NVIDIA AgentIQ 详细介绍
1. 引言
NVIDIA AgentIQ 是一个灵活的库,旨在将企业代理(无论使用何种框架)与各种数据源和工具无缝集成。通过将代理、工具和代理工作流视为简单的函数调用,AgentIQ 实现了真正的可组合性:一次构建,随处复用。
AgentIQ 的设计理念是简化 AI 代理的开发、部署和管理过程,使开发者能够专注于解决业务问题,而不是处理底层技术细节。无论您是使用哪种代理框架,AgentIQ 都能与之集成,让您充分利用现有技术栈,同时享受 AgentIQ 带来的便利和强大功能。
主要功能和优势
NVIDIA AgentIQ 提供了一系列强大的功能,使其成为开发和管理 AI 代理的理想选择:
-
框架无关性:与任何代理框架兼容,您可以使用当前的技术栈,无需重新平台化。
-
可重用性:每个代理、工具或工作流都可以组合和重新利用,使开发者能够在新场景中利用现有工作。
-
快速开发:从预构建的代理、工具或工作流开始,根据需求进行自定义。
-
性能分析:分析整个工作流直至工具和代理级别,跟踪输入/输出令牌和时间,识别瓶颈。
-
可观测性:使用任何与 OpenTelemetry 兼容的可观测性工具监控和调试工作流。
-
评估系统:使用内置评估工具验证和维护代理工作流的准确性。
-
用户界面:使用 AgentIQ UI 聊天界面与代理交互,可视化输出并调试工作流。
-
MCP 兼容性:与模型上下文协议(Model Context Protocol,MCP)兼容,允许使用 MCP 服务器提供的工具作为 AgentIQ 函数。
适用场景和目标用户
NVIDIA AgentIQ 适用于各种场景,特别是那些需要 AI 代理与多种数据源和工具交互的场景:
- 企业应用开发:需要将 AI 代理集成到现有企业系统中的开发团队。
- 研究人员和数据科学家:需要快速原型设计和测试不同代理架构的研究人员。
- AI 解决方案提供商:需要构建可靠、可扩展的 AI 代理解决方案的公司。
- 开发者和工程师:希望利用 AI 代理技术但不想被特定框架限制的开发者。
使用 NVIDIA AgentIQ,您可以快速行动,自由实验,并确保所有代理驱动项目的可靠性。在接下来的章节中,我们将深入探讨 AgentIQ 的核心特性、安装部署步骤、使用方法以及实际案例分析,帮助您全面了解这个强大的工具。
2. NVIDIA AgentIQ 核心特性
NVIDIA AgentIQ 的核心特性围绕着简化 AI 代理开发和管理的目标设计。本章将详细介绍 AgentIQ 的架构、工作流程、工具集成能力以及评估系统,帮助您理解这个强大工具的内部工作原理。
架构概述
AgentIQ 采用模块化架构,将代理、工具和工作流抽象为函数,实现高度的可组合性和可重用性。其核心架构包括以下组件:
-
函数(Functions):AgentIQ 中的基本构建块,可以是工具、代理或工作流。每个函数都有明确定义的输入和输出,使其可以轻松组合。
-
工作流(Workflows):定义代理如何使用工具和与用户交互的流程。AgentIQ 支持多种工作流类型,包括 ReAct、函数调用和自定义工作流。
-
语言模型(LLMs):AgentIQ 支持多种语言模型,包括 NVIDIA NIM 服务、OpenAI 和 Anthropic 等。
-
嵌入模型(Embedders):用于文本嵌入的模型,支持向量搜索和相似度计算。
-
评估系统(Evaluation System):用于测试和验证代理工作流的性能和准确性。
工作流程
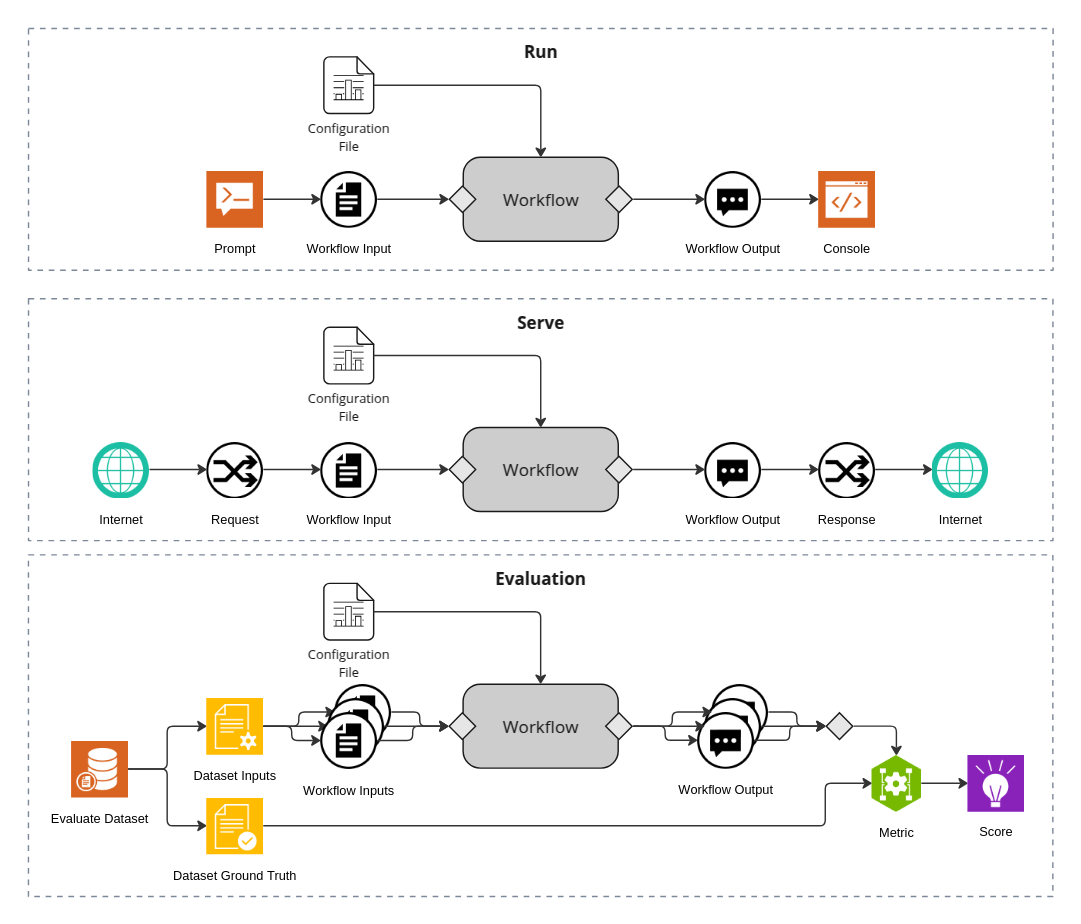
AgentIQ 的工作流程基于函数调用模型,简化了代理与工具的交互:
-
配置定义:通过 YAML 配置文件定义工作流、工具、模型和参数。
-
函数注册:工具和代理作为函数注册到 AgentIQ 系统中。
-
工作流执行:工作流协调代理和工具的交互,处理输入和输出。
-
结果生成:工作流生成最终结果并返回给用户。
这种基于函数的方法使得工作流可以轻松组合和重用,大大提高了开发效率。
工具集成
AgentIQ 的一个主要优势是其强大的工具集成能力。它提供了多种内置工具,并支持自定义工具的创建:
-
内置工具:包括网页查询、搜索引擎、数据库连接、文件操作等。
-
自定义工具:开发者可以创建自己的工具,并将其注册为 AgentIQ 函数。
-
工具链:多个工具可以组合成工具链,实现复杂的功能。
-
MCP 工具:支持使用 Model Context Protocol 服务器提供的工具。
评估系统
AgentIQ 内置了强大的评估系统,用于测试和验证代理工作流的性能:
-
评估指标:支持多种评估指标,包括精确匹配、语义相似度、RAGAS 指标等。
-
数据集管理:支持创建和管理评估数据集。
-
结果分析:提供详细的评估结果分析,帮助识别问题和优化机会。
-
持续评估:支持工作流的持续评估,确保性能稳定。
可观测性和性能分析
AgentIQ 提供了全面的可观测性和性能分析功能:
-
OpenTelemetry 集成:支持与 OpenTelemetry 兼容的可观测性工具集成。
-
性能分析:跟踪工作流、工具和代理的执行时间和令牌使用情况。
-
日志记录:详细的日志记录,帮助调试和优化。
-
可视化:通过 AgentIQ UI 可视化工作流执行过程和结果。
通过这些核心特性,NVIDIA AgentIQ 为开发者提供了一个强大、灵活且易于使用的平台,用于构建和管理 AI 代理。在下一章中,我们将详细介绍如何安装和部署 AgentIQ。
