Paligemma 简介
在详细介绍使用案例之前,让我们简要回顾一下 Paligemma 的内部运作。
Paligemma 将 SigLIP-So400m 视觉编码器与 Gemma 语言模型相结合,用于处理图像和文本(见上图)。在今年 12 月发布的新版 Paligemma 中,视觉编码器可以预处理三种不同分辨率的图像:224px、448px 或 896px。视觉编码器对图像进行预处理并输出图像标记序列,然后将其与输入文本标记线性组合。Gemma 语言模型进一步处理这种标记组合,然后输出文本标记。Gemma 模型有不同大小的参数,从 2B 到 27B 不等。
下图是模型输出的一个示例。

Paligemma 模型是在 WebLi、openImages、WIT 等各种数据集上训练出来的(详情请参见 Kaggle 博客)。这意味着 Paligemma 可以在不进行微调的情况下识别物体。然而,这种能力是有限的。因此,谷歌建议在特定领域的使用案例中对 Paligemma 进行微调。
输入格式
要对 Paligemma 进行微调,输入数据必须是 JSONL 格式。JSONL 格式的数据集每一行都是一个单独的 JSON 对象,就像一个记录列表。
Image captioning:
{"image": "some_filename.png", "prefix": "caption en" (To indicate that the model should generate an English caption for an image),"suffix": "This is an image of a big, white boat traveling in the ocean."
}Question answering:
{"image": "another_filename.jpg", "prefix": "How many people are in the image?","suffix": "ten"
}Object detection:
{"image": "filename.jpeg", "prefix": "detect airplane","suffix": "<loc0055><loc0115><loc1023><loc1023> airplane" (four corner bounding box coords)
}如果要检测多个类别,请在前缀和后缀中的每个类别之间添加分号(;)。
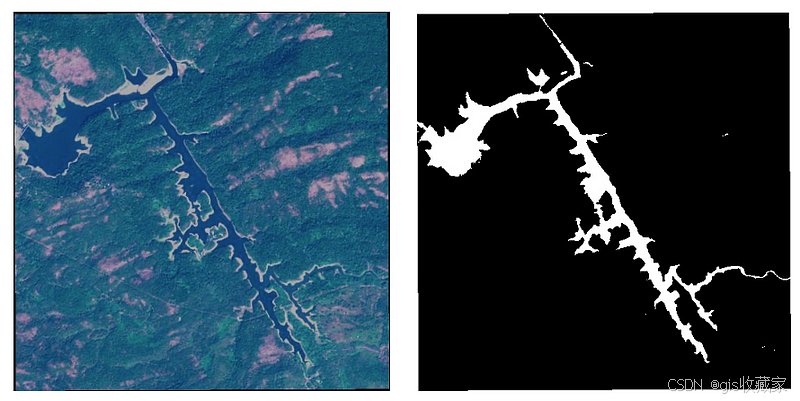
水体卫星图像
如上所述,Paligemma 是在不同的数据集上训练出来的。因此,该模型有望在分割汽车、人或动物等 "传统 "物体方面表现出色。但是,分割卫星图像中的物体又如何呢?这个问题让我开始探索 Paligemma 对卫星图像中水的分割能力。
Kaggle 的 "水体卫星图像 "数据集适合用于此目的。该数据集包含 2841 幅图像及其相应的掩膜。
该数据集中的一些遮罩是不正确的,还有一些需要进一步预处理。错误的例子包括将所有值都设置为水的遮罩,而原始图像中只有一小部分是水。其他掩码与其 RGB 图像不对应。当图像旋转时,一些掩码会使这些区域看起来像有水一样。
鉴于这些数据的局限性,我选择了 164 幅图像作为样本,这些图像的遮罩不存在上述问题。这组图像用于对 Paligemma 进行微调。
准备 JSONL 数据集
