个元素");queue.put("bbb");System.out.println("添加一个元素");//出队列String s = queue.take();System.out.println("获取到一个元素: " + s);s = queue.take();System.out.println("获取到一个元素: " + s);s = queue.take();System.out.println("获取到一个元素: " + s);}
}
可以看到,第三次调用 queue.take() 方法时会发生阻塞。因为此时队列中已经没有元素了。take 方法的特性是,如果队列为空,它会阻塞当前线程,直到队列中有元素可供取出。所以,此时线程会被阻塞,程序会停在这里等待新元素被添加到队列中。
四、阻塞队列的使用场景:
1、公司服务器
有个公司,接收客户端的消息请求,公司机房的几台服务器用于处理这些消息:
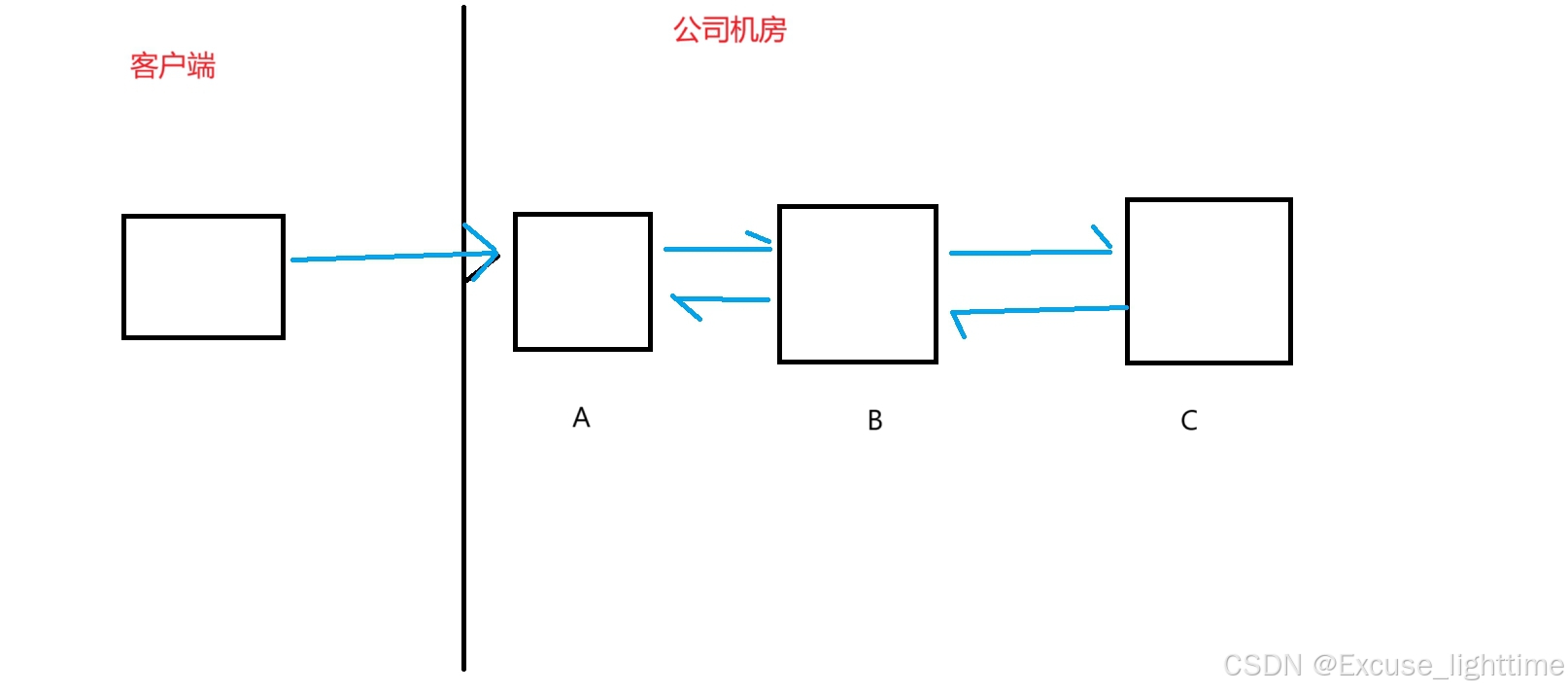
此时,A B C 之间是直接调用关系,耦合度比较大。耦合度大可以体现在:
1. 如果 C 这个模块修改了,B 可能也要配合修改。
3. 如果公司机房要增加一个 D(如下图) ,那么针对 B 也需要进行修改。
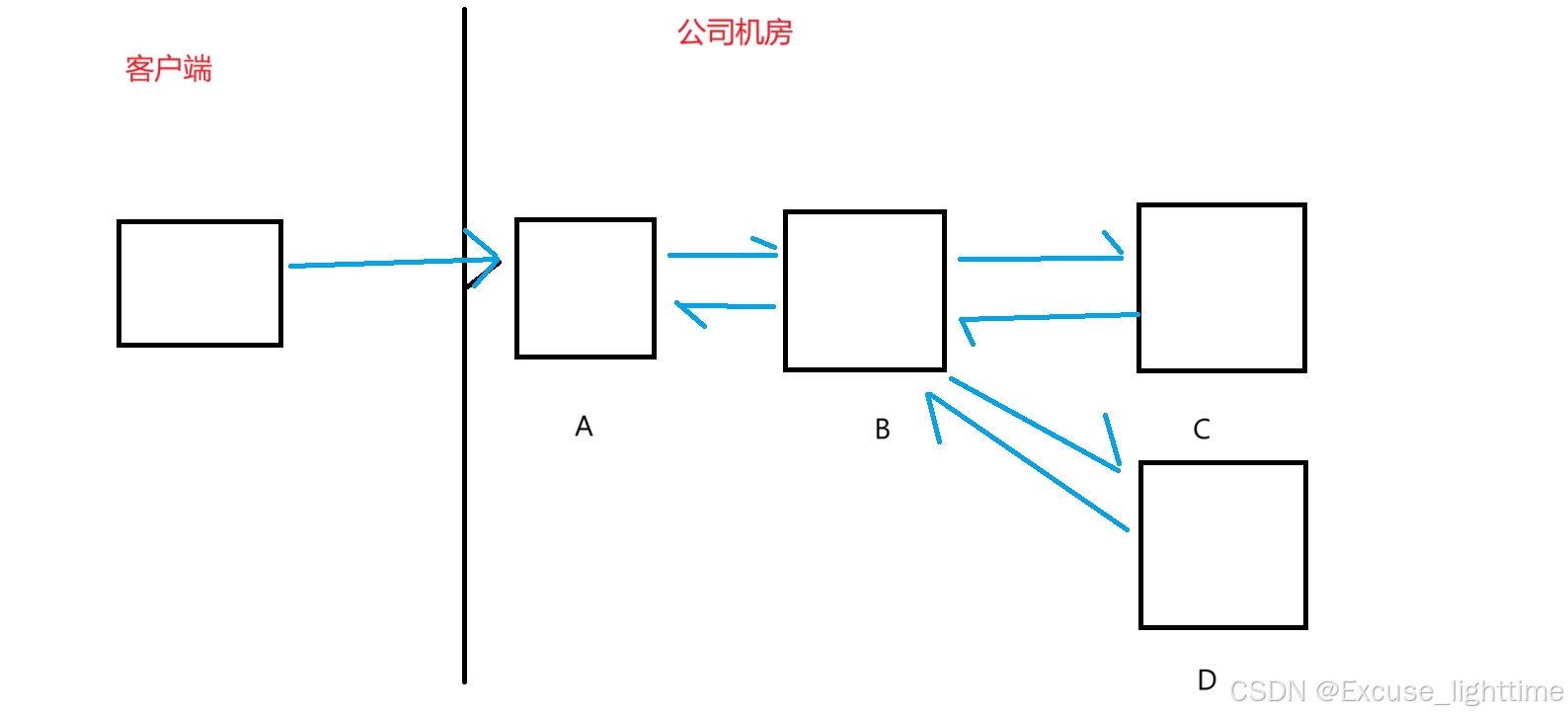
还有一个问题,就是如果 客户端发送的请求 很多,A 服务器收到多大的压力 ,此时 服务器 B C D 收到的压力是相同的,如果 一旦某个服务器顶不住了,那么这公司机房的 这个系统就崩溃了。因为各个服务器的耦合度太高了。
那么,有什么方法可以解决这些问题?