NVIDIA AgentIQ 安装和部署步骤
本章将详细介绍如何安装和部署 NVIDIA AgentIQ,包括环境准备、安装方法、验证安装以及获取必要的 API 密钥。我们还将提供常见安装问题的解决方案,确保您能够顺利开始使用 AgentIQ。
环境准备和前置条件
在开始安装 NVIDIA AgentIQ 之前,请确保您的系统满足以下前置条件:
- 安装 Git
- 安装 Git Large File Storage (LFS)
- 安装 uv(Python 包管理工具)
AgentIQ 是一个 Python 库,不需要 GPU 即可运行工作流。您可以在以下环境中部署核心工作流:
- Ubuntu 或其他 Linux 发行版(包括 WSL)
- Python 虚拟环境
从源代码安装
从源代码安装 AgentIQ 是最常用的方法,特别是对于开发和测试目的。以下是详细的安装步骤:
- 克隆 AgentIQ 仓库到本地机器:
# 克隆 AgentIQ 仓库到本地
git clone git@github.com:NVIDIA/AgentIQ.git agentiq
# 进入克隆的仓库目录
cd agentiq
- 初始化、获取并更新 Git 仓库中的子模块:
# 初始化并更新所有子模块,--init 表示初始化,--recursive 表示递归处理所有嵌套的子模块
git submodule update --init --recursive
- 通过下载 LFS 文件获取数据集:
# 安装 Git LFS 扩展,用于处理大文件
git lfs install
# 获取 LFS 文件的元数据
git lfs fetch
# 将 LFS 文件拉取到本地工作目录
git lfs pull
- 创建 Python 虚拟环境:
# 使用 uv 创建虚拟环境,--seed 参数初始化环境
uv venv --seed .venv
# 激活创建的虚拟环境
source .venv/bin/activate
- 安装 AgentIQ 库。您可以选择安装完整版(包含所有可选依赖)或仅安装核心功能:
# 安装完整版 AgentIQ,包含所有可选依赖
# --all-groups 安装所有开发工具组
# --all-extras 安装所有额外依赖
uv sync --all-groups --all-extras# 或者,仅安装核心 AgentIQ
# -e 表示可编辑模式安装,适合开发环境
uv pip install -e .
如果您只需要特定的插件,可以单独安装它们:
# 安装 langchain 插件,使用方括号指定额外依赖
uv pip install -e '.[langchain]'# 安装性能分析相关的依赖
uv pip install -e .[profiling]
- 验证安装是否成功:
# 显示 aiq 命令的帮助信息,验证命令可用
aiq --help
# 显示 aiq 的版本信息
aiq --version
如果安装成功,aiq 命令将显示帮助信息和当前版本。
使用包管理器安装
当 AgentIQ 工作流准备部署到生产环境时,部署的工作流需要声明对 agentiq 包的依赖,以及所需的插件。建议使用版本号的前两位数字来声明依赖。
对于使用 pyproject.toml 文件的项目,可以这样声明依赖:
dependencies = [# ~=1.0 表示兼容 1.0.x 的任何版本"agentiq[langchain]~=1.0",# 添加工作流需要的其他依赖
]
对于使用 requirements.txt 文件的项目:
# ==1.0.* 表示匹配 1.0.x 的任何版本
agentiq[langchain]==1.0.*
获取 API 密钥
根据您运行的工作流,您可能需要从相应的服务获取 API 密钥。大多数 AgentIQ 工作流需要一个 NVIDIA API 密钥,通过 NVIDIA_API_KEY 环境变量定义。
您可以通过访问 build.nvidia.com 并创建账户来获取 API 密钥。获取密钥后,将其设置为环境变量:
# 设置 NVIDIA API 密钥为环境变量
export NVIDIA_API_KEY=<您的API密钥>
常见安装问题及解决方案
问题:Git LFS 文件未正确下载
解决方案:确保 Git LFS 已正确安装,并重新运行以下命令:
# 重新安装 Git LFS
git lfs install
# 重新获取 LFS 文件元数据
git lfs fetch
# 重新拉取 LFS 文件到工作目录
git lfs pull
问题:依赖冲突
解决方案:创建一个新的虚拟环境,并使用 --all-groups --all-extras 选项安装 AgentIQ:
# 创建新的虚拟环境,避免与现有环境冲突
uv venv --seed .venv_new
# 激活新创建的虚拟环境
source .venv_new/bin/activate
# 安装所有依赖
uv sync --all-groups --all-extras
问题:aiq 命令未找到
解决方案:确保虚拟环境已激活,并检查安装是否成功:
# 确保虚拟环境已激活
source .venv/bin/activate
# 查找 aiq 命令的路径,验证是否正确安装
which aiq
如果仍然找不到命令,尝试重新安装:
# 重新以可编辑模式安装 AgentIQ
uv pip install -e .
