目录
- 为什么要使用微服务链路跟踪
- 微服务的现状
- 多服务协同工作
- 复杂的调用链条容易出错
- 微服务链路跟踪需要实现的需求
- 实现监控
- 决策
- 避免技术债务
- 快速定位故障
- 微服务链路跟踪的技术要求
- 低消耗
- 应用透明
- 延展性
- 可控采样率
- 可视化
- Spring Cloud Sleuth
- 简介
- Spring Cloud Sleuth的4个特点
- 使用Sleuth实现微服务跟踪
- 1.添加依赖
- 2.添加配置
- 3.查看日志
- 日志信息所包含的含义
- Spring Cloud Sleuth 整合Zipkin
- 任务背景
- Zipkin
- 构建Zipkin Server
- 1.下载jar文件
- 2.运行jar文件,启动服务
- 整合
- 1.添加依赖
- 2.修改配置
- 说明
- 3.产生数据
- 4.查看监控
- 查看链路数据
- 查看Zipkin Server监控
- 使用消息中间件传输数据
- zipkin的原理
- 收集跟踪数据是使用HTTP请求的方式,带来的问题
- 可以使用消息中间件解决
- 实现
- 1.添加依赖
- 2.修改配置
- 3.启动ZipkinServer
- 4.启动demo-user-provider、demo-user-consumer
- 5.产生数据
- 6.查看监控
- 存储跟踪数据
- 数据丢失
- 数据持久化存储
- 实现
- 1.创建zipkin数据库:从官网下载脚本
- 2.启动ZipkinServer
- 3.启动demo-user-provider、demo-user-consumer
- 4.产生数据
- 5.查看监控
为什么要使用微服务链路跟踪
微服务的现状
- 随着业务的发展,单体架构变为微服务架构,并且系统规模也变得越来越大,各微服务间的调用关系也变得越来越复杂。
多服务协同工作
- 在微服务的应用中,一个由客户端发起的请求在后端系统中会经过多个不同的微服务调用来协同产生最后的请求结果多服务协同工作。
复杂的调用链条容易出错
- 在复杂的微服务架构系统中,几乎每一个前端请求都会形成一个复杂的分布式服务调用链路
- 在每条链路中任何一个依赖服务出现延迟超时或者错误都可能引起整个请求最后的失败。
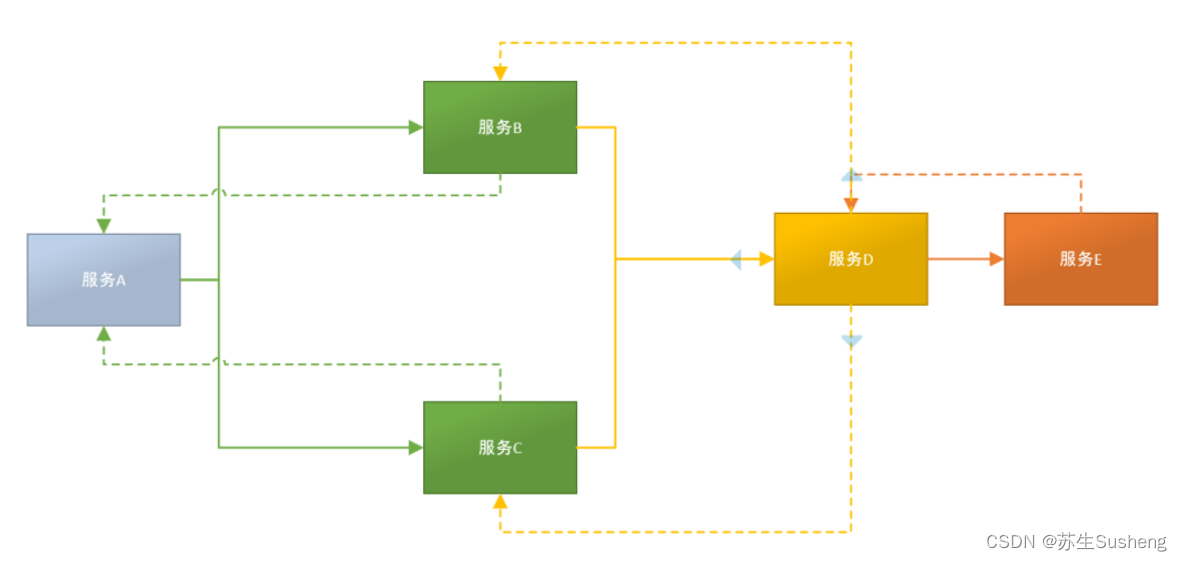
微服务链路跟踪需要实现的需求
实现监控
- 完备的监控系统可以提供及时、准确的性能报告,可以了解请求的路径、请求耗费的时间、网路延迟状态、单个业务逻辑耗费时间指标。
决策
- 我们可以分析系统瓶颈、解决系统存在的问题,以及为当前和未来的决策提供基础数据。
避免技术债务
- 系统会根据业务需求不断地进行演变,如果过去遗留的问题没处理好,则会对新的功能产生影响。
- 如果没有跟踪技术,则会产生大量技术债务。技术债务的累计会对修改或升级带来更多的问题。
快速定位故障
- 在微服务架构中,能在出现问题前预警问题,在出现问题后快速定位故障点非常重要。
- 一个完备的系统需要提供快速检测、隔离和修复问题的方式。
微服务链路跟踪的技术要求
低消耗
- 跟踪系统的本质是发现某个系统的性能或故障问题,所以它不能反过来影响被监控系统的性能。
应用透明
- 应用透明即要求链路跟踪技术对业务系统是透明的,没有侵入性,不会影响开发人员开发业务。
延展性
- 链路跟踪系统应能满足业务系统的发现需求。