如上一节所述,Paligemma 需要在归一化图像空间(......)中表示对象边框坐标的条目,外加 16 个代表 128 个不同编码的分割标记(......)。通过 Roboflow 的解释,我们很容易就能获得所需的边界框坐标格式。但如何从掩码中获取 128 个编码呢?在 Big Vision 软件库中没有明确的文档或示例可供我使用。我天真地以为创建分割标记的过程与制作边界框的过程类似。然而,这导致了水掩膜的错误表示,从而导致了错误的预测结果。
在我写这篇博客的时候(12 月初),谷歌发布了 Paligemma 的第二个版本。之后,Roboflow 发布了一份很好的概述,介绍了如何准备数据,针对不同应用(包括图像分割)对 Paligemma2 进行微调。我使用了他们的部分代码,最终获得了正确的分割编码。我犯了什么错误?首先,需要将掩码调整为[无,64,64,1]形状的张量,然后使用预训练的变异自动编码器(VAE)将注释掩码转换为文本标签。虽然 Big Vision 存储库中简要提到了 VAE 模型的用法,但没有关于如何使用的解释或示例。
我用来准备数据以微调 Paligemma 的工作流程如下所示:
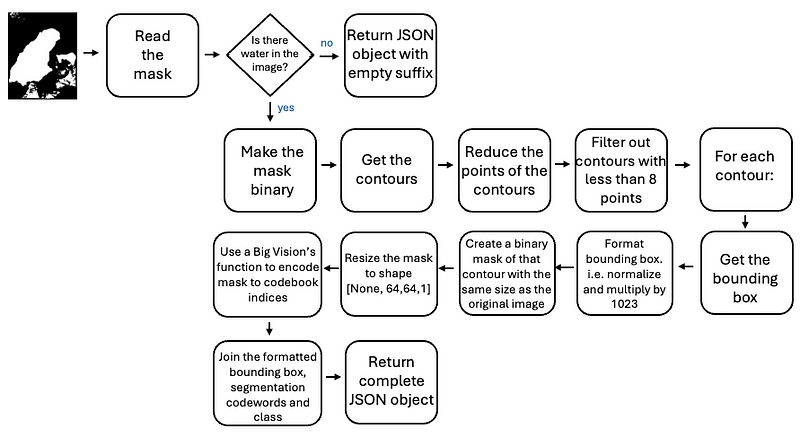
据观察,为 Paligemma 准备数据所需的步骤很多,因此我不在此分享代码片段。不过,如果你想了解代码,可以访问 GitHub 代码库。脚本 convert.py 包含上述工作流程中提到的所有步骤。我还添加了选中的图片,这样你就可以立即使用这个脚本了。
在预处理分割码返回到分割掩码时,我们注意到这些掩码是如何覆盖图像中的水体的:
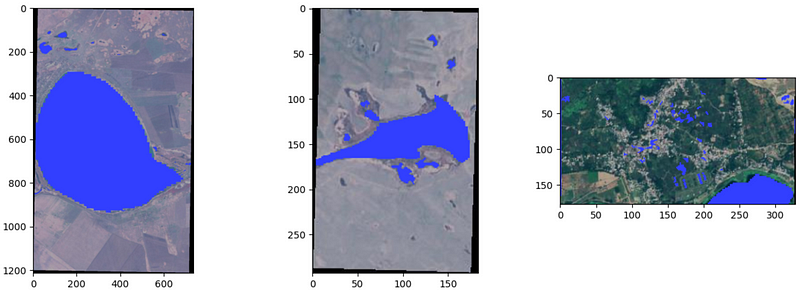
Paligemma 如何分割卫星图像中的水域
在微调 Paligemma 之前,我在上传到 Hugging Face 的模型上试用了它的分割功能。这个平台有一个演示,你可以上传图片并与不同的 Paligemma 模型互动。
当前版本的 Paligemma 在分割卫星图像中的水域方面表现一般,但并不完美。让我们看看能否改进这些结果!
有两种方法可以对 Paligemma 进行微调,一种是通过 Hugging Face 的 Transformer 库,另一种是使用 Big Vision 和 JAX。我选择了最后一种方法。Big Vision 提供了一个 Colab 笔记本,我根据自己的使用情况对其进行了修改。你可以访问我的 GitHub 仓库打开它:
有两种方法可以对 Paligemma 进行微调,一种是通过 Hugging Face 的 Transformer 库,另一种是使用 Big Vision 和 JAX。我选择了最后一种方法。Big Vision 提供了一个 Colab 笔记本,我根据自己的使用情况对其进行了修改。你可以访问我的 GitHub 仓库打开它:
SegmentWaterWithPaligemma/finetune_paligemma_for_segmentation.ipynb at main ·…
我使用的批次大小为 8,学习率为 0.003。我运行了两次训练循环,即 158 个训练步骤。使用 T4 GPU 机器的总运行时间为 24 分钟。结果不尽如人意。Paligemma 在一些图像中没有得出预测结果,而在另一些图像中,得出的掩码与地面实况相差甚远。我还在两幅图像中获得了超过 16 个标记的分段码。
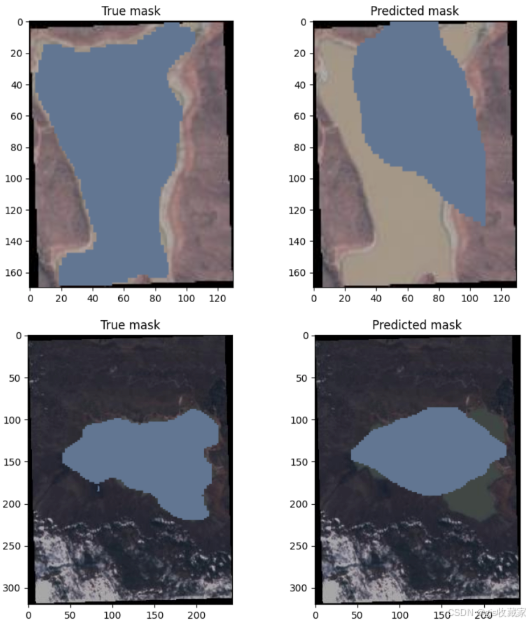
值得一提的是,我使用的是第一个 Paligemma 版本。也许使用 Paligemma2 或进一步调整批量大小或学习率,结果会有所改善。无论如何,这些实验已经超出了本博客的范围。
演示结果表明,默认的 Paligemma 模型比我的微调模型更擅长分割水。我认为,如果要建立一个专门用于分割物体的模型,UNET 是一个更好的架构