问题:无法访问 NVIDIA API
解决方案:确保您已正确设置 NVIDIA API 密钥环境变量,并检查网络连接:
# 检查 API 密钥是否正确设置
echo $NVIDIA_API_KEY
# 测试与 NVIDIA 服务器的网络连接
curl -I https://build.nvidia.com
通过按照上述步骤,您应该能够成功安装和部署 NVIDIA AgentIQ。在下一章中,我们将介绍如何开始使用 AgentIQ,包括运行示例工作流和基本命令行界面的使用。
NVIDIA AgentIQ 入门指南
本章将介绍如何开始使用 NVIDIA AgentIQ,包括基本概念、命令行界面、运行示例工作流以及使用 AgentIQ UI。通过本章内容,您将能够快速上手 AgentIQ,并开始构建自己的 AI 代理应用。
基本概念
在开始使用 AgentIQ 之前,了解一些基本概念是很有帮助的:
-
工作流(Workflow):定义代理如何使用工具和与用户交互的流程。AgentIQ 支持多种工作流类型,包括 ReAct、函数调用和自定义工作流。
-
函数(Function):AgentIQ 中的基本构建块,可以是工具、代理或工作流。每个函数都有明确定义的输入和输出。
-
工具(Tool):代理可以使用的功能,如网页查询、搜索引擎、数据库连接等。
-
语言模型(LLM):驱动代理的大型语言模型,如 NVIDIA NIM 服务提供的模型。
-
嵌入模型(Embedder):用于文本嵌入的模型,支持向量搜索和相似度计算。
命令行界面
AgentIQ 提供了一个强大的命令行界面(CLI),用于管理和运行工作流。以下是一些基本命令:
查看帮助信息
# 显示 aiq 命令的帮助信息
aiq --help# 显示特定子命令的帮助信息
aiq run --help
aiq serve --help
aiq eval --help
查看版本信息
# 显示 AgentIQ 的版本信息
aiq --version
查看可用组件
# 查看所有可用的组件类型
aiq info components# 查看特定类型的组件
aiq info components -t function
aiq info components -t llm_provider
aiq info components -t workflow
运行示例工作流
AgentIQ 提供了多个示例工作流,帮助您快速上手。以下是运行简单工作流的步骤:
-
确保您已经完成了安装和设置 API 密钥的步骤。
-
运行简单工作流:
# 运行简单工作流
aiq run --config_file examples/simple/configs/config.yml --input "你好,请介绍一下自己"
- 观察工作流的输出,包括代理的思考过程和最终回答。
使用 AgentIQ 用户界面和 API 服务器
AgentIQ 提供了一个用户界面,使您能够以可视化方式与运行中的工作流交互。根据官方文档,AgentIQ 提供了以下类型的工作流交互:
- generate non-streaming
- generate streaming
- chat non-streaming
- chat streaming
您可以通过以下方式使用 AgentIQ 的用户界面功能:
- 启动 AgentIQ 服务器:
# 使用 FastAPI 启动 AgentIQ 服务器
aiq start fastapi --config_file examples/simple/configs/config.yml
-
服务器启动后,您可以访问 API 文档(默认地址为 http://localhost:8000/docs)。
-
通过用户界面,您可以:
- 查看聊天历史
- 通过 HTTP API 与工作流交互
- 通过 WebSocket 与工作流交互
- 启用或禁用工作流中间步骤
- 展开所有工作流中间步骤
- 覆盖具有相同 ID 的中间步骤
示例工作流概述
AgentIQ 包含多个示例工作流,展示了不同的功能和用例:
-
简单工作流(Simple):基本的问答工作流,展示了 ReAct 代理的工作方式。
-
网页查询(Webpage Query):展示如何使用代理查询网页内容。
-
搜索引擎(Search Engine):展示如何使用代理搜索互联网信息。
-
数据分析(Data Analysis):展示如何使用代理进行数据分析任务。
-
多代理(Multi-Agent):展示如何使用多个代理协作完成任务。
您可以在 examples 目录中找到这些示例工作流,并通过查看它们的配置文件和代码来学习如何构建自己的工作流。
创建第一个工作流
现在,让我们创建一个简单的工作流:
- 创建一个新的工作流目录:
# 创建工作流目录
mkdir -p my_workflow/configs
- 创建配置文件
my_workflow/configs/config.yml:
# my_workflow/configs/config.ymlfunctions:current_datetime:_type: current_datetimellms:nim_llm:_type: nimmodel_name: meta/llama-3.1-70b-instructtemperature: 0.0workflow:_type: react_agenttool_names: [current_datetime]llm_name: nim_llmverbose: true
- 运行工作流:
# 运行工作流
aiq run --config_file my_workflow/configs/config.yml --input "现在是什么时间?"
这个简单的工作流使用 current_datetime 工具来回答关于当前时间的问题。
通过本章内容,您应该已经了解了如何开始使用 NVIDIA AgentIQ,包括基本概念、命令行界面、运行示例工作流以及使用 AgentIQ UI。在下一章中,我们将深入探讨 AgentIQ 的工作流配置和使用方法。
NVIDIA AgentIQ 工作流配置和使用
本章将详细介绍 NVIDIA AgentIQ 的工作流配置和使用方法,包括工作流配置文件结构、使用各种命令运行工作流以及使用 Python API 的方法。通过本章内容,您将能够深入理解 AgentIQ 工作流的配置和运行机制。
工作流配置文件结构
AgentIQ 工作流由 YAML 配置文件定义,该文件指定了工作流中使用的工具和模型,以及一般配置设置。工作流配置文件通常分为四个主要部分:functions、llms、embedders 和 workflow。
以下是一个简单工作流的配置文件示例:
# examples/simple/configs/config.ymlfunctions:webpage_query:_type: webpage_query # 工具类型,这里是网页查询工具webpage_url: https://docs.smith.langchain.com/user_guide # 要查询的网页URLdescription: "搜索关于 LangSmith 的信息。对于任何关于 LangSmith 的问题,您必须使用此工具!" # 工具描述,指导LLM如何使用embedder_name: nv-embedqa-e5-v5 # 用于文本嵌入的模型名称chunk_size: 512 # 文本分块大小,用于处理长文本current_datetime:_type: current_datetime # 获取当前日期和时间的工具llms:nim_llm:_type: nim # LLM类型,这里使用NVIDIA Inference Microservicesmodel_name: meta/llama-3.1-70b-instruct # 使用的模型名称temperature: 0.0 # 生成文本的随机性参数,0表示最确定性的输出embedders:nv-embedqa-e5-v5:_type: nim # 嵌入器类型model_name: nvidia/nv-embedqa-e5-v5 # 使用的嵌入模型名称workflow:_type: react_agent # 工作流类型,这里是ReAct代理tool_names: [webpage_query, current_datetime] # 工作流使用的工具列表llm_name: nim_llm # 工作流使用的LLM名称verbose: true # 是否输出详细信息retry_parsing_errors: true # 是否重试解析错误max_retries: 3 # 最大重试次数
让我们详细解析这个配置文件的各个部分:
functions 部分
functions 部分定义了工作流中使用的工具。在上面的例子中,定义了两个工具:
-
webpage_query:用于查询网页内容的工具_type:工具类型webpage_url:要查询的网页 URLdescription:工具描述,用于指导 LLM 如何使用该工具embedder_name:用于嵌入的模型名称chunk_size:文本分块大小
-
current_datetime:获取当前日期和时间的工具
llms 部分
llms 部分定义了工作流中使用的语言模型:
nim_llm:使用 NVIDIA Inference Microservices (NIM) 的 LLM_type:LLM 类型model_name:使用的模型名称temperature:生成文本的随机性参数
embedders 部分
embedders 部分定义了用于文本嵌入的模型:
nv-embedqa-e5-v5:NVIDIA 的嵌入模型_type:嵌入器类型model_name:使用的模型名称
workflow 部分
workflow 部分定义了工作流本身:
_type:工作流类型,这里是react_agenttool_names:工作流使用的工具列表llm_name:工作流使用的 LLM 名称verbose:是否输出详细信息retry_parsing_errors:是否重试解析错误max_retries:最大重试次数
使用 aiq run 命令运行工作流
aiq run 命令是运行工作流的最简单方式。它接收一个配置文件和输入内容:
# 基本语法
aiq run --config_file <配置文件路径> [--input "问题?" | --input_file <输入文件路径>]
# --config_file: 指定工作流配置文件的路径
# --input: 直接提供输入问题
# --input_file: 从文件中读取输入问题
例如,运行简单工作流并提供输入问题:
# 使用直接输入运行工作流
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?"
