用哈希结构封装map和set
哈希表的改造
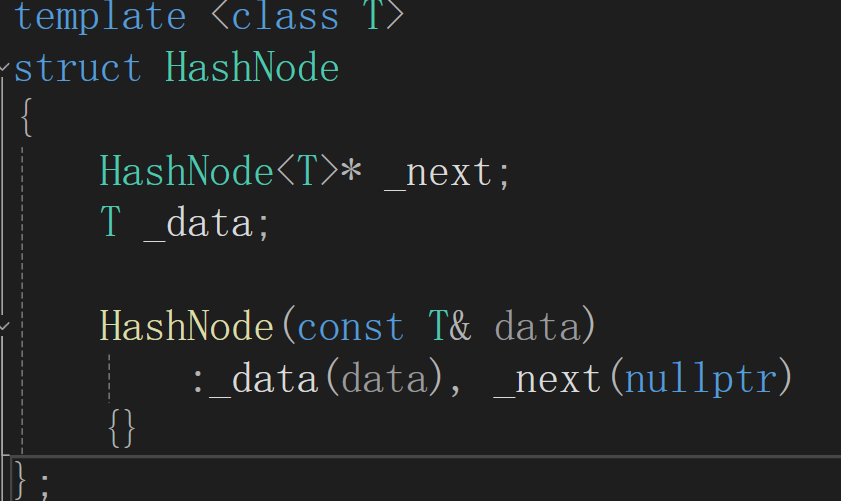
节点
数据类型改为模板
迭代器
成员
一个节点的指针,哈希表和下标用来++访问,哈希表需要支持修改,传入指针,const为了常迭代器可以传递哈希表

++
当前节点的next有内容,先遍历完当前桶。否则下标++,寻找下一个不为空的桶
self& operator++()
{if (_node->_next){//单个桶_node = _node->_next;}else{//下一个桶_hashi++;while (_hashi < _pht->_table.size()){if (_pht->_table[_hashi]){_node = _pht->_table[_hashi];break;}_hashi++;}//循环结束没有数据if (_hashi == _pht->_table.size()){_node = nullptr;}}return *this;
}
类
迭代器需要访问哈希表,带上友元
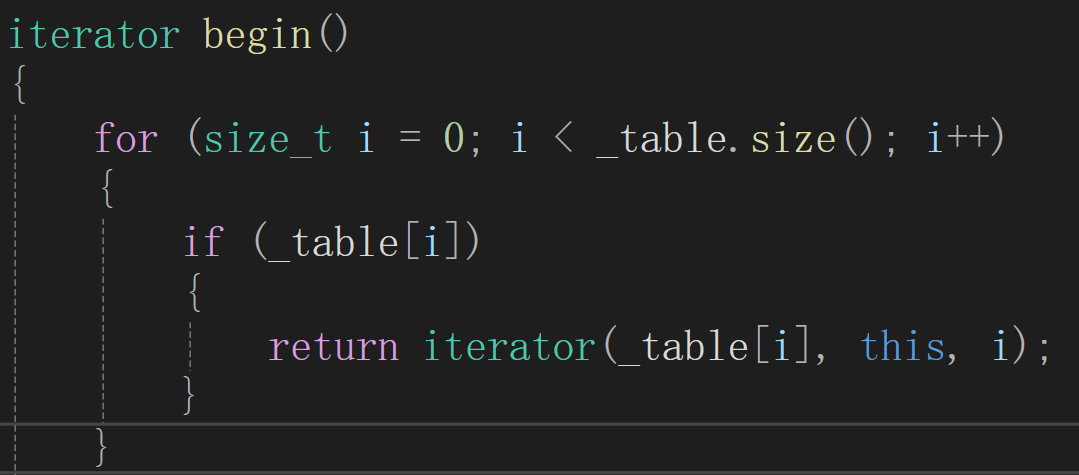
 begin返回第一个不为空的桶,end返回空
begin返回第一个不为空的桶,end返回空

