一、线性回归方程

目标:
线性回归的目标是找到最佳的系数来使模型与观察到的数据尽可能拟合。
应用:
预测:给定自变量的值,预测因变量的值。
回归分析:确定自变量对因变量的影响程度
线性回归是统计学和机器学习中最简单且最常用的技术之一,它提供了一个基本的框架来理解和分析变量之间的关系,并用于许多实际应用中,如经济学、金融学、医学、社会科学等领域。
二、参数和超参数
2.1、参数
模型中可调整的变量,它们用来捕捉数据中的模式和特征。这些参数在模型训练过程中被不断调整以最小化损失函数或优化某种目标。
权重(Weights):用来表示不同输入特征与神经元之间的连接强度
偏置(Biases):用于调整每个神经元的激活阈值,使模型能够更好地拟合数据
2.2、超参数
超参数(Hyperparameters)是机器学习和深度学习模型中的一类参数, 它们不是通过训练数据学习得到的,而是在训练过程之前需要手动设置的参数。
与模型的权重和偏置等参数不同,超参数并不直接控制模型的学习过程。 相反,超参数是在训练之前选择或调整的一组参数,用于定义模型的架 构、优化算法、学习率、正则化强度、迭代次数等。它们的选择往往是基 于经验、启发式规则、交叉验证等方法。
常见的超参数包括但不限于以下几个例子:
1. 学习率(Learning Rate):用于控制优化算法中每次更新参数时的步 长。较小的学习率会导致训练收敛较慢,而较大的学习率可能导致训练 不稳定或震荡。
2. 正则化参数(Regularization Parameter):用于控制正则化的强度, 如L1正则化和L2正则化。较大的正则化参数会增强正则化效果,有助 于防止过拟合。
3. 迭代次数(Number of Iterations):用于控制训练的迭代次数。迭代次数太小可能导致模型未完全学习数据的特征,而迭代次数太大可能导 致过拟合。
4. 批量大小(Batch Size):用于控制每次训练时用于更新参数的样本数 量。批量大小的选择会影响训练速度和内存消耗。
5. 神经网络层数和每层的神经元数量(Number of Layers and Neurons per Layer):用于定义神经网络的结构。
6. 激活函数(Activation Function):用于控制神经网络每个神经元的输 出范围,如Sigmoid、ReLU等。
选择合适的超参数对于模型的性能和泛化能力至关重要。通常,人们需要 通过多次试验和交叉验证等方法来调整超参数,以找到最优的组合,从而 获得最好的模型性能。调整超参数是机器学习和深度学习模型开发中一个 重要的步骤,也是一个相对耗时的过程。
三、反向传播

四、设计思路
散点输入
data = np.array([[-0.5, 7.7],[1.8, 98.5],[0.9, 57.8],[0.4, 39.2],[-1.4, -15.7],[-1.4, -37.3],[-1.8, -49.1],[1.5, 75.6],[0.4, 34.0],[0.8, 62.3]
])
x_data = data[:, 0]
y_data = data[:, 1]参数初始化
w = 0
b = 0
learning_rate = 0.01损失函数
def loss_fun(X, Y, w, b):_y_hat = X * w + bloss = np.mean((2 * (_y_hat - Y) ** 2))return loss散点图