# 使用配置文件examples/simple/configs/config.yml运行工作流
# 输入问题是"什么是LangSmith?"
您也可以通过文件提供输入:
# 创建输入文件
echo "什么是LangSmith?" > .tmp/input.txt
# 将问题"什么是LangSmith?"写入.tmp/input.txt文件# 使用文件输入运行工作流
aiq run --config_file examples/simple/configs/config.yml --input_file .tmp/input.txt
# 使用配置文件examples/simple/configs/config.yml运行工作流
# 从.tmp/input.txt文件读取输入问题
覆盖配置参数
您可以使用 --override 参数在运行时覆盖配置文件中的参数:
# 覆盖 LLM 的温度参数
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?" \--override llms.nim_llm.temperature 0.7
# 使用配置文件运行工作流,但覆盖LLM的温度参数为0.7
# 格式为 --override 参数路径 参数值
您也可以覆盖多个参数:
# 覆盖多个参数
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?" \--override llms.nim_llm.temperature 0.7 \--override llms.nim_llm.model_name meta/llama-3.3-70b-instruct
# 同时覆盖温度参数和模型名称
# 可以连续使用多个--override参数覆盖不同的配置项
使用 aiq serve 命令部署工作流
aiq serve 命令启动一个 Web 服务器,监听传入请求并运行指定的工作流:
# 启动工作流服务器
aiq serve --config_file examples/simple/configs/config.yml
# 使用配置文件启动Web服务器
# 默认监听端口8000和端点/generate
默认情况下,服务器监听端口 8000 和端点 /generate。您可以使用以下命令自定义端口和端点:
# 自定义端口和端点
aiq serve --config_file examples/simple/configs/config.yml --port 9000 --endpoint /api/generate
# --port 9000: 指定服务器监听端口为9000
# --endpoint /api/generate: 指定API端点为/api/generate
在另一个终端中,您可以使用 curl 发送请求与服务器交互:
# 向工作流服务器发送请求
curl --request POST \--url http://localhost:8000/generate \--header 'Content-Type: application/json' \--data '{"input_message": "什么是LangSmith?"
}'
# --request POST: 指定HTTP方法为POST
# --url: 指定服务器URL
# --header: 设置Content-Type头为application/json
# --data: 提供JSON格式的请求体,包含input_message字段
使用 aiq eval 命令评估工作流
aiq eval 命令用于评估工作流的准确性:
# 评估工作流
aiq eval --config_file examples/simple/configs/eval_config.yml
# 使用评估配置文件运行工作流评估
# 评估配置文件包含工作流配置和评估特定配置
评估配置文件 (eval_config.yml) 是工作流配置文件的超集,包含额外的评估字段。以下是一个评估配置示例:
# examples/simple/configs/eval_config.yml# 包含基本工作流配置
functions:webpage_query:_type: webpage_querywebpage_url: https://docs.smith.langchain.com/user_guidedescription: "搜索关于 LangSmith 的信息。对于任何关于 LangSmith 的问题,您必须使用此工具!"embedder_name: nv-embedqa-e5-v5chunk_size: 512current_datetime:_type: current_datetimellms:nim_llm:_type: nimmodel_name: meta/llama-3.1-70b-instructtemperature: 0.0embedders:nv-embedqa-e5-v5:_type: nimmodel_name: nvidia/nv-embedqa-e5-v5workflow:_type: react_agenttool_names: [webpage_query, current_datetime]llm_name: nim_llmverbose: trueretry_parsing_errors: truemax_retries: 3# 评估特定配置
eval:general:output_dir: ./.tmp/aiq/examples/simple/ # 评估结果输出目录dataset:_type: json # 数据集类型file_path: examples/simple/data/langsmith.json # 数据集文件路径evaluators:exact_match: # 精确匹配评估器_type: exact_match # 评估器类型
使用 Python API
除了命令行界面外,AgentIQ 还提供了 Python API,使您能够以编程方式运行和管理工作流。以下是一个使用 Python API 运行工作流的示例:
from aiq.runner import AIQRunner # 导入AIQRunner类
import yaml # 导入yaml模块用于解析YAML文件# 加载配置文件
with open("examples/simple/configs/config.yml", "r") as f:config = yaml.safe_load(f) # 解析YAML配置文件# 创建 AIQRunner 实例
runner = AIQRunner(config) # 使用配置创建运行器实例# 运行工作流
result = runner.run("什么是LangSmith?") # 运行工作流并传入输入问题# 打印结果
print(result) # 输出工作流执行结果
使用 Python API 的优势在于它提供了更大的灵活性和可编程性,使您能够将 AgentIQ 工作流集成到更大的应用程序中。
通过本章内容,您应该已经了解了 AgentIQ 工作流的配置和使用方法。在下一章中,我们将探讨如何自定义工作流,包括修改现有工作流、添加工具和创建新工作流。
NVIDIA AgentIQ 自定义工作流
本章将详细介绍如何自定义 NVIDIA AgentIQ 工作流,包括修改现有工作流、添加工具到工作流、创建新工具和工作流以及工作流参数覆盖。通过本章内容,您将能够根据自己的需求定制 AgentIQ 工作流。
修改现有工作流
在前面的章节中,我们已经了解了工作流配置文件的结构。现在,我们将探讨如何修改现有工作流以满足特定需求。
每个工作流 YAML 文件包含多个可以修改的配置参数。虽然可以直接复制和修改原始 YAML 文件,但有些参数可以使用 --override 标志在不修改原始文件的情况下覆盖。
使用 --override 修改参数
例如,要修改 LLM 的温度参数,可以使用以下命令:
# 覆盖 LLM 的温度参数
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?" \--override llms.nim_llm.temperature 0.7
# 使用--override参数覆盖配置文件中的LLM温度参数
# 格式为:--override 参数路径 参数值
让我们看一个更复杂的例子,修改 LLM 模型和温度:
# 覆盖 LLM 模型和温度
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?" \--override llms.nim_llm.temperature 0.7 \--override llms.nim_llm.model_name meta/llama-3.3-70b-instruct
# 同时覆盖两个参数:温度和模型名称
# 可以连续使用多个--override参数来修改不同的配置项
查看可用参数
要查看特定组件的所有可用参数,可以使用 aiq info components 命令:
# 查看 NIM LLM 提供商的参数
aiq info components -t llm_provider -q nim
# -t llm_provider:指定组件类型为LLM提供商
# -q nim:查询名称为nim的组件
# 这将显示NIM LLM提供商的所有可配置参数及其默认值
这将显示所有可配置的参数及其默认值。
添加工具到工作流
在前面的例子中,我们使用了一个包含两个工具的工作流:webpage_query 和 current_datetime。现在,我们将探讨如何向工作流添加新工具。
添加 Web 搜索工具
假设我们想添加一个 Web 搜索工具,以便工作流可以搜索互联网上的信息。我们需要修改配置文件,添加新工具并更新工作流配置:
# 添加 web_search 工具的配置文件functions:webpage_query:_type: webpage_query # 网页查询工具类型webpage_url: https://docs.smith.langchain.com/user_guide # 要查询的网页URLdescription: "搜索关于 LangSmith 的信息。对于任何关于 LangSmith 的问题,您必须使用此工具!" # 工具描述embedder_name: nv-embedqa-e5-v5 # 用于嵌入的模型名称chunk_size: 512 # 文本分块大小current_datetime:_type: current_datetime # 获取当前日期和时间的工具web_search:_type: web_search # 新添加的Web搜索工具description: "搜索互联网上的信息。对于 LangSmith 以外的问题,使用此工具。" # 工具描述search_engine: "google" # 使用的搜索引擎num_results: 3 # 返回的搜索结果数量llms:nim_llm:_type: nimmodel_name: meta/llama-3.1-70b-instructtemperature: 0.0embedders:nv-embedqa-e5-v5:_type: nimmodel_name: nvidia/nv-embedqa-e5-v5workflow:_type: react_agenttool_names: [webpage_query, current_datetime, web_search] # 更新工具列表,添加web_searchllm_name: nim_llmverbose: trueretry_parsing_errors: truemax_retries: 3
注意我们在 functions 部分添加了 web_search 工具,并在 workflow 部分的 tool_names 列表中包含了这个新工具。
查询可用工具
AgentIQ 包含多个内置工具,可以添加到任何工作流中。要查询可用的工具,可以使用以下命令:
# 查询所有可用的函数(工具)
aiq info components -t function
# -t function:指定查询组件类型为function(工具)
# 这将列出所有可用的内置工具及其描述
创建新工具和工作流
除了使用内置工具外,您还可以创建自己的自定义工具和工作流。AgentIQ 提供了 aiq workflow create 命令来简化这个过程。
创建新工作流
以下是创建新工作流的步骤:
# 创建一个新的工作流
aiq workflow create --workflow-dir examples text_file_ingest
# --workflow-dir examples:指定工作流目录为examples
# text_file_ingest:新工作流的名称
# 这个命令会创建一个新的工作流项目结构
这个命令会执行以下操作:
- 创建一个新目录
examples/text_file_ingest - 设置必要的文件和文件夹
- 安装新的 Python 包到您的环境中
创建的目录结构如下:
examples/
└── text_file_ingest/├── configs/│ └── config.yml├── data/├── pyproject.toml├── README.md└── src/└── aiq_text_file_ingest/├── __init__.py└── functions/└── __init__.py
创建自定义工具
现在,让我们创建一个自定义工具,用于从本地文本文件中提取信息。首先,在 src/aiq_text_file_ingest/functions/ 目录下创建一个新文件 text_reader.py:
# src/aiq_text_file_ingest/functions/text_reader.pyfrom typing import Dict, Any, Optional # 导入类型提示所需的类型
import os # 导入操作系统模块,用于文件路径操作def text_reader(file_path: str, start_line: Optional[int] = 0, end_line: Optional[int] = None) -> Dict[str, Any]:"""从文本文件中读取内容。参数:file_path: 要读取的文本文件路径start_line: 开始读取的行号(从0开始)end_line: 结束读取的行号(不包含)返回:包含文件内容的字典"""# 检查文件是否存在if not os.path.exists(file_path):return {"error": f"文件不存在: {file_path}"} # 如果文件不存在,返回错误信息try:with open(file_path, 'r', encoding='utf-8') as f: # 以UTF-8编码打开文件lines = f.readlines() # 读取所有行# 应用行范围if end_line is None:content = lines[start_line:] # 如果没有指定结束行,读取从开始行到文件末尾else:content = lines[start_line:end_line] # 否则读取指定范围的行return {"content": "".join(content), # 将读取的行合并为一个字符串"total_lines": len(lines), # 返回文件总行数"read_lines": len(content) # 返回实际读取的行数}except Exception as e:return {"error": f"读取文件时出错: {str(e)}"} # 捕获并返回任何读取错误
然后,在 __init__.py 文件中注册这个函数:
# src/aiq_text_file_ingest/functions/__init__.pyfrom .text_reader import text_reader # 导入text_reader函数__all__ = ["text_reader"] # 声明模块公开的函数,使其可被导入
更新工作流配置
接下来,更新 configs/config.yml 文件以使用新创建的工具:
# configs/config.ymlfunctions:text_reader:_type: text_reader # 使用我们创建的自定义工具description: "从文本文件中读取内容。提供文件路径、开始行和结束行(可选)。" # 工具描述llms:nim_llm:_type: nimmodel_name: meta/llama-3.1-70b-instructtemperature: 0.0workflow:_type: react_agenttool_names: [text_reader] # 工作流使用的工具列表,只包含我们的自定义工具llm_name: nim_llmverbose: trueretry_parsing_errors: truemax_retries: 3
重新构建并运行
创建自定义工具后,需要重新构建工作流并运行:
# 重新安装工作流包
uv pip install -e examples/text_file_ingest
# -e 表示可编辑模式安装,适合开发环境
# 这将安装我们创建的自定义工作流包# 运行工作流
aiq run --config_file examples/text_file_ingest/configs/config.yml --input "请读取 /path/to/example.txt 文件的内容"
# 使用我们的自定义工作流配置运行工作流
# 输入是一个请求读取文件内容的问题
工作流参数覆盖
除了使用 --override 标志外,您还可以在配置文件中使用环境变量来覆盖参数。这对于在不同环境中部署工作流特别有用。
使用环境变量
在配置文件中,您可以使用 ${ENV_VAR} 语法引用环境变量:
# 使用环境变量的配置文件functions:webpage_query:_type: webpage_querywebpage_url: ${WEBPAGE_URL:-https://docs.smith.langchain.com/user_guide} # 使用环境变量WEBPAGE_URL,如果未设置则使用默认值description: "搜索关于 LangSmith 的信息。对于任何关于 LangSmith 的问题,您必须使用此工具!"embedder_name: nv-embedqa-e5-v5chunk_size: 512llms:nim_llm:_type: nimmodel_name: ${MODEL_NAME:-meta/llama-3.1-70b-instruct} # 使用环境变量MODEL_NAME,如果未设置则使用默认值temperature: ${TEMPERATURE:-0.0} # 使用环境变量TEMPERATURE,如果未设置则使用默认值# ... 其余配置 ...
在这个例子中,如果环境变量 WEBPAGE_URL、MODEL_NAME 或 TEMPERATURE 已设置,则使用它们的值;否则,使用冒号后面的默认值。
设置环境变量并运行
# 设置环境变量并运行工作流
export WEBPAGE_URL="https://python.langchain.com/docs/get_started" # 设置网页URL环境变量
export MODEL_NAME="meta/llama-3.3-70b-instruct" # 设置模型名称环境变量
export TEMPERATURE="0.5" # 设置温度参数环境变量aiq run --config_file examples/simple/configs/config.yml --input "什么是LangChain?"