凡是数据比较的地方都需要用仿函数
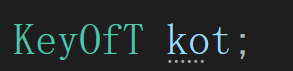

全
#pragma once
#pragma once
#include <string>
#include <iostream>
#include <vector>template <class T>
struct HashNode
{HashNode<T>* _next;T _data;HashNode(const T& data):_data(data), _next(nullptr){}
};//hash int
template <class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//字符串模板特化,string
template <>
struct HashFunc<std::string>
{size_t operator()(const std::string& key){//BKDR方法size_t hash = 0;for (auto ch : key){hash *= 31;hash += ch;}return hash;}
};//前置声明
template <class K, class T, class KeyOfT, class Hash>
class HashBucket;template <class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
struct __HashIterator
{typedef HashNode<T> node;typedef __HashIterator<K, T, Ref, Ptr, KeyOfT, Hash> self;node* _node;const HashBucket<K, T, KeyOfT, Hash>* _pht;size_t _hashi;__HashIterator(node* node, HashBucket<K, T, KeyOfT, Hash>* pht, size_t hashi):_node(node), _pht(pht), _hashi(hashi){}__HashIterator(node* node, const HashBucket<K, T, KeyOfT, Hash>* pht, size_t hashi):_node(node), _pht(pht), _hashi(hashi){}bool operator!=(const self& x){return _node != x._node;}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}self& operator++(){if (_node->_next){//单个桶_node = _node->_next;}else{//下一个桶_hashi++;while (_hashi < _pht->_table.size()){if (_pht->_table[_hashi]){_node = _pht->_table[_hashi];break;}_hashi++;}//循环结束没有数据if (_hashi == _pht->_table.size()){_node = nullptr;}}return *this;}
};//unordered_set hashpackage<K, K>
//unordered_set hashpackage<K, pair<K ,V>>//keyoft取出插入数据的key,hash将其他类型转为整形
template <class K, class T, class KeyOfT, class Hash>
class HashBucket
{typedef HashNode<T> node;//typedef __HashIterator<K, T, KeyOfT, Hash, const T&, const T*> const_iterator;template <class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>friend struct __HashIterator;
public:typedef __HashIterator<K, T, T&, T*, KeyOfT, Hash> iterator;typedef __HashIterator<K, T, const T&, const T*, KeyOfT, Hash> const_iterator;iterator begin(){for (size_t i = 0; i < _table.size(); i++){if (_table[i]){return iterator(_table[i], this, i);}}//如果都为空return end();}iterator end(){return iterator(nullptr, this, -1);}const_iterator begin() const{for (size_t i = 0; i < _table.size(); i++){if (_table[i]){return const_iterator(_table[i], this, i);}} }//const修饰this,传入const HashBucket对象const_iterator end() const{return const_iterator(nullptr, this, -1);}public:HashBucket(){_table.resize(10);}std::pair<iterator, bool> insert(const T& data){KeyOfT kot;iterator it = find(kot(data));if (it != end()){return std::make_pair(it, false);}Hash hf;//负载因子,1if (_n == _table.size()){//扩容size_t newsize = _table.size() * 2;std::vector<node*> newtable;newtable.resize(newsize, nullptr);//遍历旧表for (size_t i = 0; i < _table.size(); i++){node* cur = _table[i];while (cur){node* next = cur->_next;//挪动到新表size_t hashi = hf(kot(cur->_data)) % newtable.size();cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}//旧表还指向节点,置空_table[i] = nullptr;}_table.swap(newtable);}//Hash hf;size_t hashi = hf(kot(data)) % _table.size();node* newnode = new node(data);//头插newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return std::make_pair(iterator(newnode, this, hashi), true);}iterator find(const K& key){KeyOfT kot;Hash hf;//线性探测,字符串需要转整数size_t hashi = hf(key) % _table.size();node* cur = _table[hashi];while (cur){if (kot(cur->_data) == key){return iterator(cur, this, hashi);}cur = cur->_next;}return end();}bool erase(const K& key){KeyOfT kot;Hash hf;size_t hashi = hf(key) % _table.size();node* prev = nullptr;node* cur = _table[hashi];while (cur){//删除if (kot(cur->_data) == key){if (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;}void print(){for (size_t i = 0; i < _table.size(); i++){if (_table[i]){node* cur = _table[i];while (cur){std::cout << "[" << i << "]->" << cur->_kv.first <<":" << cur->_kv.second << " ";cur = cur->_next;}std::cout << std::endl;}else{printf("[%d]->\n", i);}}}~HashBucket(){for (size_t i = 0; i < _table.size(); i++){node* del = _table[i];while (del){node* next = del->_next;delete del;del = next;}_table[i] = nullptr;}}//桶情况void some(){/*size_t bucketsize = 0;size_t maxbucketlen = 0;size_t sum = 0;double averagebucketlen = 0;for (size_t i = 0; i < _table.size(); i++){if (_table[i]){node* cur = _table[i];int len = 0;while (cur){cur = cur->_next;len++;}if (maxbucketlen < len){maxbucketlen = len;}sum += len;bucketsize++;}}averagebucketlen = (double)sum / (double)bucketsize;printf("哈希表大小:%d\n", _table.size());printf("桶大小:%d\n", bucketsize);printf("最大桶:%d\n", maxbucketlen);printf("平均桶:%lf\n", averagebucketlen);*/size_t bucketSize = 0;size_t maxBucketLen = 0;size_t sum = 0;double averageBucketLen = 0;for (size_t i = 0; i < _table.size(); i++){node* cur = _table[i];if (cur){++bucketSize;}size_t bucketLen = 0;while (cur){++bucketLen;cur = cur->_next;}sum += bucketLen;if (bucketLen > maxBucketLen){maxBucketLen = bucketLen;}}averageBucketLen = (double)sum / (double)bucketSize;printf("插入数据:%d\n", _n);printf("all bucketSize:%d\n", _table.size());printf("bucketSize:%d\n", bucketSize);printf("maxBucketLen:%d\n", maxBucketLen);printf("averageBucketLen:%lf\n\n", averageBucketLen);}private:std::vector<node*> _table;size_t _n = 0; //个数
};
unordset
K和V都传K,为了保证key不能修改,使用const迭代器,hash字符串转换模板在这一层传入