for n in range(1, 501): # 进行 500 次迭代训练 # a = wx + b # 根据当前参数计算预测值 y_hat = w * x_data + b # 计算根据参数得到的预测值 # da/dw = x # w 对预测值的影响(斜率) # e = (y - a) ** 2 # 计算损失(误差的平方) # de/da = -2 * (y - a) # 计算损失对预测值的导数(梯度) # de/dw = de/da * da/dw # 链式法则计算损失对 w 的梯度 # de/dw = -2 * (y - a) * x # 损失对 w 的梯度 gradient_w = np.mean(2 * (y_hat - y_data) * x_data) # 计算 w 的梯度均值 # de/db = de/da * da/db # 同样的逻辑应用于 b # de/db = -2 * (y - a) # 损失对 b 的梯度 gradient_b = np.mean(2 * (y_hat - y_data)) # 计算 b 的梯度均值 # 梯度下降更新参数: w = w - learning_rate * gradient_w # 更新权重 w b = b - learning_rate * gradient_b # 更新偏置 b if n % 10 == 0 or n == 1: # 每 10 次迭代或第一次迭代时 plt.cla() # 清空当前图形 min_x = x_data.min() # 获取 x 数据的最小值 max_x = x_data.max() # 获取 x 数据的最大值 min_y = w * min_x + b # 根据当前的 w 和 b 计算最小 y 值 max_y = w * max_x + b # 根据当前的 w 和 b 计算最大 y 值 plt.scatter(x_data, y_data, marker='o', color='b') # 绘制散点图 plt.plot([min_x, max_x], [min_y, max_y], color='r') # 绘制拟合线 plt.xlabel('X') # 设置 x 轴标签 plt.ylabel('Y') # 设置 y 轴标签 plt.pause(1) # 暂停 1 秒以更新图形 plt.show() # 最后显示图形 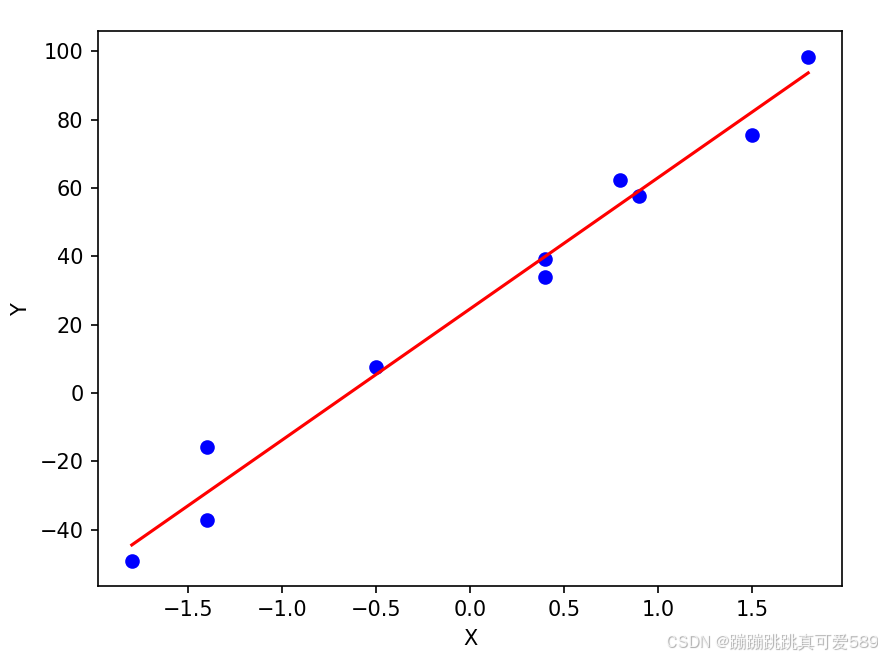
损失图
# 创建网格用于绘制等高线
w_values = np.linspace(-20, 80, 100)
b_values = np.linspace(-20, 80, 100)
W, B = np.meshgrid(w_values, b_values)
loss_value = np.zeros_like(W)# 计算每对 (w, b) 的损失值
for i in range(len(w_values)):for j in range(len(b_values)):loss_value[j, i] = loss_fun(x_data, y_data, w_values[i], b_values[j])# 训练过程
path = [] # 路径记录 w 和 b 的值