# 运行工作流,配置将使用我们设置的环境变量值
通过本章内容,您应该已经了解了如何自定义 AgentIQ 工作流,包括修改现有工作流、添加工具、创建新工具和工作流以及使用参数覆盖。在下一章中,我们将通过实际案例分析,展示如何应用这些知识构建实用的 AI 代理应用。
NVIDIA AgentIQ 案例分析
本章将通过四个具体案例,展示如何使用 NVIDIA AgentIQ 构建和部署不同类型的 AI 代理应用。这些案例涵盖了从简单问答到复杂工具集成的多种场景,帮助您理解 AgentIQ 的实际应用方式。
案例一:构建简单问答工作流
我们的第一个案例是构建一个简单的问答工作流,它能够回答关于 LangSmith 的问题。这个案例基于我们之前讨论过的 examples/simple 工作流。
工作流配置
首先,让我们回顾一下工作流配置:
# examples/simple/configs/config.ymlfunctions:webpage_query:_type: webpage_query # 网页查询工具类型webpage_url: https://docs.smith.langchain.com/user_guide # 要查询的LangSmith文档URLdescription: "搜索关于 LangSmith 的信息。对于任何关于 LangSmith 的问题,您必须使用此工具!" # 工具描述embedder_name: nv-embedqa-e5-v5 # 用于文本嵌入的模型名称chunk_size: 512 # 文本分块大小current_datetime:_type: current_datetime # 获取当前日期和时间的工具llms:nim_llm:_type: nim # LLM类型model_name: meta/llama-3.1-70b-instruct # 使用的模型名称temperature: 0.0 # 生成文本的随机性参数embedders:nv-embedqa-e5-v5:_type: nim # 嵌入器类型model_name: nvidia/nv-embedqa-e5-v5 # 使用的嵌入模型名称workflow:_type: react_agent # 工作流类型tool_names: [webpage_query, current_datetime] # 工作流使用的工具列表llm_name: nim_llm # 工作流使用的LLM名称verbose: true # 是否输出详细信息retry_parsing_errors: true # 是否重试解析错误max_retries: 3 # 最大重试次数
运行工作流
安装并运行工作流:
# 安装工作流
uv pip install -e examples/simple
# -e 表示可编辑模式安装,适合开发环境
# 安装examples/simple目录下的工作流包# 运行工作流
aiq run --config_file examples/simple/configs/config.yml --input "什么是LangSmith?它有哪些主要功能?"
# 使用配置文件运行工作流
# 输入问题是"什么是LangSmith?它有哪些主要功能?"
工作流执行过程
当我们运行这个工作流时,以下是执行过程:
- 工作流接收用户输入:“什么是LangSmith?它有哪些主要功能?”
- ReAct Agent 分析问题,确定需要使用
webpage_query工具 webpage_query工具查询 LangSmith 用户指南网页- 使用嵌入模型
nv-embedqa-e5-v5对网页内容进行嵌入 - 检索与问题最相关的内容
- LLM 生成最终回答
输出示例
Workflow Result:
LangSmith 是一个用于 LLM 应用程序开发、监控和测试的平台。它支持应用程序开发生命周期中的各种工作流,包括:主要功能:
1. 原型设计:快速实验不同的提示、模型类型和检索策略
2. 调试:使用跟踪和应用程序跟踪调试问题
3. 测试:创建数据集并运行评估
4. 监控:监控生产中的应用程序
5. 自动化:设置自动化以简化工作流程
6. 线程:管理对话历史记录
7. 注释跟踪:添加元数据和反馈
8. 数据集管理:将运行添加到数据集中LangSmith 提供了一个统一的界面,使开发人员能够更有效地构建、评估和监控他们的 LLM 应用程序。
案例二:添加网页查询功能
在第二个案例中,我们将扩展前一个工作流,添加一个通用的网页查询功能,使代理能够查询任何指定的网页。
创建新工作流
首先,我们创建一个新的工作流:
# 创建新工作流
aiq workflow create --workflow-dir examples web_query
# --workflow-dir examples:指定工作流目录为examples
# web_query:新工作流的名称
# 这个命令会创建一个新的工作流项目结构
自定义工作流配置
修改配置文件 examples/web_query/configs/config.yml:
# examples/web_query/configs/config.ymlfunctions:dynamic_webpage_query:_type: dynamic_webpage_query # 动态网页查询工具类型description: "查询任何网页的内容。提供完整的URL,包括http://或https://前缀。" # 工具描述embedder_name: nv-embedqa-e5-v5 # 用于文本嵌入的模型名称chunk_size: 512 # 文本分块大小current_datetime:_type: current_datetime # 获取当前日期和时间的工具llms:nim_llm:_type: nim # LLM类型model_name: meta/llama-3.1-70b-instruct # 使用的模型名称temperature: 0.0 # 生成文本的随机性参数embedders:nv-embedqa-e5-v5:_type: nim # 嵌入器类型model_name: nvidia/nv-embedqa-e5-v5 # 使用的嵌入模型名称workflow:_type: react_agent # 工作流类型tool_names: [dynamic_webpage_query, current_datetime] # 工作流使用的工具列表llm_name: nim_llm # 工作流使用的LLM名称verbose: true # 是否输出详细信息retry_parsing_errors: true # 是否重试解析错误max_retries: 3 # 最大重试次数
创建动态网页查询工具
在 src/aiq_web_query/functions/ 目录下创建 dynamic_webpage_query.py 文件:
# src/aiq_web_query/functions/dynamic_webpage_query.pyfrom typing import Dict, Any, Optional # 导入类型提示所需的类型
import requests # 导入HTTP请求库
from bs4 import BeautifulSoup # 导入HTML解析库
import numpy as np # 导入数值计算库
from aiq.embedders import get_embedder # 导入AgentIQ嵌入器获取函数def dynamic_webpage_query(query: str, # 查询文本url: str, # 要查询的网页URLembedder_name: str = "nv-embedqa-e5-v5", # 默认使用的嵌入模型chunk_size: int = 512, # 默认文本分块大小top_k: int = 3 # 默认返回的最相关块数量
) -> Dict[str, Any]:"""查询指定网页的内容并返回与查询最相关的部分。参数:query: 查询文本url: 要查询的网页URLembedder_name: 用于嵌入的模型名称chunk_size: 文本分块大小top_k: 返回的最相关块数量返回:包含查询结果的字典"""try:# 获取网页内容response = requests.get(url) # 发送GET请求获取网页response.raise_for_status() # 如果请求失败,抛出异常# 解析HTMLsoup = BeautifulSoup(response.text, 'html.parser') # 使用BeautifulSoup解析HTML# 提取文本内容text = soup.get_text(separator=' ', strip=True) # 提取所有文本,使用空格分隔,去除首尾空白# 分块chunks = []for i in range(0, len(text), chunk_size): # 按指定大小分块chunks.append(text[i:i+chunk_size])if not chunks:return {"result": "网页内容为空"} # 如果没有内容,返回空结果# 获取嵌入器embedder = get_embedder(embedder_name) # 获取指定的嵌入模型# 计算查询和块的嵌入query_embedding = embedder.embed_query(query) # 计算查询文本的嵌入向量chunk_embeddings = embedder.embed_documents(chunks) # 计算所有文本块的嵌入向量# 计算相似度similarities = []for chunk_embedding in chunk_embeddings:similarity = np.dot(query_embedding, chunk_embedding) # 计算点积相似度similarities.append(similarity)# 获取最相关的块top_indices = np.argsort(similarities)[-top_k:][::-1] # 获取相似度最高的top_k个索引top_chunks = [chunks[i] for i in top_indices] # 获取对应的文本块return {"result": "\n\n".join(top_chunks), # 将最相关的块合并为结果"url": url # 返回查询的URL}except Exception as e:return {"error": f"查询网页时出错: {str(e)}"} # 捕获并返回任何错误