插入的返回值是pair,这里哈希表返回的是普通迭代器,需要构造成const迭代器返回
std::pair<const_iterator, bool> insert(const K& key)
{auto ret = _ht.insert(key);return std::pair<const_iterator, bool>(const_iterator(ret.first._node,ret.first._pht, ret.first._hashi), ret.second);
}
全
#pragma once
#include "hashpackage.h"template <class K, class Hash = HashFunc<K>>
class unordset
{struct SetOfK{const K& operator()(const K& key){return key;}};public:typedef typename HashBucket<K, K, SetOfK, Hash>::const_iterator iterator;typedef typename HashBucket<K, K, SetOfK, Hash>::const_iterator const_iterator;const_iterator begin() const{return _ht.begin();}const_iterator end() const{return _ht.end();}std::pair<const_iterator, bool> insert(const K& key){auto ret = _ht.insert(key);return std::pair<const_iterator, bool>(const_iterator(ret.first._node,ret.first._pht, ret.first._hashi), ret.second);}iterator find(const K& key){return _ht.find(key);}bool erase(const K& key){return _ht.erase(key);}private:HashBucket<K, K, SetOfK, Hash> _ht;
};
unordsmap
提供[]运算,返回迭代器的数据

全
#pragma once
#include "hashpackage.h"template <class K, class V, class Hash = HashFunc<K>>
class unordmap
{struct SetOfV{const K& operator()(const std::pair<K, V>& kv){return kv.first;}};
public:typedef typename HashBucket<K, std::pair<const K, V>, SetOfV, Hash>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}std::pair<iterator, bool> insert(const std::pair<K, V>& kv){return _ht.insert(kv);}V& operator[](const K& key){std::pair<iterator, bool> ret = _ht.insert(std::make_pair(key, V()));return ret.first->second;}const V& operator[](const K& key) const{std::pair<iterator, bool> ret = _ht.insert(std::make_pair(key, V()));return ret.first->second;}iterator find(const K& key){return _ht.find(key);}bool erase(const K& key){return _ht.erase(key);}private:HashBucket<K, std::pair<const K, V>, SetOfV, Hash> _ht;
};