可以这样:
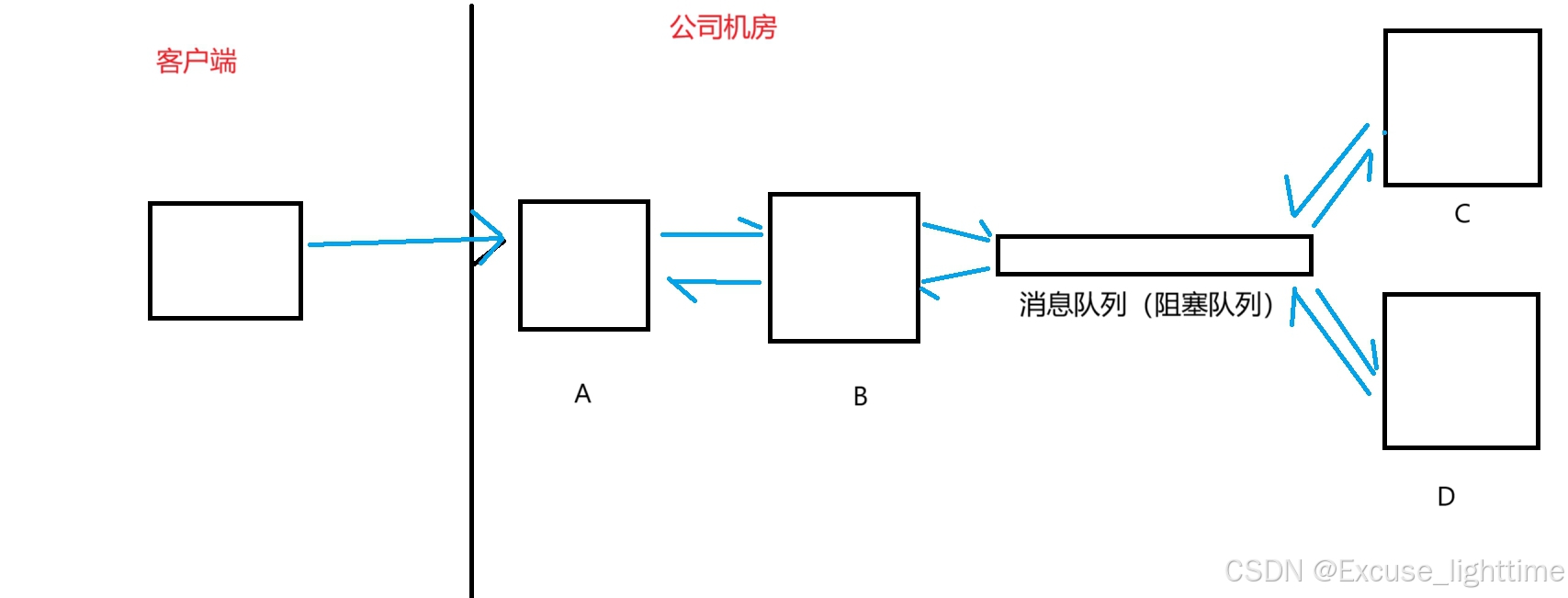
这样,通过一个阻塞队列;如果 C 产生变动,或者再增添服务器(E,F,G......), 对于 B 的影响就很小了。
并且,如果客户端发送的请求 很多,那么服务器A的压力只会给到B,服务器 C 和 D 被 消息队列(阻塞队列)保护起来了。然后再由服务器 C 和 D 慢慢的来处理每个请求,这样做可以有效进行 "削峰",防止服务器被突然到来的一波请求直接冲垮。
但是这样也不是没有缺点的,如果引入的消息队列(阻塞队列)过多,不仅会使得系统复杂,还会增加网络开销。
2.生产者消费者模型:
生产速度与消费速度一样:
public class Demo15 {public static void main(String[] args) throws InterruptedException {BlockingQueue<String> queue = new LinkedBlockingQueue<>(100);//生产者线程Thread producer = new Thread(() -> {int count = 0;try {while (true) {queue.put("" + count);System.out.println("生产了一个元素: " + count);count++;//设置生产速度Thread.sleep(1000);}} catch (InterruptedException e) {e.printStackTrace();}});//消费者线程Thread consumer = new Thread(() -> {try {while (true) {String elem = queue.take();System.out.println("消费了一个元素: " + elem);//设置消费速度Thread.sleep(1000);}} catch (InterruptedException e) {e.printStackTrace();}});producer.start();consumer.start();producer.join();consumer.join();}
}
由于生产者和消费者的速度相同,队列中的元素数量会保持相对稳定。这样能保证系统处于一种稳定的运行状态,不会出现队列满或者队列空的情况。
生产速度比消费速度慢:
public class Demo15 {public static void main(String[] args) throws InterruptedException {BlockingQueue<String> queue = new LinkedBlockingQueue<>(100);//生产者线程Thread producer = new Thread(() -> {int count = 0;try {while (true) {queue.put("" + count);System.out.println("生产了一个元素: " + count);count++;//设置生产速度Thread.sleep(1000);}} catch (InterruptedException e) {e.printStackTrace();}});//消费者线程Thread consumer = new Thread(() -> {try {while (true) {String elem = queue.take();System.out.println("消费了一个元素: " + elem);//设置消费速度//Thread.sleep(1000);}} catch (InterruptedException e) {e.printStackTrace();}});producer.start();consumer.start();producer.join();consumer.join();}