for n in range(1, 501):path.append((w, b)) # 记录当前参数值y_hat = w * x_data + b # 预测值# 计算梯度gradient_w = np.mean(2 * (y_hat - y_data) * x_data)gradient_b = np.mean(2 * (y_hat - y_data))# 梯度下降法更新参数w -= learning_rate * gradient_wb -= learning_rate * gradient_b# 每 10 次迭代或第一次迭代时绘制if n % 10 == 0 or n == 1:plt.clf() # 清空当前图形plt.contourf(W, B, loss_value, levels=20, cmap='viridis') # 绘制等高线图plt.colorbar() # 显示颜色条plt.scatter(w, b, c='r', label='当前参数') # 绘制当前参数点plt.plot(*zip(*path), c='r', label='路径') # 绘制路径plt.title(f'迭代次数: {n}')plt.xlabel('w')plt.ylabel('b')plt.legend()plt.show() 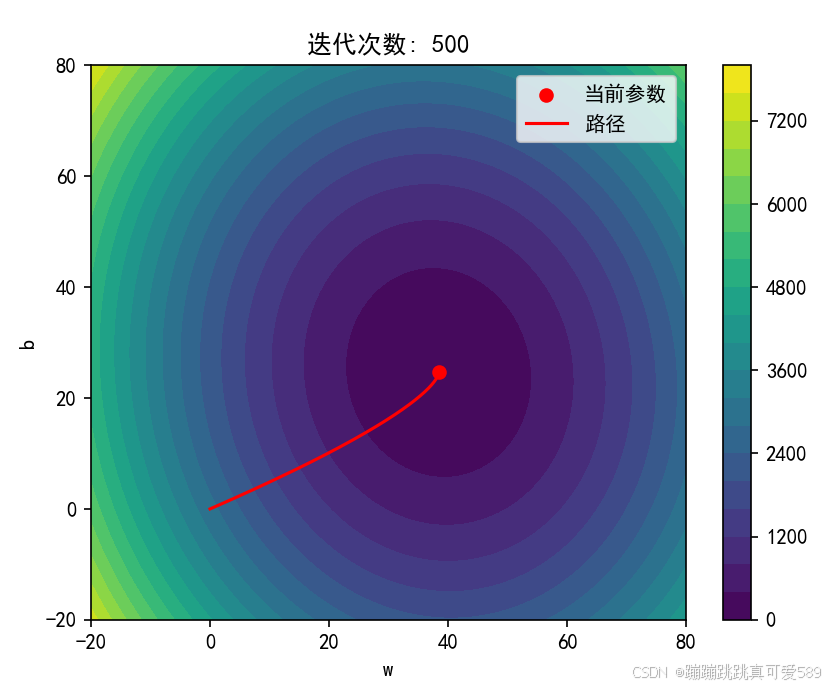
W,B等离线
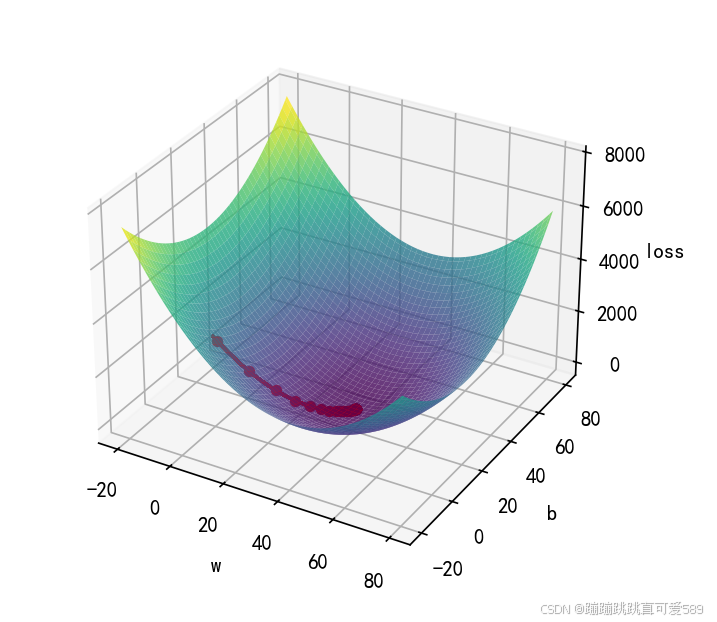
完整代码
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import gridspec # 1. 散点输入
data = np.array([ [-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]
])
x_data = data[:, 0] # 获取输入数据的 x 值
y_data = data[:, 1] # 获取输入数据的 y 值 # 2. 参数初始化
w = 0 # 权重初始值
b = 0 # 偏置初始值
learning_rate = 0.01 # 学习率,用于更新参数的步长 # 3. 损失函数
def loss_fun(X, Y, w, b): _y_hat = X * w + b # 根据当前权重和偏置计算预测值 loss = np.mean((2 * (_y_hat - Y) ** 2)) # 计算均方误差损失 return loss fig = plt.figure(figsize=(12, 6))
g = gridspec.GridSpec(2, 2) # 创建一个 2x2 的网格 ax2 = fig.add_subplot(g[0, 0]) # 上左子图用于散点图
ax2.set_xlabel('X') # 设置 x 轴标签
ax2.set_ylabel('Y') # 设置 y 轴标签 ax3 = fig.add_subplot(g[1, 0]) # 下左子图用于参数可视化
ax3.set_xlabel('w') # 设置 w 轴标签
ax3.set_ylabel('b') # 设置 b 轴标签 ax1 = fig.add_subplot(g[:, 1], projection='3d') # 右侧 3D 子图用于损失可视化
w_values = np.linspace(-20, 80, 100) # 生成 w 的取值范围
b_values = np.linspace(-20, 80, 100) # 生成 b 的取值范围
W, B = np.meshgrid(w_values, b_values) # 创建网格以计算损失值
loss_value = np.zeros_like(W) # 初始化损失值数组 # 计算每对 (w, b) 的损失值