- 当系统越来越庞大和复杂后,链路追踪技术依然能快速地跟踪产生的数据,并及时地对数据进行统计和生成报表。
可控采样率
- 可以通过设置采样率来平衡性能消耗和采样质量
可视化
- 具有可视化的控制台也是链路跟踪的一个重要需求
Spring Cloud Sleuth
简介
- Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案,
- 它在整个分布式系统中能跟踪一个请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),
- 捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具。
Spring Cloud Sleuth的4个特点
- 提供链路追踪:通过sleuth可以很清楚的看出一个请求经过了哪些服务,可以方便的理清服务间的调用关系。
- 性能分析:通过sleuth可以很方便的看出每个采集请求的耗时,分析出哪些服务调用比较耗时,当服务调用的耗时随着请求量的增大而增大时,也可以对服务的扩容提供一定的提醒作用。
- 优化链路:对于频繁地调用一个服务,或者并行地调用等,可以针对业务做一些优化措施。
- 可视化:对于程序未捕获的异常,可以在zipkin界面上看到。
使用Sleuth实现微服务跟踪
1.添加依赖
分别为 demo-user-provider、demo-user-consumer项目添加依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId></dependency>
2.添加配置
分别为 demo-user-provider、demo-user-consumer项目添加配置信息
spring:application:name: demo-user-consumer # 提供者服务是:demo-user-providersleuth:sampler:probability: 1 #设置抽样采集率
logging:level:#为了更详细地查看服务通讯时的日志信息,将sleuth的日志级别设置为dubugorg.springframework.cloud.sleuth: debug
3.查看日志
- 依次运行项目demo-eureka-server、demo-user-provider、demo-user-consumer
- postman访问消费者接口(要能够访问提供者服务的接口)
- 在日志中查看跟踪信息


日志信息所包含的含义

- demo-user-consumer:表示微服务的名称
- 52e7dabd360d4ca5:是TranceId。一条链路中只有一个TranceId
- 0bcba7f4505aeb01:是spanId。链路中的基本工作单元id
- false: 是否将数据输出到其他服务中。
Spring Cloud Sleuth 整合Zipkin
任务背景
- 通过Sleuth产生的调用链监控信息,让我们可以得知微服务之间的调用链路
- 但是监控信息只输出到控制台始终不太方便查看。
- 所以我们需要一个图形化的工具。这时候就轮到zipkin出场了。
Zipkin
- Zipkin是Twitter开源的分布式跟踪系统,主要用来收集系统的时序数据,从而追踪系统的调用问题。
- Zipkin提供了一个非常友好的管理界面,可以查看服务之间调用的依赖关系、服务之间调用的耗时情况等。