}
上述代码中,生产速度比消费速度慢。这是因为生产者线程每次生产一个元素后会休眠 1000 毫秒,而消费者线程在取出元素后并没有休眠操作,会持续不断地尝试从队列中取出元素进行消费。
由于生产者每 1 秒才生产一个元素,而消费者会持续不断地尝试从队列中取元素,所以大部分时间队列中最多只有一个元素。当生产者生产出一个新元素放入队列时,消费者会马上将其取出。(也就是消费线程拿了一个元素,然后阻塞等待,直到生产线程一秒后又生产了一个元素,消费线程再消费......)。
生产速度比消费速度快:
public class Demo15 {public static void main(String[] args) throws InterruptedException {BlockingQueue<String> queue = new LinkedBlockingQueue<>(100);//生产者线程Thread producer = new Thread(() -> {int count = 0;try {while (true) {queue.put("" + count);System.out.println("生产了一个元素: " + count);count++;//设置生产速度//Thread.sleep(1000);}} catch (InterruptedException e) {e.printStackTrace();}});//消费者线程Thread consumer = new Thread(() -> {try {while (true) {String elem = queue.take();System.out.println("消费了一个元素: " + elem);//设置消费速度Thread.sleep(1000);}} catch (InterruptedException e) {e.printStackTrace();}});producer.start();consumer.start();producer.join();consumer.join();}
}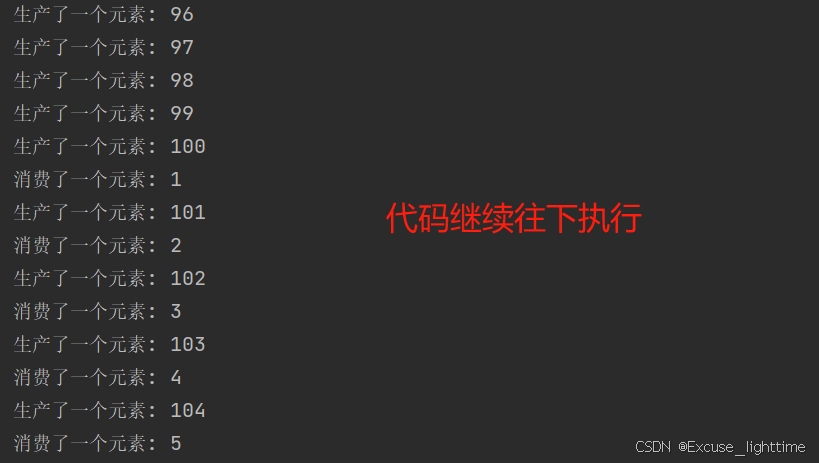
这段截图是后面的运行情况。
消费了一个元素 :0 这个打印结果,出现在代码刚开始跑的时候出现,因为刚开始时队列为空,生产的元素 0 刚被放进队列就被消费线程取出来打印了,然后消费线程等待 1 秒期间,由于队列容量只有100,所以生产线程就只能立刻生产到 100 个元素后处于阻塞状态,一秒后,消费线程继续执行。再消费打印 消费了一个元素 :1
五、模拟实现生产者消费者模型:
实现代码:
//模拟实现生产者消费者模型
class MyBlockingQueue {private String[] arr = null;//数组起始下标private int head = 0;//数组结束下标private int end = 0;//记录有效元素个数private int size = 0;//锁对象private Object locker = new Object();//构造数组大小public MyBlockingQueue(int num) {arr = new String[num];}//线程放置元素public void put(String elem) throws