在 __init__.py 文件中注册这个函数:
# src/aiq_web_query/functions/__init__.pyfrom .dynamic_webpage_query import dynamic_webpage_query # 导入动态网页查询函数__all__ = ["dynamic_webpage_query"] # 声明模块公开的函数,使其可被导入
安装并运行工作流
# 安装工作流
uv pip install -e examples/web_query
# -e 表示可编辑模式安装,适合开发环境
# 安装examples/web_query目录下的工作流包# 运行工作流
aiq run --config_file examples/web_query/configs/config.yml --input "请查询 https://python.langchain.com/docs/get_started 并告诉我 LangChain 是什么"
# 使用配置文件运行工作流
# 输入是一个请求查询LangChain文档并解释LangChain的问题
案例三:创建自定义工具
在第三个案例中,我们将创建一个更复杂的自定义工具,用于执行 Python 代码并返回结果。这对于数据分析和计算任务特别有用。
创建新工作流
# 创建新工作流
aiq workflow create --workflow-dir examples code_executor
# --workflow-dir examples:指定工作流目录为examples
# code_executor:新工作流的名称
# 这个命令会创建一个新的工作流项目结构
创建代码执行工具
在 src/aiq_code_executor/functions/ 目录下创建 python_executor.py 文件:
# src/aiq_code_executor/functions/python_executor.pyfrom typing import Dict, Any # 导入类型提示所需的类型
import sys # 导入系统模块
import io # 导入输入输出模块
import traceback # 导入异常跟踪模块
from contextlib import redirect_stdout, redirect_stderr # 导入上下文管理器,用于重定向输出def python_executor(code: str, timeout: int = 10) -> Dict[str, Any]:"""执行Python代码并返回结果。参数:code: 要执行的Python代码timeout: 执行超时时间(秒)返回:包含执行结果的字典"""# 捕获标准输出和标准错误stdout_capture = io.StringIO() # 创建标准输出捕获器stderr_capture = io.StringIO() # 创建标准错误捕获器# 存储执行结果result = None # 初始化结果变量error = None # 初始化错误变量try:# 设置执行环境exec_globals = {"__builtins__": __builtins__, # 包含Python内置函数和变量"print": print, # 提供print函数"Exception": Exception, # 提供Exception类}# 重定向输出with redirect_stdout(stdout_capture), redirect_stderr(stderr_capture):# 执行代码try:# 使用 exec 执行代码块exec(code, exec_globals) # 在指定的全局命名空间中执行代码# 如果代码中有 result 变量,获取它if "result" in exec_globals:result = exec_globals["result"] # 获取代码执行后的result变量except Exception as e:error = f"{type(e).__name__}: {str(e)}\n{traceback.format_exc()}" # 捕获并格式化执行错误# 获取捕获的输出stdout = stdout_capture.getvalue() # 获取标准输出内容stderr = stderr_capture.getvalue() # 获取标准错误内容# 构建返回结果return {"result": result, # 返回执行结果"stdout": stdout, # 返回标准输出"stderr": stderr, # 返回标准错误"error": error # 返回错误信息}except Exception as e:return {"error": f"执行代码时出错: {str(e)}"} # 捕获并返回任何执行错误
在 __init__.py 文件中注册这个函数:
# src/aiq_code_executor/functions/__init__.pyfrom .python_executor import python_executor # 导入Python代码执行函数__all__ = ["python_executor"] # 声明模块公开的函数,使其可被导入
更新工作流配置
修改配置文件 examples/code_executor/configs/config.yml:
# examples/code_executor/configs/config.ymlfunctions:python_executor:_type: python_executor # Python代码执行工具类型description: "执行Python代码并返回结果。提供完整的Python代码块。" # 工具描述current_datetime:_type: current_datetime # 获取当前日期和时间的工具llms:nim_llm:_type: nim # LLM类型model_name: meta/llama-3.1-70b-instruct # 使用的模型名称temperature: 0.0 # 生成文本的随机性参数workflow:_type: react_agent # 工作流类型tool_names: [python_executor, current_datetime] # 工作流使用的工具列表llm_name: nim_llm # 工作流使用的LLM名称verbose: true # 是否输出详细信息retry_parsing_errors: true # 是否重试解析错误max_retries: 3 # 最大重试次数
安装并运行工作流
# 安装工作流
uv pip install -e examples/code_executor
# -e 表示可编辑模式安装,适合开发环境
# 安装examples/code_executor目录下的工作流包# 运行工作流
aiq run --config_file examples/code_executor/configs/config.yml --input "请计算斐波那契数列的前10个数字"
# 使用配置文件运行工作流
# 输入是一个请求计算斐波那契数列的问题
示例输出
Workflow Result:
斐波那契数列的前10个数字是:0, 1, 1, 2, 3, 5, 8, 13, 21, 34我使用Python代码计算了这个结果:```python
def fibonacci(n):"""生成斐波那契数列的前n个数字"""fib_sequence = [0, 1]for i in range(2, n):fib_sequence.append(fib_sequence[i-1] + fib_sequence[i-2])return fib_sequence# 计算前10个斐波那契数
result = fibonacci(10)
print("斐波那契数列的前10个数字:", result)
执行结果显示了斐波那契数列的前10个数字:[0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
## 案例四:评估工作流性能在最后一个案例中,我们将展示如何评估工作流的性能,这对于确保 AI 代理的质量和可靠性至关重要。### 创建评估数据集首先,我们需要创建一个评估数据集。在 `examples/simple/data/` 目录下创建 `eval_dataset.json` 文件:```json
[{"id": 1,"input": "什么是LangSmith?","expected_output": "LangSmith是一个用于LLM应用程序开发、监控和测试的平台。"},{"id": 2,"input": "如何使用LangSmith进行原型设计?","expected_output": "使用LangSmith进行原型设计,可以快速实验不同的提示、模型类型和检索策略。"},{"id": 3,"input": "LangSmith有哪些主要功能?","expected_output": "LangSmith的主要功能包括原型设计、调试、测试、监控、自动化、线程管理、注释跟踪和数据集管理。"}
]
创建评估配置
创建评估配置文件 examples/simple/configs/eval_config.yml:
# examples/simple/configs/eval_config.yml# 包含基本工作流配置
functions:webpage_query:_type: webpage_query # 网页查询工具类型webpage_url: https://docs.smith.langchain.com/user_guide # 要查询的网页URLdescription: "搜索关于 LangSmith 的信息。对于任何关于 LangSmith 的问题,您必须使用此工具!" # 工具描述embedder_name: nv-embedqa-e5-v5 # 用于嵌入的模型名称chunk_size: 512 # 文本分块大小current_datetime:_type: current_datetime # 获取当前日期和时间的工具llms:nim_llm:_type: nim # LLM类型model_name: meta/llama-3.1-70b-instruct # 使用的模型名称temperature: 0.0 # 生成文本的随机性参数embedders:nv-embedqa-e5-v5:_type: nim # 嵌入器类型model_name: nvidia/nv-embedqa-e5-v5 # 使用的嵌入模型名称workflow:_type: react_agent # 工作流类型tool_names: [webpage_query, current_datetime] # 工作流使用的工具列表llm_name: nim_llm # 工作流使用的LLM名称verbose: true # 是否输出详细信息retry_parsing_errors: true # 是否重试解析错误max_retries: 3 # 最大重试次数# 评估特定配置
eval:general:output_dir: ./.tmp/aiq/examples/simple/ # 评估结果输出目录dataset:_type: json # 数据集类型file_path: examples/simple/data/eval_dataset.json # 数据集文件路径evaluators:exact_match: # 精确匹配评估器_type: exact_match # 评估器类型semantic_similarity: # 语义相似度评估器_type: semantic_similarity # 评估器类型llm_name: nim_llm # 使用的LLM名称ragas: # RAGAS评估器_type: ragas # 评估器类型metrics: ["faithfulness", "answer_relevancy"] # 使用的评估指标
运行评估
# 运行评估
aiq eval --config_file examples/simple/configs/eval_config.yml
# 使用评估配置文件运行工作流评估
# 评估结果将保存在指定的输出目录中
分析评估结果
评估完成后,结果将保存在指定的输出目录中。您可以查看详细的评估指标,包括:
- 精确匹配分数:衡量生成的答案与预期答案的精确匹配程度
- 语义相似度:衡量生成的答案与预期答案的语义相似程度
- RAGAS 指标:
- 忠实度:生成的答案是否忠实于检索的上下文
- 答案相关性:生成的答案与问题的相关程度
通过这些指标,您可以全面评估工作流的性能,并根据需要进行优化。
可视化评估结果
您可以使用 Python 脚本可视化评估结果:
# visualization.pyimport json # 导入JSON处理模块
import matplotlib.pyplot as plt # 导入绘图模块
import pandas as pd # 导入数据分析模块# 加载评估结果
with open('./.tmp/aiq/examples/simple/eval_results.json', 'r') as f:results = json.load(f) # 从JSON文件加载评估结果# 提取指标
metrics = {'exact_match': [], # 存储精确匹配分数'semantic_similarity': [], # 存储语义相似度分数'faithfulness': [], # 存储忠实度分数'answer_relevancy': [] # 存储答案相关性分数
}for item in results['eval_output_items']:# 从每个评估项中提取各项指标分数metrics['exact_match'].append(item['evaluators'].get('exact_match', {}).get('score', 0))metrics['semantic_similarity'].append(item['evaluators'].get('semantic_similarity', {}).get('score', 0))metrics['faithfulness'].append(item['evaluators'].get('ragas', {}).get('faithfulness', 0))metrics['answer_relevancy'].append(item['evaluators'].get('ragas', {}).get('answer_relevancy', 0))# 创建DataFrame
df = pd.DataFrame(metrics) # 将指标数据转换为DataFrame# 计算平均分数
avg_scores = df.mean() # 计算每个指标的平均分数# 绘制条形图
plt.figure(figsize=(10, 6)) # 创建图形,设置大小
avg_scores.plot(kind='bar', color=['blue', 'green', 'orange', 'red']) # 绘制条形图
plt.title('工作流评估指标平均分数') # 设置图表标题
plt.ylabel('分数') # 设置Y轴标签
plt.ylim(0, 1) # 设置Y轴范围
plt.grid(axis='y', linestyle='--', alpha=0.7) # 添加网格线
plt.savefig('evaluation_metrics.png') # 保存图表为PNG文件
plt.close() # 关闭图表# 打印平均分数
print("评估指标平均分数:")
for metric, score in avg_scores.items():print(f"{metric}: {score:.4f}") # 打印每个指标的平均分数,保留4位小数
通过这四个案例,我们展示了 NVIDIA AgentIQ 在不同场景下的应用方式,从简单的问答到复杂的代码执行和性能评估。这些案例涵盖了 AgentIQ 的核心功能,帮助您理解如何利用这个强大的工具构建自己的 AI 代理应用。
总结与展望
在本博客中,我们深入探讨了 NVIDIA AgentIQ 这一强大的 AI 代理开发工具。从基本概念到实际应用案例,我们全面介绍了 AgentIQ 的各个方面,帮助您理解如何利用这个工具构建和部署 AI 代理应用。
主要内容回顾
我们首先介绍了 AgentIQ 的核心特性和设计理念,包括其框架无关性、可重用性、快速开发能力以及强大的评估系统。这些特性使 AgentIQ 成为开发和管理 AI 代理的理想选择。
接着,我们详细讲解了 AgentIQ 的安装和部署步骤,包括环境准备、从源代码安装、使用包管理器安装以及获取必要的 API 密钥。我们还提供了常见安装问题的解决方案,确保您能够顺利开始使用 AgentIQ。
在入门指南中,我们介绍了 AgentIQ 的基本概念、命令行界面、运行示例工作流以及使用 AgentIQ UI 的方法。这些基础知识为后续的深入学习奠定了基础。
我们深入探讨了 AgentIQ 的工作流配置和使用方法,包括工作流配置文件结构、使用各种命令运行工作流以及使用 Python API 的方法。这些内容帮助您理解 AgentIQ 工作流的配置和运行机制。
在自定义工作流章节中,我们介绍了如何修改现有工作流、添加工具到工作流、创建新工具和工作流以及工作流参数覆盖。这些知识使您能够根据自己的需求定制 AgentIQ 工作流。
最后,我们通过四个具体案例,展示了如何使用 NVIDIA AgentIQ 构建和部署不同类型的 AI 代理应用。这些案例涵盖了从简单问答到复杂工具集成的多种场景,帮助您理解 AgentIQ 的实际应用方式。
AgentIQ 的优势
通过本博客的学习,我们可以总结出 NVIDIA AgentIQ 的几个主要优势:
-
灵活性和可扩展性:AgentIQ 的模块化架构和函数抽象使其具有极高的灵活性和可扩展性,能够适应各种应用场景。
-
易于使用:AgentIQ 提供了简洁的命令行界面和 Python API,使开发者能够快速上手并构建复杂的 AI 代理应用。
-
强大的工具集成:AgentIQ 支持多种内置工具,并允许开发者创建自定义工具,大大扩展了 AI 代理的能力。
-
全面的评估系统:AgentIQ 内置了强大的评估系统,使开发者能够全面评估工作流的性能,并根据需要进行优化。
-
与 NVIDIA 生态系统的集成:作为 NVIDIA 产品,AgentIQ 与 NVIDIA 的其他 AI 工具和服务无缝集成,提供了更强大的功能和更好的性能。
未来展望
随着 AI 技术的不断发展,NVIDIA AgentIQ 也将持续演进,提供更多功能和更好的性能。未来,我们可以期待以下方面的发展:
-
更多预构建工具和工作流:AgentIQ 可能会提供更多预构建的工具和工作流,使开发者能够更快地构建复杂的 AI 代理应用。
-
更强大的评估和监控功能:随着 AI 代理在生产环境中的应用越来越广泛,AgentIQ 可能会提供更强大的评估和监控功能,确保 AI 代理的质量和可靠性。
-
更深入的生态系统集成:AgentIQ 可能会与更多的 NVIDIA 产品和第三方工具集成,提供更全面的解决方案。
-
更多的学习资源和社区支持:随着 AgentIQ 用户的增加,我们可以期待更多的学习资源和社区支持,帮助开发者更好地使用 AgentIQ。
结语
NVIDIA AgentIQ 是一个强大的 AI 代理开发工具,它简化了 AI 代理的开发、部署和管理过程,使开发者能够专注于解决业务问题,而不是处理底层技术细节。通过本博客的学习,您应该已经掌握了使用 AgentIQ 构建和部署 AI 代理应用的基本知识和技能。
我们鼓励您继续探索 AgentIQ 的更多功能,并将其应用到您的实际项目中。随着您对 AgentIQ 的深入了解和使用,您将能够构建更复杂、更强大的 AI 代理应用,为您的业务带来更大的价值。
祝您在 AI 代理开发之旅中取得成功!