for i, w in enumerate(w_values): for j, b in enumerate(b_values): loss_value[j, i] = loss_fun(x_data, y_data, w, b) # 计算并保存损失值 # 绘制损失表面
ax1.plot_surface(W, B, loss_value, alpha=0.8, cmap='viridis') # 绘制 3D 表面
ax1.set_xlabel('w') # 设置 x 轴标签
ax1.set_ylabel('b') # 设置 y 轴标签
ax1.set_zlabel('loss') # 设置 z 轴标签 path = [] # 用于记录 w 和 b 的值以绘制路径 # 4. 开始迭代
for n in range(1, 501): path.append((w, b)) # 记录当前 w 和 b 的值 # 5、反向传播,手动计算损失函数关于自变量(模型参数)的梯度 # a=wx+b y_hat = w * x_data + b # 计算预测值 # da/dw=x # e=(y-a)**2 # de/da=-2(y-a) # de/dw=de/da * da/dw # de/dw=-2(y-a)*x gradient_w = np.mean(2 * (y_hat - y_data) * x_data) # 计算关于 w 的梯度 # de/db=de/da * da/db # de/db=-2(y-a) gradient_b = np.mean(2 * (y_hat - y_data)) # 计算关于 b 的梯度 # 梯度下降 w = w - learning_rate * gradient_w # 更新 w b = b - learning_rate * gradient_b # 更新 b # 6. 显示频率设置 if n % 10 == 0 or n == 1: # 每10次迭代或者第一次迭代显示一次 x_min = x_data.min() # 获取 x 值的最小值 x_max = x_data.max() # 获取 x 值的最大值 y_min = w * x_min + b # 根据当前的 w 和 b 计算最小 y 值 y_max = w * x_max + b # 根据当前的 w 和 b 计算最大 y 值 ax2.cla() # 清除之前的图形 ax2.scatter(x_data, y_data) # 绘制散点图 ax2.plot([x_min, x_max], [y_min, y_max], c='r') # 绘制拟合线 ax3.contourf(W, B, loss_value, levels=20) # 绘制等高线图 ax3.scatter(w, b, c='r') # 绘制当前参数点 ax1.scatter(w, b, loss_fun(x_data, y_data, w, b)) # 在3D图中添加当前损失点 if len(path) > 0: path_w, path_b = zip(*path) # 分离记录的 w 和 b ax3.plot(path_w, path_b, c='r') # 绘制路径 # 在 3D 图中绘制路径 ax1.plot(path_w, path_b, [loss_fun(x_data, y_data, w_val, b_val) for w_val, b_val in zip(path_w, path_b)], c='r') plt.pause(1) # 暂停 1 秒plt.show() # 显示最终图形 