- Zipkin官网地址:https://zipkin.io/
构建Zipkin Server
1.下载jar文件
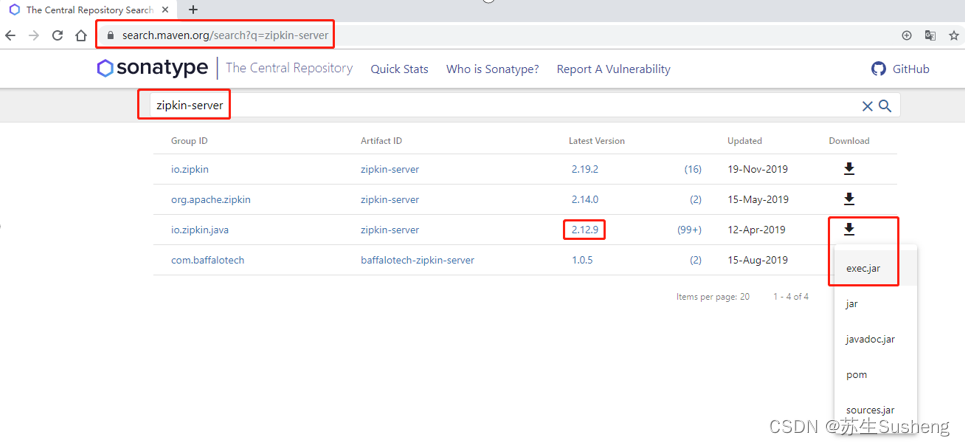
- zipkin官网下载
- Maven仓库中下载
- https://search.maven.org/
- zipkin-server:2.12.9
2.运行jar文件,启动服务
- 控制台输入 java -jar zipkin-server-2.12.9-exec.jar
http://localhost:9411
整合
1.添加依赖
分别为demo-user-consumer、demo-user-provider再添加依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2.修改配置
- 分别修改demo-user-consumer、demo-user-provider 的application.yml
- 在其中指定Zipkin Server地址和采样
spring:application:name: demo-user-consumer # 提供者服务是:demo-user-providersleuth:sampler:probability: 1 #设置抽样采集率zipkin:#指定Zipkin服务器的地址和端口base-url: http://localhost:9411#设置用HTTP方式传输数据sender:type: web
logging:level:#为了更详细地查看服务通讯时的日志信息,将sleuth和openfeign的日志级别设置为dubugorg.springframework.cloud.sleuth: debugorg.springframework.cloud.openfeign: debug
说明
- 在开发、测试中配置文件中的spring.sleuth.sampler. probability属性设置为1.0,代表100%采样
- 否则可能会忽略掉大量span,可能看不到想要查看的请求
3.产生数据
- 使用postman多次访问消费者接口(要能够访问提供者服务的接口)
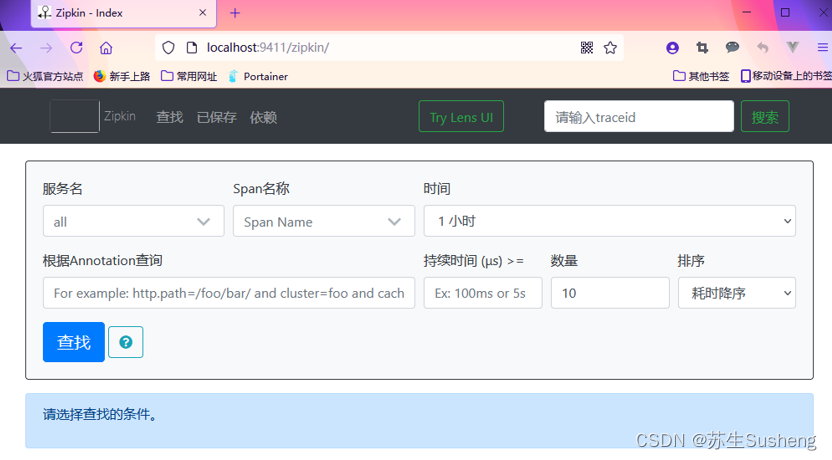
4.查看监控
- 输入条件
- 点击Find Traces查看
- 点击某一个trace查看详细数据
查看链路数据
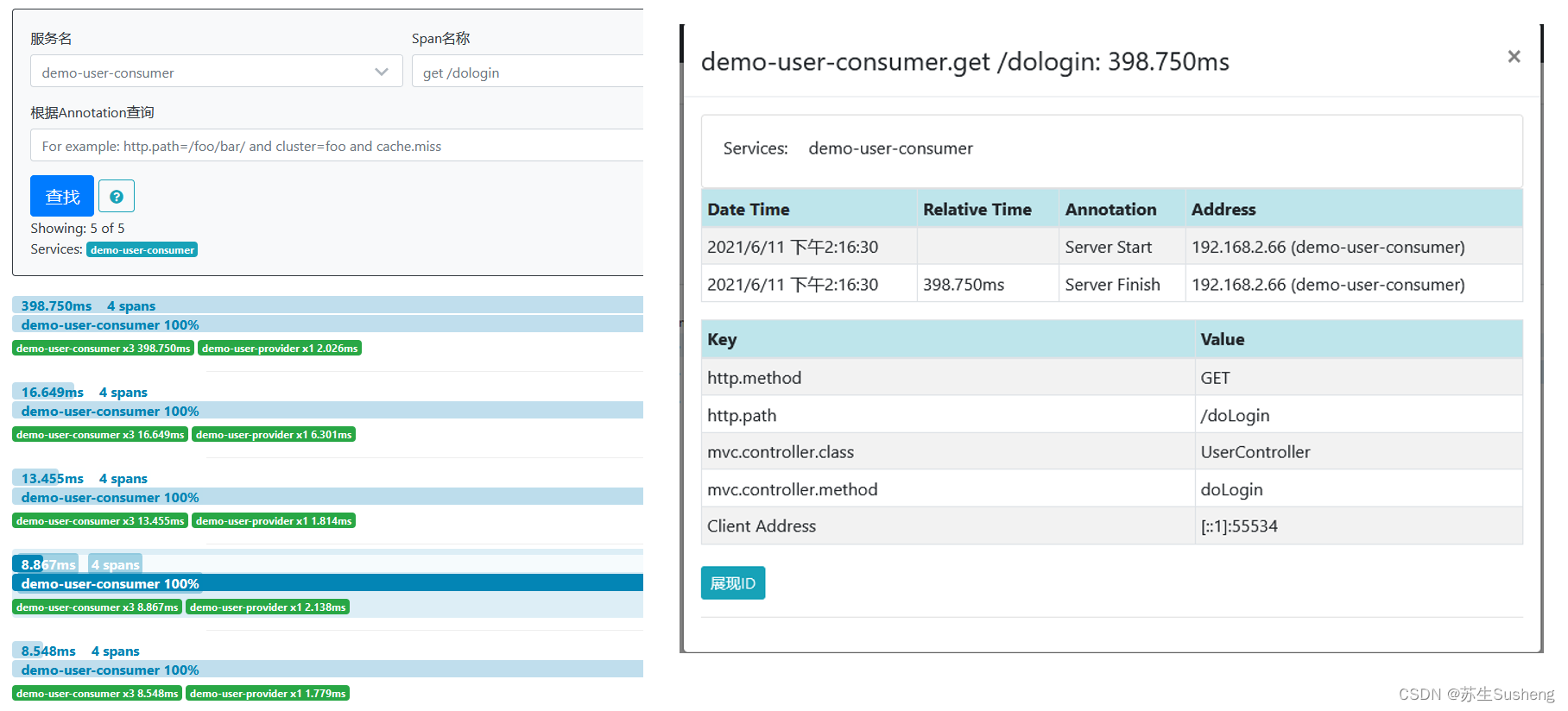
查看Zipkin Server监控
查看要素:
| 名称 | 作用 |
|---|---|
| Service Name | 服务名称,对应的是配置文件中spring.application.name的值,下拉选取 |
| Span Name | 表示Span的名称, Span是Sleuth中的基本工作单元。all表示所有Span |
| Start time | 起始时间 |
| End time | 截止时间 |
| Duration | 表示持续时间,也就是Span从创建到关闭的时间 |
| Limit | 表示查询数据的数量 |
使用消息中间件传输数据
zipkin的原理
- zipkin的原理是服务之间的调用关系会通过HTTP方式上报到zipkin-server端,
- 然后我们再通过zipkin-ui去调用查看追踪服务之间的调用链路
收集跟踪数据是使用HTTP请求的方式,带来的问题