InterruptedException {synchronized (locker) {//如果队列满了while (size >= arr.length) {locker.wait();}arr[end] = elem;end++;//判断 end 是否到了末尾if(end >= arr.length) {end = 0;}//有效元素加一size++;//唤醒 take 的阻塞locker.notify();}}//线程取走元素public String take() throws InterruptedException {synchronized (locker) {//如果队列为空while (size <= 0) {locker.wait();}//得到队列最前面的元素String ret = arr[head];head++;//判断 head 是否到了末尾if(head >= arr.length) {head = 0;}//有效元素减一size--;//唤醒 put 的阻塞locker.notify();//返回队列最前面的元素return ret;}}
}我们使用了一个循环数组,当元素到末尾时,会走到起始的位置(文章之前有讲过,在JAVA数据结构部分的循环队列),实现了 put 方法和 take 方法。
这里解决几个问题:
1、为什么判断数组是否为空和是否为满的情况,用到 size >= arr.length 和 size <= 0 ?
这里使用了防御性编程,原则上我们写的这个代码是不会出现 size > arr.length 和 size < 0的情况,直接使用 size == arr.length 和 size == 0就行了,上述代码这么做是更稳健的做法。
2、为什么把 put 方法和 take 方法各自都加上了synchronized 锁?
因为对于上述的两个方法中,如果有多个线程参与其中一个方法,会涉及到多线程修改同一个变量的操作(比如上述代码的 size 变量);这个操作会出问题的,会引发线程安全问题。
还有就是,一个线程使用 put 方法,另一个线程使用 take 方法,也会涉及到修改同一个变量的操作(比如上述代码的 size 变量);
综上所述,加了锁,确保同一时刻只有一个线程参与某个方法。
3、为什么使用了 wait 和 notify 这些会阻塞方法?
上述代码中,假如 A 线程使用 put 方法时,如果此时的数组满了,就需要阻塞等待并释放当前的锁,直到有元素被 take 走了之后,再被唤醒继续执行 put 操作,那么,谁来唤醒线程 A 呢?肯定是执行 take 方法的另一个线程 B ,当线程 B 获取锁然后 take 走一个元素后,就可以唤醒此时的线程 A 了,线程 A 再 put 一个元素。
所以,上述的 put 方法的 notify 就是唤醒执行 take 方法的线程,take方法的 notify 就是唤醒执行 put 方法的线程,是相互的。
4、为什么判断 为什么判断数组是否为空和是否为满的情况 使用while循环?
假如对于正常执行 put 方法的线程 A ,进入 wait 之前,肯定是会判断一次条件,写成 while ,当 wait 被唤醒之后,还需要再判断一次条件。
正常来说,肯定是条件被打破了,线程 A 才能被唤醒,也就是其他线程使用 take 方法 take 走了一个元素后,条件就变成 size < arr.lenngth ,线程 A 就能继续往下执行。(相当于二次确认的效果)。
但是,不排除在其他代码中,唤醒之后,条件仍然成立的可能性。如果使用了 if ,那么只有一次判断,代码继续往下执行肯定就出错了。(JAVA官方推荐使用while作为 wait 的循环判断条件)