- 耦合性,都需要连接到Zipkin Server
- 不稳定性,网络出现问题就无法保证收集到跟踪数据
可以使用消息中间件解决
- 先将需要收集的数据发送到消息中间件中
- 然后Zipkin Server再从消息中间件取出数据分析
- RabbitMQ

实现
1.添加依赖
- 分别为demo-user-consumer、demo-user-provider添加依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency>
2.修改配置
- 修改demo-user-consumer、demo-user-provider 的application.yml
spring:application:name: demo-user-consumer # 提供者服务是:demo-user-providersleuth:sampler:probability: 1zipkin:base-url: http://localhost:9411sender:type: rabbitrabbitmq:host: 192.168.29.80port: 5672username: adminpassword: adminvirtual-host: /
logging:level:org.springframework.cloud.sleuth: debug
3.启动ZipkinServer
输入命令:
java -jar zipkin-server-2.12.9-exec.jar --zipkin.collector.rabbitmq.uri=amqp://admin:admin@192.168.29.80:5672
4.启动demo-user-provider、demo-user-consumer
5.产生数据
- 使用postman多次访问消费者接口(要能够访问提供者服务的接口)
6.查看监控
- 输入条件
- 点击Find Traces查看
- 点击某一个trace查看详细数据
存储跟踪数据
数据丢失
- Zipkin Server对数据的存储默认是在内存中的
- 在企业生产环境中,一旦Service关闭重启或者服务崩溃,就会导致历史数据消失,需要持久化这些数据。
数据持久化存储
- MySQL
- Elasticsearch
- …
实现
1.创建zipkin数据库:从官网下载脚本
- 官网:https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
2.启动ZipkinServer
-
启动脚本
java -jar zipkin-server-2.12.9-exec.jar --MYSQL_HOST=192.168.2.220 --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=123456 --MYSQL_DB=zipkin --STORAGE_TYPE=mysql --zipkin.collector.rabbitmq.uri=amqp://admin:admin@192.168.29.80:5672
3.启动demo-user-provider、demo-user-consumer
4.产生数据
- 使用postman多次访问消费者接口(要能够访问提供者服务的接口)
5.查看监控
- 输入条件
- 点击Find Traces查看
- 点击某一个trace查看详细数据